Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'inserimento dati è il processo di raccolta, lettura e preparazione di dati da origini diverse, ad esempio file, database, API o servizi cloud, in modo che possano essere usati nelle applicazioni downstream. In pratica, questo processo segue il flusso di lavoro Extract-Transform-Load (ETL):
- Estrarre dati dall'origine originale, sia che si tratti di un PDF, di un documento word, di un file audio o di un'API Web.
- Trasformare i dati tramite pulizia, suddivisione in blocchi, arricchimento o conversione di formati.
- Caricare i dati in una destinazione come un database, un archivio vettoriale o un modello di intelligenza artificiale per il recupero e l'analisi.
Per gli scenari di intelligenza artificiale e Machine Learning, in particolare Retrieval-Augmented Generation (RAG), l'inserimento dati non riguarda solo la conversione dei dati da un formato a un altro. Si tratta di rendere i dati utilizzabili per applicazioni intelligenti. Ciò significa rappresentare i documenti in modo da conservare la struttura e il significato, suddividerli in blocchi gestibili, arricchire i documenti con metadati o incorporamenti e archiviarli in modo che possano essere recuperati in modo rapido e accurato.
Perché l'inserimento dati è importante per le applicazioni di intelligenza artificiale
Si supponga di creare un chatbot basato su RAG per aiutare i dipendenti a trovare informazioni nell'ampia raccolta di documenti dell'azienda. Questi documenti possono includere pdf, file di Word, presentazioni di PowerPoint e pagine Web sparsi in diversi sistemi.
Il chatbot deve comprendere e cercare migliaia di documenti per fornire risposte accurate e contestuali. Ma i documenti non elaborati non sono adatti per i sistemi di intelligenza artificiale. È necessario trasformarli in un formato che mantiene il significato, rendendoli ricercabili e recuperabili.
Questo è il percorso in cui l'inserimento dati diventa critico. È necessario estrarre testo da formati di file diversi, suddividere documenti di grandi dimensioni in blocchi più piccoli che rientrano nei limiti del modello di intelligenza artificiale, arricchire il contenuto con metadati, generare incorporamenti per la ricerca semantica e archiviare tutto in modo da consentire il recupero rapido. Ogni passaggio richiede un'attenta considerazione su come mantenere il significato e il contesto originali.
Libreria Microsoft.Extensions.DataIngestion
Il 📦 pacchetto Microsoft.Extensions.DataIngestion fornisce blocchi predefiniti .NET fondamentali per l'inserimento di dati. Consente agli sviluppatori di leggere, elaborare e preparare documenti per i flussi di lavoro di Intelligenza artificiale e apprendimento automatico, in particolare scenari di generazione aumentata dal recupero (RAG).
Con questi blocchi predefiniti, è possibile creare pipeline di inserimento dati affidabili, flessibili e intelligenti personalizzate per le esigenze dell'applicazione:
- Rappresentazione unificata dei documenti: Rappresenta qualsiasi tipo di file (ad esempio, PDF, Immagine o Microsoft Word) in un formato coerente che funziona bene con i modelli linguistici di grandi dimensioni.
- Inserimento dati flessibile: Leggere i documenti sia dai servizi cloud che dalle origini locali usando più lettori predefiniti, semplificando l'inserimento di dati da qualsiasi posizione.
- Miglioramenti predefiniti dell'intelligenza artificiale: Arricchire automaticamente il contenuto con riepiloghi, analisi del sentiment, estrazione di parole chiave e classificazione, preparazione dei dati per flussi di lavoro intelligenti.
- Strategie di suddivisione in blocchi personalizzabili: Suddividere i documenti in blocchi usando approcci basati su token, basati su sezioni o con riconoscimento semantico, in modo da poter ottimizzare le esigenze di recupero e analisi.
- Archiviazione pronta per la produzione: Memorizza blocchi elaborati nei database vettoriali e nei document store più diffusi, con supporto per la generazione di embedding, rendendo le pipeline pronte per l'utilizzo in scenari reali.
- Composizione della pipeline end-to-end: Concatenare lettori, processori, chunker e scrittori con l'API IngestionPipeline<T>, riducendo codice standard e semplificando la creazione, la personalizzazione e l'estensione dei flussi di lavoro completi.
- Prestazioni e scalabilità: Progettato per l'elaborazione dei dati scalabile, questi componenti possono gestire in modo efficiente grandi volumi di dati, rendendoli adatti per applicazioni di livello aziendale.
Tutti questi componenti sono aperti ed estendibili per progettazione. È possibile aggiungere logica personalizzata e nuovi connettori ed estendere il sistema per supportare gli scenari di intelligenza artificiale emergenti. Standardizzando il modo in cui i documenti vengono rappresentati, elaborati e archiviati, gli sviluppatori .NET possono creare pipeline di dati affidabili, scalabili e gestibili senza "reinventare la ruota" per ogni progetto.
Basata su basi stabili
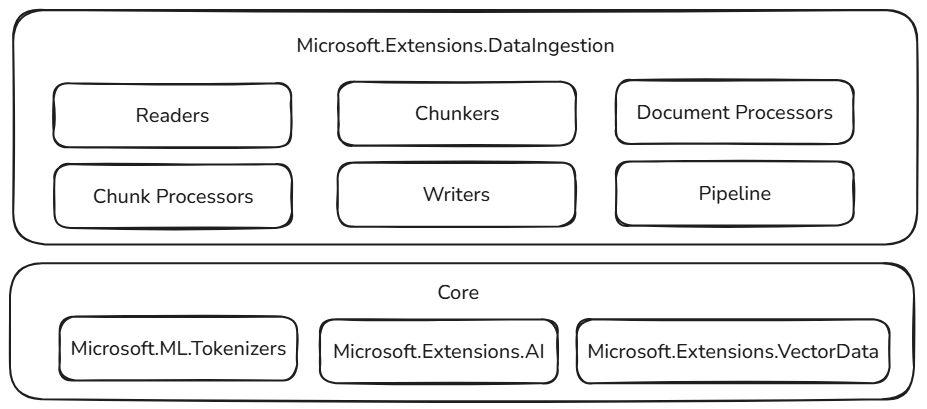
Questi blocchi predefiniti di inserimento dati si basano su componenti collaudati ed estendibili nell'ecosistema .NET, garantendo affidabilità, interoperabilità e integrazione senza problemi con i flussi di lavoro di intelligenza artificiale esistenti:
- Microsoft.ML.Tokenizers: I tokenizer forniscono le basi per la suddivisione in blocchi dei documenti in base ai token. Ciò consente una suddivisione precisa del contenuto, essenziale per preparare i dati per modelli linguistici di grandi dimensioni e ottimizzare le strategie di recupero.
- Microsoft.Extensions.AI: Questo set di librerie supporta le trasformazioni di arricchimento usando modelli linguistici di grandi dimensioni. Consente funzionalità come riepilogo, analisi del sentiment, estrazione di parole chiave e generazione di embedding, semplificando il miglioramento dei dati con approfondimenti intelligenti.
- Microsoft.Extensions.VectorData: Questo set di librerie offre un'interfaccia coerente per l'archiviazione di blocchi elaborati in un'ampia gamma di archivi vettoriali, tra cui Qdrant, Azure SQL, CosmosDB, MongoDB, ElasticSearch e molti altri ancora. In questo modo, le pipeline di dati sono pronte per la produzione e possono essere ridimensionate in back-end di archiviazione diversi.
Oltre a modelli e strumenti familiari, queste astrazioni si basano su componenti già estendibili. Le funzionalità e l'interoperabilità dei plug-in sono fondamentali, quindi, man mano che il resto dell'ecosistema di intelligenza artificiale .NET aumenta, aumentano anche le funzionalità dei componenti di inserimento dati. Questo approccio consente agli sviluppatori di integrare facilmente nuovi connettori, arricchimenti e opzioni di archiviazione, mantenendo le pipeline pronte per il futuro e adattabili agli scenari di intelligenza artificiale in continua evoluzione.
Componenti fondamentali di inserimento dati
La libreria Microsoft.Extensions.DataIngestion è basata su diversi componenti chiave che interagiscono per creare una pipeline di elaborazione dati completa. Questa sezione illustra ogni componente e il modo in cui si adattano tra loro.
Documenti e lettori di documenti
Alla base della libreria è il IngestionDocument tipo , che fornisce un modo unificato per rappresentare qualsiasi formato di file senza perdere informazioni importanti.
IngestionDocument è incentrato su Markdown perché i modelli linguistici di grandi dimensioni funzionano meglio con la formattazione Markdown.
L'astrazione IngestionDocumentReader gestisce il caricamento di documenti da varie origini, incluse le directory locali o i flussi. Sono disponibili alcuni lettori:
Altri lettori (inclusi LlamaParse e Azure Document Intelligence) verranno aggiunti in futuro.
Questa progettazione significa che è possibile usare documenti di origini diverse usando la stessa API coerente, rendendo il codice più gestibile e flessibile.
Documento in fase di elaborazione
I responsabili del trattamento dei documenti applicano trasformazioni a livello di documento per migliorare e preparare il contenuto. La libreria fornisce la ImageAlternativeTextEnricher classe come processore predefinito che usa modelli linguistici di grandi dimensioni per generare testo alternativo descrittivo per le immagini all'interno di documenti.
Blocchi e strategie di suddivisione in blocchi
Dopo aver caricato un documento, in genere è necessario suddividerlo in parti più piccole denominate blocchi. I blocchi rappresentano sottosezioni di un documento che può essere elaborato, archiviato e recuperato in modo efficiente dai sistemi di intelligenza artificiale. Questo processo di suddivisione in blocchi è essenziale per gli scenari di generazione ottimizzati per il recupero, in cui è necessario trovare rapidamente le informazioni più rilevanti.
La libreria offre diverse strategie di suddivisione in blocchi per adattarsi a casi d'uso diversi:
- Suddivisione in blocchi basata su intestazioni per dividere in base alle intestazioni.
- Suddivisione in blocchi basata su sezioni, ad esempio pagine.
- Suddivisione in blocchi con riconoscimento semantico per preservare i pensieri completi.
Queste strategie di suddivisione in blocchi si basano sulla libreria Microsoft.ML.Tokenizers per suddividere in modo intelligente il testo in parti di dimensioni appropriate che funzionano bene con modelli linguistici di grandi dimensioni. La strategia di suddivisione in blocchi corretta dipende dai tipi di documento e dal modo in cui si prevede di recuperare le informazioni.
Tokenizer tokenizer = TiktokenTokenizer.CreateForModel("gpt-4");
IngestionChunkerOptions options = new(tokenizer)
{
MaxTokensPerChunk = 2000,
OverlapTokens = 0
};
IngestionChunker<string> chunker = new HeaderChunker(options);
Elaborazione e arricchimento di blocchi
Dopo aver suddiviso i documenti in blocchi, è possibile applicare processori per migliorare e arricchire il contenuto. I processori chunk funzionano su singoli pezzi e possono eseguire:
-
Arricchimento del contenuto , inclusi i riepiloghi automatici (
SummaryEnricher), l'analisi del sentiment (SentimentEnricher) e l'estrazione di parole chiave (KeywordEnricher). -
Classificazione per la categorizzazione automatica dei contenuti in base alle categorie predefinite (
ClassificationEnricher).
Questi processori usano Microsoft.Extensions.AI.Abstractions per sfruttare i modelli linguistici di grandi dimensioni per la trasformazione intelligente del contenuto, rendendo i blocchi più utili per le applicazioni di intelligenza artificiale downstream.
Elaboratore e archiviazione di documenti
IngestionChunkWriter<T> archivia blocchi elaborati in un archivio dati per il recupero successivo. Usando Microsoft.Extensions.AI e Microsoft.Extensions.VectorData.Abstractions, la libreria fornisce la classe che supporta l'archiviazione VectorStoreWriter<T> di blocchi in qualsiasi archivio vettoriale supportato da Microsoft.Extensions.VectorData.
Gli vector stores includono opzioni comuni come Qdrant, SQL Server, CosmosDB, MongoDB, ElasticSearch e altri. Il writer può anche generare automaticamente embedding per le porzioni usando Microsoft.Extensions.AI, preparandole per scenari di ricerca semantica e recupero.
OpenAIClient openAIClient = new(
new ApiKeyCredential(Environment.GetEnvironmentVariable("GITHUB_TOKEN")!),
new OpenAIClientOptions { Endpoint = new Uri("https://models.github.ai/inference") });
IEmbeddingGenerator<string, Embedding<float>> embeddingGenerator =
openAIClient.GetEmbeddingClient("text-embedding-3-small").AsIEmbeddingGenerator();
using SqliteVectorStore vectorStore = new(
"Data Source=vectors.db;Pooling=false",
new()
{
EmbeddingGenerator = embeddingGenerator
});
// The writer requires the embedding dimension count to be specified.
// For OpenAI's `text-embedding-3-small`, the dimension count is 1536.
using VectorStoreWriter<string> writer = new(vectorStore, dimensionCount: 1536);
Pipeline di elaborazione documenti
L'API IngestionPipeline<T> consente di concatenare i vari componenti di inserimento dati in un flusso di lavoro completo. È possibile combinare:
- Lettori per caricare documenti da varie fonti.
- Processori per trasformare e arricchire il contenuto del documento.
- Utilizzare i Chunkers per suddividere i documenti in parti gestibili.
- Writer per archiviare i risultati finali nell'archivio dati scelto.
Questo approccio alla pipeline riduce il codice boilerplate e semplifica la compilazione, il test e la gestione di flussi di lavoro complessi di inserimento dati.
using IngestionPipeline<string> pipeline = new(reader, chunker, writer, loggerFactory: loggerFactory)
{
DocumentProcessors = { imageAlternativeTextEnricher },
ChunkProcessors = { summaryEnricher }
};
await foreach (var result in pipeline.ProcessAsync(new DirectoryInfo("."), searchPattern: "*.md"))
{
Console.WriteLine($"Completed processing '{result.DocumentId}'. Succeeded: '{result.Succeeded}'.");
}
Un singolo errore di inserimento di documenti non deve avere esito negativo nell'intera pipeline. Ecco perché IngestionPipeline<T>.ProcessAsync implementa un esito positivo parziale restituendo IAsyncEnumerable<IngestionResult>. Il chiamante è responsabile della gestione di eventuali errori, ad esempio ritentando i documenti non riusciti o interrompendo il primo errore.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.