Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In questa esercitazione si crea un'app MSTest per valutare la risposta della chat di un modello OpenAI. L'app di test usa il Microsoft. Librerie Extensions.AI.Evaluation per eseguire le valutazioni, memorizzare nella cache le risposte del modello e creare report. L'esercitazione utilizza valutatori predefiniti e personalizzati. Analizzatori di qualità integrati (dal pacchetto Microsoft.Extensions.AI.Evaluation.Quality) utilizzano un LLM per eseguire valutazioni; questo analizzatore personalizzato non utilizza l'intelligenza artificiale.
Prerequisiti
- .NET 8 o versione successiva
- Visual Studio Code (facoltativo)
Configurare il servizio di intelligenza artificiale
Per effettuare il provisioning di un Azure OpenAI service e di un modello usando il portale di Azure, completare i passaggi descritti nell'articolo Creare e distribuire una risorsa Servizio Azure OpenAI. Nel passaggio "Distribuisci un modello" selezionare il modello di gpt-5.
Creare l'app di test
Completare i passaggi seguenti per creare un progetto MSTest che si connette a un modello di intelligenza artificiale.
In una finestra del terminale passare alla directory in cui si vuole creare l'app e creare una nuova app MSTest con il
dotnet newcomando :dotnet new mstest -o TestAIWithReportingPassare alla directory
TestAIWithReportinge aggiungere i pacchetti necessari all'app:dotnet add package Azure.AI.OpenAI dotnet add package Azure.Identity dotnet add package Microsoft.Extensions.AI.Abstractions dotnet add package Microsoft.Extensions.AI.Evaluation dotnet add package Microsoft.Extensions.AI.Evaluation.Quality dotnet add package Microsoft.Extensions.AI.Evaluation.Reporting dotnet add package Microsoft.Extensions.AI.OpenAI dotnet add package Microsoft.Extensions.Configuration dotnet add package Microsoft.Extensions.Configuration.UserSecretsEsegui i comandi seguenti per aggiungere app secrets per l'endpoint Azure OpenAI e l'ID tenant:
dotnet user-secrets init dotnet user-secrets set AZURE_OPENAI_ENDPOINT <your-Azure-OpenAI-endpoint> dotnet user-secrets set AZURE_TENANT_ID <your-tenant-ID>A seconda dell'ambiente, l'ID tenant potrebbe non essere necessario. In tal caso, rimuovi l'ID tenant dal codice che crea un'istanza del componente DefaultAzureCredential.
Aprire la nuova app nell'editor preferito.
Aggiungere il codice dell'app di test
Rinominare il file Test1.cs in MyTests.cs, quindi aprire il file e rinominare la classe in
MyTests. Eliminare il metodo vuotoTestMethod1.Aggiungere le direttive necessarie
usingall'inizio del file.using Azure.AI.OpenAI; using Azure.Identity; using Microsoft.Extensions.AI.Evaluation; using Microsoft.Extensions.AI; using Microsoft.Extensions.Configuration; using Microsoft.Extensions.AI.Evaluation.Reporting.Storage; using Microsoft.Extensions.AI.Evaluation.Reporting; using Microsoft.Extensions.AI.Evaluation.Quality;Aggiungere la TestContext proprietà alla classe .
// The value of the TestContext property is populated by MSTest. public TestContext? TestContext { get; set; }Aggiungere il
GetAzureOpenAIChatConfigurationmetodo , che crea l'oggetto IChatClient usato dall'analizzatore per comunicare con il modello.private static ChatConfiguration GetAzureOpenAIChatConfiguration() { IConfigurationRoot config = new ConfigurationBuilder().AddUserSecrets<MyTests>().Build(); string endpoint = config["AZURE_OPENAI_ENDPOINT"]; string tenantId = config["AZURE_TENANT_ID"]; string model = "gpt-5"; // Get an instance of Microsoft.Extensions.AI's <see cref="IChatClient"/> // interface for the selected LLM endpoint. AzureOpenAIClient azureClient = new( new Uri(endpoint), new DefaultAzureCredential(new DefaultAzureCredentialOptions() { TenantId = tenantId })); IChatClient client = azureClient.GetChatClient(deploymentName: model).AsIChatClient(); // Create an instance of <see cref="ChatConfiguration"/> // to communicate with the LLM. return new ChatConfiguration(client); }Configurare la funzionalità di creazione di report.
private string ScenarioName => $"{TestContext!.FullyQualifiedTestClassName}.{TestContext.TestName}"; private static string ExecutionName => $"{DateTime.Now:yyyyMMddTHHmmss}"; private static readonly ReportingConfiguration s_defaultReportingConfiguration = DiskBasedReportingConfiguration.Create( storageRootPath: "C:\\TestReports", evaluators: GetEvaluators(), chatConfiguration: GetAzureOpenAIChatConfiguration(), enableResponseCaching: true, executionName: ExecutionName);Nome scenario
Il nome dello scenario è impostato sul nome completo del metodo di test corrente. Tuttavia, è possibile impostarlo su qualsiasi stringa quando si chiama CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken). Prendere in considerazione questi fattori quando si sceglie un nome di scenario:
- Quando si usa l'archiviazione basata su disco, il nome dello scenario viene usato come nome della cartella in cui vengono archiviati i risultati di valutazione corrispondenti. È quindi consigliabile mantenere il nome ragionevolmente breve ed evitare eventuali caratteri non consentiti nei nomi di file e directory.
- Per impostazione predefinita, il report di valutazione generato suddivide i nomi degli scenari in
.modo che i risultati siano visualizzati in una visualizzazione gerarchica con raggruppamento, annidamento e aggregazione appropriati. La visualizzazione gerarchica è particolarmente utile quando il nome dello scenario è il nome completo del metodo di test corrispondente, perché raggruppa i risultati in base a spazi dei nomi e nomi di classe nella gerarchia. Tuttavia, puoi anche sfruttare questa funzionalità includendo i punti (.) nei nomi dei tuoi scenari personalizzati per creare una gerarchia di report che funzioni meglio per i tuoi scenari.
Nome della esecuzione
Il nome dell'esecuzione viene usato per raggruppare i risultati della valutazione che fanno parte della stessa esecuzione di valutazione (o esecuzione di test) quando vengono archiviati i risultati della valutazione. Se non si specifica un nome di esecuzione durante la creazione di , ReportingConfigurationtutte le esecuzioni di valutazione usano lo stesso nome di esecuzione predefinito di
Default. In questo caso, i risultati di un'esecuzione vengono sovrascritti dalla successiva e si perde la possibilità di confrontare i risultati tra diverse esecuzioni.In questo esempio viene usato un timestamp come nome di esecuzione. Se nel progetto sono presenti più test, assicurarsi che i risultati vengano raggruppati correttamente usando lo stesso nome di esecuzione in tutte le configurazioni di report usate nei test.
In uno scenario più reale, è anche possibile condividere lo stesso nome di esecuzione tra i test di valutazione che risiedono in più assembly diversi e eseguiti in processi di test diversi. In questi casi, è possibile usare uno script per aggiornare una variabile di ambiente con un nome di esecuzione appropriato (ad esempio il numero di build corrente assegnato dal sistema CI/CD) prima di eseguire i test. In alternativa, se il sistema di compilazione produce versioni dei file di assembly che aumentano in modo monotonico, è possibile leggere dal AssemblyFileVersionAttribute codice di test e usarlo come nome di esecuzione per confrontare i risultati tra diverse versioni del prodotto.
Configurazione dei report
Un ReportingConfiguration identifica:
- L'insieme di analizzatori che devono essere richiamati per ogni oggetto ScenarioRun creato chiamando CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
- Endpoint LLM che gli analizzatori devono usare (vedere ReportingConfiguration.ChatConfiguration).
- Come e dove dovrebbero essere archiviati i risultati per lo scenario.
- Il modo in cui le risposte LLM correlate all'esecuzione dello scenario devono essere memorizzate nella cache.
- Nome di esecuzione che deve essere usato quando si segnalano i risultati per lo scenario in esecuzione.
Questo test usa una configurazione di reportistica basata su disco.
In un file separato aggiungere la
WordCountEvaluatorclasse , che è un analizzatore personalizzato che implementa IEvaluator.using System.Text.RegularExpressions; using Microsoft.Extensions.AI; using Microsoft.Extensions.AI.Evaluation; namespace TestAIWithReporting; public class WordCountEvaluator : IEvaluator { public const string WordCountMetricName = "Words"; public IReadOnlyCollection<string> EvaluationMetricNames => [WordCountMetricName]; /// <summary> /// Counts the number of words in the supplied string. /// </summary> private static int CountWords(string? input) { if (string.IsNullOrWhiteSpace(input)) { return 0; } MatchCollection matches = Regex.Matches(input, @"\b\w+\b"); return matches.Count; } /// <summary> /// Provides a default interpretation for the supplied <paramref name="metric"/>. /// </summary> private static void Interpret(NumericMetric metric) { if (metric.Value is null) { metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unknown, failed: true, reason: "Failed to calculate word count for the response."); } else { if (metric.Value <= 100 && metric.Value > 5) metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Good, reason: "The response was between 6 and 100 words."); else metric.Interpretation = new EvaluationMetricInterpretation( EvaluationRating.Unacceptable, failed: true, reason: "The response was either too short or greater than 100 words."); } } public ValueTask<EvaluationResult> EvaluateAsync( IEnumerable<ChatMessage> messages, ChatResponse modelResponse, ChatConfiguration? chatConfiguration = null, IEnumerable<EvaluationContext>? additionalContext = null, CancellationToken cancellationToken = default) { // Count the number of words in the supplied <see cref="modelResponse"/>. int wordCount = CountWords(modelResponse.Text); string reason = $"This {WordCountMetricName} metric has a value of {wordCount} because " + $"the evaluated model response contained {wordCount} words."; // Create a <see cref="NumericMetric"/> with value set to the word count. // Include a reason that explains the score. var metric = new NumericMetric(WordCountMetricName, value: wordCount, reason); // Attach a default <see cref="EvaluationMetricInterpretation"/> for the metric. Interpret(metric); return new ValueTask<EvaluationResult>(new EvaluationResult(metric)); } }Conta
WordCountEvaluatoril numero di parole presenti nella risposta. A differenza di alcuni analizzatori, non si basa sull'intelligenza artificiale. IlEvaluateAsyncmetodo restituisce un oggetto EvaluationResult che include un NumericMetric oggetto contenente il conteggio delle parole.Il
EvaluateAsyncmetodo associa anche un'interpretazione predefinita alla metrica. L'interpretazione predefinita considera la metrica valida (accettabile) se il conteggio delle parole rilevate è compreso tra 6 e 100. In caso contrario, la metrica viene considerata non riuscita. Se necessario, il chiamante può eseguire l'override di questa interpretazione predefinita.Nel
MyTests.cs, aggiungere un metodo per raccogliere i valutatori da usare nella valutazione.private static IEnumerable<IEvaluator> GetEvaluators() { IEvaluator relevanceEvaluator = new RelevanceEvaluator(); IEvaluator coherenceEvaluator = new CoherenceEvaluator(); IEvaluator wordCountEvaluator = new WordCountEvaluator(); return [relevanceEvaluator, coherenceEvaluator, wordCountEvaluator]; }Aggiungere un metodo per aggiungere un prompt di ChatMessagesistema, definire le opzioni di chat e chiedere al modello una risposta a una determinata domanda.
private static async Task<(IList<ChatMessage> Messages, ChatResponse ModelResponse)> GetAstronomyConversationAsync( IChatClient chatClient, string astronomyQuestion) { const string SystemPrompt = """ You're an AI assistant that can answer questions related to astronomy. Keep your responses concise and under 100 words. Use the imperial measurement system for all measurements in your response. """; IList<ChatMessage> messages = [ new ChatMessage(ChatRole.System, SystemPrompt), new ChatMessage(ChatRole.User, astronomyQuestion) ]; var chatOptions = new ChatOptions { Temperature = 0.0f, ResponseFormat = ChatResponseFormat.Text }; ChatResponse response = await chatClient.GetResponseAsync(messages, chatOptions); return (messages, response); }Il test in questa esercitazione valuta la risposta dell'LLM a una domanda di astronomia. Poiché la memorizzazione nella cache delle risposte di ReportingConfiguration è abilitata e poiché l'oggetto fornito IChatClient viene sempre recuperato dall'oggetto ScenarioRun creato usando questa configurazione di reporting, la risposta LLM per il test viene memorizzata nella cache e riutilizzata. La risposta viene riutilizzata fino alla scadenza della voce della cache corrispondente (in 14 giorni per impostazione predefinita) o fino a quando un qualsiasi parametro di richiesta, come l'endpoint LLM o la domanda posta, cambia.
Aggiungere un metodo per convalidare la risposta.
/// <summary> /// Runs basic validation on the supplied <see cref="EvaluationResult"/>. /// </summary> private static void Validate(EvaluationResult result) { // Retrieve the score for relevance from the <see cref="EvaluationResult"/>. NumericMetric relevance = result.Get<NumericMetric>(RelevanceEvaluator.RelevanceMetricName); Assert.IsFalse(relevance.Interpretation!.Failed, relevance.Reason); Assert.IsTrue(relevance.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the score for coherence from the <see cref="EvaluationResult"/>. NumericMetric coherence = result.Get<NumericMetric>(CoherenceEvaluator.CoherenceMetricName); Assert.IsFalse(coherence.Interpretation!.Failed, coherence.Reason); Assert.IsTrue(coherence.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); // Retrieve the word count from the <see cref="EvaluationResult"/>. NumericMetric wordCount = result.Get<NumericMetric>(WordCountEvaluator.WordCountMetricName); Assert.IsFalse(wordCount.Interpretation!.Failed, wordCount.Reason); Assert.IsTrue(wordCount.Interpretation.Rating is EvaluationRating.Good or EvaluationRating.Exceptional); Assert.IsFalse(wordCount.ContainsDiagnostics()); Assert.IsTrue(wordCount.Value > 5 && wordCount.Value <= 100); }Suggerimento
Le metriche includono ognuna una
Reasonproprietà che spiega il motivo del punteggio. Il motivo è incluso nel report generato e può essere visualizzato facendo clic sull'icona delle informazioni nella scheda della metrica corrispondente.Infine, aggiungere il metodo di test stesso.
[TestMethod] public async Task SampleAndEvaluateResponse() { // Create a <see cref="ScenarioRun"/> with the scenario name // set to the fully qualified name of the current test method. await using ScenarioRun scenarioRun = await s_defaultReportingConfiguration.CreateScenarioRunAsync( ScenarioName, additionalTags: ["Moon"]); // Use the <see cref="IChatClient"/> that's included in the // <see cref="ScenarioRun.ChatConfiguration"/> to get the LLM response. (IList<ChatMessage> messages, ChatResponse modelResponse) = await GetAstronomyConversationAsync( chatClient: scenarioRun.ChatConfiguration!.ChatClient, astronomyQuestion: "How far is the Moon from the Earth at its closest and furthest points?"); // Run the evaluators configured in <see cref="s_defaultReportingConfiguration"/> against the response. EvaluationResult result = await scenarioRun.EvaluateAsync(messages, modelResponse); // Run some basic validation on the evaluation result. Validate(result); }Questo metodo di test:
Crea l'oggetto ScenarioRun.
await usinggarantisce l'eliminazione corretta dell'oggettoScenarioRune la corretta persistenza dei risultati della valutazione nell'archivio risultati.Ottiene la risposta dell'LLM a una domanda di astronomia specifica. Il test utilizza lo stesso IChatClient impiegato per la valutazione, passato al metodo
GetAstronomyConversationAsync, per ottenere la memorizzazione nella cache delle risposte della risposta LLM primaria da valutare. Il passaggio dello stesso client abilita anche la memorizzazione nella cache delle risposte per i turni LLM usati dagli analizzatori per eseguire le proprie valutazioni internamente. Con la memorizzazione nella cache delle risposte, la risposta LLM viene recuperata:- Direttamente dall'endpoint LLM nella prima esecuzione del test corrente o nelle esecuzioni successive se la voce memorizzata nella cache è scaduta (14 giorni, per impostazione predefinita).
- Dalla cache delle risposte (basata su disco) configurata in
s_defaultReportingConfigurationnelle esecuzioni successive del test.
Esegue i valutatori contro la risposta. Analogamente alla risposta LLM, le esecuzioni successive recuperano la valutazione dalla cache delle risposte (basata su disco) configurata in
s_defaultReportingConfiguration.Esegue una convalida di base sul risultato della valutazione.
Questo passaggio è facoltativo e principalmente a scopo dimostrativo. Nelle valutazioni reali, è possibile non convalidare i singoli risultati perché le risposte e i punteggi di valutazione LLM possono cambiare nel tempo man mano che il prodotto (e i modelli usati) si evolvono. Potresti non voler che i singoli test di valutazione falliscano e blocchino le compilazioni nelle pipeline CI/CD quando i risultati cambiano. Al contrario, potrebbe essere meglio basarsi sul report generato e tenere traccia delle tendenze complessive dei punteggi di valutazione in scenari diversi nel tempo (e fallire solo le singole compilazioni qualora si verifichi un calo significativo dei punteggi di valutazione in più test differenti). Detto questo, c'è una certa sfumatura qui e la scelta di se convalidare singoli risultati o meno può variare a seconda del caso d'uso specifico.
Quando il metodo termina, l'oggetto
scenarioRunviene eliminato e il risultato della valutazione per la valutazione viene archiviato nell'archivio dei risultati (basato su disco) configurato ins_defaultReportingConfiguration.
Eseguire il test/valutazione
Eseguire il test usando il flusso di lavoro di test preferito, ad esempio usando il comando dell'interfaccia a riga di comando dotnet test o tramite Esplora Test.
Generare un report
Installare Microsoft.Extensions.AI.Evaluation.Console tool .NET eseguendo il comando seguente nella finestra del terminale:
dotnet tool install --create-manifest-if-needed Microsoft.Extensions.AI.Evaluation.ConsoleGenerare un report eseguendo il comando seguente:
dotnet tool run aieval report --path <path\to\your\cache\storage> --output report.htmlApri il file
report.html. Il report è simile allo screenshot seguente.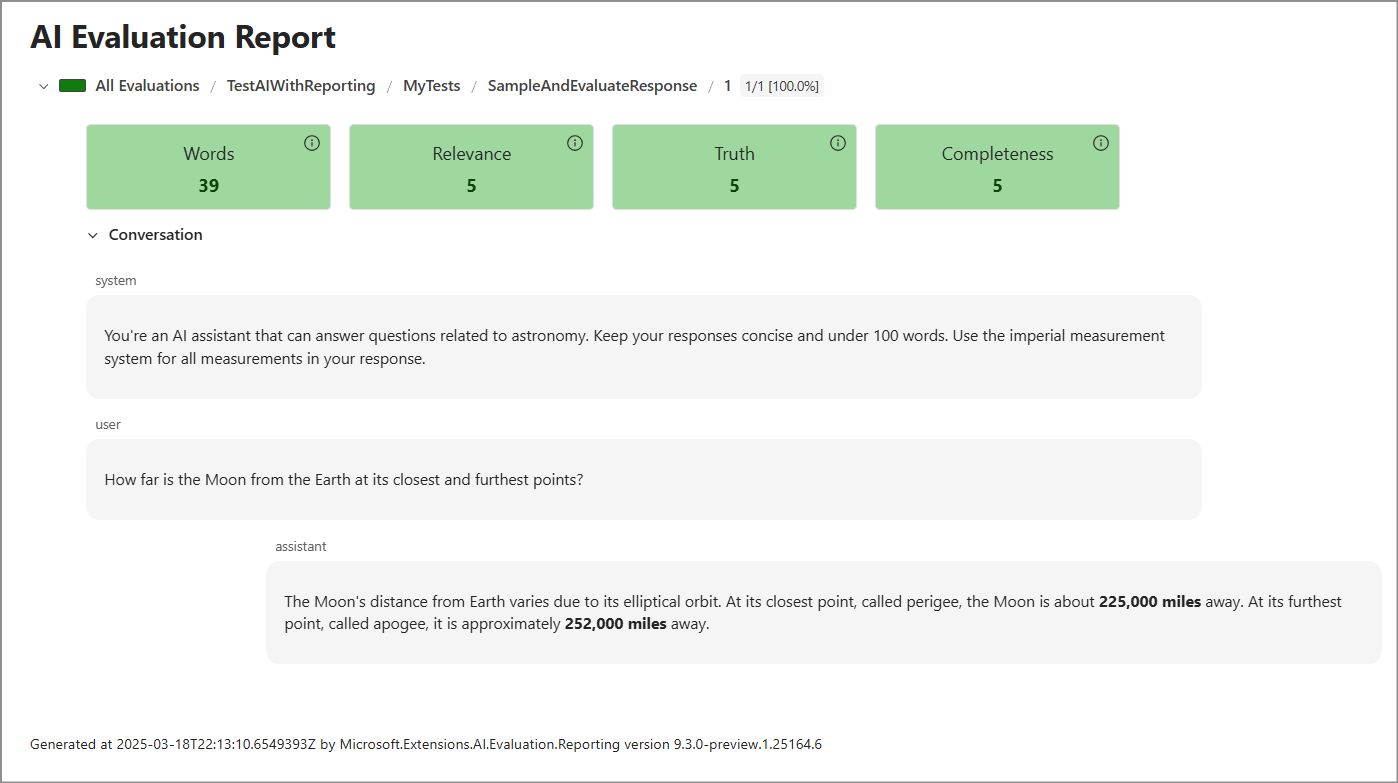
Passaggi successivi
- Passare alla directory in cui vengono archiviati i risultati del test , ovvero
C:\TestReports, a meno che non sia stata modificata la posizione al momento della creazione di ReportingConfiguration.resultsNella sottodirectory si noti che è presente una cartella per ogni esecuzione di test denominata con un timestamp (ExecutionName). All'interno di ognuna di queste cartelle è presente una cartella per ogni nome di scenario, in questo caso solo il singolo metodo di test nel progetto. Tale cartella contiene un file JSON con tutti i dati, inclusi i messaggi, la risposta e il risultato della valutazione. - Espandere la valutazione. Ecco un paio di idee:
- Aggiungere un altro analizzatore personalizzato, ad esempio un analizzatore che usa l'intelligenza artificiale per determinare il sistema di misurazione usato nella risposta.
- Aggiungere un altro metodo di test, ad esempio, un metodo che valuta più risposte dal LLM. Poiché ogni risposta può essere diversa, è consigliabile campionare e valutare almeno alcune risposte a una domanda. In questo caso, si specifica un nome di iterazione ogni volta che si chiama CreateScenarioRunAsync(String, String, IEnumerable<String>, IEnumerable<String>, CancellationToken).
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.