Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook Architecting Cloud Native .NET Applications for Azure, disponibile in .NET Docs o come PDF scaricabile gratuito che può essere letto offline.

Interrompere le operazioni e chiedere ai colleghi di definire il termine "Cloud Native". C'è una buona probabilità che si otterranno diverse risposte.
Si inizierà con una definizione semplice:
L'architettura e le tecnologie native del cloud sono un approccio alla progettazione, costruzione e gestione dei carichi di lavoro che sono realizzati nel cloud e sfruttano appieno il modello di cloud computing.
Cloud Native Computing Foundation fornisce la definizione ufficiale:
Le tecnologie native del cloud consentono alle organizzazioni di creare ed eseguire applicazioni scalabili in ambienti moderni e dinamici, ad esempio cloud pubblici, privati e ibridi. I contenitori, le mesh di servizi, i microservizi, l'infrastruttura non modificabile e le API dichiarative esemplificano questo approccio.
Queste tecniche consentono sistemi ad accoppiamento debole che sono resilienti, gestibili e osservabili. In combinazione con un'automazione affidabile, consentono ai tecnici di apportare modifiche ad alto impatto frequenti e prevedibili con fatica minima.
Il cloud nativo riguarda la velocità e l'agilità. I sistemi aziendali si stanno evolvendo dall'abilitazione delle capacità aziendali alle armi della trasformazione strategica che accelerano la velocità e la crescita aziendale. È fondamentale ottenere immediatamente nuove idee sul mercato.
Allo stesso tempo, i sistemi aziendali sono diventati sempre più complessi con gli utenti che richiedono di più. Si aspettano tempi di risposta rapidi, funzionalità innovative e tempi di inattività zero. I problemi di prestazioni, gli errori ricorrenti e l'impossibilità di spostarsi rapidamente non sono più accettabili. I tuoi utenti visiteranno il tuo concorrente. I sistemi nativi del cloud sono progettati per adottare cambiamenti rapidi, su larga scala e resilienza.
Ecco alcune aziende che hanno implementato tecniche native del cloud. Considerare la velocità, l'agilità e la scalabilità ottenute.
| Azienda | Esperienza |
|---|---|
| Netflix | Dispone di oltre 600 servizi in produzione. Distribuisce 100 volte al giorno. |
| Uber | Ha più di 1.000 servizi in produzione. Viene distribuito diverse migliaia di volte ogni settimana. |
| Dispone di oltre 3.000 servizi in produzione. Distribuisce 1.000 volte al giorno. |
Come puoi vedere, Netflix, Uber e WeChat espongono sistemi nativi del cloud costituiti da molti servizi indipendenti. Questo stile architettonico consente loro di rispondere rapidamente alle condizioni di mercato. Aggiornano istantaneamente piccole aree di un'applicazione dinamica, complessa, senza una ridistribuzione completa. Ridimensionano singolarmente i servizi in base alle esigenze.
I pilastri del cloud nativo
La velocità e l'agilità del cloud nativo derivano da molti fattori. In primo luogo, l'infrastruttura cloud. Ma c'è di più: altri cinque pilastri fondamentali illustrati nella figura 1-3 forniscono anche il fondamento per i sistemi nativi del cloud.
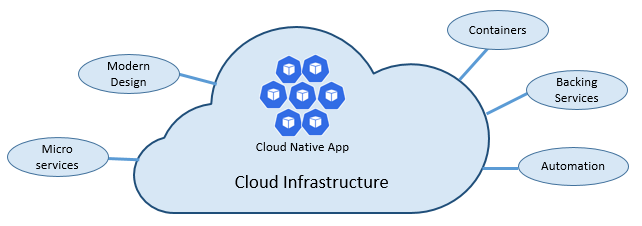
Figura 1-3. Pilastri fondamentali nativi del cloud
Diamo un po' di tempo per comprendere meglio il significato di ogni pilastro.
Il cloud
I sistemi nativi del cloud sfruttano appieno il modello di servizio cloud.
Progettato per prosperare in un ambiente cloud dinamico virtualizzato, questi sistemi usano ampiamente l'infrastruttura di calcolo PaaS (Platform as a Service) e i servizi gestiti. Considerano l'infrastruttura sottostante come usa e getta - fornita in pochi minuti e ridimensionata, espansa o eliminata su richiesta, tramite automazione.
Considera la differenza tra il modo in cui trattamo gli animali domestici e le materie prime. In un data center tradizionale, i server vengono trattati come animali domestici: un computer fisico, dato un nome significativo e curato. È possibile ridimensionare aggiungendo altre risorse allo stesso computer (aumento delle prestazioni). Se il server si ammala, lo curi fino a farlo tornare in salute. Se il server non sarà più disponibile, tutti notano.
Il modello di servizio delle materie prime è diverso. È possibile effettuare il provisioning di ogni istanza come macchina virtuale o contenitore. Sono identici e assegnati un identificatore di sistema, ad esempio Service-01, Service-02 e così via. È possibile ridimensionare creando più istanze (aumento del numero di istanze). Nessuno nota quando un'istanza non è più disponibile.
Il modello di materie prime abbraccia un'infrastruttura immutabile. I server non vengono ripristinati o modificati. Se qualcosa fallisce o richiede un aggiornamento, viene distrutto e ne viene creato uno nuovo, il tutto eseguito automaticamente.
I sistemi nativi del cloud abbracciano il modello di servizio delle materie prime. Continuano a funzionare man mano che l'infrastruttura viene espansa o ridotta, senza tener conto dei computer su cui sono in esecuzione.
La piattaforma cloud di Azure supporta questo tipo di infrastruttura altamente elastica con scalabilità automatica, riparazione automatica e funzionalità di monitoraggio.
Design moderno
Come si progetta un'app nativa del cloud? Che aspetto dovrebbe avere l'architettura? A quali principi, modelli e procedure consigliate si dovrebbe rispettare? Quali problemi di infrastruttura e operativi sarebbero importanti?
Applicazione Twelve-Factor
Una metodologia ampiamente accettata per la costruzione di applicazioni basate sul cloud è l'applicazioneTwelve-Factor. Descrive un set di principi e procedure che gli sviluppatori seguono per costruire applicazioni ottimizzate per ambienti cloud moderni. Particolare attenzione viene prestata alla portabilità tra ambienti e automazione dichiarativa.
Anche se applicabile a qualsiasi applicazione basata sul Web, molti professionisti considerano Twelve-Factor una solida base per la creazione di app native del cloud. I sistemi basati su questi principi possono distribuire e ridimensionare rapidamente e aggiungere funzionalità per reagire rapidamente ai cambiamenti di mercato.
La tabella seguente evidenzia la metodologia di Twelve-Factor:
| Fattore | Spiegazione |
|---|---|
| 1 - CodeBase | Una singola codebase per ogni microservizio, archiviata nel proprio repository. Tracciato con controllo di versione, può essere distribuito in diversi ambienti (QA, Staging, Produzione). |
| 2 - Dipendenze | Ogni microservizio isola e impacchetta le proprie dipendenze, abbracciando le modifiche senza influire sull'intero sistema. |
| 3 - Configurazioni | Le informazioni di configurazione vengono spostate dal microservizio ed esterne tramite uno strumento di gestione della configurazione all'esterno del codice. La stessa distribuzione può propagarsi in ambienti con la configurazione corretta applicata. |
| 4 - Servizi di backup | Le risorse ausiliarie (archivi dati, cache, broker di messaggi) devono essere esposte tramite un URL indirizzabile. In questo modo la risorsa viene disaccoppiata dall'applicazione, rendendola intercambiabile. |
| 5 - Compilazione, Rilascio, Esecuzione | Ogni versione deve applicare una separazione rigorosa tra le fasi di compilazione, rilascio ed esecuzione. Ognuno deve essere contrassegnato con un ID univoco e deve supportare la capacità di eseguire il rollback. I sistemi CI/CD moderni consentono di soddisfare questo principio. |
| 6 - Processi | Ogni microservizio deve essere eseguito nel proprio processo, isolato da altri servizi in esecuzione. Esternalizzare lo stato necessario a un servizio di backup, ad esempio una cache distribuita o un archivio dati. |
| 7 - Collegamento delle porte | Ogni microservizio deve essere indipendente con le relative interfacce e funzionalità esposte sulla propria porta. In questo modo viene fornito l'isolamento da altri microservizi. |
| 8 - Concorrenza | Quando la capacità deve aumentare, scalare orizzontalmente i servizi tra più processi identici (copie) anziché aumentare le prestazioni di un'istanza singola e di grandi dimensioni sulla macchina più potente disponibile. Sviluppare l'applicazione in modo che sia simultaneamente scalabile in ambienti cloud senza problemi. |
| 9 - Disposabilità | Le istanze del servizio devono essere eliminabili. Favorire l'avvio rapido per aumentare le opportunità di scalabilità e gli arresti graduali per lasciare il sistema in uno stato corretto. I contenitori Docker insieme a un agente di orchestrazione soddisfano intrinsecamente questo requisito. |
| 10 - Parità Dev/Prod | Mantenere gli ambienti nel ciclo di vita dell'applicazione il più simili possibile, evitando costose scorciatoie. In questo caso, l'adozione di contenitori può contribuire notevolmente promuovendo lo stesso ambiente di esecuzione. |
| 11 - Registrazione | Considerare i log generati dai microservizi come flussi di eventi. Elaborarli con un aggregatore di eventi. Propagare i dati di log agli strumenti di gestione dei log e data mining, come Azure Monitor o Splunk, e infine per l'archiviazione a lungo termine. |
| 12 - Processi amministrativi | Eseguire attività amministrative/di gestione, ad esempio la pulizia dei dati o l'analisi del calcolo, come processi occasionali. Usare strumenti indipendenti per richiamare queste attività dall'ambiente di produzione, ma separatamente dall'applicazione. |
Nel libro , Beyond the Twelve-Factor App, l'autore Kevin Hoffman dettaglia ognuno dei 12 fattori originali (scritto nel 2011). Inoltre, illustra tre fattori aggiuntivi che riflettono la progettazione moderna delle applicazioni cloud.
| Nuovo fattore | Spiegazione |
|---|---|
| 13 - API First | Trasformare tutto in un servizio. Si supponga che il codice venga usato da un client front-end, un gateway o un altro servizio. |
| 14 - Telemetria | In una workstation si ha una visibilità approfondita sull'applicazione e sul relativo comportamento. Nel cloud, non lo fai. Assicurati che la progettazione includa la raccolta di dati di monitoraggio, specifici del dominio e di stato del sistema. |
| 15 - Autenticazione/Autorizzazione | Implementare l'identità dall'inizio. Prendere in considerazione le funzionalità RBAC (controllo degli accessi basato sui ruoli) disponibili nei cloud pubblici. |
In questo capitolo e in tutto il libro, si farà riferimento a molti dei 12+ fattori.
Azure Well-Architected Framework
La progettazione e la distribuzione di carichi di lavoro basati sul cloud possono risultare difficili, soprattutto quando si implementa un'architettura nativa del cloud. Microsoft offre procedure consigliate standard di settore per aiutare l'utente e il team a offrire soluzioni cloud affidabili.
Microsoft Well-Architected Framework offre un set di set di principi guida che possono essere usati per migliorare la qualità di un carico di lavoro nativo del cloud. Il framework è costituito da cinque pilastri dell'eccellenza dell'architettura:
| Principi | Descrizione |
|---|---|
| Gestione costi | Concentrarsi sulla generazione anticipata del valore incrementale. Applicare i principi Build-Measure-Learn per accelerare il time-to-market evitando soluzioni a elevato utilizzo di capitale. Usando una strategia con pagamento in base al consumo, investire mentre si scala, piuttosto che fare un grande investimento in anticipo. |
| Eccellenza operativa | Automatizzare l'ambiente e le operazioni per aumentare la velocità e ridurre l'errore umano. Eseguire rapidamente il rollback o l'avanzamento degli aggiornamenti dei problemi. Implementare il monitoraggio e la diagnostica fin dall'inizio. |
| Efficienza prestazionale | Soddisfare in modo efficiente le richieste dei carichi di lavoro. Favorire la scalabilità orizzontale e integrarla nei vostri sistemi. Eseguire continuamente test di prestazioni e carico per identificare potenziali colli di bottiglia. |
| Affidabilità | Creare carichi di lavoro resilienti e disponibili. La resilienza consente ai carichi di lavoro di eseguire il ripristino da errori e continuare a funzionare. La disponibilità garantisce agli utenti l'accesso al carico di lavoro in qualsiasi momento. Progettare applicazioni per aspettarsi errori e ripristinarli. |
| sicurezza | Implementare la sicurezza nell'intero ciclo di vita di un'applicazione, dalla progettazione e dall'implementazione alla distribuzione e alle operazioni. Prestare particolare attenzione alla gestione delle identità, all'accesso all'infrastruttura, alla sicurezza delle applicazioni e alla sovranità e alla crittografia dei dati. |
Per iniziare, Microsoft offre un set di valutazioni online che consentono di valutare i carichi di lavoro cloud correnti rispetto ai cinque pilastri ben strutturati.
Microservizi
I sistemi nativi del cloud adottano i microservizi, uno stile architetturale diffuso per la costruzione di applicazioni moderne.
Creato come set distribuito di servizi di piccole dimensioni indipendenti che interagiscono tramite un'infrastruttura condivisa, i microservizi condividono le caratteristiche seguenti:
Ognuna implementa una funzionalità aziendale specifica all'interno di un contesto di dominio più ampio.
Ognuno viene sviluppato in modo autonomo e può essere distribuito in modo indipendente.
Ognuno di essi incapsula la propria tecnologia di archiviazione dei dati, le dipendenze e la piattaforma di programmazione.
Ogni esecuzione viene eseguita nel proprio processo e comunica con altri utenti usando protocolli di comunicazione standard, ad esempio HTTP/HTTPS, gRPC, WebSocket o AMQP.
Compongono insieme per formare un'applicazione.
La figura 1-4 contrasta un approccio applicativo monolitico con un approccio basato su microservizi. Si noti che il monolith è costituito da un'architettura a più livelli, che viene eseguita in un singolo processo. In genere utilizza un database relazionale. L'approccio al microservizio, tuttavia, separa le funzionalità in servizi indipendenti, ognuno con la propria logica, stato e dati. Ogni microservizio ospita il proprio archivio dati.
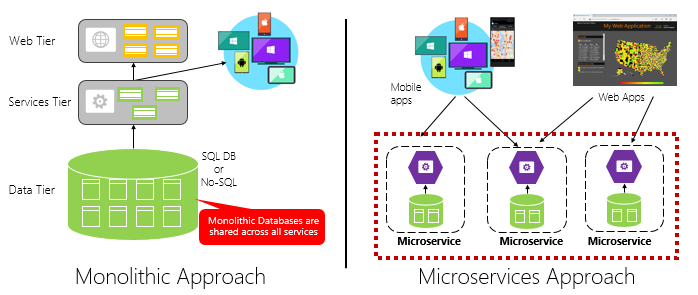
Figura 1-4. Architettura monolitica e microservizi
Si noti come i microservizi promuovono il principio Dei processi dall'applicazioneTwelve-Factor, descritta in precedenza nel capitolo .
Fattore 6 specifica "Ogni microservizio deve essere eseguito nel proprio processo, isolato da altri servizi in esecuzione".
Perché i microservizi?
I microservizi offrono agilità.
In precedenza nel capitolo è stata confrontata un'applicazione e-commerce creata come monolitica con i microservizi. Nell'esempio sono stati illustrati alcuni vantaggi chiari:
Ogni microservizio ha un ciclo di vita autonomo e può evolversi in modo indipendente e distribuirsi di frequente. Non è necessario attendere una versione trimestrale per distribuire una nuova funzionalità o un aggiornamento. È possibile aggiornare una piccola area di un'applicazione in tempo reale con meno rischio di interrompere l'intero sistema. L'aggiornamento può essere eseguito senza una ridistribuzione completa dell'applicazione.
Ogni microservizio può essere ridimensionato in modo indipendente. Invece di ridimensionare l'intera applicazione come singola unità, si aumentano solo i servizi che richiedono una maggiore potenza di elaborazione per soddisfare i livelli di prestazioni desiderati e i contratti di servizio. La scalabilità con granularità fine offre un maggiore controllo del sistema e consente di ridurre i costi complessivi man mano che si ridimensionano parti del sistema, non tutto.
Una guida di riferimento eccellente per comprendere i microservizi è .NET Microservices: Architecture for Containerized .NET Applications (Architettura per applicazioni .NET in contenitori). Il libro approfondisce la progettazione e l'architettura dei microservizi. È un complemento a un'architettura di riferimento di microservizi full-stack disponibile per il download gratuito da Microsoft.
Sviluppo di microservizi
È possibile creare microservizi in qualsiasi piattaforma di sviluppo moderna.
La piattaforma Microsoft .NET è un'ottima scelta. Gratuito e open source, include molte funzionalità predefinite che semplificano lo sviluppo di microservizi. .NET è multipiattaforma. Le applicazioni possono essere compilate ed eseguite in Windows, macOS e la maggior parte dei tipi di Linux.
.NET offre prestazioni elevate e ha ottenuto punteggi elevati rispetto a Node.js e ad altre piattaforme concorrenti. È interessante notare che TechEmpower ha condotto un ampio set di benchmark delle prestazioni in molte piattaforme e framework di applicazioni Web. .NET ha ottenuto punteggi nella top 10, ben oltre Node.js e altre piattaforme concorrenti.
.NET viene gestito da Microsoft e dalla community .NET su GitHub.
Problemi relativi ai microservizi
Sebbene i microservizi nativi del cloud distribuiti possano offrire un'enorme agilità e velocità, presentano molte sfide:
Comunicazione
In che modo le applicazioni client front-end comunicheranno con i microservizi core di cui è stato eseguito il backup? Consentirà la comunicazione diretta? In alternativa, è possibile astrarre i microservizi back-end con un gateway che offre flessibilità, controllo e sicurezza?
In che modo i microservizi core back-end comunicano tra loro? È possibile consentire chiamate HTTP dirette che possono aumentare l'accoppiamento e influire sulle prestazioni e sull'agilità? Oppure è possibile considerare la messaggistica disaccoppiata con tecnologie di accodamento e argomenti?
La comunicazione è illustrata nel capitolo Modelli di comunicazione nativi del cloud .
Resilienza
Un'architettura di microservizi sposta il tuo sistema dalla comunicazione nel processo a quella fuori dal processo. In un'architettura distribuita, cosa accade quando il servizio B non risponde a una chiamata di rete dal servizio A? In alternativa, cosa accade quando il servizio C diventa temporaneamente non disponibile e altri servizi che lo chiamano diventano bloccati?
La resilienza è illustrata nel capitolo Resilienza nativa del cloud .
Dati distribuiti
Per impostazione predefinita, ogni microservizio incapsula i propri dati, esponendo le operazioni tramite l'interfaccia pubblica. In tal caso, come eseguire query sui dati o implementare una transazione tra più servizi?
I dati distribuiti sono trattati nel capitolo Modelli di dati nativi del cloud .
Segreti
In che modo i microservizi archivieranno e gestiranno in modo sicuro i segreti e i dati di configurazione sensibili?
I segreti vengono trattati in dettaglio sulla sicurezza nativa del cloud.
Gestire la complessità con Dapr
Dapr è un runtime di applicazioni open source distribuito. Grazie a un'architettura di componenti collegabili, semplifica notevolmente l'impianto idraulico dietro le applicazioni distribuite. Fornisce un collante dinamico che collega l'applicazione a funzionalità infrastrutturali e componenti predefiniti dal runtime Dapr. La figura 1-5 mostra Dapr da 20.000 piedi.
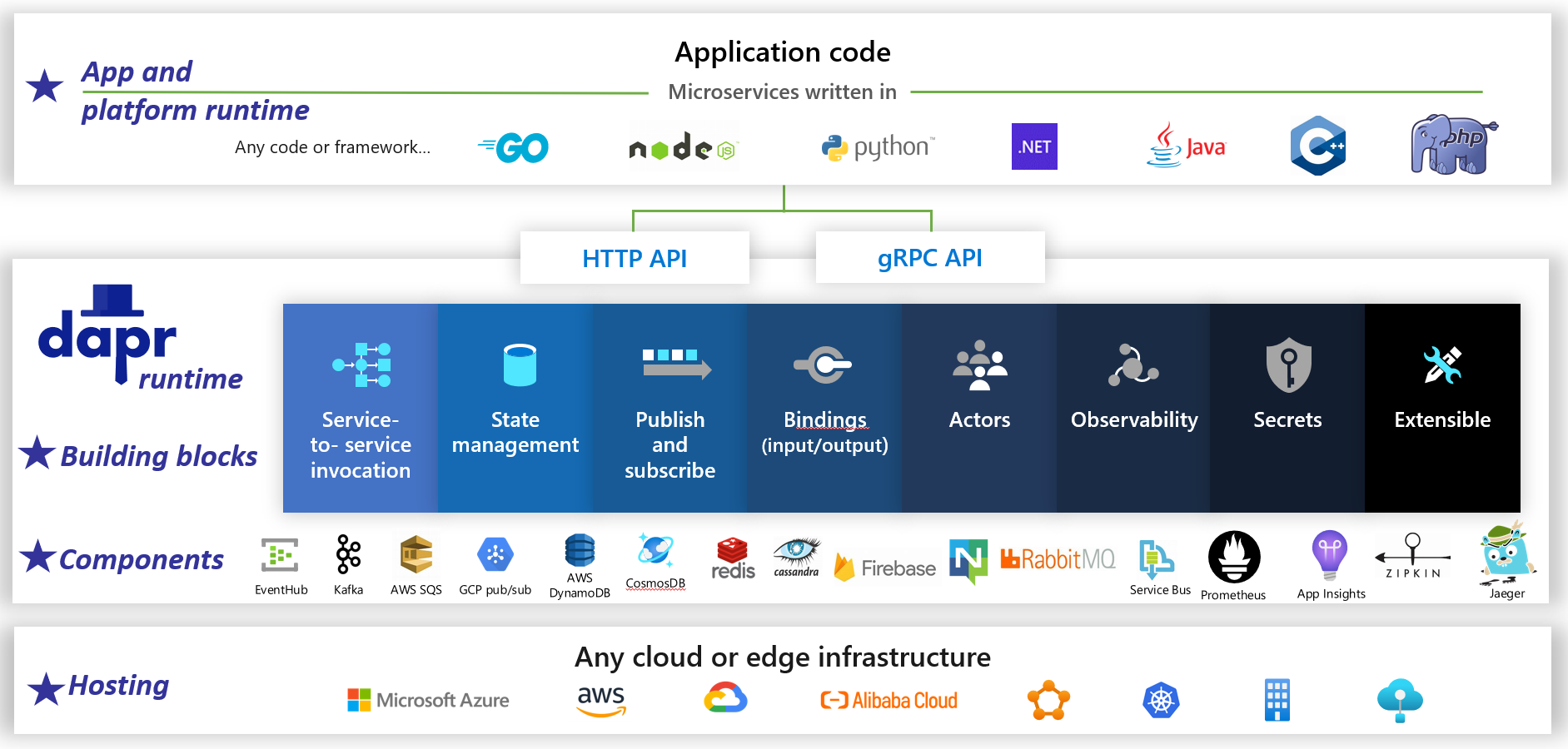 figura 1-5. Dapr a 20.000 piedi.
figura 1-5. Dapr a 20.000 piedi.
Nella riga superiore della figura si noti come Dapr fornisce SDK specifici del linguaggio per le piattaforme di sviluppo più diffuse. Dapr v1 include il supporto per .NET, Go, Node.js, Python, PHP, Java e JavaScript.
Anche se gli SDK specifici del linguaggio migliorano l'esperienza di sviluppo, Dapr è indipendente dalla piattaforma. Dietro le quinte, il modello di programmazione di Dapr espone le funzionalità tramite protocolli di comunicazione HTTP/gRPC standard. Qualsiasi piattaforma di programmazione può chiamare Dapr tramite le API HTTP e gRPC native.
Le caselle blu al centro della figura rappresentano i blocchi fondamentali di Dapr. Ognuno espone il codice di idraulica predefinito per una funzionalità di applicazione distribuita che l'applicazione può utilizzare.
La riga dei componenti rappresenta un ampio set di componenti dell'infrastruttura predefiniti che l'applicazione può utilizzare. Si pensi ai componenti come al codice dell'infrastruttura che non è necessario scrivere.
La riga inferiore evidenzia la portabilità di Dapr e i diversi ambienti in cui può essere eseguito.
Guardando avanti, Dapr ha il potenziale di avere un impatto profondo sullo sviluppo di applicazioni native del cloud.
Contenitori
È naturale sentire il termine contenitore menzionato in qualsiasi conversazione nativa del cloud . Nel libro Cloud Native Patterns, l'autore Cornelia Davis osserva che "i contenitori sono un ottimo strumento di abilitazione del software nativo del cloud". Cloud Native Computing Foundation inserisce la containerizzazione di microservizi come primo passaggio della mappa trailCloud-Native per le aziende che iniziano il percorso nativo del cloud.
{kind=link}
La creazione di contenitori di un microservizio è semplice e semplice. Il codice, le relative dipendenze e il runtime vengono inseriti in un pacchetto binario denominato immagine del contenitore. Le immagini vengono archiviate in un registro contenitori, che funge da repository o libreria per le immagini. Un registro può trovarsi nel computer di sviluppo, nel data center o in un cloud pubblico. Docker gestisce un registro pubblico tramite l'hub Docker. Il cloud di Azure offre un registro contenitori privato per archiviare le immagini del contenitore vicino alle applicazioni cloud che le eseguiranno.
Quando un'applicazione viene avviata o ridimensionata, si trasforma l'immagine del contenitore in un'istanza del contenitore in esecuzione. L'istanza viene eseguita su qualsiasi computer in cui è installato un motore runtime dei container. È possibile avere il numero di istanze del servizio in contenitori in base alle esigenze.
La figura 1-6 mostra tre microservizi diversi, ognuno nel proprio contenitore, tutti in esecuzione in un singolo host.
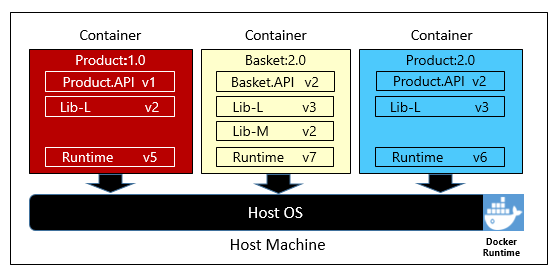
Figura 1-6. Più contenitori in esecuzione in un host contenitore
Si noti come ogni contenitore gestisce il proprio set di dipendenze e runtime, che possono essere diversi l'uno dall'altro. In questo caso vengono visualizzate versioni diverse del microservizio Product in esecuzione nello stesso host. Ogni contenitore condivide una sezione del sistema operativo host sottostante, della memoria e del processore, ma è isolata l'una dall'altra.
Nota come il modello di contenitore abbraccia il principio Dependencies dall'applicazione Twelve-Factor.
Fattore 2 specifica che "Ogni microservizio isola e impacchetta le proprie dipendenze, adottando le modifiche senza influire sull'intero sistema".
I contenitori supportano sia carichi di lavoro Linux che Windows. Il cloud di Azure abbraccia apertamente entrambi. È interessante notare che è Linux, non Windows Server, che è diventato il sistema operativo più diffuso in Azure.
Anche se esistono diversi fornitori di contenitori, Docker ha acquisito la maggior parte del mercato. L'azienda ha guidato il movimento dei container software. È diventato lo standard di fatto per la creazione di pacchetti, la distribuzione e l'esecuzione di applicazioni native del cloud.
Perché i contenitori?
I contenitori offrono portabilità e garantiscono la coerenza tra ambienti. Incapsulando tutto in un singolo pacchetto, si isolano il microservizio e le relative dipendenze dall'infrastruttura sottostante.
È possibile distribuire il contenitore in qualsiasi ambiente che ospita il motore di runtime Docker. I carichi di lavoro in contenitori eliminano anche i costi di preconfigurazione di ogni ambiente con framework, librerie software e motori di runtime.
Condividendo il sistema operativo sottostante e le risorse host, un contenitore ha un footprint molto inferiore rispetto a una macchina virtuale completa. Le dimensioni minori aumentano la densità, o il numero di microservizi che un specifico host può eseguire contemporaneamente.
Orchestrazione dei contenitori
Anche se gli strumenti come Docker creano immagini ed eseguono contenitori, sono necessari anche strumenti per gestirli. La gestione dei contenitori viene eseguita con un programma software speciale denominato agente di orchestrazione del contenitore. Quando si opera su larga scala con molti contenitori indipendenti in esecuzione, l'orchestrazione è essenziale.
La figura 1-7 mostra le attività di gestione che gli agenti di orchestrazione dei contenitori automatizzano.
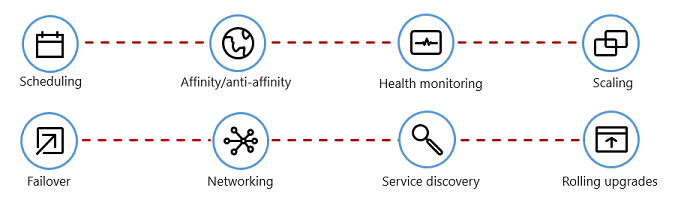
Figura 1-7. Cosa fanno gli orchestratori di container
Nella tabella seguente vengono descritte le attività di orchestrazione comuni.
| Attività | Spiegazione |
|---|---|
| Pianificazione | Effettuare automaticamente il provisioning delle istanze del contenitore. |
| Affinità/anti-affinità | Gestire contenitori in prossimità o distanziali tra loro, ottimizzando la disponibilità e le prestazioni. |
| Monitoraggio dell’integrità | Rilevare e correggere automaticamente gli errori. |
| Ripristino automatico | Riassegnare automaticamente un'istanza non riuscita a una macchina sana. |
| Scalabilità | Aggiungere o rimuovere automaticamente un'istanza di contenitore per soddisfare la domanda. |
| Rete | Gestire un overlay di rete per la comunicazione tra container. |
| Individuazione dei servizi | Abilitare i contenitori per individuarsi tra loro. |
| Aggiornamenti progressivi | Coordinare gli aggiornamenti incrementali con un'implementazione senza interruzioni. Eseguire automaticamente il rollback delle modifiche problematiche. |
Si noti che gli orchestratori di container adottano i principi di disponibilità e di concorrenza dall'applicazioneTwelve-Factor.
Fattore 9 specifica che "Le istanze del servizio devono essere temporanee, favorendo avvii rapidi per aumentare le opportunità di scalabilità e arresti graduali per lasciare il sistema in uno stato corretto". I contenitori Docker insieme a un orchestratore soddisfano intrinsecamente questo requisito".
Factor #8 specifica che "i servizi vengono ridimensionati in un numero elevato di piccoli processi identici (copie) anziché aumentare le prestazioni di una singola istanza di grandi dimensioni nel computer più potente disponibile".
Sebbene esistano diversi agenti di orchestrazione dei contenitori, Kubernetes è diventato lo standard di fatto per il mondo nativo del cloud. Si tratta di una piattaforma open source portatile ed estendibile per la gestione dei carichi di lavoro in contenitori.
È possibile ospitare la propria istanza di Kubernetes, ma quindi si sarebbe responsabili del provisioning e della gestione delle relative risorse, che possono essere complesse. Il cloud di Azure offre Kubernetes come servizio gestito. Sia il servizio Azure Kubernetes cheAzure Red Hat OpenShift (ARO) consentono di sfruttare appieno le funzionalità e la potenza di Kubernetes come servizio gestito, senza dover installarla e gestirla.
L'orchestrazione dei contenitori è descritta in dettaglio in Ridimensionamento delle applicazioni Cloud-Native.
Servizi di backup
I sistemi nativi del cloud dipendono da molte risorse ausiliarie diverse, ad esempio archivi dati, broker di messaggi, monitoraggio e servizi di gestione delle identità. Questi servizi sono noti come servizi di backup.
La figura 1-8 mostra molti servizi di supporto comuni usati dai sistemi nativi del cloud.
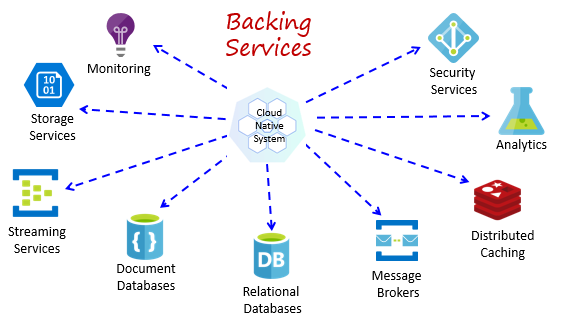
Figura 1-8. Servizi di backup comuni
È possibile ospitare i propri servizi di backup, ma quindi si sarebbe responsabili delle licenze, del provisioning e della gestione di tali risorse.
I provider di servizi cloud offrono un'ampia gamma di servizi di backup gestiti. Invece di possedere il servizio, è sufficiente utilizzarlo. Il provider di servizi cloud gestisce la risorsa su larga scala e ha la responsabilità di prestazioni, sicurezza e manutenzione. Il monitoraggio, la ridondanza e la disponibilità sono integrati nel servizio. I provider garantiscono prestazioni a livello di servizio e supportano completamente i servizi gestiti: aprire un ticket e risolvere il problema.
I sistemi nativi del cloud favoriscono i servizi di backup gestiti dai fornitori di servizi cloud. Il risparmio nel tempo e nel lavoro può essere significativo. Il rischio operativo di ospitare i propri servizi e incontrare problemi può diventare costoso rapidamente.
Una procedura consigliata consiste nel considerare un servizio di backup come risorsa collegata, associato dinamicamente a un microservizio con informazioni di configurazione (URL e credenziali) archiviate in una configurazione esterna. Queste linee guida sono descritte nella Twelve-Factor Applicazione, descritta in precedenza nel capitolo.
Factor #4 specifica che i servizi di backup "devono essere esposti tramite un URL indirizzabile. In questo modo la risorsa viene disaccoppiata dall'applicazione, consentendo l'interscambio".
Fattore 3 specifica che "Le informazioni di configurazione vengono spostate dal microservizio ed esterne tramite uno strumento di gestione della configurazione all'esterno del codice".
Con questo modello, un servizio di backup può essere collegato e scollegato senza modifiche al codice. È possibile alzare di livello un microservizio dal controllo di qualità a un ambiente di staging. È possibile aggiornare la configurazione del microservizio in modo che punti ai servizi di backup nella gestione temporanea e inserire le impostazioni nel contenitore tramite una variabile di ambiente.
I fornitori di servizi cloud forniscono API per comunicare con i servizi di backup proprietari. Queste librerie incapsulano l'idraulica proprietaria e la complessità. Tuttavia, la comunicazione diretta con queste API associa strettamente il codice a tale servizio di backup specifico. È una pratica ampiamente accettata per isolare i dettagli di implementazione dell'API del fornitore. È possibile introdurre un livello di intermediazione o un'API intermedia, esponendo operazioni generiche al codice del servizio e incapsulare il codice del fornitore al suo interno. Questo accoppiamento libero consente di scambiare un servizio di backup per un altro o spostare il codice in un ambiente cloud diverso senza dover apportare modifiche al codice del servizio mainline. Dapr, illustrato in precedenza, segue questo modello con il set di blocchi predefiniti.
Su un pensiero finale, i servizi di backup promuovono anche il principio di inattività dell'applicazioneTwelve-Factor, discussa in precedenza nel capitolo.
Fattore 6 specifica che ogni microservizio deve essere eseguito nel proprio processo, isolato da altri servizi in esecuzione. Esternalizzare lo stato necessario a un servizio di backup, ad esempio una cache distribuita o un archivio dati."
I servizi di backup sono descritti in Modelli di dati nativi del cloud e modelli di comunicazione nativi del cloud.
Automazione
Come si è visto, i sistemi nativi del cloud adottano microservizi, contenitori e progettazione moderna del sistema per ottenere velocità e agilità. Ma questa è solo parte della storia. Come si effettua il provisioning degli ambienti cloud su cui vengono eseguiti questi sistemi? Come si distribuiscono rapidamente le funzionalità e gli aggiornamenti delle app? Come si completa l'immagine completa?
Immettere la pratica ampiamente accettata dell'infrastruttura come codice o IaC.
Con IaC, è possibile automatizzare il provisioning della piattaforma e la distribuzione di applicazioni. Si applicano essenzialmente procedure di progettazione software, ad esempio test e controllo delle versioni alle procedure DevOps. L'infrastruttura e le distribuzioni sono automatizzate, coerenti e ripetibili.
Automazione dell'infrastruttura
Gli strumenti come Azure Resource Manager, Azure Bicep, Terraform di HashiCorp e l'interfaccia della riga di comando di Azure consentono di creare uno script dichiarativo dell'infrastruttura cloud necessaria. I nomi delle risorse, le posizioni, le capacità e i segreti sono parametrizzati e dinamici. Lo script viene sottoposto a controllo delle versioni e archiviato nel controllo del codice sorgente come artefatto del progetto. Invocare lo script per eseguire il provisioning di un'infrastruttura coerente e ripetibile in ambienti di sistema, come QA, Staging e Produzione.
Sotto le quinte, IaC è idempotente, vale a dire che è possibile eseguire lo stesso script su e oltre senza effetti collaterali. Se il team deve apportare una modifica, modifica e riesegui lo script. Sono interessate solo le risorse aggiornate.
Nell'articolo Che cos'è l'infrastruttura come codice, l'autore Sam Guckenheimer descrive come i team che implementano IaC possano offrire ambienti stabili rapidamente e su larga scala. Evitano la configurazione manuale degli ambienti e applicano la coerenza rappresentando lo stato desiderato degli ambienti tramite codice. Le distribuzioni dell'infrastruttura con IaC sono ripetibili e impediscono problemi di runtime causati dalla deriva della configurazione o dalle dipendenze mancanti. I team DevOps possono collaborare con un set unificato di procedure e strumenti per distribuire applicazioni e l'infrastruttura di supporto rapidamente, in modo affidabile e su larga scala".
Automazione delle distribuzioni
L'applicazioneTwelve-Factor, descritta in precedenza, richiede passaggi separati durante la trasformazione del codice completato in un'applicazione in esecuzione.
Fattore 5 specifica che "Ogni versione deve applicare una separazione rigorosa tra le fasi di compilazione, rilascio ed esecuzione. Ciascuno deve essere contrassegnato con un ID univoco e deve supportare la capacità di eseguire il rollback.
I sistemi CI/CD moderni consentono di soddisfare questo principio. Forniscono passaggi di compilazione e recapito separati che consentono di garantire codice coerente e qualitativo facilmente disponibile per gli utenti.
La figura 1-9 mostra la separazione attraverso il processo di distribuzione.
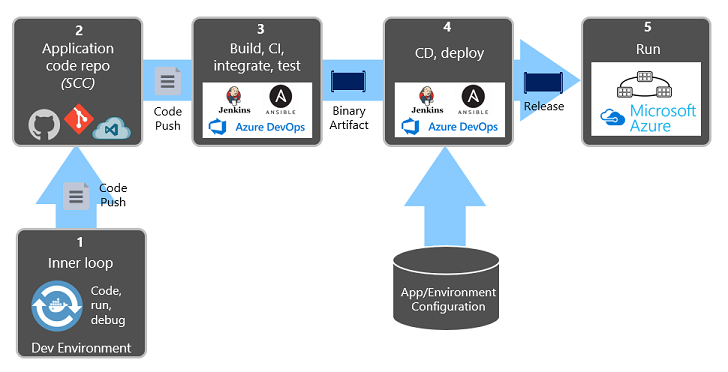
Figura 1-9. Passaggi di implementazione in una pipeline CI/CD
Nella figura precedente prestare particolare attenzione alla separazione delle attività:
- Lo sviluppatore costruisce una funzionalità nell'ambiente di sviluppo, iterando il cosiddetto "ciclo interno" di codice, esecuzione e debug.
- Al termine, il codice viene inserito in un repository di codice, ad esempio GitHub, Azure DevOps o BitBucket.
- Il push attiva una fase di compilazione che trasforma il codice in un artefatto binario. Il lavoro viene implementato con una pipeline di integrazione continua (CI). Compila, testa e crea automaticamente pacchetti dell'applicazione.
- La fase di rilascio preleva l'artefatto binario, applica informazioni di configurazione dell'applicazione e dell'ambiente esterne e produce una versione non modificabile. La versione viene distribuita in un ambiente specificato. Il lavoro viene implementato con una pipeline di Continuous Delivery (CD). Ogni versione deve essere identificabile. Si può dire: "Questa distribuzione esegue la versione 2.1.1 dell'applicazione".
- Infine, la funzionalità rilasciata viene eseguita nell'ambiente di esecuzione di destinazione. Le versioni non sono modificabili, ovvero qualsiasi modifica deve creare una nuova versione.
L'applicazione di queste procedure, le organizzazioni hanno radicalmente evoluto il modo in cui distribuiscono software. Molti sono passati da versioni trimestrali a aggiornamenti su richiesta. L'obiettivo è rilevare i problemi all'inizio del ciclo di sviluppo quando sono meno costosi da risolvere. Più lunga è la durata tra le integrazioni, i problemi più costosi diventano da risolvere. Con coerenza nel processo di integrazione, i team possono eseguire il commit delle modifiche al codice più frequentemente, con conseguente migliore collaborazione e qualità del software.
L'infrastruttura come automazione del codice e della distribuzione, insieme a GitHub e Azure DevOps, è descritta in dettaglio in DevOps.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.