Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook, Architettura di microservizi .NET per applicazioni .NET containerizzati, disponibile in documentazione .NET o come PDF scaricabile gratuitamente leggibile offline.

La gestione di errori imprevisti è uno dei problemi più difficili da risolvere, soprattutto in un sistema distribuito. Gran parte del codice scritto dagli sviluppatori comporta la gestione delle eccezioni e questo è anche il momento in cui il maggior tempo è dedicato ai test. Il problema è più coinvolto rispetto alla scrittura di codice per gestire gli errori. Cosa accade quando il computer in cui è in esecuzione il microservizio ha esito negativo? Non solo è necessario rilevare questo errore di microservizio (un problema difficile da solo), ma è necessario anche un elemento per riavviare il microservizio.
Un microservizio deve essere resiliente agli errori e poter essere in grado di riavviare spesso in un altro computer per la disponibilità. Questa resilienza dipende anche dallo stato salvato per conto del microservizio, da cui il microservizio può recuperare questo stato e dal fatto che il microservizio possa essere riavviato correttamente. In altre parole, è necessario avere resilienza nella funzionalità di calcolo (il processo può essere riavviato in qualsiasi momento), nonché resilienza nello stato o nei dati (senza perdita di dati e i dati rimangono coerenti).
I problemi di resilienza vengono aggravati durante scenari come quando si verificano guasti durante un aggiornamento dell'applicazione. Il microservizio, che usa il sistema di distribuzione, deve determinare se può continuare a passare alla versione più recente o eseguire invece il rollback a una versione precedente per mantenere uno stato coerente. È necessario prendere in considerazione domande quali se sono disponibili macchine sufficienti per continuare e come ripristinare le versioni precedenti del microservizio. Questo approccio richiede al microservizio di generare informazioni sull'integrità in modo che l'applicazione nel suo complesso e l'agente di orchestrazione possano adottare queste decisioni.
Inoltre, la resilienza è correlata al comportamento dei sistemi basati sul cloud. Come accennato, un sistema basato sul cloud deve accettare i guasti e deve cercare di recuperare da essi automaticamente. Ad esempio, in caso di errori di rete o contenitori, le app client o i servizi client devono avere una strategia per riprovare a inviare messaggi o ripetere le richieste, poiché in molti casi gli errori nel cloud sono parziali. La sezione Implementazione di applicazioni resilienti in questa guida illustra come gestire un errore parziale. Descrive tecniche come i tentativi con backoff esponenziale o il modello di interruttore in .NET usando librerie come Polly, che offre un'ampia gamma di criteri per gestire questo argomento.
Gestione della salute e diagnostica nei microservizi
Può sembrare ovvio ed è spesso trascurato, ma un microservizio deve segnalarne lo stato di salute e la diagnostica. In caso contrario, non è possibile ottenere informazioni dettagliate dal punto di vista delle operazioni. Correlare gli eventi di diagnostica in un set di servizi indipendenti e gestire gli sfasamenti dell'orologio del computer per avere un senso dell'ordine degli eventi è difficile. Allo stesso modo in cui si interagisce con un microservizio su protocolli e formati di dati concordati, è necessario standardizzare come registrare gli eventi di integrità e diagnostica che alla fine finiscono in un archivio eventi per l'esecuzione di query e la visualizzazione. In un approccio basato su microservizi, è fondamentale che i diversi team siano d'accordo su un singolo formato di registrazione. È necessario un approccio coerente alla visualizzazione degli eventi di diagnostica nell'applicazione.
Controlli di salute
La salute è diversa dalla diagnostica. La salute è il microservizio che segnala il suo stato attuale per eseguire azioni appropriate. Un buon esempio è l'uso di meccanismi di aggiornamento e distribuzione per mantenere la disponibilità. Anche se un servizio potrebbe essere attualmente non integro a causa di un arresto anomalo del processo o di un riavvio del computer, il servizio potrebbe essere ancora operativo. L'ultima cosa di cui hai bisogno è peggiorare la situazione eseguendo un aggiornamento. L'approccio migliore consiste nell'eseguire prima un'indagine o consentire il ripristino del microservizio. Gli eventi di salute di un microservizio ci aiutano a prendere decisioni informate e, in effetti, aiutano a creare servizi autoriparanti.
Nella sezione Implementazione dei controlli di integrità nei servizi di ASP.NET Core di questa guida, viene illustrato come usare una nuova libreria di HealthChecks di ASP.NET nei microservizi in modo che possano segnalare il loro stato a un servizio di monitoraggio per adottare le azioni appropriate.
È anche possibile usare una libreria open source eccellente denominata AspNetCore.Diagnostics.HealthChecks, disponibile in GitHub e come pacchetto NuGet. Questa libreria esegue anche verifiche di stato, con un tocco originale, gestendo due tipi di controlli:
- Liveness: controlla se il microservizio è attivo, ovvero se è in grado di accettare richieste e rispondere.
- Idoneità: verifica se le dipendenze del microservizio (database, servizi di accodamento e così via) sono pronte, in modo che il microservizio possa eseguire le operazioni da eseguire.
Uso di diagnostica e log dei flussi di eventi
I log forniscono informazioni sull'esecuzione di un'applicazione o di un servizio, incluse eccezioni, avvisi e semplici messaggi informativi. In genere, ogni log è in un formato di testo con una riga per evento, anche se le eccezioni spesso mostrano l'analisi dello stack tra più righe.
Nelle applicazioni monolitiche basate su server è possibile scrivere log in un file su disco (un file di log) e quindi analizzarlo con qualsiasi strumento. Poiché l'esecuzione dell'applicazione è limitata a un server o a una macchina virtuale fissa, in genere non è troppo complessa analizzare il flusso di eventi. Tuttavia, in un'applicazione distribuita in cui più servizi vengono eseguiti in molti nodi in un cluster dell'agente di orchestrazione, la possibilità di correlare gli eventi distribuiti è una sfida.
Un'applicazione basata su microservizi non deve tentare di archiviare il flusso di output di eventi o file di log da solo e non provare nemmeno a gestire il routing degli eventi in una posizione centrale. Deve essere trasparente, vale a dire che ogni processo deve semplicemente scrivere il flusso di eventi in un output standard che verrà raccolto dall'infrastruttura dell'ambiente di esecuzione in cui è in esecuzione. Un esempio di questi router del flusso di eventi è Microsoft.Diagnostic.EventFlow, che raccoglie flussi di eventi da più origini e lo pubblica nei sistemi di output. Questi possono includere un output standard semplice per un ambiente di sviluppo o sistemi cloud come Monitoraggio di Azure e Diagnostica di Azure. Esistono anche buone piattaforme e strumenti di analisi dei log di terze parti in grado di eseguire ricerche, avvisi, report e monitorare i log, anche in tempo reale, come Splunk o Middleware.
Strumenti di orchestrazione che gestiscono informazioni sullo stato di salute e sulla diagnostica
Quando si crea un'applicazione basata su microservizi, è necessario gestire la complessità. Naturalmente, un singolo microservizio è semplice da gestire, ma decine o centinaia di tipi e migliaia di istanze di microservizi è un problema complesso. Non si tratta solo della creazione dell'architettura di microservizi, ma è necessaria anche disponibilità elevata, accessibilità, resilienza, integrità e diagnostica se si intende avere un sistema stabile e coeso.
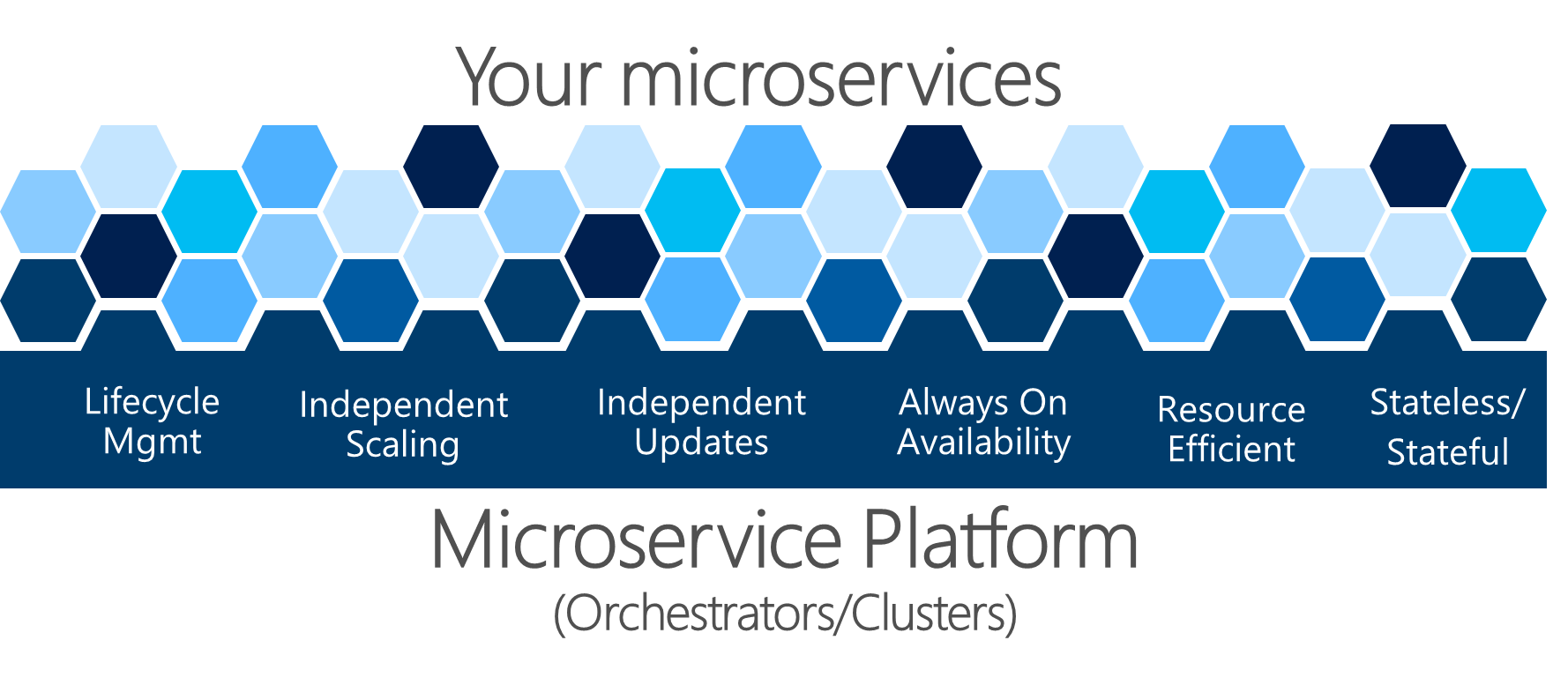
Figura 4-22. Una piattaforma di microservizi è fondamentale per la gestione dell'integrità di un'applicazione
I problemi complessi illustrati nella figura 4-22 sono difficili da risolvere da soli. I team di sviluppo devono concentrarsi sulla risoluzione dei problemi aziendali e sulla creazione di applicazioni personalizzate con approcci basati su microservizi. Non devono concentrarsi sulla risoluzione di problemi di infrastruttura complessi; se lo facessero, il costo di qualsiasi applicazione basata su microservizi sarebbe enorme. Di conseguenza, esistono piattaforme orientate ai microservizi, dette agenti di orchestrazione o cluster di microservizi, che cercano di risolvere i problemi difficili di compilazione ed esecuzione di un servizio e l'uso efficiente delle risorse dell'infrastruttura. Questo approccio riduce le complessità della creazione di applicazioni che usano un approccio ai microservizi.
Diversi agenti di orchestrazione potrebbero sembrare simili, ma la diagnostica e i controlli di integrità offerti da ognuno di essi differiscono in funzionalità e stato di maturità, a volte a seconda della piattaforma del sistema operativo, come illustrato nella sezione successiva.
Risorse aggiuntive
L'app Twelve-Factor. XI. Log: trattare i log come flussi di eventi
https://12factor.net/logsLibreria EventFlow di Diagnostica Microsoft del repository GitHub.
https://github.com/Azure/diagnostics-eventflowChe cos'è Diagnostica di Azure
https://learn.microsoft.com/azure/azure-diagnosticsConnettere i computer Windows al servizio Monitoraggio di Azure
https://learn.microsoft.com/azure/azure-monitor/platform/agent-windowsRegistrazione di ciò che si intende: utilizzo del blocco applicativo di registrazione semantica
https://learn.microsoft.com/previous-versions/msp-n-p/dn440729(v=pandp.60)Splunk Sito ufficiale.
https://www.splunk.com/Middleware Sito ufficiale.
https://middleware.io/Classe EventSource API per la traccia degli eventi per Windows (ETW)
https://learn.microsoft.com/dotnet/api/system.diagnostics.tracing.eventsource
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.