Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook, Architettura di microservizi .NET per applicazioni .NET containerizzati, disponibile in documentazione .NET o come PDF scaricabile gratuitamente leggibile offline.

Quando si usano database relazionali come SQL Server, Oracle o PostgreSQL, è consigliabile implementare il livello di persistenza basato su Entity Framework (EF). EF supporta LINQ e fornisce oggetti fortemente tipizzati per il modello, nonché una persistenza semplificata nel database.
Entity Framework ha una lunga cronologia come parte di .NET Framework. Quando si usa .NET, è consigliabile usare anche Entity Framework Core, che viene eseguito in Windows o Linux nello stesso modo di .NET. EF Core è una riscrittura completa di Entity Framework implementata con un footprint molto più piccolo e importanti miglioramenti delle prestazioni.
Introduzione a Entity Framework Core
Entity Framework (EF) Core è una versione leggera, estendibile e multipiattaforma della diffusa tecnologia di accesso ai dati di Entity Framework. È stato introdotto con .NET Core a metà del 2016.
Poiché un'introduzione a EF Core è già disponibile nella documentazione Microsoft, qui vengono forniti semplicemente collegamenti a tali informazioni.
Risorse aggiuntive
Entity Framework Core
https://learn.microsoft.com/ef/core/Introduzione a ASP.NET Core ed Entity Framework Core con Visual Studio
https://learn.microsoft.com/aspnet/core/data/ef-mvc/Classe DbContext
https://learn.microsoft.com/dotnet/api/microsoft.entityframeworkcore.dbcontextConfrontare EF Core & EF6.x
https://learn.microsoft.com/ef/efcore-and-ef6/index
Infrastruttura in Entity Framework Core secondo la prospettiva del DDD
Dal punto di vista DDD, una funzionalità importante di EF è la possibilità di usare entità di dominio POCO, note anche nella terminologia di EF come entità POCO code-first. Se si usano entità di dominio POCO, le classi del modello di dominio sono ignoranti per la persistenza, seguendo i principi Persistence Ignorance e Infrastructure Ignorance .
Per i modelli DDD, è necessario incapsulare il comportamento e le regole del dominio all'interno della classe di entità stessa, in modo che possa controllare invarianti, convalide e regole durante l'accesso a qualsiasi raccolta. Pertanto, non è buona pratica in DDD consentire l'accesso pubblico alle raccolte di entità figlio o oggetti di valore. Si vogliono invece esporre metodi che controllano come e quando è possibile aggiornare i campi e le raccolte di proprietà e quali comportamenti e azioni devono verificarsi in questo caso.
A partire da EF Core 1.1, per soddisfare tali requisiti DDD, è possibile avere campi semplici nelle entità anziché nelle proprietà pubbliche. Se non si vuole che un campo di entità sia accessibile esternamente, è sufficiente creare l'attributo o il campo anziché una proprietà. È anche possibile usare setter di proprietà private.
In modo analogo, è ora possibile avere accesso in sola lettura alle raccolte usando una proprietà pubblica tipizzata come IReadOnlyCollection<T>, supportata da un membro di campo privato per la raccolta (ad esempio un List<T>) nell'entità che si basa su EF per la persistenza. Le versioni precedenti di Entity Framework richiedono proprietà di raccolta per supportare ICollection<T>, il che significa che qualsiasi sviluppatore che usa la classe di entità padre può aggiungere o rimuovere elementi tramite le raccolte di proprietà. Tale possibilità sarebbe contro i modelli consigliati in DDD.
È possibile usare una raccolta privata durante l'esposizione di un oggetto di sola IReadOnlyCollection<T> lettura, come illustrato nell'esempio di codice seguente:
public class Order : Entity
{
// Using private fields, allowed since EF Core 1.1
private DateTime _orderDate;
// Other fields ...
private readonly List<OrderItem> _orderItems;
public IReadOnlyCollection<OrderItem> OrderItems => _orderItems;
protected Order() { }
public Order(int buyerId, int paymentMethodId, Address address)
{
// Initializations ...
}
public void AddOrderItem(int productId, string productName,
decimal unitPrice, decimal discount,
string pictureUrl, int units = 1)
{
// Validation logic...
var orderItem = new OrderItem(productId, productName,
unitPrice, discount,
pictureUrl, units);
_orderItems.Add(orderItem);
}
}
Alla proprietà OrderItems è possibile accedere solo in modalità di sola lettura tramite IReadOnlyCollection<OrderItem>. Questo tipo è di sola lettura, quindi è protetto da normali aggiornamenti esterni.
EF Core consente di eseguire il mapping del modello di dominio al database fisico senza "contaminare" il modello di dominio. Si tratta di codice POCO .NET puro, perché l'azione di mapping viene implementata nel livello di persistenza. In tale azione di mapping è necessario configurare il mapping da campi a database. Nell'esempio seguente del metodo OnModelCreating della classe OrderingContext di OrderEntityTypeConfiguration, la chiamata a SetPropertyAccessMode indica a EF Core di accedere alla proprietà OrderItems tramite il suo campo.
// At OrderingContext.cs from eShopOnContainers
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// ...
modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration());
// Other entities' configuration ...
}
// At OrderEntityTypeConfiguration.cs from eShopOnContainers
class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> orderConfiguration)
{
orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA);
// Other configuration
var navigation =
orderConfiguration.Metadata.FindNavigation(nameof(Order.OrderItems));
//EF access the OrderItem collection property through its backing field
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
// Other configuration
}
}
Quando si usano campi anziché proprietà, l'entità OrderItem viene resa persistente come se avesse una List<OrderItem> proprietà. Tuttavia, espone un singolo metodo di accesso, il metodo AddOrderItem, per l'aggiunta di nuovi elementi all'ordine. Di conseguenza, il comportamento e i dati sono associati e saranno coerenti in tutto il codice dell'applicazione che usa il modello di dominio.
Implementare repository personalizzati con Entity Framework Core
A livello di implementazione, un repository è semplicemente una classe con codice di persistenza dei dati coordinata da un'unità di lavoro (DBContext in EF Core) quando si eseguono aggiornamenti, come illustrato nella classe seguente:
// using directives...
namespace Microsoft.eShopOnContainers.Services.Ordering.Infrastructure.Repositories
{
public class BuyerRepository : IBuyerRepository
{
private readonly OrderingContext _context;
public IUnitOfWork UnitOfWork
{
get
{
return _context;
}
}
public BuyerRepository(OrderingContext context)
{
_context = context ?? throw new ArgumentNullException(nameof(context));
}
public Buyer Add(Buyer buyer)
{
return _context.Buyers.Add(buyer).Entity;
}
public async Task<Buyer> FindAsync(string buyerIdentityGuid)
{
var buyer = await _context.Buyers
.Include(b => b.Payments)
.Where(b => b.FullName == buyerIdentityGuid)
.SingleOrDefaultAsync();
return buyer;
}
}
}
L'interfaccia IBuyerRepository proviene dal livello del modello di dominio ed è considerata un contratto. Tuttavia, l'implementazione del repository viene eseguita a livello di persistenza e infrastruttura.
Il DbContext di Entity Framework viene iniettato nel costruttore tramite Dependency Injection. Viene condiviso tra più repository all'interno dello stesso ambito di richiesta HTTP, grazie alla durata predefinita (ServiceLifetime.Scoped) nel contenitore IoC (che può anche essere impostata in modo esplicito con services.AddDbContext<>).
Metodi da implementare in un repository (aggiornamenti o transazioni e query)
All'interno di ogni classe del repository è necessario inserire i metodi di persistenza che aggiornano lo stato delle entità contenute nell'aggregazione correlata. Tenere presente che esiste una relazione uno-a-uno tra un'aggregazione e il relativo repository correlato. Si consideri che un oggetto entità radice aggregato potrebbe avere entità figlio incorporate all'interno del grafico di Entity Framework. Ad esempio, un acquirente potrebbe avere più metodi di pagamento come entità figlie correlate.
Poiché l'approccio per il microservizio di ordinamento in eShopOnContainers è basato anche su CQS/CQRS, la maggior parte delle query non viene implementata nei repository personalizzati. Gli sviluppatori hanno la libertà di creare le query e i join necessari per il livello di presentazione senza le restrizioni imposte da entità aggregate, repository personalizzati per entità aggregate e Domain-Driven Design (DDD) in generale. La maggior parte dei repository personalizzati suggeriti da questa guida include diversi metodi di aggiornamento o transazionali, ma solo i metodi di query necessari per ottenere i dati da aggiornare. Ad esempio, il repository BuyerRepository implementa un metodo FindAsync, perché l'applicazione deve sapere se un determinato acquirente esiste prima di creare un nuovo acquirente correlato all'ordine.
Tuttavia, i metodi di query reali per ottenere i dati da inviare al livello di presentazione o alle app client vengono implementati, come indicato, nelle query CQRS basate su query flessibili che usano Dapper.
Uso di un repository personalizzato rispetto all'uso diretto di EF DbContext
La classe DbContext di Entity Framework si basa sui modelli Unit of Work e Repository e può essere usata direttamente dal codice, ad esempio da un controller MVC core ASP.NET. I modelli unit of work e repository generano il codice più semplice, come nel microservizio di catalogo CRUD in eShopOnContainers. Nei casi in cui si vuole ottenere il codice più semplice possibile, è possibile usare direttamente la classe DbContext, come fanno molti sviluppatori.
Tuttavia, l'implementazione di repository personalizzati offre diversi vantaggi quando si implementano microservizi o applicazioni più complessi. Gli schemi unit of work e repository sono progettati per incapsulare il livello di persistenza dell'infrastruttura in modo che sia separato dai livelli dell'applicazione e del modello di dominio. L'implementazione di questi modelli può facilitare l'uso di repository fittizi che simulano l'accesso al database.
Nella figura 7-18, è possibile osservare le differenze tra il non utilizzo di repository (utilizzando direttamente il DbContext di Entity Framework) rispetto all'utilizzo di repository, che semplifica la simulazione di tali repository.
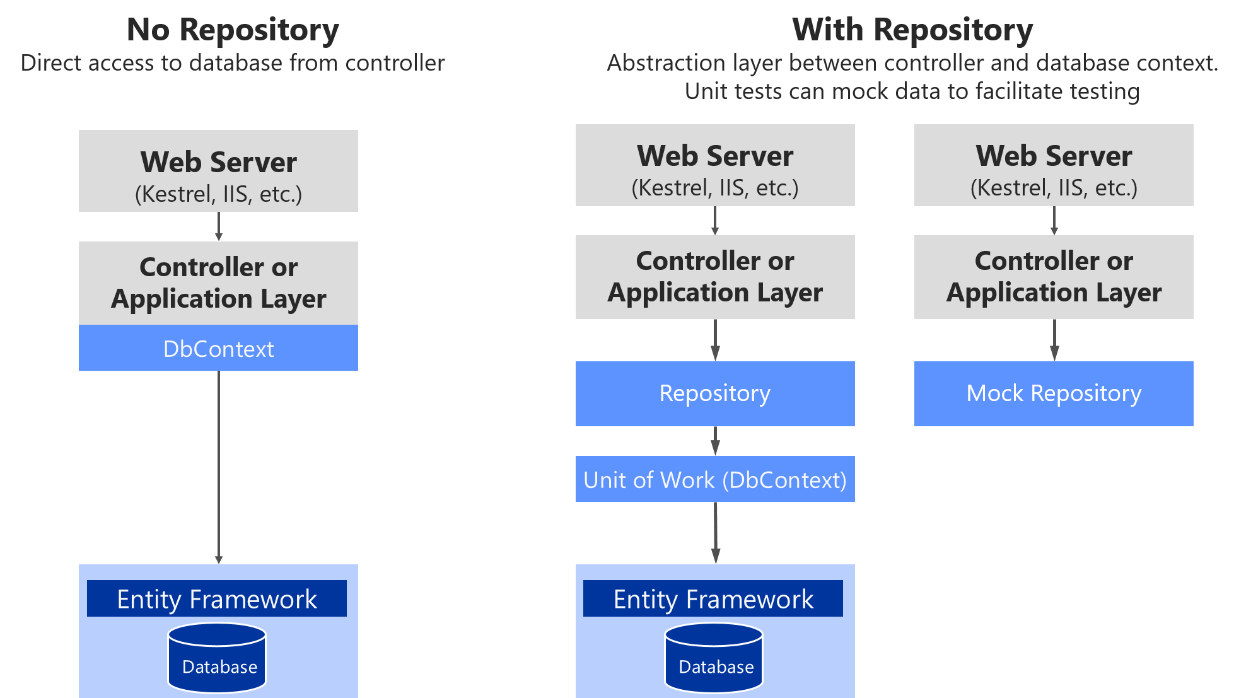
Figura 7-18. Uso di repository personalizzati rispetto a un DbContext semplice
La figura 7-18 mostra che l'uso di un repository personalizzato aggiunge un livello di astrazione che può essere usato per semplificare il test simulando il repository. Esistono diverse alternative durante il mocking. È possibile simulare solo repository o simulare un'intera unità di lavoro. Di solito è sufficiente mockare solo i repository, e la complessità per astrarre e mockare un'intera unità di lavoro non è generalmente richiesta.
Successivamente, quando ci si concentra sul livello dell'applicazione, si vedrà come funziona l'inserimento delle dipendenze in ASP.NET Core e come viene implementato quando si usano i repository.
In breve, i repository personalizzati consentono di testare più facilmente il codice con unit test che non sono interessati dallo stato del livello dati. Se si eseguono test che accedono anche al database effettivo tramite Entity Framework, non sono unit test, ma test di integrazione, che sono molto più lenti.
Se si stesse utilizzando direttamente DbContext, è necessario fare il mock o eseguire i test unitari utilizzando un'istanza di SQL Server in memoria con dati prevedibili per i test unitari. Tuttavia, la simulazione di DbContext o il controllo dei dati falsi richiede più lavoro rispetto alla simulazione a livello di repository. Naturalmente, è sempre possibile testare i controller MVC.
Durata dell'istanza di Entity Framework DbContext e IUnitOfWork nel tuo contenitore IoC
L'oggetto DbContext (esposto come IUnitOfWork oggetto) deve essere condiviso tra più repository all'interno dello stesso ambito di richiesta HTTP. Ad esempio, questo vale quando l'operazione eseguita deve gestire più aggregazioni o semplicemente perché si usano più istanze del repository. È anche importante ricordare che l'interfaccia IUnitOfWork fa parte del livello di dominio, non di un tipo EF Core.
A tale scopo, l'istanza dell'oggetto DbContext deve avere la durata del servizio impostata su ServiceLifetime.Scoped. Questa è la durata predefinita quando si registra un DbContext con builder.Services.AddDbContext nel contenitore IoC dal file Program.cs nel tuo progetto ASP.NET Core Web API. Il codice seguente illustra questa operazione.
// Add framework services.
builder.Services.AddMvc(options =>
{
options.Filters.Add(typeof(HttpGlobalExceptionFilter));
}).AddControllersAsServices();
builder.Services.AddEntityFrameworkSqlServer()
.AddDbContext<OrderingContext>(options =>
{
options.UseSqlServer(Configuration["ConnectionString"],
sqlOptions => sqlOptions.MigrationsAssembly(typeof(Startup).GetTypeInfo().
Assembly.GetName().Name));
},
ServiceLifetime.Scoped // Note that Scoped is the default choice
// in AddDbContext. It is shown here only for
// pedagogic purposes.
);
La modalità di creazione delle istanze di DbContext non deve essere configurata con i modelli ServiceLifetime.Transient o ServiceLifetime.Singleton.
Durata dell'istanza del repository nel contenitore IoC
In modo analogo, la durata del repository deve essere in genere impostata come ambito (InstancePerLifetimeScope in Autofac). Potrebbe anche essere temporaneo (InstancePerDependency in Autofac), ma il servizio sarà più efficiente in termini di memoria quando si utilizza la durata di ambito.
// Registering a Repository in Autofac IoC container
builder.RegisterType<OrderRepository>()
.As<IOrderRepository>()
.InstancePerLifetimeScope();
L'uso della durata singleton per il repository può causare gravi problemi di concorrenza quando DbContext è impostato sulla durata dell'ambito (InstancePerLifetimeScope) (durata predefinita per un DBContext). Finché la durata di vita del servizio per i repository e il DbContext sono entrambi definiti come ambito, è possibile evitare questi problemi.
Risorse aggiuntive
Implementazione del repository e dell'unità di modelli di lavoro in un'applicazione MVC ASP.NET
https://www.asp.net/mvc/overview/older-versions/getting-started-with-ef-5-using-mvc-4/implementing-the-repository-and-unit-of-work-patterns-in-an-asp-net-mvc-applicationJonathan Allen. Strategie di implementazione per il modello di repository con Entity Framework, Dapper e Chain
https://www.infoq.com/articles/repository-implementation-strategiesCesare de la Torre. Confronto tra le durate di vita del servizio nel contenitore IoC di ASP.NET Core e gli ambiti delle istanze nel contenitore IoC Autofac.
https://devblogs.microsoft.com/cesardelatorre/comparing-asp-net-core-ioc-service-life-times-and-autofac-ioc-instance-scopes/
Mappatura delle tabelle
Il mapping delle tabelle identifica i dati della tabella da cui eseguire query e salvarli nel database. In precedenza è stato illustrato come usare le entità di dominio, ad esempio un dominio di prodotto o ordine, per generare uno schema di database correlato. Ef è fortemente progettato in base al concetto di convenzioni. Le convenzioni affrontano domande come "Quale sarà il nome di una tabella?" o "Quale proprietà è la chiave primaria?" Le convenzioni sono in genere basate su nomi convenzionali. Ad esempio, è tipico che la chiave primaria sia una proprietà che termina con Id.
Per convenzione, ogni entità verrà configurata a mappare su una tabella con lo stesso nome della proprietà DbSet<TEntity> che espone l'entità nel contesto derivato. Se non viene specificato alcun DbSet<TEntity> valore per l'entità specificata, viene usato il nome della classe.
Annotazioni dei dati e API Fluent
Esistono molte convenzioni aggiuntive di EF Core e la maggior parte di esse può essere modificata usando le annotazioni dei dati o l'API Fluent, implementata all'interno del metodo OnModelCreating.
Le annotazioni dei dati devono essere usate nelle classi del modello di entità stesse, che è un modo più intrusivo dal punto di vista DDD. Ciò è dovuto al fatto che si sta contaminando il modello con annotazioni di dati correlate al database dell'infrastruttura. D'altra parte, l'API Fluent è un modo pratico per modificare la maggior parte delle convenzioni e dei mapping all'interno del livello dell'infrastruttura di persistenza dei dati, in modo che il modello di entità sia pulito e disaccoppiato dall'infrastruttura di persistenza.
API Fluent e il metodo OnModelCreating
Come accennato, per modificare convenzioni e mapping, è possibile usare il metodo OnModelCreating nella classe DbContext.
Il microservizio di ordinamento in eShopOnContainers implementa il mapping e la configurazione espliciti, se necessario, come illustrato nel codice seguente.
// At OrderingContext.cs from eShopOnContainers
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
// ...
modelBuilder.ApplyConfiguration(new OrderEntityTypeConfiguration());
// Other entities' configuration ...
}
// At OrderEntityTypeConfiguration.cs from eShopOnContainers
class OrderEntityTypeConfiguration : IEntityTypeConfiguration<Order>
{
public void Configure(EntityTypeBuilder<Order> orderConfiguration)
{
orderConfiguration.ToTable("orders", OrderingContext.DEFAULT_SCHEMA);
orderConfiguration.HasKey(o => o.Id);
orderConfiguration.Ignore(b => b.DomainEvents);
orderConfiguration.Property(o => o.Id)
.UseHiLo("orderseq", OrderingContext.DEFAULT_SCHEMA);
//Address value object persisted as owned entity type supported since EF Core 2.0
orderConfiguration
.OwnsOne(o => o.Address, a =>
{
a.WithOwner();
});
orderConfiguration
.Property<int?>("_buyerId")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("BuyerId")
.IsRequired(false);
orderConfiguration
.Property<DateTime>("_orderDate")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("OrderDate")
.IsRequired();
orderConfiguration
.Property<int>("_orderStatusId")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("OrderStatusId")
.IsRequired();
orderConfiguration
.Property<int?>("_paymentMethodId")
.UsePropertyAccessMode(PropertyAccessMode.Field)
.HasColumnName("PaymentMethodId")
.IsRequired(false);
orderConfiguration.Property<string>("Description").IsRequired(false);
var navigation = orderConfiguration.Metadata.FindNavigation(nameof(Order.OrderItems));
// DDD Patterns comment:
//Set as field (New since EF 1.1) to access the OrderItem collection property through its field
navigation.SetPropertyAccessMode(PropertyAccessMode.Field);
orderConfiguration.HasOne<PaymentMethod>()
.WithMany()
.HasForeignKey("_paymentMethodId")
.IsRequired(false)
.OnDelete(DeleteBehavior.Restrict);
orderConfiguration.HasOne<Buyer>()
.WithMany()
.IsRequired(false)
.HasForeignKey("_buyerId");
orderConfiguration.HasOne(o => o.OrderStatus)
.WithMany()
.HasForeignKey("_orderStatusId");
}
}
È possibile impostare tutti i mapping dell'API Fluent nello stesso OnModelCreating metodo, ma è consigliabile partizionare tale codice e avere più classi di configurazione, una per entità, come illustrato nell'esempio. In particolare per i modelli di grandi dimensioni, è consigliabile avere classi di configurazione separate per la configurazione di tipi di entità diversi.
Il codice nell'esempio mostra alcune dichiarazioni esplicite e il mapping. Tuttavia, le convenzioni di EF Core eseguono automaticamente molti di questi mapping, quindi il codice effettivo necessario nel caso potrebbe essere più piccolo.
Algoritmo Hi/Lo in EF Core
Un aspetto interessante del codice nell'esempio precedente è che usa l'algoritmo Hi/Lo come strategia di generazione chiave.
L'algoritmo Hi/Lo è utile quando sono necessarie chiavi univoce prima di eseguire il commit delle modifiche. Come riepilogo, l'algoritmo Hi-Lo assegna identificatori univoci alle righe della tabella, pur non in base all'archiviazione immediata della riga nel database. In questo modo è possibile iniziare subito a usare gli identificatori, come avviene con gli ID di database sequenziali regolari.
L'algoritmo Hi/Lo descrive un meccanismo per ottenere un batch di ID univoci da una sequenza di database correlata. Questi ID sono sicuri da usare perché il database garantisce l'univocità, quindi non ci saranno conflitti tra gli utenti. Questo algoritmo è interessante per questi motivi:
Non interrompe il modello Unit of Work.
Ottiene gli ID sequenza a lotti, per ridurre al minimo le comunicazioni al database.
Genera un identificatore leggibile umano, a differenza delle tecniche che usano GUID.
EF Core supporta HiLo con il UseHiLo metodo , come illustrato nell'esempio precedente.
Eseguire il mapping dei campi anziché delle proprietà
Con questa funzionalità, disponibile a partire da EF Core 1.1, è possibile eseguire direttamente il mapping delle colonne ai campi. È possibile non usare proprietà nella classe di entità e solo per eseguire il mapping delle colonne da una tabella ai campi. Un uso comune per quello sarebbe campi privati per qualsiasi stato interno a cui non è necessario accedere dall'esterno dell'entità.
È possibile eseguire questa operazione con singoli campi o anche con raccolte, ad esempio un List<> campo. Questo punto è stato menzionato in precedenza durante la modellazione delle classi del modello di dominio, ma qui è possibile vedere come viene eseguito il mapping con la PropertyAccessMode.Field configurazione evidenziata nel codice precedente.
Usare le proprietà shadow in EF Core, nascoste a livello di infrastruttura
Le proprietà shadow in EF Core sono proprietà che non esistono nel modello di classe di entità. I valori e gli stati di queste proprietà vengono mantenuti esclusivamente nella classe ChangeTracker a livello di infrastruttura.
Implementare il modello Specifica query
Come illustrato in precedenza nella sezione di progettazione, il Schema Specifica Query è un modello di progettazione Domain-Driven progettato come luogo in cui è possibile inserire la definizione di una query con logica di ordinamento e paging opzionale.
Il modello di specifica delle query definisce una query in un oggetto. Ad esempio, per incapsulare una query di paging che cerca alcuni prodotti è possibile creare una specifica PagedProduct che accetta i parametri di input necessari (pageNumber, pageSize, filtro e così via). Quindi, all'interno di qualsiasi metodo Repository (in genere un overload List()), accetterebbe un oggetto IQuerySpecification e eseguirebbe la query prevista in base a tale specificazione.
Un esempio di interfaccia specifica generica è il codice seguente, simile al codice usato nell'applicazione di riferimento eShopOnWeb .
// GENERIC SPECIFICATION INTERFACE
// https://github.com/dotnet-architecture/eShopOnWeb
public interface ISpecification<T>
{
Expression<Func<T, bool>> Criteria { get; }
List<Expression<Func<T, object>>> Includes { get; }
List<string> IncludeStrings { get; }
}
L'implementazione di una classe base di specifica generica è quindi la seguente.
// GENERIC SPECIFICATION IMPLEMENTATION (BASE CLASS)
// https://github.com/dotnet-architecture/eShopOnWeb
public abstract class BaseSpecification<T> : ISpecification<T>
{
public BaseSpecification(Expression<Func<T, bool>> criteria)
{
Criteria = criteria;
}
public Expression<Func<T, bool>> Criteria { get; }
public List<Expression<Func<T, object>>> Includes { get; } =
new List<Expression<Func<T, object>>>();
public List<string> IncludeStrings { get; } = new List<string>();
protected virtual void AddInclude(Expression<Func<T, object>> includeExpression)
{
Includes.Add(includeExpression);
}
// string-based includes allow for including children of children
// for example, Basket.Items.Product
protected virtual void AddInclude(string includeString)
{
IncludeStrings.Add(includeString);
}
}
La specifica seguente carica una singola entità carrello in base all'ID del carrello o all'ID dell'acquirente a cui appartiene il carrello. Caricherà con entusiasmo la raccolta del Items carrello.
// SAMPLE QUERY SPECIFICATION IMPLEMENTATION
public class BasketWithItemsSpecification : BaseSpecification<Basket>
{
public BasketWithItemsSpecification(int basketId)
: base(b => b.Id == basketId)
{
AddInclude(b => b.Items);
}
public BasketWithItemsSpecification(string buyerId)
: base(b => b.BuyerId == buyerId)
{
AddInclude(b => b.Items);
}
}
Infine, è possibile vedere di seguito come un repository EF generico può utilizzare tale specifica per filtrare e caricare i dati con anticipazione correlati a un determinato tipo di entità T.
// GENERIC EF REPOSITORY WITH SPECIFICATION
// https://github.com/dotnet-architecture/eShopOnWeb
public IEnumerable<T> List(ISpecification<T> spec)
{
// fetch a Queryable that includes all expression-based includes
var queryableResultWithIncludes = spec.Includes
.Aggregate(_dbContext.Set<T>().AsQueryable(),
(current, include) => current.Include(include));
// modify the IQueryable to include any string-based include statements
var secondaryResult = spec.IncludeStrings
.Aggregate(queryableResultWithIncludes,
(current, include) => current.Include(include));
// return the result of the query using the specification's criteria expression
return secondaryResult
.Where(spec.Criteria)
.AsEnumerable();
}
Oltre a incapsulare la logica di filtro, la specifica può specificare la struttura dei dati da restituire, incluse le proprietà da riempire.
Anche se non raccomandiamo di restituire IQueryable da un repository, è perfettamente accettabile usarli all'interno del repository per creare un set di risultati. È possibile visualizzare questo approccio usato nel metodo List precedente, che usa espressioni intermedie IQueryable per compilare l'elenco di include della query prima di eseguire la query con i criteri della specifica sull'ultima riga.
Informazioni su come viene applicato il modello di specifica nell'esempio eShopOnWeb.
Risorse aggiuntive
Mappatura delle tabelle
https://learn.microsoft.com/ef/core/modeling/relational/tablesUsare HiLo per generare chiavi con Entity Framework Core
https://www.talkingdotnet.com/use-hilo-to-generate-keys-with-entity-framework-core/Campi di supporto
https://learn.microsoft.com/ef/core/modeling/backing-fieldSteve Smith. Raccolte incapsulate in Entity Framework Core
https://ardalis.com/encapsulated-collections-in-entity-framework-coreProprietà delle ombre
https://learn.microsoft.com/ef/core/modeling/shadow-propertiesModello di specifica
https://deviq.com/specification-pattern/Pacchetto NuGet Ardalis.Specification Usato da eShopOnWeb. \ https://www.nuget.org/packages/Ardalis.Specification
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.