Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Suggerimento
Questo contenuto è un estratto dell'eBook, Architect Modern Web Applications with ASP.NET Core and Azure, disponibile in .NET Docs o come PDF scaricabile gratuito che può essere letto offline.

"Se i costruttori costruirono edifici nel modo in cui i programmatori scrivevano programmi, allora il primo legno che arrivò lungo avrebbe distrutto la civiltà."
- Gerald Weienberg
È consigliabile progettare e progettare soluzioni software tenendo conto della manutenibilità. I principi descritti in questa sezione consentono di guidare l'utente verso le decisioni relative all'architettura che determineranno applicazioni pulite e gestibili. In genere, questi principi ti guideranno verso la creazione di applicazioni da componenti discreti che non sono strettamente associati ad altre parti dell'applicazione, ma invece comunicano tramite interfacce esplicite o sistemi di messaggistica.
Principi di progettazione comuni
Separazione delle problematiche
Un principio guida durante lo sviluppo è Separazione delle preoccupazioni. Questo principio afferma che il software deve essere separato in base ai tipi di lavoro che esegue. Si consideri, ad esempio, un'applicazione che include la logica per identificare elementi degni di nota da visualizzare all'utente e quali formatta tali elementi in modo particolare per renderli più evidenti. Il comportamento responsabile della scelta degli elementi da formattare deve essere mantenuto separato dal comportamento responsabile della formattazione degli elementi, poiché questi comportamenti sono preoccupazioni separate che sono correlate solo in modo casuale l'una all'altra.
A livello di architettura, le applicazioni possono essere create logicamente per seguire questo principio separando il comportamento aziendale principale dalla logica dell'infrastruttura e dell'interfaccia utente. Idealmente, le regole business e la logica devono risiedere in un progetto separato, che non deve dipendere da altri progetti nell'applicazione. Questa separazione consente di garantire che il modello aziendale sia facile da testare e che possa evolversi senza essere strettamente accoppiato ai dettagli di implementazione di basso livello (consente anche se le preoccupazioni dell'infrastruttura dipendono dalle astrazioni definite nel livello aziendale). La separazione delle problematiche è una considerazione fondamentale per l'uso dei livelli nelle architetture dell'applicazione.
Incapsulamento
Parti diverse di un'applicazione devono usare l'incapsulamento per isolarli da altre parti dell'applicazione. I componenti e i livelli dell'applicazione devono essere in grado di regolare l'implementazione interna senza interrompere i collaboratori, purché i contratti esterni non vengano violati. L'uso corretto dell'incapsulamento consente di ottenere l'accoppiamento libero e la modularità nelle progettazioni dell'applicazione, poiché gli oggetti e i pacchetti possono essere sostituiti con implementazioni alternative purché venga mantenuta la stessa interfaccia.
Nelle classi, l'incapsulamento viene ottenuto limitando l'accesso esterno allo stato interno della classe. Se un attore esterno vuole modificare lo stato dell'oggetto, deve farlo tramite una funzione ben definita (o setter di proprietà), anziché avere accesso diretto allo stato privato dell'oggetto. Analogamente, i componenti dell'applicazione e le applicazioni stessi devono esporre interfacce ben definite per consentire ai collaboratori di usare, anziché consentire la modifica diretta dello stato. Questo approccio consente di liberare la progettazione interna dell'applicazione per evolversi nel tempo senza preoccuparsi che questo interrompa i collaboratori, purché vengano mantenuti i contratti pubblici.
Lo stato globale modificabile è antitetico all'incapsulamento. Un valore recuperato dallo stato globale modificabile in una funzione non può essere basato su per avere lo stesso valore in un'altra funzione (o ancora più avanti nella stessa funzione). La comprensione dei problemi relativi allo stato globale modificabile è uno dei motivi per cui i linguaggi di programmazione come C# supportano regole di ambito diverse, usate ovunque dalle istruzioni ai metodi alle classi. Vale la pena notare che le architetture guidate dai dati che si basano su un database centrale per l'integrazione all'interno e tra le applicazioni sono, da soli, scegliendo di dipendere dallo stato globale modificabile rappresentato dal database. Una considerazione fondamentale nella progettazione basata su dominio e nell'architettura pulita è come incapsulare l'accesso ai dati e come garantire che lo stato dell'applicazione non sia reso non valido dall'accesso diretto al formato di persistenza.
Inversione delle dipendenze
La direzione della dipendenza all'interno dell'applicazione deve essere nella direzione dell'astrazione, non nei dettagli dell'implementazione. La maggior parte delle applicazioni viene scritta in modo che i flussi di dipendenza in fase di compilazione nella direzione dell'esecuzione del runtime, producendo un grafico delle dipendenze diretto. Ovvero, se la classe A chiama un metodo della classe B e la classe B chiama un metodo della classe C, in fase di compilazione la classe A dipende dalla classe B e la classe B dipende dalla classe C, come illustrato nella figura 4-1.
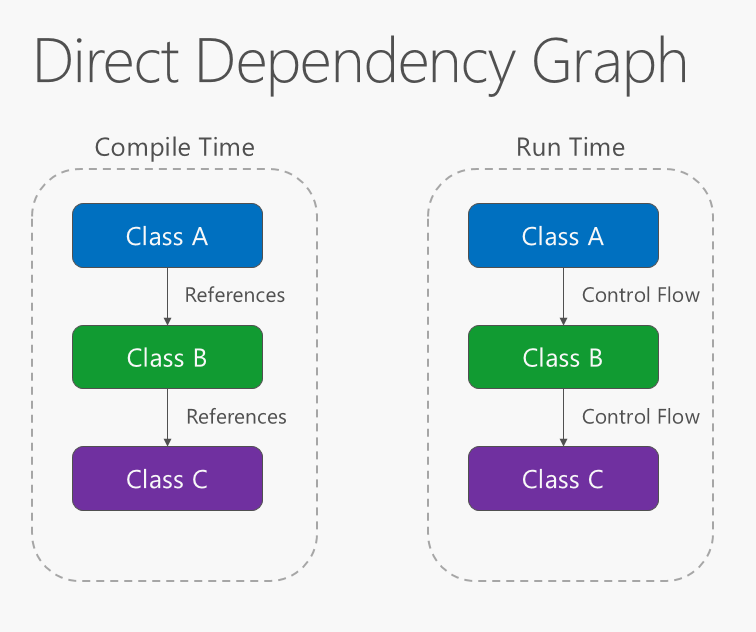
Figura 4-1. Grafico delle dipendenze dirette.
L'applicazione del principio di inversione delle dipendenze consente a A di chiamare metodi su un'astrazione implementata da B, rendendo possibile che A chiami B in fase di esecuzione, ma per B dipende da un'interfaccia controllata da A in fase di compilazione ( invertendo così la tipica dipendenza in fase di compilazione). In fase di esecuzione, il flusso di esecuzione del programma rimane invariato, ma l'introduzione delle interfacce significa che le diverse implementazioni di queste interfacce possono essere facilmente collegate.
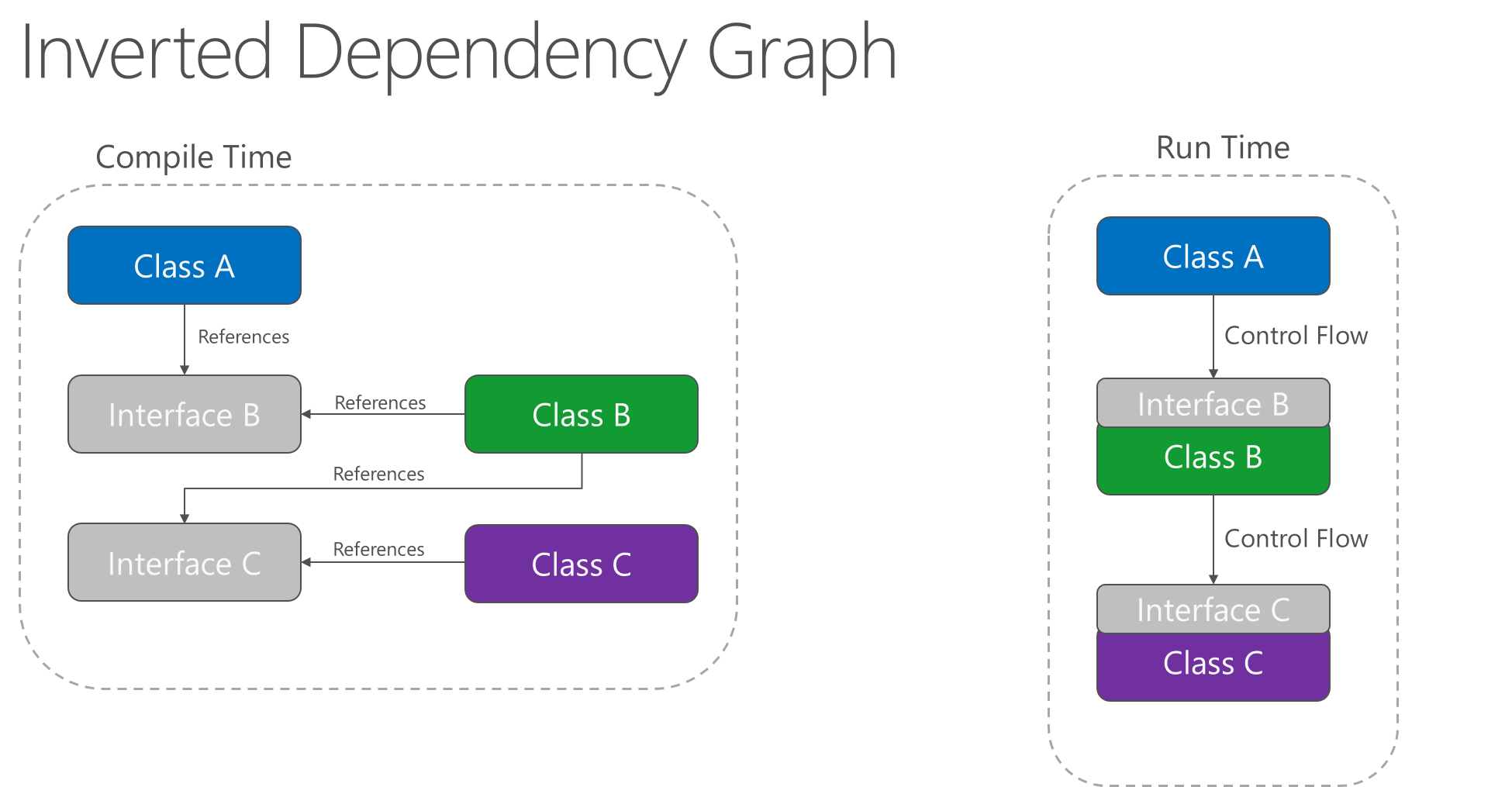
Figura 4-2. Grafico delle dipendenze invertito.
L'inversione delle dipendenze è una parte fondamentale della creazione di applicazioni ad accoppiamento libero, poiché i dettagli di implementazione possono essere scritti per dipendere e implementare astrazioni di livello superiore, anziché in altro modo. Le applicazioni risultanti sono più testabili, modulari e gestibili di conseguenza. La pratica dell'inserimento delle dipendenze è resa possibile seguendo il principio di inversione delle dipendenze.
Dipendenze esplicite
I metodi e le classi devono richiedere in modo esplicito qualsiasi oggetto di collaborazione necessario per funzionare correttamente. Viene chiamato principio delle dipendenze esplicite. I costruttori di classi offrono un'opportunità per le classi di identificare gli elementi necessari per essere in uno stato valido e per funzionare correttamente. Se si definiscono classi che possono essere costruite e chiamate, ma che funzioneranno correttamente solo se sono presenti determinati componenti globali o dell'infrastruttura, queste classi sono disoneste con i propri client. Il contratto del costruttore indica al client che richiede solo gli elementi specificati (possibilmente nulla se la classe usa solo un costruttore senza parametri), ma in fase di esecuzione si scopre che l'oggetto ha effettivamente bisogno di qualcos'altro.
Seguendo il principio esplicito delle dipendenze, le classi e i metodi sono onesti con i propri client riguardo a ciò di cui hanno bisogno per funzionare. Seguendo il principio, il codice risulta più autodocumentato e i contratti di codifica più intuitivi, poiché gli utenti si fidaranno del fatto che, purché forniscano ciò che è necessario sotto forma di parametri del metodo o del costruttore, gli oggetti con cui lavorano si comportano correttamente in fase di esecuzione.
Responsabilità singola
Il principio di responsabilità singola si applica alla progettazione orientata agli oggetti, ma può anche essere considerato un principio architettonico simile alla separazione delle problematiche. Afferma che gli oggetti devono avere una sola responsabilità e che devono avere un solo motivo per cambiare. In particolare, l'unica situazione in cui l'oggetto deve cambiare è se il modo in cui esegue la propria responsabilità deve essere aggiornato. Seguendo questo principio è possibile produrre sistemi più ad accoppiamento libero e modulare, poiché molti tipi di nuovo comportamento possono essere implementati come nuove classi, anziché aggiungendo ulteriore responsabilità alle classi esistenti. L'aggiunta di nuove classi è sempre più sicura rispetto alla modifica delle classi esistenti, poiché nessun codice dipende ancora dalle nuove classi.
In un'applicazione monolitica, è possibile applicare il singolo principio di responsabilità a un livello elevato ai livelli nell'applicazione. La responsabilità della presentazione deve rimanere nel progetto dell'interfaccia utente, mentre la responsabilità dell'accesso ai dati deve essere mantenuta all'interno di un progetto di infrastruttura. La logica di business deve essere mantenuta nel progetto principale dell'applicazione, in cui può essere facilmente testata e può evolversi indipendentemente da altre responsabilità.
Quando questo principio viene applicato all'architettura dell'applicazione e viene portato al relativo endpoint logico, si ottengono i microservizi. Un determinato microservizio deve avere una singola responsabilità. Se è necessario estendere il comportamento di un sistema, è in genere preferibile aggiungerlo aggiungendo altri microservizi anziché aggiungendo responsabilità a un sistema esistente.
Altre informazioni sull'architettura dei microservizi
Don't Repeat Yourself (DRY)
L'applicazione deve evitare di specificare il comportamento correlato a un concetto specifico in più posizioni, perché questa pratica è una fonte frequente di errori. A un certo punto, una modifica dei requisiti richiederà la modifica di questo comportamento. È probabile che almeno un'istanza del comportamento non venga aggiornata e che il sistema si comporti in modo incoerente.
Anziché duplicare la logica, incapsularla in un costrutto di programmazione. Creare questa costruzione della singola autorità su questo comportamento e avere qualsiasi altra parte dell'applicazione che richiede questo comportamento usi il nuovo costrutto.
Annotazioni
Evitare di unire il comportamento che è solo casualmente ripetitivo. Ad esempio, solo perché due costanti diverse hanno entrambi lo stesso valore, ciò non significa che sia necessario avere una sola costante, se concettualmente fanno riferimento a cose diverse. La duplicazione è sempre preferibile associare l'astrazione errata.
Ignoranza di persistenza
L'ignoranza della persistenza (PI) si riferisce a tipi che devono essere salvati in modo permanente, ma il cui codice non è interessato dalla scelta della tecnologia di persistenza. Tali tipi in .NET vengono talvolta definiti oggetti CLR (POCO) semplici, perché non devono ereditare da una determinata classe di base o implementare un'interfaccia specifica. L'ignoranza della persistenza è utile perché consente di rendere persistente lo stesso modello di business in diversi modi, offrendo maggiore flessibilità all'applicazione. Le scelte di persistenza possono cambiare nel tempo, da una tecnologia di database a un'altra o potrebbero essere necessarie forme aggiuntive di persistenza oltre a qualsiasi altra applicazione avviata, ad esempio usando una cache Redis o Azure Cosmos DB oltre a un database relazionale.
Alcuni esempi di violazioni di questo principio includono:
Classe di base obbligatoria.
Implementazione dell'interfaccia richiesta.
Classi responsabili del salvataggio, ad esempio il modello record attivo.
Costruttore senza parametri obbligatorio.
Proprietà che richiedono la parola chiave virtuale.
Attributi obbligatori specifici della persistenza.
Il requisito per cui le classi hanno una delle caratteristiche o dei comportamenti precedenti aggiunge l'accoppiamento tra i tipi da rendere persistenti e la scelta della tecnologia di persistenza, rendendo più difficile adottare nuove strategie di accesso ai dati in futuro.
Contesti delimitati
I contesti delimitati sono un modello centrale in Domain-Driven Progettazione. Offrono un modo per affrontare la complessità in applicazioni o organizzazioni di grandi dimensioni suddividendoli in moduli concettuali separati. Ogni modulo concettuale rappresenta quindi un contesto separato da altri contesti (di conseguenza, delimitato) e può evolversi in modo indipendente. Ogni contesto delimitato deve essere idealmente libero di scegliere i propri nomi per i concetti al suo interno e deve avere accesso esclusivo al proprio archivio di persistenza.
Come minimo, le singole applicazioni Web devono cercare di essere il proprio contesto delimitato, con il proprio archivio di persistenza per il proprio modello di business, invece di condividere un database con altre applicazioni. La comunicazione tra contesti delimitati avviene tramite interfacce a livello di codice, anziché tramite un database condiviso, che consente di eseguire la logica di business e gli eventi in risposta alle modifiche che si verificano. I contesti delimitati sono strettamente associati ai microservizi, che vengono implementati idealmente come singoli contesti delimitati.
Risorse aggiuntive
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.