Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Scopri come usare un modello ONNX preaddestrato in ML.NET per rilevare oggetti nelle immagini.
Il training di un modello di rilevamento oggetti da zero richiede l'impostazione di milioni di parametri, una grande quantità di dati di training etichettati e una grande quantità di risorse di calcolo (centinaia di ore GPU). L'uso di un modello con training preliminare consente di completare il processo di training.
In questa esercitazione si apprenderà come:
- Informazioni sul problema
- Scopri cos'è ONNX e come funziona con ML.NET
- Comprendere il modello
- Riutilizzare il modello con training preliminare
- Rilevare gli oggetti con un modello caricato
Prerequisiti
- Visual Studio 2022 o versione successiva.
- pacchetto NuGet Microsoft.ML
- Il Pacchetto NuGet Microsoft.ML.ImageAnalytics
- Pacchetto NuGet Microsoft.ML.OnnxTransformer
- Modello Tiny YOLOv2 preaddestrato
- Netron (facoltativo)
Panoramica dell'esempio di rilevamento degli oggetti ONNX
Questo esempio crea un'applicazione console .NET Core che rileva gli oggetti all'interno di un'immagine usando un modello ONNX di Deep Learning con training preliminare. Il codice per questo esempio è disponibile nel repository dotnet/machinelearning-samples su GitHub.
Che cos'è il rilevamento degli oggetti?
Il rilevamento degli oggetti è un problema di visione artificiale. Anche se strettamente correlato alla classificazione delle immagini, il rilevamento degli oggetti esegue la classificazione delle immagini a una scala più granulare. Il rilevamento degli oggetti individua e classifica le entità all'interno delle immagini. I modelli di rilevamento oggetti vengono comunemente sottoposti a training usando deep learning e reti neurali. Per altre informazioni, vedere Deep Learning e Machine Learning .
Usare il rilevamento degli oggetti quando le immagini contengono più oggetti di tipi diversi.

Alcuni casi d'uso per il rilevamento degli oggetti includono:
- Automobili a Guida Autonoma
- Robotica
- Rilevamento viso
- Sicurezza sul posto di lavoro
- Conteggio oggetti
- Riconoscimento delle attività
Selezionare un modello di Deep Learning
Deep Learning è un subset di Machine Learning. Per eseguire il training di modelli di Deep Learning, sono necessarie grandi quantità di dati. I modelli nei dati sono rappresentati da una serie di livelli. Le relazioni nei dati vengono codificate come connessioni tra i livelli contenenti pesi. Maggiore è il peso, più forte è la relazione. Collettivamente, questa serie di livelli e connessioni è nota come reti neurali artificiali. Più livelli in una rete, il "più profondo" è, rendendolo una rete neurale profonda.
Esistono diversi tipi di reti neurali, i più comuni sono perceptron multi-layer (MLP), rete neurale convoluzionale (CNN) e rete neurale ricorrente (RNN). Il modello più semplice è l'MLP, che mappa un set di input a un set di output. Questa rete neurale è valida quando i dati non hanno un componente spaziale o temporale. La CNN usa livelli convoluzionali per elaborare le informazioni spaziali contenute nei dati. Un buon caso d'uso per le reti neurali convoluzionali (CNN) è l'elaborazione di immagini per rilevare la presenza di una caratteristica in una regione di un'immagine (ad esempio, c'è un naso al centro di un'immagine?). Infine, le reti RNN consentono l'uso della persistenza dello stato o della memoria come input. Le reti APN vengono usate per l'analisi delle serie temporali, in cui l'ordinamento sequenziale e il contesto degli eventi sono importanti.
Comprendere il modello
Il rilevamento degli oggetti è un'attività di elaborazione delle immagini. Di conseguenza, la maggior parte dei modelli di Deep Learning sottoposti a training per risolvere questo problema sono reti CNN. Il modello usato in questa esercitazione è il modello Tiny YOLOv2, una versione più compatta del modello YOLOv2 descritta nel documento: "YOLO9000: Better, Faster, Stronger" di Redmon e Farhadi. Tiny YOLOv2 viene sottoposto a training nel set di dati PASCAL VOC ed è costituito da 15 livelli che possono prevedere 20 classi diverse di oggetti. Poiché Tiny YOLOv2 è una versione condensata del modello YOLOv2 originale, viene fatto un compromesso tra velocità e accuratezza. I diversi livelli che costituiscono il modello possono essere visualizzati usando strumenti come Netron. L'ispezione del modello genera un mapping delle connessioni tra tutti i livelli che costituiscono la rete neurale, in cui ogni livello conterrà il nome del livello insieme alle dimensioni del rispettivo input/output. Le strutture di dati usate per descrivere gli input e gli output del modello sono noti come tensori. I tensori possono essere considerati contenitori che archiviano i dati in dimensioni N. Nel caso di Tiny YOLOv2, il nome del livello di input è image e prevede un tensore di dimensioni 3 x 416 x 416. Il nome del livello di output è grid e genera un tensore di output di dimensioni 125 x 13 x 13.
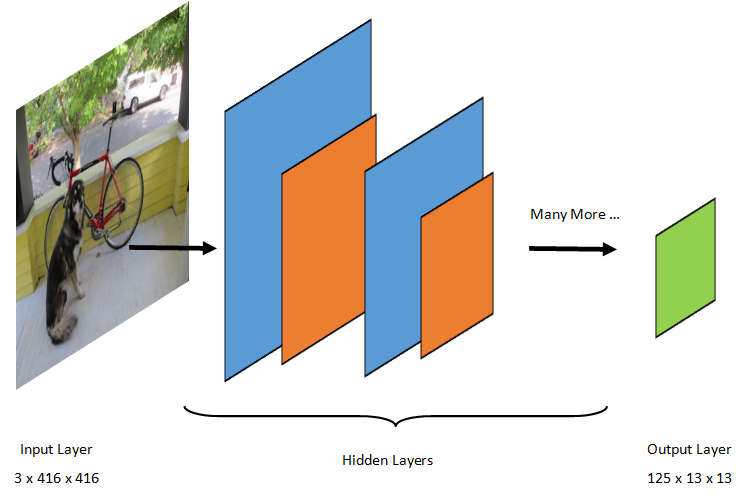
Il modello YOLO accetta un'immagine 3(RGB) x 416px x 416px. Il modello accetta questo input e lo passa attraverso i diversi livelli per produrre un output. L'output divide l'immagine di input in una 13 x 13 griglia, con ogni cella della griglia costituita da 125 valori.
Che cos'è un modello ONNX?
Open Neural Network Exchange (ONNX) è un formato open source per i modelli di intelligenza artificiale. ONNX supporta l'interoperabilità tra framework. Ciò significa che è possibile eseguire il training di un modello in uno dei numerosi framework di Machine Learning più diffusi, ad esempio PyTorch, convertirlo in formato ONNX e utilizzare il modello ONNX in un framework diverso, ad esempio ML.NET. Per altre informazioni, visitare il sito Web ONNX.

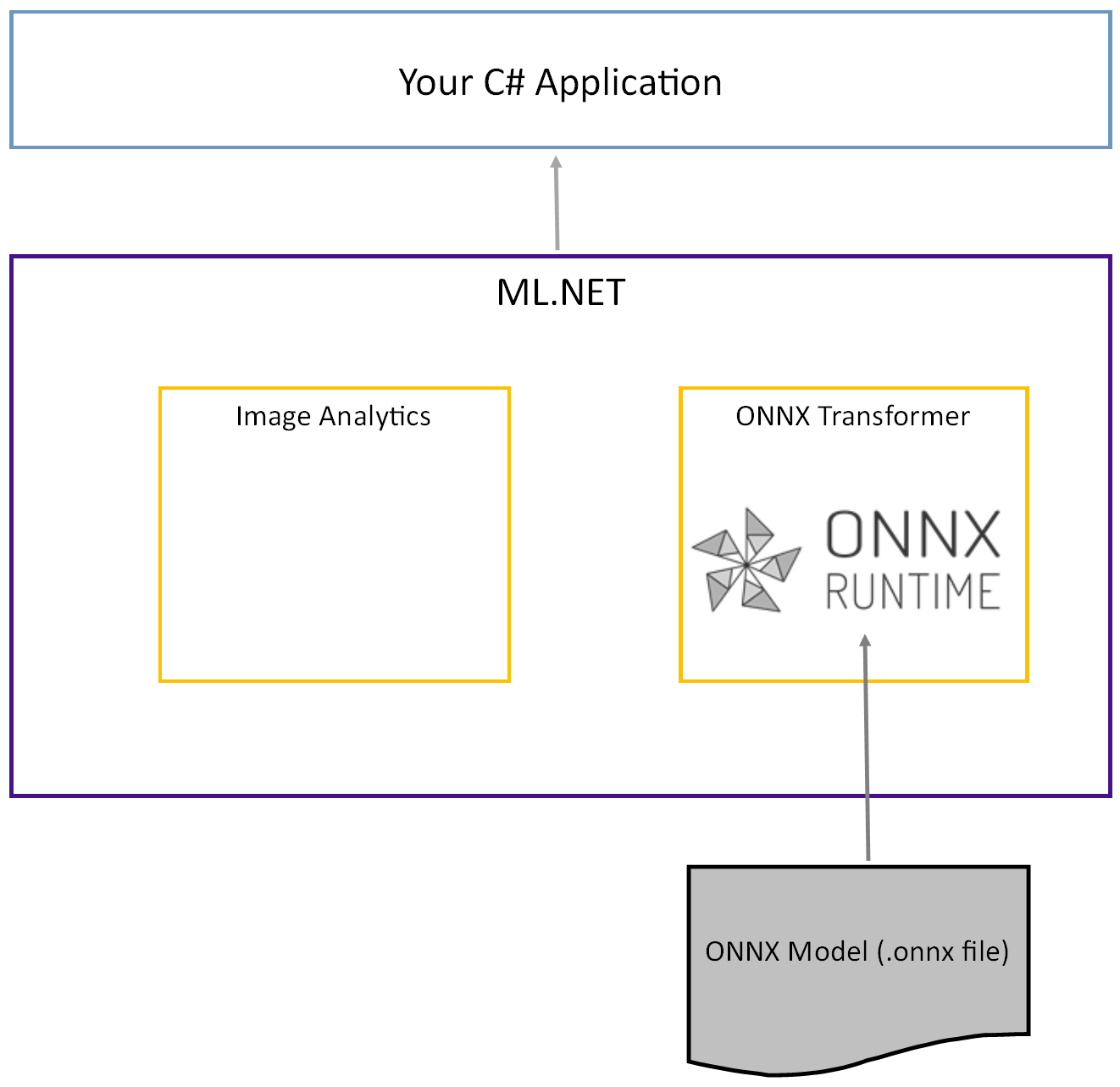
Il modello Tiny YOLOv2 preaddestrato viene archiviato in formato ONNX, una rappresentazione serializzata dei livelli e degli schemi appresi di tali livelli. In ML.NET l'interoperabilità con ONNX viene ottenuta con i ImageAnalytics pacchetti NuGet e OnnxTransformer . Il ImageAnalytics pacchetto contiene una serie di trasformazioni che accettano un'immagine e la codificano in valori numerici che possono essere usati come input in una pipeline di stima o training. Il OnnxTransformer pacchetto sfrutta il runtime ONNX per caricare un modello ONNX e usarlo per eseguire stime in base all'input fornito.
Configurare il progetto console .NET
Ora che si ha una conoscenza generale del funzionamento di ONNX e del funzionamento di Tiny YOLOv2, è il momento di compilare l'applicazione.
Creare un'applicazione console
Creare un'applicazione console C# denominata "ObjectDetection". Fare clic sul pulsante Avanti.
Scegliere .NET 8 come framework da usare. Fare clic sul pulsante Crea.
Installare il pacchetto NuGet Microsoft.ML:
Annotazioni
In questo esempio viene usata la versione stabile più recente dei pacchetti NuGet menzionati, a meno che non diversamente specificato.
- In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e scegliere Gestisci pacchetti NuGet.
- Scegliere "nuget.org" come origine pacchetto, selezionare la scheda Sfoglia e cercare Microsoft.ML.
- Selezionare il pulsante Installa .
- Selezionare il pulsante OK nella finestra di dialogo Anteprima modifiche e quindi selezionare il pulsante Accetto nella finestra di dialogo Accettazione della licenza se si accettano le condizioni di licenza per i pacchetti elencati.
- Ripetere questi passaggi per Microsoft.Windows.Compatibility, Microsoft.ML.ImageAnalytics, Microsoft.ML.OnnxTransformer e Microsoft.ML.OnnxRuntime.
Preparare i dati e il modello con training preliminare
Scaricare il file ZIP della directory degli asset del progetto e decomprimerlo.
Copiare la directory
assetsnella directory del tuo progetto ObjectDetection. Questa directory e le relative sottodirectory contengono i file di immagine (ad eccezione del modello Tiny YOLOv2, che verrà scaricato e aggiunto nel passaggio successivo) necessari per questa esercitazione.Scaricare il modello Tiny YOLOv2 dallo zoo del modello ONNX.
Copiare il file nella directory del
model.onnxprogettoassets\Modele rinominarlo inTinyYolo2_model.onnx. Questa directory contiene il modello necessario per questa esercitazione.In "Esplora soluzioni", fare clic con il pulsante destro del mouse su ognuno dei file nella directory degli asset e nelle sottodirectory e scegliere Proprietà. Nella sezione Avanzate, cambiare il valore di Copia nella directory di output con Copia se più recente.
Creare classi e definire percorsi
Aprire il file Program.cs e aggiungere le direttive aggiuntive using seguenti all'inizio del file:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
Definire quindi i percorsi dei vari asset.
Creare prima di tutto il
GetAbsolutePathmetodo nella parte inferiore del file Program.cs .string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }Quindi, sotto le
usingdirettive creare campi per archiviare la posizione degli asset.var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
Aggiungere una nuova directory al progetto per archiviare i dati di input e le classi di stima.
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e quindi scegliere Aggiungi>nuova cartella. Quando la nuova cartella viene visualizzata in Esplora soluzioni, denominarla "DataStructures".
Creare la classe di dati di input nella directory DataStructures appena creata.
In Esplora soluzioni fare clic con il pulsante destro del mouse sulla directory DataStructures e quindi scegliere Aggiungi>nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il campo Nome in ImageNetData.cs. Quindi selezionare Aggiungi.
Il file ImageNetData.cs viene aperto nell'editor di codice. Aggiungere la direttiva seguente
usingall'inizio di ImageNetData.cs:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;Rimuovere la definizione di classe esistente e aggiungere il codice seguente per la
ImageNetDataclasse al file ImageNetData.cs :public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetDataè la classe di dati dell'immagine di input e include i campi seguenti String :-
ImagePathcontiene il percorso in cui è archiviata l'immagine. -
Labelcontiene il nome del file.
Contiene inoltre
ImageNetDataun metodoReadFromFileche carica più file di immagine archiviati nelimageFolderpercorso specificato e li restituisce come raccolta diImageNetDataoggetti.-
Creare la classe di stima nella directory DataStructures .
In Esplora soluzioni fare clic con il pulsante destro del mouse sulla directory DataStructures e quindi scegliere Aggiungi>nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il campo Nome in ImageNetPrediction.cs. Quindi selezionare Aggiungi.
Il file ImageNetPrediction.cs viene aperto nell'editor di codice. Aggiungere la direttiva seguente
usingall'inizio di ImageNetPrediction.cs:using Microsoft.ML.Data;Rimuovere la definizione di classe esistente e aggiungere il codice seguente per la
ImageNetPredictionclasse al file ImageNetPrediction.cs :public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPredictionè la classe di dati di stima e ha il campo seguentefloat[]:-
PredictedLabelscontiene le dimensioni, il punteggio di oggettività e le probabilità di classe per ogni delle caselle di delimitazione rilevate in un'immagine.
-
Inizializzare le variabili
La classe MLContext è un punto di partenza per tutte le operazioni di ML.NET e l'inizializzazione mlContext crea un nuovo ambiente ML.NET che può essere condiviso tra gli oggetti del flusso di lavoro di creazione del modello. È simile, concettualmente, a DBContext in Entity Framework.
Inizializzare la mlContext variabile con una nuova istanza di MLContext aggiungendo la riga seguente sotto il outputFolder campo .
MLContext mlContext = new MLContext();
Creare un parser per l'output del modello post-elaborazione
Il modello segmenta un'immagine in una 13 x 13 griglia, in cui ogni cella della griglia è 32px x 32px. Ogni cella della griglia contiene 5 riquadri delimitatori degli oggetti potenziali. Un rettangolo delimitatore ha 25 elementi:
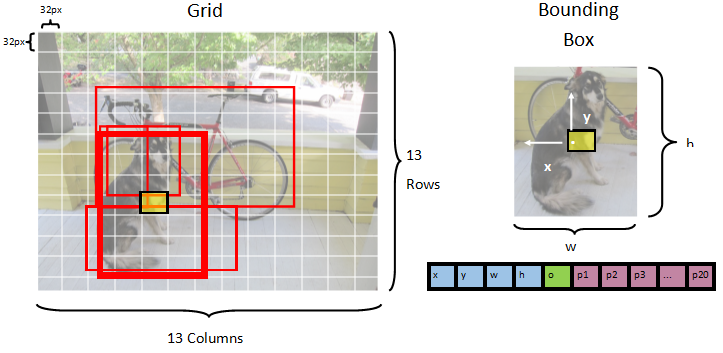
-
xla posizione x del centro della bounding box rispetto alla cella della griglia a cui è associato. -
yla posizione y del centro della casella di delimitazione rispetto alla cella della griglia a cui è associata. -
wla larghezza della "bounding box". -
haltezza della scatola di delimitazione. -
ovalore di confidenza che un oggetto esiste all'interno del rettangolo di selezione, noto anche come punteggio di oggettità. -
p1-p20probabilità di classe per ognuna delle 20 classi stimate dal modello.
In totale, i 25 elementi che descrivono ciascuno dei 5 bounding box costituiscono i 125 elementi contenuti in ogni cella della griglia.
L'output generato dal modello ONNX con training preliminare è una matrice float di lunghezza 21125, che rappresenta gli elementi di un tensore con dimensioni 125 x 13 x 13. Per trasformare le stime generate dal modello in un tensore, è necessario eseguire alcune operazioni di post-elaborazione. A tale scopo, creare un set di classi per analizzare l'output.
Aggiungere una nuova directory al progetto per organizzare il set di classi parser.
- In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e quindi scegliere Aggiungi>nuova cartella. Quando la nuova cartella viene visualizzata in Esplora soluzioni, denominarla "YoloParser".
Creare rettangoli di delimitazione e dimensioni
L'output dei dati del modello include le coordinate e le dimensioni delle scatole di delimitazione degli oggetti all'interno dell'immagine. Creare una classe base per le dimensioni.
In Esplora soluzioni fare clic con il pulsante destro del mouse sulla directory YoloParser e quindi scegliere Aggiungi>nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il campo Nome in DimensionsBase.cs. Quindi selezionare Aggiungi.
Il file DimensionsBase.cs viene aperto nell'editor di codice. Rimuovere tutte le direttive e la
usingdefinizione di classe esistente.Aggiungere il codice seguente per la
DimensionsBaseclasse al file DimensionsBase.cs :public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBaseha le proprietà seguentifloat:-
Xcontiene la posizione dell'oggetto lungo l'asse x. -
Ycontiene la posizione dell'oggetto lungo l'asse y. -
Heightcontiene l'altezza dell'oggetto . -
Widthcontiene la larghezza dell'oggetto.
-
Quindi, crea una classe per le tue bounding box.
In Esplora soluzioni fare clic con il pulsante destro del mouse sulla directory YoloParser e quindi scegliere Aggiungi>nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il campo Nome in YoloBoundingBox.cs. Quindi selezionare Aggiungi.
Il file YoloBoundingBox.cs viene aperto nell'editor di codice. Aggiungere la direttiva seguente
usingall'inizio di YoloBoundingBox.cs:using System.Drawing;Appena sopra la definizione di classe esistente, aggiungere una nuova definizione di classe denominata
BoundingBoxDimensionsche eredita dalla classeDimensionsBaseper contenere le dimensioni del rispettivo bounding box.public class BoundingBoxDimensions : DimensionsBase { }Rimuovere la definizione di classe esistente
YoloBoundingBoxe aggiungere il codice seguente per laYoloBoundingBoxclasse al file YoloBoundingBox.cs :public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBoxha le proprietà seguenti:-
Dimensionscontiene le dimensioni del riquadro di delimitazione. -
Labelcontiene la classe dell'oggetto rilevato all'interno del riquadro delimitatore. -
Confidencecontiene l'attendibilità della classe . -
Rectcontiene la rappresentazione del rettangolo del riquadro di delimitazione delle sue dimensioni. -
BoxColorcontiene il colore associato alla rispettiva classe utilizzata per disegnare sull'immagine.
-
Creare il parser
Ora che vengono create le classi per le dimensioni e i rettangoli di delimitazione, è possibile creare il parser.
In Esplora soluzioni fare clic con il pulsante destro del mouse sulla directory YoloParser e quindi scegliere Aggiungi>nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il campo Nome in YoloOutputParser.cs. Quindi selezionare Aggiungi.
Il file YoloOutputParser.cs viene aperto nell'editor di codice. Aggiungere le direttive seguenti
usingall'inizio di YoloOutputParser.cs:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;All'interno della definizione di classe esistente
YoloOutputParseraggiungere una classe nidificata contenente le dimensioni di ognuna delle celle nell'immagine. Aggiungere il codice seguente per laCellDimensionsclasse che eredita dallaDimensionsBaseclasse all'inizio della definizione dellaYoloOutputParserclasse.class CellDimensions : DimensionsBase { }All'interno della definizione della
YoloOutputParserclasse aggiungere le costanti e il campo seguenti.public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;-
ROW_COUNTè il numero di righe nella griglia in cui l'immagine è divisa. -
COL_COUNTè il numero di colonne nella griglia in cui l'immagine è divisa. -
CHANNEL_COUNTè il numero totale di valori contenuti in una cella della griglia. -
BOXES_PER_CELLè il numero di rettangoli delimitatori in una cella, -
BOX_INFO_FEATURE_COUNTè il numero di funzionalità contenute all'interno di una casella (x,y, altezza, larghezza, attendibilità). -
CLASS_COUNTè il numero di stime di classe contenute in ogni rettangolo di selezione. -
CELL_WIDTHè la larghezza di una cella nella griglia dell'immagine. -
CELL_HEIGHTè l'altezza di una cella nella griglia dell'immagine. -
channelStrideè la posizione iniziale della cella corrente nella griglia.
Quando il modello esegue una stima, nota anche come assegnazione dei punteggi, divide l'immagine
416px x 416pxdi input in una griglia di celle le dimensioni di13 x 13. Ogni cella contiene è32px x 32px. All'interno di ogni cella sono presenti 5 caselle di delimitazione, ognuna contenente 5 caratteristiche (x, y, larghezza, altezza, affidabilità). Inoltre, ogni bounding box contiene la probabilità di ciascuna delle classi, che in questo caso sono 20. Pertanto, ogni cella contiene 125 informazioni (5 caratteristiche + 20 probabilità di classe).-
Creare un elenco di ancoraggi per tutti e 5 i rettangoli al di sotto di channelStride.
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
Gli ancoraggi sono rapporti predefiniti di altezza e larghezza delle scatole di delimitazione. La maggior parte degli oggetti o delle classi rilevate da un modello ha rapporti simili. Questo è utile quando si tratta di creare box di delimitazione. Invece di prevedere i rettangoli di selezione, viene calcolato l'offset rispetto alle dimensioni predefinite, il che diminuisce quindi il calcolo necessario per prevedere il rettangolo di selezione. In genere, questi rapporti di ancoraggio vengono calcolati in base al set di dati usato. In questo caso, poiché il dataset è noto e i valori sono stati precomputati, gli ancoraggi possono essere inseriti manualmente.
Definire quindi le etichette o le classi previste dal modello. Questo modello stima 20 classi, ovvero un subset del numero totale di classi stimate dal modello YOLOv2 originale.
Aggiungere l'elenco di etichette sotto .anchors
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
Esistono colori associati a ognuna delle classi. Assegnare i colori della classe sotto :labels
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
Creare funzioni helper
Esistono una serie di passaggi coinvolti nella fase di post-elaborazione. A tale scopo, è possibile usare diversi metodi helper.
I metodi helper usati dal parser sono:
-
Sigmoidapplica la funzione sigmoid che restituisce un numero compreso tra 0 e 1. -
Softmaxnormalizza un vettore di input in una distribuzione di probabilità. -
GetOffsetesegue il mapping degli elementi nell'output unidimensionale del modello alla posizione corrispondente in un125 x 13 x 13tensore. -
ExtractBoundingBoxesestrae le dimensioni del rettangolo delimitatore usando ilGetOffsetmetodo dall'output del modello. -
GetConfidenceestrae il valore di attendibilità che indica quanto il modello è sicuro di aver rilevato un oggetto e usa la funzioneSigmoidper trasformarlo in una percentuale. -
MapBoundingBoxToCellutilizza le dimensioni del rettangolo delimitatore e le esegue il mapping nella rispettiva cella all'interno dell'immagine. -
ExtractClassesestrae le predizioni di classe per il rilevatore di confine dall'output del modello usando il metodoGetOffsete le trasforma in una distribuzione di probabilità usando il metodoSoftmax. -
GetTopResultseleziona la classe dall'elenco delle classi stimate con la probabilità più alta. -
IntersectionOverUnionfiltra rettangoli di delimitazione sovrapposti con probabilità inferiori.
Aggiungere il codice per tutti i metodi helper sotto l'elenco di classColors.
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
Dopo aver definito tutti i metodi helper, è possibile usarli per elaborare l'output del modello.
Sotto il IntersectionOverUnion metodo creare il ParseOutputs metodo per elaborare l'output generato dal modello.
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
Creare un elenco per memorizzare le caselle di delimitazione e definire le variabili all'interno del metodo ParseOutputs.
var boxes = new List<YoloBoundingBox>();
Ogni immagine è divisa in una griglia di 13 x 13 celle. Ogni cella contiene cinque rettangoli delimitatori. Sotto la boxes variabile aggiungere il codice per elaborare tutte le caselle in ognuna delle celle.
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
All'interno del ciclo più interno, calcolate la posizione iniziale della casella corrente all'interno dell'output del modello unidimensionale.
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
Direttamente sotto, utilizzare il ExtractBoundingBoxDimensions metodo per ottenere le dimensioni del rettangolo di selezione corrente.
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
Usare quindi il GetConfidence metodo per ottenere la confidenza per il rettangolo di selezione corrente.
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
Successivamente, utilizzare il metodo per eseguire il MapBoundingBoxToCell mapping del rettangolo di selezione corrente alla cella corrente in fase di elaborazione.
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
Prima di eseguire altre operazioni di elaborazione, verificare se il valore di attendibilità è maggiore della soglia specificata. In caso contrario, elaborare il raccordo statico successivo.
if (confidence < threshold)
continue;
In caso contrario, continuare a elaborare l'output. Il passaggio successivo consiste nell'ottenere la distribuzione delle probabilità delle classi previste per il bounding box corrente usando il ExtractClasses metodo.
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
Usare quindi il GetTopResult metodo per ottenere il valore e l'indice della classe con la probabilità più alta per la casella corrente e calcolarne il punteggio.
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
Utilizzare per topScore mantenere di nuovo solo i rettangoli di delimitazione che superano la soglia specificata.
if (topScore < threshold)
continue;
Infine, se il rettangolo di selezione corrente supera la soglia, creare un nuovo oggetto BoundingBox e aggiungerlo alla lista boxes.
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
Dopo l'elaborazione di tutte le celle nell'immagine, restituire l'elenco boxes . Aggiungere l'istruzione return seguente sotto il ciclo for-most esterno nel ParseOutputs metodo .
return boxes;
Filtrare i riquadri sovrapposti
Ora che tutti i rettangoli delimitatori altamente sicuri sono stati estratti dall'output del modello, è necessario eseguire ulteriori filtri per rimuovere le immagini sovrapposte. Aggiungere un metodo denominato FilterBoundingBoxes sotto il ParseOutputs metodo :
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
All'interno del FilterBoundingBoxes metodo, iniziare creando una matrice uguale alle dimensioni delle caselle rilevate e contrassegnando tutti gli slot come attivi o pronti per l'elaborazione.
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
Ordinare quindi l'elenco contenente i rettangoli delimitatori in ordine decrescente in base all'attendibilità.
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
Successivamente, creare un elenco per contenere i risultati filtrati.
var results = new List<YoloBoundingBox>();
Iniziare a elaborare ogni rettangolo delimitatore eseguendo l'iterazione su ogni rettangolo delimitatore.
for (int i = 0; i < boxes.Count; i++)
{
}
All'interno di questo ciclo for, controllare se è possibile elaborare il bounding box corrente.
if (isActiveBoxes[i])
{
}
In tal caso, aggiungere il rettangolo di selezione all'elenco dei risultati. Se i risultati superano il limite specificato di caselle da estrarre, interrompere il ciclo. Aggiungere il codice seguente all'interno dell'istruzione if.
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
In caso contrario, esaminare le bounding box adiacenti. Aggiungere il codice seguente sotto il controllo del limite di caselle.
for (var j = i + 1; j < boxes.Count; j++)
{
}
Come la prima casella, se la casella adiacente è attiva o pronta per l'elaborazione, usare il IntersectionOverUnion metodo per controllare se la prima casella e la seconda casella superano la soglia specificata. Aggiungere il codice seguente al ciclo for più interno.
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
All'esterno del ciclo for-most interno che controlla i rettangoli di delimitazione adiacenti, verificare se sono presenti rettangoli di delimitazione rimanenti da elaborare. In caso contrario, uscire dal ciclo for esterno.
if (activeCount <= 0)
break;
Infine, al di fuori del ciclo for iniziale del metodo FilterBoundingBoxes, restituire i risultati:
return results;
Ottimo. È ora possibile usare questo codice insieme al modello per l'assegnazione dei punteggi.
Usare il modello per l'assegnazione dei punteggi
Proprio come per la post-elaborazione, esistono alcuni passaggi nei passaggi di assegnazione dei punteggi. A tale scopo, aggiungere una classe che conterrà la logica di assegnazione dei punteggi al progetto.
In Esplora soluzioni fare clic con il pulsante destro del mouse sul progetto e quindi scegliere Aggiungi>nuovo elemento.
Nella finestra di dialogo Aggiungi nuovo elemento selezionare Classe e modificare il campo Nome in OnnxModelScorer.cs. Quindi selezionare Aggiungi.
Il file OnnxModelScorer.cs viene aperto nell'editor di codice. Aggiungere le direttive seguenti
usingall'inizio di OnnxModelScorer.cs:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;All'interno della definizione della
OnnxModelScorerclasse aggiungere le variabili seguenti.private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();Direttamente sotto, creare un costruttore per la
OnnxModelScorerclasse che inizializzerà le variabili definite in precedenza.public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }Dopo aver creato il costruttore, definire un paio di struct che contengono variabili correlate alle impostazioni dell'immagine e del modello. Creare uno struct denominato
ImageNetSettingsper contenere l'altezza e la larghezza prevista come input per il modello.public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }Successivamente, creare un altro struct denominato
TinyYoloModelSettingsche contiene i nomi dei livelli di input e output del modello. Per visualizzare il nome dei livelli di input e output del modello, è possibile usare uno strumento come Netron.public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }Creare quindi il primo set di metodi usati per l'assegnazione dei punteggi. Creare il
LoadModelmetodo all'interno dellaOnnxModelScorerclasse.private ITransformer LoadModel(string modelLocation) { }All'interno del
LoadModelmetodo aggiungere il codice seguente per la registrazione.Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET le pipeline devono conoscere lo schema dei dati su cui operare quando viene chiamato il
Fitmetodo . In questo caso, verrà usato un processo simile al training. Tuttavia, poiché non viene eseguito alcun training effettivo, è accettabile usare un oggetto vuotoIDataView. Creare un nuovoIDataViewoggetto per la pipeline da un elenco vuoto.var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());Di seguito, definire la pipeline. La pipeline sarà costituita da quattro trasformazioni.
-
LoadImagescarica l'immagine come bitmap. -
ResizeImagesridimensiona l'immagine in base alle dimensioni specificate (in questo caso ,416 x 416). -
ExtractPixelsmodifica la rappresentazione in pixel dell'immagine da una bitmap a un vettore numerico. -
ApplyOnnxModelcarica il modello ONNX e lo usa per assegnare punteggi ai dati forniti.
Important
Applicare modelli solo da origini attendibili. L'applicazione di modelli da origini non attendibili è un rischio per la sicurezza.
Definire la pipeline nel
LoadModelmetodo sotto ladatavariabile .var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));È il momento di istanziare il modello per l'assegnazione dei punteggi. Chiamare il
Fitmetodo nella pipeline e restituirlo per un'ulteriore elaborazione.var model = pipeline.Fit(data); return model;-
Dopo il caricamento del modello, può essere usato per eseguire stime. Per facilitare questo processo, creare un metodo denominato PredictDataUsingModel sotto il LoadModel metodo .
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
All'interno di PredictDataUsingModelaggiungere il codice seguente per la registrazione.
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
Usare quindi il Transform metodo per assegnare un punteggio ai dati.
IDataView scoredData = model.Transform(testData);
Estrarre le probabilità stimate e restituirle per un'elaborazione aggiuntiva.
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
Dopo aver configurato entrambi i passaggi, combinarli in un unico metodo. Sotto il PredictDataUsingModel metodo aggiungere un nuovo metodo denominato Score.
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
Quasi lì! Ora è il momento di mettere tutto da usare.
Individuare gli oggetti
Ora che tutta la configurazione è stata completata, è possibile rilevare alcuni oggetti.
Assegnare punteggi e analizzare gli output del modello
Sotto la creazione della mlContext variabile aggiungere un'istruzione try-catch.
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
All'interno del try blocco iniziare a implementare la logica di rilevamento degli oggetti. Prima di tutto, caricare i dati in un oggetto IDataView.
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
Creare quindi un'istanza di OnnxModelScorer e usarla per assegnare un punteggio ai dati caricati.
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
A questo punto è tempo per il passaggio di post-elaborazione. Creare un'istanza di YoloOutputParser e usarla per elaborare l'output del modello.
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
Dopo aver elaborato l'output del modello, si procede a disegnare i box delimitatori sulle immagini.
Visualizzare le previsioni
Dopo che il modello ha assegnato un punteggio alle immagini e gli output sono stati elaborati, i rettangoli delimitatori devono essere disegnati sull'immagine. A tale scopo, aggiungere un metodo denominato DrawBoundingBox sotto il GetAbsolutePath metodo all'interno di Program.cs.
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
Prima di tutto, caricare l'immagine e ottenere le dimensioni di altezza e larghezza nel DrawBoundingBox metodo .
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
Poi, crea un ciclo for-each per iterare su ciascuno dei rettangoli di delimitazione rilevati dal modello.
foreach (var box in filteredBoundingBoxes)
{
}
All'interno del ciclo for-each, ottenere le dimensioni del rettangolo di selezione.
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
Poiché le dimensioni del riquadro delimitatore corrispondono all'input del modello di 416 x 416, adattare il riquadro delimitatore in modo che corrisponda alle dimensioni effettive dell'immagine.
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
Definire quindi un modello per il testo che verrà visualizzato sopra ogni riquadro di delimitazione. Il testo conterrà la classe dell'oggetto all'interno della rispettiva casella di rilevamento e il grado di certezza.
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
Per disegnare sull'immagine, convertirla in un Graphics oggetto .
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
All'interno del blocco di using codice ottimizzare le impostazioni dell'oggetto Graphics grafico.
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
Sotto, impostare le opzioni relative al tipo di carattere e al colore per il testo e la casella di delimitazione.
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
Creare e riempire un rettangolo sopra il rettangolo delimitatore per contenere il testo usando il FillRectangle metodo . Ciò consentirà di contrastare il testo e migliorare la leggibilità.
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
Disegnare quindi il testo e il rettangolo delimitatore sull'immagine usando i metodi DrawString e DrawRectangle.
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
All'esterno del ciclo for-each, aggiungere il codice per salvare le immagini in outputFolder.
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
Per ulteriori commenti e suggerimenti che l'applicazione sta effettuando stime come previsto in fase di esecuzione, aggiungere un metodo denominato LogDetectedObjects sotto il DrawBoundingBox metodo nel file Program.cs per restituire gli oggetti rilevati nella console.
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
Ora che sono disponibili metodi helper per creare feedback visivo dalle stime, aggiungere un ciclo for per scorrere ognuna delle immagini valutate.
for (var i = 0; i < images.Count(); i++)
{
}
All'interno del ciclo for, ottenere il nome del file di immagine e i rettangoli di delimitazione associati.
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
Di seguito, usare il DrawBoundingBox metodo per disegnare i rettangoli di delimitazione nell'immagine.
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
Infine, usare il LogDetectedObjects metodo per restituire stime nella console.
LogDetectedObjects(imageFileName, detectedObjects);
Dopo l'istruzione try-catch, aggiungere una logica aggiuntiva per indicare che il processo è stato eseguito.
Console.WriteLine("========= End of Process..Hit any Key ========");
Ecco fatto!
Results
Dopo aver seguito i passaggi precedenti, eseguire l'app console (CTRL+F5). I risultati dovrebbero essere simili all'output seguente. È possibile che vengano visualizzati avvisi o messaggi di elaborazione, ma questi messaggi sono stati rimossi dai risultati seguenti per maggiore chiarezza.
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
Per visualizzare le immagini con rettangoli delimitatori, passare alla assets/images/output/ directory . Di seguito è riportato un esempio di una delle immagini elaborate.

Congratulazioni! Hai creato con successo un modello di Machine Learning per il rilevamento degli oggetti riutilizzando un modello pre-addestrato ONNX in ML.NET.
È possibile trovare il codice sorgente per questa esercitazione nel repository dotnet/machinelearning-samples .
In questo tutorial, hai imparato come:
- Informazioni sul problema
- Scopri cos'è ONNX e come funziona con ML.NET
- Comprendere il modello
- Riutilizzare il modello con training preliminare
- Rilevare gli oggetti con un modello caricato
Vedere il repository GitHub degli esempi di Machine Learning per esplorare un esempio di rilevamento degli oggetti espanso.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.