Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La classe XmlDataDocument è una classe derivata di XmlDocument e contiene dati XML. Il vantaggio di XmlDataDocument è che fornisce un ponte tra dati relazionali e gerarchici. È un XmlDocument che può essere associato a un Oggetto DataSet e entrambe le classi possono sincronizzare le modifiche apportate ai dati contenuti nelle due classi. Un xmlDocument associato a un oggetto DataSet consente l'integrazione xml con dati relazionali e non è necessario che i dati siano rappresentati come XML o in un formato relazionale. È possibile eseguire entrambe le operazioni e non essere vincolate a una singola rappresentazione dei dati.
I vantaggi della disponibilità dei dati in due visualizzazioni sono i seguenti:
La parte strutturata di un documento XML può essere mappata a un set di dati ed essere archiviata, indicizzata e ricercata in modo efficiente.
Le trasformazioni, la convalida e la navigazione possono essere eseguite in modo efficiente tramite un modello di cursore sui dati XML archiviati in modo relazionale. A volte, può essere eseguita in modo più efficiente rispetto alle strutture relazionali rispetto a se il codice XML viene archiviato in un modello XmlDocument .
Il dataset può archiviare una parte del codice XML. Ovvero, è possibile usare XPath o XslTransform per archiviare in un oggetto DataSet solo gli elementi e gli attributi di interesse. Da qui, è possibile apportare modifiche al sottoinsieme di dati filtrato più piccolo, con le modifiche propagate ai dati più grandi in XmlDataDocument.
È anche possibile eseguire una trasformazione sui dati caricati in DataSet da SQL Server. Un'altra opzione consiste nell'associare controlli WinForm e WebForm gestiti in stile .NET Framework a un dataset popolato da un flusso di input XML.
Oltre a supportare XslTransform, XmlDataDocument espone dati relazionali a query XPath e convalida. Fondamentalmente, tutti i servizi XML sono disponibili su dati relazionali e strutture relazionali, ad esempio l'associazione di controllo, il codegen e così via, sono disponibili su una proiezione strutturata di XML senza compromettere la fedeltà XML.
Poiché XmlDataDocument viene ereditato da xmlDocument, fornisce un'implementazione del DOM W3C. Il fatto che XmlDataDocument sia associato e archivia un subset dei suoi dati all'interno di un DataSet non limita o modifica l'utilizzo come XmlDocument in alcun modo. Il codice scritto per utilizzare un xmlDocument funziona in modo non modificato rispetto a xmlDataDocument. Il set di dati fornisce la visualizzazione relazionale degli stessi dati definendo tabelle, colonne, relazioni e vincoli ed è un archivio dati utente autonomo in memoria.
La figura seguente mostra le diverse associazioni che i dati XML hanno con DataSet e XmlDataDocument:
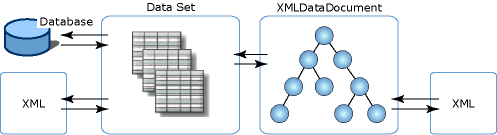
La figura mostra che i dati XML possono essere caricati direttamente in un dataset, che consente la manipolazione diretta con XML in modo relazionale. In alternativa, il codice XML può essere caricato in una classe derivata del DOM, ovvero XmlDataDocument, e successivamente caricato e sincronizzato con l'oggetto DataSet. Poiché l'oggetto DataSet e XmlDataDocument vengono sincronizzati su un singolo set di dati, le modifiche apportate ai dati in un archivio vengono riflesse nell'altro archivio.
XmlDataDocument eredita tutte le funzionalità di modifica e navigazione da XmlDocument. In alcuni casi, l'uso di XmlDataDocument e delle relative funzionalità ereditate, sincronizzate con un oggetto DataSet, è un'opzione più appropriata rispetto al caricamento di XML direttamente nell'oggetto DataSet. Nella tabella seguente vengono illustrati gli elementi da considerare quando si sceglie il metodo da usare per caricare l'oggetto DataSet.
| Quando caricare XML direttamente in un dataset | Quando sincronizzare xmlDataDocument con un oggetto DataSet |
|---|---|
| Le query di dati nel set di dati sono più semplici tramite SQL rispetto a XPath. | Le query XPath sono necessarie nei dati del DataSet. |
| La conservazione dell'ordinamento degli elementi nel codice XML di origine non è fondamentale. | La conservazione dell'ordinamento degli elementi nel codice XML di origine è fondamentale. |
| Gli spazi vuoti tra elementi e formattazione non devono essere mantenuti nel codice XML di origine. | Lo spazio vuoto e la conservazione della formattazione nel codice XML di origine sono fondamentali. |
Se il caricamento e la scrittura di XML direttamente in un dataset soddisfa le esigenze, vedere Caricamento di un dataset da XML e scrittura di un dataset come dati XML.
Se si carica l'oggetto DataSet da un xmlDataDocument in base alle proprie esigenze, vedere Sincronizzazione di un set di dati con un documento XML.
Vedere anche
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.