Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo offre una panoramica dei tipi che consentono di leggere i dati eseguiti in più buffer. Vengono usati principalmente per supportare PipeReader oggetti.
IBufferWriter<T>
System.Buffers.IBufferWriter<T> è un contratto per la scrittura memorizzata nel buffer sincrono. Al livello più basso, l'interfaccia:
- È di base e non è difficile da usare.
- Consente l'accesso a Memory<T> o Span<T>.
Memory<T>oSpan<T>può essere registrato e puoi determinare quanti elementiTsono stati scritti.
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
Metodo precedente:
- Richiede un buffer di almeno 5 byte da
IBufferWriter<byte>utilizzandoGetSpan(5). - Scrive i byte per la stringa ASCII "Hello" nell'oggetto restituito
Span<byte>. - Chiamate IBufferWriter<T> per indicare il numero di byte scritti nel buffer.
Questo metodo di scrittura usa il Memory<T>/Span<T> buffer fornito da .IBufferWriter<T> In alternativa, è possibile usare il Write metodo di estensione per copiare un buffer esistente in IBufferWriter<T>.
Write esegue il lavoro di chiamata GetSpan/Advance in base alle esigenze, quindi non è necessario chiamare Advance dopo la scrittura:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> è un'implementazione del IBufferWriter<T> cui archivio di backup è una singola matrice contigua.
Problemi comuni di IBufferWriter
-
GetSpaneGetMemoryrestituiscono un buffer con almeno la quantità di memoria richiesta. Non presupporre dimensioni esatte del buffer. - Non esiste alcuna garanzia che le chiamate successive restituiscano lo stesso buffer o un buffer della stessa dimensione.
- È necessario richiedere un nuovo buffer dopo aver chiamato
Advanceper continuare a scrivere altri dati. Non può essere scritto in un buffer acquisito in precedenza dopo la chiamata diAdvance.
ReadOnlySequence<T>
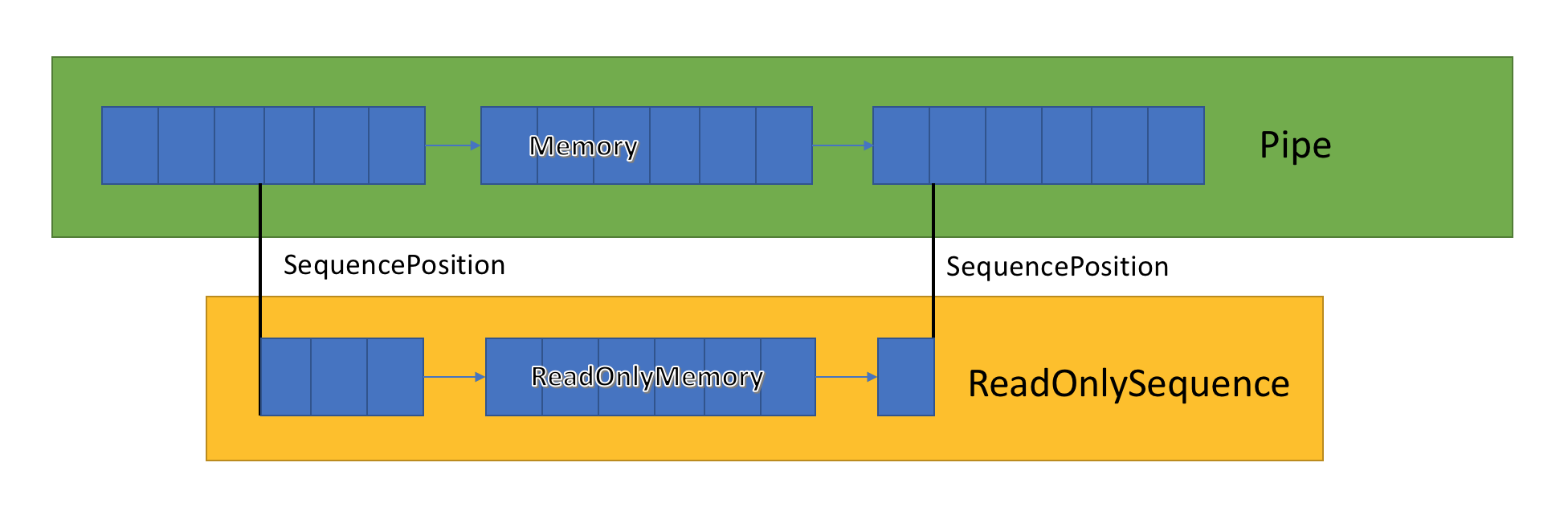
ReadOnlySequence<T> è uno struct che può rappresentare una sequenza contigua o non contigua di T. Può essere costruito da:
- Un
T[] - Un
ReadOnlyMemory<T> - Coppia di nodi ReadOnlySequenceSegment<T> di elenco collegati e indice per rappresentare la posizione iniziale e finale della sequenza.
La terza rappresentazione è quella più interessante perché ha implicazioni sulle prestazioni su varie operazioni su ReadOnlySequence<T>:
| Rappresentazione | Operazione | Complessità |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
A causa di questa rappresentazione mista, espone ReadOnlySequence<T> gli indici come SequencePosition anziché un numero intero. A SequencePosition:
- Valore non trasparente che rappresenta un indice nell'oggetto
ReadOnlySequence<T>da cui è originato. - È costituito da due parti, un numero intero e un oggetto . I due valori rappresentati sono associati all'implementazione di
ReadOnlySequence<T>.
Accedere ai dati
ReadOnlySequence<T> Espone i dati come enumerabili di ReadOnlyMemory<T>. L'enumerazione di ogni segmento può essere eseguita usando un foreach di base:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
Il metodo precedente cerca in ogni segmento un byte specifico. Se è necessario tenere traccia di ogni segmento SequencePosition, ReadOnlySequence<T>.TryGet è più appropriato. L'esempio successivo modifica il codice precedente in modo da restituire un valore SequencePosition invece di un numero intero. La restituzione di un SequencePosition ha il vantaggio di consentire al chiamante di evitare una seconda scansione per ottenere i dati a un indice specifico.
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
La combinazione di SequencePosition e TryGet agisce come un enumeratore. Il campo di posizione viene modificato all'inizio di ogni iterazione in modo da iniziare ogni segmento all'interno di ReadOnlySequence<T>.
Il metodo precedente esiste come metodo di estensione in ReadOnlySequence<T>.
PositionOf può essere usato per semplificare il codice precedente:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
Effettuare l'elaborazione di ReadOnlySequence<T>
L'elaborazione di un ReadOnlySequence<T> può risultare complessa perché i dati possono essere suddivisi tra più segmenti all'interno della sequenza. Per ottenere prestazioni ottimali, suddividere il codice in due percorsi:
- Un percorso rapido che gestisce il caso di un segmento singolo.
- Percorso lento che gestisce i dati suddivisi tra segmenti.
Esistono alcuni approcci che possono essere usati per elaborare i dati in sequenze con più segmenti:
- Usare il
SequenceReader<T>. - Analizzare i dati segmento per segmento, tenendo traccia di
SequencePositione dell'indice all'interno del segmento analizzato. In questo modo si evitano allocazioni non necessarie, ma possono risultare inefficienti, soprattutto per i buffer di piccole dimensioni. - Copiare
ReadOnlySequence<T>in un array contiguo e trattarlo come un unico buffer.- Se la dimensione di
ReadOnlySequence<T>è piccola, può essere ragionevole copiare i dati in un buffer allocato dallo stack usando l'operatore stackalloc . - Copia il
ReadOnlySequence<T>in un array condiviso usando ArrayPool<T>.Shared. - Usa
ReadOnlySequence<T>.ToArray(). Questo non è consigliato nei percorsi ad accesso frequente perché alloca un nuovoT[]nell'heap.
- Se la dimensione di
Gli esempi seguenti illustrano alcuni casi comuni per l'elaborazione ReadOnlySequence<byte>:
Elaborare dati binari
Nell'esempio seguente si analizza un numero intero big-endian di 4 byte dall'inizio di ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
Elaborare dati di testo
L'esempio seguente:
- Trova la prima nuova riga (
\r\n) inReadOnlySequence<byte>e la restituisce tramite il parametro out 'line'. - Taglia quella riga, escludendo il
\r\ndal buffer di input.
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
Segmenti vuoti
È valido archiviare segmenti vuoti all'interno di un oggetto ReadOnlySequence<T>. I segmenti vuoti possono verificarsi durante l'enumerazione esplicita dei segmenti:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
Il codice precedente crea un ReadOnlySequence<byte> oggetto con segmenti vuoti e mostra come questi segmenti vuoti influiscono sulle varie API:
-
ReadOnlySequence<T>.Slicecon unSequencePositionche punta a un segmento vuoto preserva quel segmento. -
ReadOnlySequence<T>.Slicecon un int salta i segmenti vuoti. - L'enumerazione di
ReadOnlySequence<T>riporta i segmenti vuoti.
Potenziali problemi con ReadOnlySequence<T> e SequencePosition
Esistono diversi risultati insoliti quando si tratta di un ReadOnlySequence<T>/SequencePosition contro un normale ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int:
-
SequencePositionè un marcatore di posizione per un oggetto specificoReadOnlySequence<T>, non una posizione assoluta. Poiché è relativo a un oggetto specificoReadOnlySequence<T>, non ha significato se usato all'esternoReadOnlySequence<T>della posizione in cui ha avuto origine. - L'aritmetica non può essere eseguita su
SequencePositionsenzaReadOnlySequence<T>. Ciò significa fare cose di base comeposition++è scrittoposition = ReadOnlySequence<T>.GetPosition(1, position). -
GetPosition(long)non supporta indici negativi. Ciò significa che è impossibile ottenere il penultimo carattere senza percorrere tutti i segmenti. - Non è possibile confrontare due
SequencePositionelementi, rendendo difficile:- Sapere se una posizione è maggiore o minore di un'altra posizione.
- Scrivere alcuni algoritmi di analisi.
-
ReadOnlySequence<T>è maggiore di un riferimento a un oggetto e deve essere passato da in o ref , dove possibile. Il passaggio diReadOnlySequence<T>,inorefriduce le copie dello struct. - Segmenti vuoti:
- Sono validi all'interno di un oggetto
ReadOnlySequence<T>. - Può essere visualizzato quando si esegue l'iterazione usando il
ReadOnlySequence<T>.TryGetmetodo . - Può essere visualizzato sezionando la sequenza usando il
ReadOnlySequence<T>.Slice()metodo conSequencePositionoggetti .
- Sono validi all'interno di un oggetto
SequenceReader<T>
- Nuovo tipo introdotto in .NET Core 3.0 per semplificare l'elaborazione di un oggetto
ReadOnlySequence<T>. - Unifica le differenze tra un singolo segmento
ReadOnlySequence<T>e un segmento multiploReadOnlySequence<T>. - Fornisce helper per la lettura di dati binari e di testo (
byteechar) che possono essere suddivisi tra segmenti o meno.
Esistono metodi predefiniti per gestire l'elaborazione di dati binari e delimitati. La sezione seguente illustra l'aspetto di questi stessi metodi con :SequenceReader<T>
Accedere ai dati
SequenceReader<T> dispone di metodi per enumerare i dati direttamente all'interno ReadOnlySequence<T> di . Il codice seguente è un esempio di elaborazione di un oggetto ReadOnlySequence<byte>byte alla volta:
while (reader.TryRead(out byte b))
{
Process(b);
}
CurrentSpan espone il segmento Span corrente, che è simile a quello eseguito manualmente nel metodo.
Usa la posizione
Il codice seguente è un esempio di implementazione di FindIndexOf usando SequenceReader<T>:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
Elaborare dati binari
Nell'esempio seguente si analizza un numero intero big-endian di 4 byte dall'inizio di ReadOnlySequence<byte>.
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
Elaborare dati di testo
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
Problemi comuni di SequenceReader<T>
- Poiché
SequenceReader<T>è uno struct modificabile, deve essere sempre passato per riferimento. -
SequenceReader<T>è uno struct di riferimento, quindi può essere usato solo nei metodi sincroni e non può essere memorizzato nei campi. Per altre informazioni, vedere Evitare allocazioni. -
SequenceReader<T>è ottimizzato per l'uso come lettore forward-only.Rewindè destinato a backup di piccole dimensioni che non possono essere risolti usando altreReadAPI ,PeekeIsNext.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.