Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
System.IO.Pipelines è una libreria progettata per semplificare l'I/O a prestazioni elevate in .NET. Il pacchetto è destinato a .NET Standard per compatibilità generale, .NET Framework e .NET moderno. Nelle versioni moderne di .NET è System.IO.Pipelines incluso nel framework condiviso e non richiede un pacchetto NuGet separato.
La libreria è disponibile anche come pacchetto NuGet System.IO.Pipelines .
Quale problema viene risolto da System.IO.Pipelines?
Le app che analizzano i dati di streaming sono costituite da codice boilerplate con molti flussi di codice specializzati e insoliti. Il boilerplate e il codice caso speciale sono complessi e difficili da gestire.
System.IO.Pipelines è stato progettato per:
- Avere prestazioni elevate nell'analisi dei dati di streaming.
- Ridurre la complessità del codice.
Questo codice è tipico per un server TCP che riceve messaggi delimitati da riga (delimitati da '\n') da un client:
async Task ProcessLinesAsync(NetworkStream stream)
{
var buffer = new byte[1024];
await stream.ReadAsync(buffer, 0, buffer.Length);
// Process a single line from the buffer
ProcessLine(buffer);
}
Il codice precedente presenta diversi problemi:
- L'intero messaggio (fine della riga) potrebbe non essere ricevuto in una singola chiamata a
ReadAsync. - Ignora il risultato di
stream.ReadAsync.stream.ReadAsyncrestituisce la quantità di dati letti. - Non gestisce il caso in cui più righe vengono lette in una singola chiamata
ReadAsync. - Alloca una matrice
bytea ogni lettura.
Per risolvere i problemi precedenti, apportare queste modifiche:
Mettere in buffer i dati in ingresso fino a quando non viene trovata una nuova riga.
Analizzare tutte le righe restituite nel buffer.
La riga potrebbe essere maggiore di 1 KB (1024 byte). Il codice deve ridimensionare il buffer di input fino a quando non viene trovato il delimitatore per adattare la riga completa all'interno del buffer.
- Se il buffer viene ridimensionato, vengono eseguite più copie del buffer man mano che vengono visualizzate righe più lunghe nell'input.
- Per ridurre lo spazio sprecato, compattare il buffer utilizzato per la lettura delle righe.
Valutare l'uso del pool di buffer per evitare di allocare memoria ripetutamente.
Questo codice risolve alcuni dei problemi seguenti:
async Task ProcessLinesAsync(NetworkStream stream)
{
byte[] buffer = ArrayPool<byte>.Shared.Rent(1024);
var bytesBuffered = 0;
var bytesConsumed = 0;
while (true)
{
// Calculate the amount of bytes remaining in the buffer.
var bytesRemaining = buffer.Length - bytesBuffered;
if (bytesRemaining == 0)
{
// Double the buffer size and copy the previously buffered data into the new buffer.
var newBuffer = ArrayPool<byte>.Shared.Rent(buffer.Length * 2);
Buffer.BlockCopy(buffer, 0, newBuffer, 0, buffer.Length);
// Return the old buffer to the pool.
ArrayPool<byte>.Shared.Return(buffer);
buffer = newBuffer;
bytesRemaining = buffer.Length - bytesBuffered;
}
var bytesRead = await stream.ReadAsync(buffer, bytesBuffered, bytesRemaining);
if (bytesRead == 0)
{
// EOF
break;
}
// Keep track of the amount of buffered bytes.
bytesBuffered += bytesRead;
var linePosition = -1;
do
{
// Look for a EOL in the buffered data.
linePosition = Array.IndexOf(buffer, (byte)'\n', bytesConsumed,
bytesBuffered - bytesConsumed);
if (linePosition >= 0)
{
// Calculate the length of the line based on the offset.
var lineLength = linePosition - bytesConsumed;
// Process the line.
ProcessLine(buffer, bytesConsumed, lineLength);
// Move the bytesConsumed to skip past the line consumed (including \n).
bytesConsumed += lineLength + 1;
}
}
while (linePosition >= 0);
}
}
Il codice precedente è complesso e non risolve tutti i problemi identificati. La rete ad alte prestazioni implica in genere la scrittura di codice complesso per ottimizzare le prestazioni.
System.IO.Pipelines è stato progettato per semplificare la scrittura di questo tipo di codice.
Pipa
Usare la Pipe classe per creare una PipeWriter/PipeReader coppia. Tutti i dati scritti in PipeWriter sono disponibili in PipeReader:
var pipe = new Pipe();
PipeReader reader = pipe.Reader;
PipeWriter writer = pipe.Writer;
Utilizzo di base della pipe
async Task ProcessLinesAsync(Socket socket)
{
var pipe = new Pipe();
Task writing = FillPipeAsync(socket, pipe.Writer);
Task reading = ReadPipeAsync(pipe.Reader);
await Task.WhenAll(reading, writing);
}
async Task FillPipeAsync(Socket socket, PipeWriter writer)
{
const int minimumBufferSize = 512;
while (true)
{
// Allocate at least 512 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(minimumBufferSize);
try
{
int bytesRead = await socket.ReceiveAsync(memory, SocketFlags.None);
if (bytesRead == 0)
{
break;
}
// Tell the PipeWriter how much was read from the Socket.
writer.Advance(bytesRead);
}
catch (Exception ex)
{
LogError(ex);
break;
}
// Make the data available to the PipeReader.
FlushResult result = await writer.FlushAsync();
if (result.IsCompleted)
{
break;
}
}
// By completing PipeWriter, tell the PipeReader that there's no more data coming.
await writer.CompleteAsync();
}
async Task ReadPipeAsync(PipeReader reader)
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
while (TryReadLine(ref buffer, out ReadOnlySequence<byte> line))
{
// Process the line.
ProcessLine(line);
}
// Tell the PipeReader how much of the buffer has been consumed.
reader.AdvanceTo(buffer.Start, buffer.End);
// Stop reading if there's no more data coming.
if (result.IsCompleted)
{
break;
}
}
// Mark the PipeReader as complete.
await reader.CompleteAsync();
}
bool TryReadLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
// Look for a EOL in the buffer.
SequencePosition? position = buffer.PositionOf((byte)'\n');
if (position == null)
{
line = default;
return false;
}
// Skip the line + the \n.
line = buffer.Slice(0, position.Value);
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
return true;
}
Due cicli gestiscono la lettura e la scrittura:
-
FillPipeAsynclegge daSockete scrive inPipeWriter. -
ReadPipeAsynclegge daPipeReadere analizza le righe in ingresso.
Non vengono allocati buffer espliciti. Tutta la gestione del buffer viene delegata alle implementazioni PipeReader e PipeWriter. La delega della gestione del buffer semplifica l'utilizzo del codice per concentrarsi esclusivamente sulla logica di business.
Nel primo ciclo:
- PipeWriter.GetMemory(Int32) viene chiamato per ottenere memoria dallo scrittore sottostante.
-
PipeWriter.Advance(Int32) viene chiamato per indicare a
PipeWriterla quantità di dati scritti nel buffer. -
PipeWriter.FlushAsync viene chiamato per rendere i dati disponibili per
PipeReader.
Nel secondo ciclo, PipeReader utilizza i buffer scritti da PipeWriter. I buffer provengono dal socket. Chiamata a PipeReader.ReadAsync:
Restituisce un oggetto ReadResult contenente due informazioni importanti:
- I dati vengono letti sotto forma di ReadOnlySequence<T>.
- Valore booleano
IsCompletedche indica se è stata raggiunta la fine dei dati (EOF).
Dopo aver trovato il delimitatore di fine riga (EOL) e aver analizzato la riga:
- La logica elabora il buffer per ignorare gli elementi già elaborati.
-
PipeReader.AdvanceTo viene chiamato per indicare a
PipeReaderla quantità di dati utilizzati ed esaminati.
I cicli del lettore e dello scrittore terminano chiamando PipeReader.Complete e PipeWriter.Complete. La chiamata Complete rilascia la memoria allocata dal sottostante Pipe.
Backpressure e controllo del flusso
Idealmente, le operazioni di lettura e analisi funzionano insieme:
- Il thread di lettura utilizza i dati dalla rete e li inserisce nei buffer.
- Il thread di analisi è responsabile della costruzione delle strutture di dati appropriate.
In genere, l'analisi richiede più tempo rispetto alla semplice copia di blocchi di dati dalla rete:
- Il thread di lettura precede il thread di analisi.
- Il thread di lettura deve rallentare o allocare più memoria per archiviare i dati per il thread di analisi.
Per ottenere prestazioni ottimali, è necessario trovare un equilibrio tra pause frequenti e allocazione di più memoria.
Per risolvere il problema precedente, Pipe dispone di due impostazioni per controllare il flusso di dati:
- PauseWriterThreshold: determina la quantità di dati da memorizzare nel buffer prima della sospensione delle chiamate da FlushAsync.
- ResumeWriterThreshold: determina il volume di dati che il lettore deve monitorare prima che le chiamate a PipeWriter.FlushAsync riprendano.
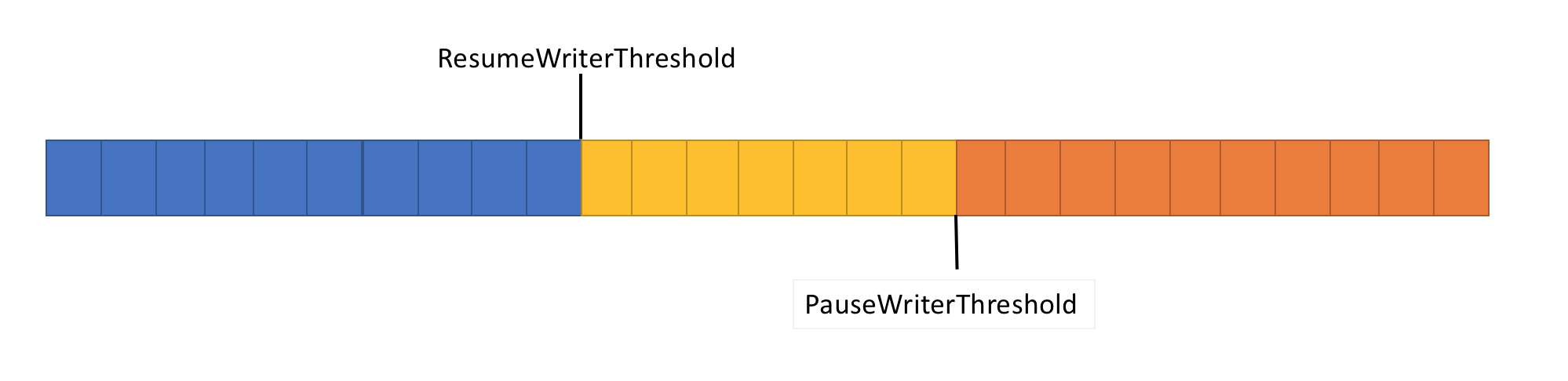
- Restituisce un oggetto incompleto
ValueTask<FlushResult>quando la quantità di dati nell'oggettoPipeintersecaPauseWriterThreshold. - Completa
ValueTask<FlushResult>quando diventa inferiore aResumeWriterThreshold.
Due valori vengono usati per evitare il ciclo rapido, che può verificarsi se viene usato un valore.
Esempi
// The Pipe will start returning incomplete tasks from FlushAsync until
// the reader examines at least 5 bytes.
var options = new PipeOptions(pauseWriterThreshold: 10, resumeWriterThreshold: 5);
var pipe = new Pipe(options);
PipeScheduler
In genere, quando si usano async e await, il codice asincrono riprende su un oggetto TaskScheduler o sull'oggetto corrente SynchronizationContext.
Quando si esegue l'I/O, è importante avere un controllo dettagliato sulla posizione in cui viene eseguito l'I/O. Questo controllo consente di sfruttare in modo efficace le cache della CPU. Una memorizzazione nella cache efficiente è fondamentale per le app ad alte prestazioni come i server Web. PipeScheduler fornisce il controllo sulla posizione in cui vengono eseguiti i callback asincroni. Per impostazione predefinita:
- L'attuale SynchronizationContext è utilizzato.
- Se non è presente
SynchronizationContext, usa il pool di thread per eseguire i callback.
public static void Main(string[] args)
{
var writeScheduler = new SingleThreadPipeScheduler();
var readScheduler = new SingleThreadPipeScheduler();
// Tell the Pipe what schedulers to use and disable the SynchronizationContext.
var options = new PipeOptions(readerScheduler: readScheduler,
writerScheduler: writeScheduler,
useSynchronizationContext: false);
var pipe = new Pipe(options);
}
// This is a sample scheduler that async callbacks on a single dedicated thread.
public class SingleThreadPipeScheduler : PipeScheduler
{
private readonly BlockingCollection<(Action<object> Action, object State)> _queue =
new BlockingCollection<(Action<object> Action, object State)>();
private readonly Thread _thread;
public SingleThreadPipeScheduler()
{
_thread = new Thread(DoWork);
_thread.Start();
}
private void DoWork()
{
foreach (var item in _queue.GetConsumingEnumerable())
{
item.Action(item.State);
}
}
public override void Schedule(Action<object?> action, object? state)
{
if (state is not null)
{
_queue.Add((action, state));
}
// else log the fact that _queue.Add was not called.
}
}
PipeScheduler.ThreadPool è l'implementazione di PipeScheduler che accoda i callback al pool di thread.
PipeScheduler.ThreadPool è il valore predefinito e in genere la scelta migliore.
PipeScheduler.Inline può causare conseguenze impreviste, ad esempio deadlock.
Reimpostazione della pipe
Il riutilizzo dell'oggetto Pipe è spesso efficiente. Per reimpostare la pipe, chiamare PipeReaderReset quando sia PipeReader che PipeWriter sono completi.
PipeReader
PipeReader gestisce la memoria per conto del chiamante.
Chiamare semprePipeReader.AdvanceTo dopo aver chiamato PipeReader.ReadAsync. Ciò consente a PipeReader di sapere quando il chiamante ha finito di utilizzare la memoria in modo che possa essere monitorata. L'oggetto ReadOnlySequence<T> restituito da PipeReader.ReadAsync è valido solo fino alla chiamata a PipeReader.AdvanceTo. Non è consentito usare ReadOnlySequence<T> dopo aver chiamato PipeReader.AdvanceTo.
PipeReader.AdvanceTo accetta due argomenti SequencePosition:
- Il primo argomento determina la quantità di memoria utilizzata.
- Il secondo argomento determina la quantità di buffer osservata.
Segnare i dati come utilizzati significa che il canale può rilasciare la memoria al pool di buffer sottostante. Contrassegnare i dati come osservati controlla cosa fa la prossima chiamata a PipeReader.ReadAsync. Contrassegnare tutto come osservato significa che la chiamata successiva a PipeReader.ReadAsync non restituirà risultati fino a quando non sono presenti altri dati scritti nella pipe. Qualsiasi altro valore rende la chiamata successiva a PipeReader.ReadAsync restituire immediatamente con i dati osservati e non osservati, ma non i dati già consumati.
Scenari di lettura di dati di streaming
Durante la lettura dei dati di streaming emerge un paio di modelli tipici:
- Dato un flusso di dati, analizzare un singolo messaggio.
- Dato un flusso di dati, analizzare tutti i messaggi disponibili.
Questi esempi usano il TryParseLines metodo per analizzare i messaggi da un oggetto ReadOnlySequence<T>.
TryParseLines analizza un singolo messaggio e aggiorna il buffer di input per tagliare il messaggio analizzato dal buffer.
TryParseLines non fa parte di .NET; si tratta di un metodo scritto dall'utente usato nelle sezioni seguenti.
bool TryParseLines(ref ReadOnlySequence<byte> buffer, out Message message);
Leggere un singolo messaggio
Questo codice legge un singolo messaggio da un PipeReader e lo restituisce al chiamante.
async ValueTask<Message?> ReadSingleMessageAsync(PipeReader reader,
CancellationToken cancellationToken = default)
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
// In the event that no message is parsed successfully, mark consumed
// as nothing and examined as the entire buffer.
SequencePosition consumed = buffer.Start;
SequencePosition examined = buffer.End;
try
{
if (TryParseLines(ref buffer, out Message message))
{
// A single message was successfully parsed so mark the start of the
// parsed buffer as consumed. TryParseLines trims the buffer to
// point to the data after the message was parsed.
consumed = buffer.Start;
// Examined is marked the same as consumed here, so the next call
// to ReadSingleMessageAsync will process the next message if there's
// one.
examined = consumed;
return message;
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(consumed, examined);
}
}
return null;
}
Il codice precedente:
- Analizza un singolo messaggio.
- Aggiorna i valori di
SequencePositionconsumato eSequencePositionesaminato per puntare all'inizio del buffer di input ridotto.
I due argomenti SequencePosition vengono aggiornati perché TryParseLines rimuove il messaggio analizzato dal buffer di input. In genere, quando si analizza un singolo messaggio dal buffer, la posizione esaminata deve essere una delle seguenti:
- La fine del messaggio.
- La fine del buffer ricevuto se non è stato trovato alcun messaggio.
Il caso di messaggio singolo presenta il maggior rischio di errori. Il passaggio di valori errati a esaminare potrebbe comportare un'eccezione di memoria insufficiente o un loop infinito. Per ottenere ulteriori informazioni, vedere la sezione Problemi comuni di PipeReader in questo articolo.
Importante
ReadSingleMessageAsync non chiama PipeReader.CompleteAsync. Il chiamante è responsabile del completamento di PipeReader. La chiamata PipeReader.CompleteAsync all'interno ReadSingleMessageAsync segnala che non è possibile leggere più dati, impedendo la lettura dei messaggi successivi.
Leggere più messaggi
Questo codice legge tutti i messaggi da un PipeReader e chiama ProcessMessageAsync su ciascuno.
async Task ProcessMessagesAsync(PipeReader reader, CancellationToken cancellationToken = default)
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
if (buffer.Length > 0)
{
// The message is incomplete and there's no more data to process.
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Poiché ProcessMessagesAsync è proprietario del ciclo di lettura dei messaggi completo, chiama PipeReader.CompleteAsync al termine. A differenza del caso a messaggio singolo, il chiamante non deve completare il lettore.
ProcessMessagesAsync acquisisce la proprietà completa del ciclo di vita di PipeReader.
Annullamento
- Supporta il passaggio di un parametro CancellationToken.
- Genera un'eccezione OperationCanceledException se la
CancellationTokenviene annullata mentre è in corso un'operazione di lettura. - Supporta un modo per annullare l'operazione di lettura corrente tramite PipeReader.CancelPendingRead, evitando di generare un'eccezione. La chiamata
PipeReader.CancelPendingReadfa sì che la chiamata corrente o successiva a PipeReader.ReadAsync restituisca un oggetto ReadResult conIsCanceledimpostato sutrue. Ciò è utile per interrompere il ciclo di lettura esistente in modo non distruttivo e non eccezionale.
private PipeReader reader;
public MyConnection(PipeReader reader)
{
this.reader = reader;
}
public void Abort()
{
// Cancel the pending read so the process loop ends without an exception.
reader.CancelPendingRead();
}
public async Task ProcessMessagesAsync()
{
try
{
while (true)
{
ReadResult result = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = result.Buffer;
try
{
if (result.IsCanceled)
{
// The read was canceled. You can quit without reading the existing data.
break;
}
// Process all messages from the buffer, modifying the input buffer on each
// iteration.
while (TryParseLines(ref buffer, out Message message))
{
await ProcessMessageAsync(message);
}
// There's no more data to be processed.
if (result.IsCompleted)
{
break;
}
}
finally
{
// Since all messages in the buffer are being processed, you can use the
// remaining buffer's Start and End position to determine consumed and examined.
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
finally
{
await reader.CompleteAsync();
}
}
Problemi comuni di PipeReader
Il passaggio dei valori errati a
consumedoexaminedpotrebbe comportare la lettura dei dati già letti.Passando
buffer.Endcome esaminato potrebbe comportare:- Dati bloccati
- Un'eventuale eccezione di memoria insufficiente se i dati non vengono consumati. Ad esempio,
PipeReader.AdvanceTo(position, buffer.End)quando si elabora un singolo messaggio alla volta dal buffer.
Il passaggio dei valori errati a
consumedoexaminedpotrebbe comportare un ciclo infinito. Ad esempio,PipeReader.AdvanceTo(buffer.Start)sebuffer.Startnon è stato modificato, la chiamata successiva viene PipeReader.ReadAsync restituita immediatamente prima dell'arrivo dei nuovi dati.Il passaggio dei valori errati a
consumedoexaminedpotrebbe comportare un buffer infinito (OOM finale).L'uso ReadOnlySequence<T> dopo la chiamata PipeReader.AdvanceTo potrebbe causare un danneggiamento della memoria (uso dopo il rilascio).
Se non si riesce a chiamare Complete/CompleteAsync , potrebbe verificarsi una perdita di memoria.
Controllare ReadResult.IsCompleted e uscire dalla logica di lettura prima dell'elaborazione del buffer comportano la perdita di dati. La condizione di uscita del ciclo deve essere basata su
ReadResult.Buffer.IsEmptyeReadResult.IsCompleted. L'esecuzione errata di questa operazione potrebbe comportare un ciclo infinito.
Codice problematico
❌ Perdita di dati
ReadResult può restituire il segmento finale dei dati quando IsCompleted è impostato su true. La mancata lettura dei dati prima di uscire dal ciclo di lettura comporta la perdita di dati.
Avviso
Non usare il codice seguente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio seguente viene fornito per spiegare i problemi comuni di PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> dataLossBuffer = result.Buffer;
if (result.IsCompleted)
break;
Process(ref dataLossBuffer, out Message message);
reader.AdvanceTo(dataLossBuffer.Start, dataLossBuffer.End);
}
Avviso
Non usare il codice precedente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio precedente viene fornito per spiegare i problemi comuni di PipeReader.
❌ Cicli infiniti
La logica seguente potrebbe comportare un ciclo infinito se Result.IsCompleted è true ma non è mai presente un messaggio completo nel buffer.
Avviso
Non usare il codice seguente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio seguente viene fornito per spiegare i problemi comuni di PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (result.IsCompleted && infiniteLoopBuffer.IsEmpty)
break;
Process(ref infiniteLoopBuffer, out Message message);
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Avviso
Non usare il codice precedente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio precedente viene fornito per spiegare i problemi comuni di PipeReader.
Ecco un altro frammento di codice che presenta lo stesso problema. Verifica la presenza di un buffer non vuoto prima di controllare ReadResult.IsCompleted. Poiché si trova in un else ifoggetto, entra in un ciclo infinito se non è mai presente un messaggio completo nel buffer.
Avviso
Non usare il codice seguente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio seguente viene fornito per spiegare i problemi comuni di PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> infiniteLoopBuffer = result.Buffer;
if (!infiniteLoopBuffer.IsEmpty)
Process(ref infiniteLoopBuffer, out Message message);
else if (result.IsCompleted)
break;
reader.AdvanceTo(infiniteLoopBuffer.Start, infiniteLoopBuffer.End);
}
Avviso
Non usare il codice precedente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio precedente viene fornito per spiegare i problemi comuni di PipeReader.
❌ Applicazione non rispondente
La chiamata incondizionata di PipeReader.AdvanceTo con buffer.End nella posizione examined potrebbe comportare l'arresto dell'applicazione durante l'analisi di un singolo messaggio. La chiamata successiva a PipeReader.AdvanceTo non verrà restituita fino a quando:
- Sono presenti altri dati scritti nella pipe.
- E i nuovi dati non sono stati esaminati in precedenza.
Avviso
Non usare il codice seguente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio seguente viene fornito per spiegare i problemi comuni di PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> hangBuffer = result.Buffer;
Process(ref hangBuffer, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(hangBuffer.Start, hangBuffer.End);
if (message != null)
return message;
}
Avviso
Non usare il codice precedente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio precedente viene fornito per spiegare i problemi comuni di PipeReader.
❌ Memoria insufficiente (OOM)
Con le seguenti condizioni, questo codice mantiene il buffering fino a quando non si verifica un OutOfMemoryException.
- Nessuna dimensione massima del messaggio.
- I dati restituiti da
PipeReadernon creano un messaggio completo. Ad esempio, l'altro lato sta scrivendo un messaggio di grandi dimensioni ,ad esempio un messaggio da 4 GB.
Avviso
Non usare il codice seguente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio seguente viene fornito per spiegare i problemi comuni di PipeReader.
Environment.FailFast("This code is terrible, don't use it!");
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> thisCouldOutOfMemory = result.Buffer;
Process(ref thisCouldOutOfMemory, out Message message);
if (result.IsCompleted)
break;
reader.AdvanceTo(thisCouldOutOfMemory.Start, thisCouldOutOfMemory.End);
if (message != null)
return message;
}
Avviso
Non usare il codice precedente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio precedente viene fornito per spiegare i problemi comuni di PipeReader.
❌ Danneggiamento della memoria
Quando si scrivono degli helper che leggono il buffer, occorre copiare qualsiasi payload che viene restituito prima di chiamare Advance. Nell'esempio seguente, la memoria scartata dall'oggetto Pipe viene restituita e potrebbe essere riutilizzata per l'operazione successiva (lettura/scrittura).
Avviso
Non usare il codice seguente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio seguente viene fornito per spiegare i problemi comuni di PipeReader.
public class Message
{
public ReadOnlySequence<byte> CorruptedPayload { get; set; }
}
Environment.FailFast("This code is terrible, don't use it!");
Message message = null;
while (true)
{
ReadResult result = await reader.ReadAsync(cancellationToken);
ReadOnlySequence<byte> buffer = result.Buffer;
ReadHeader(ref buffer, out int length);
if (length <= buffer.Length)
{
message = new Message
{
// Slice the payload from the existing buffer
CorruptedPayload = buffer.Slice(0, length)
};
buffer = buffer.Slice(length);
}
if (result.IsCompleted)
break;
reader.AdvanceTo(buffer.Start, buffer.End);
if (message != null)
{
// This code is broken since reader.AdvanceTo() was called with a position *after* the buffer
// was captured.
break;
}
}
return message;
}
Avviso
Non usare il codice precedente. L'utilizzo di questo esempio porterà a perdita di dati, blocchi, problemi di sicurezza e NON deve essere copiato. L'esempio precedente viene fornito per spiegare i problemi comuni di PipeReader.
PipeWriter
PipeWriter gestisce i buffer per la scrittura per conto del chiamante.
PipeWriter implementa IBufferWriter<byte>.
IBufferWriter<byte> consente l'accesso ai buffer per eseguire operazioni di scrittura senza copie di buffer aggiuntive.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
// Request at least 5 bytes from the PipeWriter.
Memory<byte> memory = writer.GetMemory(5);
// Write directly into the buffer.
int written = Encoding.ASCII.GetBytes("Hello".AsSpan(), memory.Span);
// Tell the writer how many bytes were written.
writer.Advance(written);
await writer.FlushAsync(cancellationToken);
}
Il codice precedente:
- Richiede un buffer di almeno 5 byte da
PipeWriterutilizzando GetMemory. - Scrive i byte della stringa ASCII
"Hello"nell'oggettoMemory<byte>restituito. - Chiama Advance per indicare il numero di byte scritti nel buffer.
- Rilascia
PipeWriter, che invia i byte al dispositivo sottostante.
Il precedente metodo di scrittura usa il buffer fornito da PipeWriter. Può anche usare PipeWriter.WriteAsync, che:
- Copia il buffer esistente nell'oggetto
PipeWriter. - Chiama GetSpan, Advance in base alle esigenze e chiama FlushAsync.
async Task WriteHelloAsync(PipeWriter writer, CancellationToken cancellationToken = default)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer, there's no need to call Advance here
// (Write does that).
await writer.WriteAsync(helloBytes, cancellationToken);
}
Annullamento
FlushAsync supporta il passaggio di un oggetto CancellationToken. Se il token viene annullato mentre è presente uno scaricamento in sospeso, passare CancellationToken risulterà in OperationCanceledException.
PipeWriter.FlushAsync supporta un modo per annullare l'operazione di svuotamento corrente tramite PipeWriter.CancelPendingFlush senza generare un'eccezione. La chiamata PipeWriter.CancelPendingFlush fa sì che la chiamata corrente o successiva a PipeWriter.FlushAsync o PipeWriter.WriteAsync restituisca un oggetto FlushResult con IsCanceled impostato su true. Ciò è utile per interrompere lo scaricamento della resa in modo non distruttivo e non eccezionale.
Problemi comuni di PipeWriter
- GetSpan e GetMemory restituiscono un buffer con almeno la quantità di memoria richiesta. Non presupporre dimensioni esatte del buffer.
- Le chiamate successive non garantiscono la restituzione dello stesso buffer o di un buffer della stessa dimensione.
- È necessario richiedere un nuovo buffer dopo aver chiamato Advance per continuare a scrivere altri dati. Il buffer acquisito in precedenza non può essere scritto.
- Chiamare GetMemory o GetSpan mentre c'è una chiamata incompleta a FlushAsync non è sicura.
- Chiamare Complete o CompleteAsync mentre ci sono dati non scaricati potrebbe comportare un danneggiamento della memoria.
Suggerimenti per PipeReader e PipeWriter
Usare questi suggerimenti per usare correttamente le System.IO.Pipelines classi:
- Completare sempre PipeReader e PipeWriter, inclusa un'eccezione, se applicabile.
- Chiamare sempre PipeReader.AdvanceTo dopo aver chiamato PipeReader.ReadAsync.
- Periodicamente
awaitPipeWriter.FlushAsync durante la scrittura e controllare sempre FlushResult.IsCompleted. Interrompere la scrittura seIsCompletedètrue, poiché ciò indica che il lettore è completato e non si preoccupa più di ciò che viene scritto. - Chiamare PipeWriter.FlushAsync dopo aver scritto qualcosa a cui si desidera che
PipeReaderabbia accesso. - Non chiamare
FlushAsyncse il lettore non può iniziare fino a cheFlushAsyncnon ha terminato, perché potrebbe causare un deadlock. - Assicurarsi che solo un contesto "sia proprietario" di un oggetto
PipeReaderoPipeWriteroppure che vi acceda. Questi tipi non sono thread-safe. - Non accedere mai a un oggetto ReadResult.Buffer dopo aver chiamato PipeReader.AdvanceTo o completato l'oggetto
PipeReader.
IDuplexPipe
IDuplexPipe è un contratto per tipi che supportano sia la lettura che la scrittura. Ad esempio, una connessione di rete è rappresentata da un oggetto IDuplexPipe.
A differenza di Pipe, che contiene PipeReader e PipeWriter, IDuplexPipe rappresenta un singolo lato di una connessione duplex completa. Ciò che si scrive nel PipeWriter non verrà letto da PipeReader.
Flussi
Durante la lettura o la scrittura di dati di flusso, in genere si leggono i dati usando un deserializzatore e si scrivono dati usando un serializzatore. La maggior parte di queste API di flusso di lettura e scrittura ha un parametro Stream. Per semplificare l'integrazione con queste API esistenti, PipeReader e PipeWriter espongono un metodo AsStream.
AsStream restituisce un'implementazione Stream intorno a PipeReader o PipeWriter.
Esempio di flusso
Creare istanze PipeReader e PipeWriter usando i metodi statici Create forniti da un oggetto Stream e opzioni di creazione facoltative corrispondenti.
StreamPipeReaderOptions consente di controllare la creazione dell'istanza PipeReader con i parametri seguenti:
-
StreamPipeReaderOptions.BufferSize è la dimensione minima del buffer in byte usata quando si noleggia la memoria dal pool e l'impostazione predefinita è
4096. - Il flag StreamPipeReaderOptions.LeaveOpen determina se il flusso sottostante viene lasciato aperto dopo il completamento di
PipeReadere l'impostazione predefinita èfalse. -
StreamPipeReaderOptions.MinimumReadSize rappresenta la soglia dei byte rimanenti nel buffer prima che venga allocato un nuovo buffer. L'impostazione predefinita è
1024. -
StreamPipeReaderOptions.Pool è l'oggetto
MemoryPool<byte>utilizzato per l'allocazione della memoria e l'impostazione predefinita ènull.
StreamPipeWriterOptions consente di controllare la creazione dell'istanza PipeWriter con i parametri seguenti:
- Il flag StreamPipeWriterOptions.LeaveOpen determina se il flusso sottostante viene lasciato aperto dopo il completamento di
PipeWritere l'impostazione predefinita èfalse. -
StreamPipeWriterOptions.MinimumBufferSize rappresenta le dimensioni minime del buffer quando si noleggia la memoria da Pool, l'impostazione predefinita è
4096. -
StreamPipeWriterOptions.Pool è l'oggetto
MemoryPool<byte>utilizzato per l'allocazione della memoria e l'impostazione predefinita ènull.
Importante
Quando si creano istanze di PipeReader e PipeWriter utilizzando i metodi Create, prendere in considerazione la durata dell'oggetto Stream. Se hai bisogno di accedere al flusso dopo che il lettore o lo scrittore hanno terminato, imposta il flag LeaveOpen su true nelle opzioni di configurazione. In caso contrario, il flusso viene chiuso.
Questo codice illustra la creazione di PipeReader istanze e PipeWriter utilizzando i metodi Create di un flusso.
using System.Buffers;
using System.IO.Pipelines;
using System.Text;
class Program
{
static async Task Main()
{
using var stream = File.OpenRead("lorem-ipsum.txt");
var reader = PipeReader.Create(stream);
var writer = PipeWriter.Create(
Console.OpenStandardOutput(),
new StreamPipeWriterOptions(leaveOpen: true));
WriteUserCancellationPrompt();
var processMessagesTask = ProcessMessagesAsync(reader, writer);
var userCanceled = false;
var cancelProcessingTask = Task.Run(() =>
{
while (char.ToUpperInvariant(Console.ReadKey().KeyChar) != 'C')
{
WriteUserCancellationPrompt();
}
userCanceled = true;
// No exceptions thrown
reader.CancelPendingRead();
writer.CancelPendingFlush();
});
await Task.WhenAny(cancelProcessingTask, processMessagesTask);
Console.WriteLine(
$"\n\nProcessing {(userCanceled ? "cancelled" : "completed")}.\n");
}
static void WriteUserCancellationPrompt() =>
Console.WriteLine("Press 'C' to cancel processing...\n");
static async Task ProcessMessagesAsync(
PipeReader reader,
PipeWriter writer)
{
try
{
while (true)
{
ReadResult readResult = await reader.ReadAsync();
ReadOnlySequence<byte> buffer = readResult.Buffer;
try
{
if (readResult.IsCanceled)
{
break;
}
if (TryParseLines(ref buffer, out string message))
{
FlushResult flushResult =
await WriteMessagesAsync(writer, message);
if (flushResult.IsCanceled || flushResult.IsCompleted)
{
break;
}
}
if (readResult.IsCompleted)
{
if (!buffer.IsEmpty)
{
throw new InvalidDataException("Incomplete message.");
}
break;
}
}
finally
{
reader.AdvanceTo(buffer.Start, buffer.End);
}
}
}
catch (Exception ex)
{
Console.Error.WriteLine(ex);
}
finally
{
await reader.CompleteAsync();
await writer.CompleteAsync();
}
}
static bool TryParseLines(
ref ReadOnlySequence<byte> buffer,
out string message)
{
SequencePosition? position;
StringBuilder outputMessage = new();
while(true)
{
position = buffer.PositionOf((byte)'\n');
if (!position.HasValue)
break;
outputMessage.Append(Encoding.ASCII.GetString(buffer.Slice(buffer.Start, position.Value)))
.AppendLine();
buffer = buffer.Slice(buffer.GetPosition(1, position.Value));
};
message = outputMessage.ToString();
return message.Length != 0;
}
static ValueTask<FlushResult> WriteMessagesAsync(
PipeWriter writer,
string message) =>
writer.WriteAsync(Encoding.ASCII.GetBytes(message));
}
L'applicazione usa un oggetto StreamReader per leggere il file lorem-ipsum.txt come flusso e deve terminare con una riga vuota. Il FileStream viene passato a PipeReader.Create, che istanzia un oggetto PipeReader. L'applicazione console passa quindi il flusso di output standard a PipeWriter.Create utilizzando Console.OpenStandardOutput(). L'esempio supporta l'annullamento.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.