Principi architetturali
Suggerimento
Questo contenuto è un estratto dell'eBook Progettare applicazioni Web moderne con ASP.NET Core e Azure, disponibile in .NET Docs o come PDF scaricabile gratuitamente che può essere letto offline.

"Se i costruttori costruissero edifici come i programmatori scrivono i programmi, il primo picchio che passa distruggerebbe la civiltà."
- Gerald Weinberg
È necessario ideare e progettare soluzioni software tenendo presente l'aspetto della loro gestione. I principi indicati in questa sezione possono favorire scelte architetturali che daranno vita ad applicazioni pulite e gestibili. Generalmente, questi principi orientano verso la creazione di applicazioni contenenti componenti discreti che non sono strettamente accoppiati ad altre parti dell'applicazione, ma che comunicano tramite interfacce esplicite o sistemi di messaggistica.
Principi di progettazione comuni
Separazione delle problematiche
Un principio guida per lo sviluppo di applicazioni è la separazione dei concetti. In base a questo principio, deve esistere una separazione a livello di software in funzione delle operazioni eseguite. Ad esempio, si consideri un'applicazione che include la logica per l'identificazione di elementi importanti da visualizzare all'utente e la formattazione specifica di tali elementi per renderli più evidenti. Il comportamento responsabile della scelta degli elementi da formattare dovrebbe essere mantenuto separato dal comportamento responsabile della formattazione vera e propria degli elementi, poiché questi comportamenti rappresentano concetti distinti e solo casualmente correlati tra loro.
Dal punto di vista della progettazione, è possibile costruire in modo logico le applicazioni rispettando questo principio e separando il comportamento di business principale dalla logica dell'interfaccia utente e dell'infrastruttura. Idealmente, le regole e la logica di business dovrebbero risiedere in un progetto separato e autonomo rispetto agli altri progetti dell'applicazione. Questa separazione consente di garantire che il modello aziendale sia facile da testare e che possa evolversi senza essere strettamente accoppiato ai dettagli di implementazione di basso livello (è utile anche se le preoccupazioni dell'infrastruttura dipendono dalle astrazioni definite nel livello aziendale). La separazione dei compiti è un fattore chiave nella scelta di utilizzare i livelli nelle architetture delle applicazioni.
Incapsulamento
Parti diverse di un'applicazione devono essere isolate da altre mediante l'incapsulamento. I componenti e i livelli dell'applicazione devono essere in grado di regolare la loro implementazione interna senza interrompere i collaboratori, a patto che i contratti esterni non vengano violati. Un utilizzo corretto dell'incapsulamento consente di progettare le applicazioni con modularità e un tipo di accoppiamento debole poiché gli oggetti e i pacchetti possono essere sostituiti con implementazioni alternative, purché la stessa interfaccia venga mantenuta.
L'incapsulamento delle classi avviene limitando l'accesso esterno allo stato interno della classe. Se un attore esterno vuole modificare lo stato dell'oggetto, dovrà farlo tramite una funzione ben definita o un setter di proprietà anziché accedendo direttamente allo stato privato dell'oggetto. Analogamente, i componenti dell'applicazione e le applicazioni stesse non devono consentire la modifica diretta del loro stato bensì esporre interfacce ben definite a uso dei collaboratori. Questo approccio consente alla struttura interna dell'applicazione di evolversi nel tempo senza comportare l'interruzione dei collaboratori, purché i contratti pubblici vengano mantenuti.
Lo stato globale modificabile è antitetico all'incapsulamento. Un valore recuperato dallo stato globale modificabile in una funzione non può essere basato sul fatto di avere lo stesso valore in un'altra funzione (o ancora più avanti nella stessa funzione). La comprensione dei problemi relativi allo stato globale modificabile è uno dei motivi per cui i linguaggi di programmazione come C# supportano regole di ambito diverse, usate ovunque dalle istruzioni ai metodi alle classi. Vale la pena notare che le architetture guidate dai dati che si affidano a un database centrale per l'integrazione all'interno e tra le applicazioni scelgono esse stesse di dipendere dallo stato globale mutevole rappresentato dal database. Una considerazione fondamentale nella progettazione basata su dominio e nell'architettura pulita è come incapsulare l'accesso ai dati e come garantire che lo stato dell'applicazione non sia reso non valido dall'accesso diretto al formato di persistenza.
Inversione delle dipendenze
La direzione delle dipendenza all'interno dell'applicazione deve puntare verso l'astrazione, non verso i dettagli di implementazione. La maggior parte delle applicazioni vengono scritte in modo che le dipendenze in fase di compilazione scorrano nella direzione della fase di esecuzione, producendo un grafico delle dipendenze diretto. Ovvero, se la classe A chiama un metodo della classe B e la classe B chiama un metodo della classe C, in fase di compilazione la classe A dipende dalla classe B e la classe B dipende dalla classe C, come illustrato nella figura 4-1.
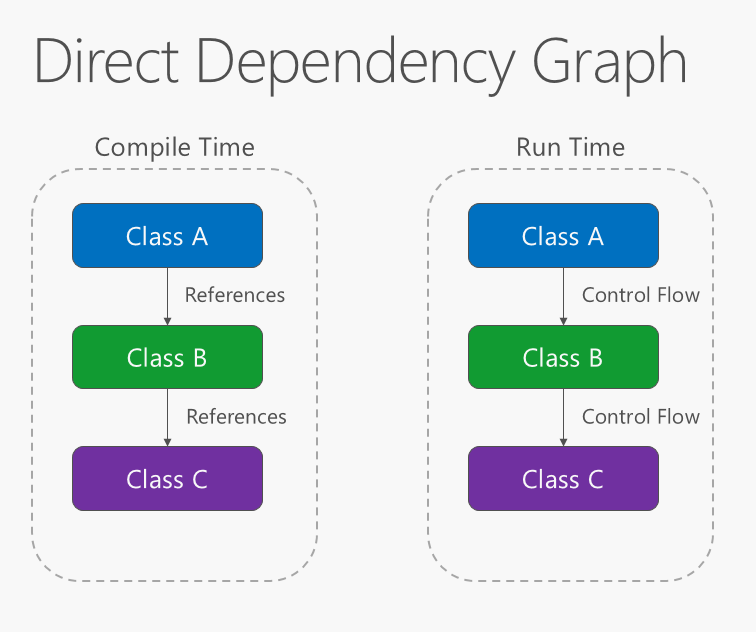
Figura 4-1. Grafico delle dipendenze dirette.
L'applicazione del principio di inversione delle dipendenze consente ad A di chiamare metodi su un'astrazione implementata da B, consentendo ad A di chiamare B in fase di esecuzione, ma a B di dipendere da un'interfaccia controllata da A in fase di compilazione pertanto invertendo le dipendenze tipiche della fase di compilazione. In fase di esecuzione, il flusso di esecuzione del programma rimane invariato, ma l'introduzione di interfacce significa che sarà possibile collegare facilmente diverse implementazioni di tali interfacce.
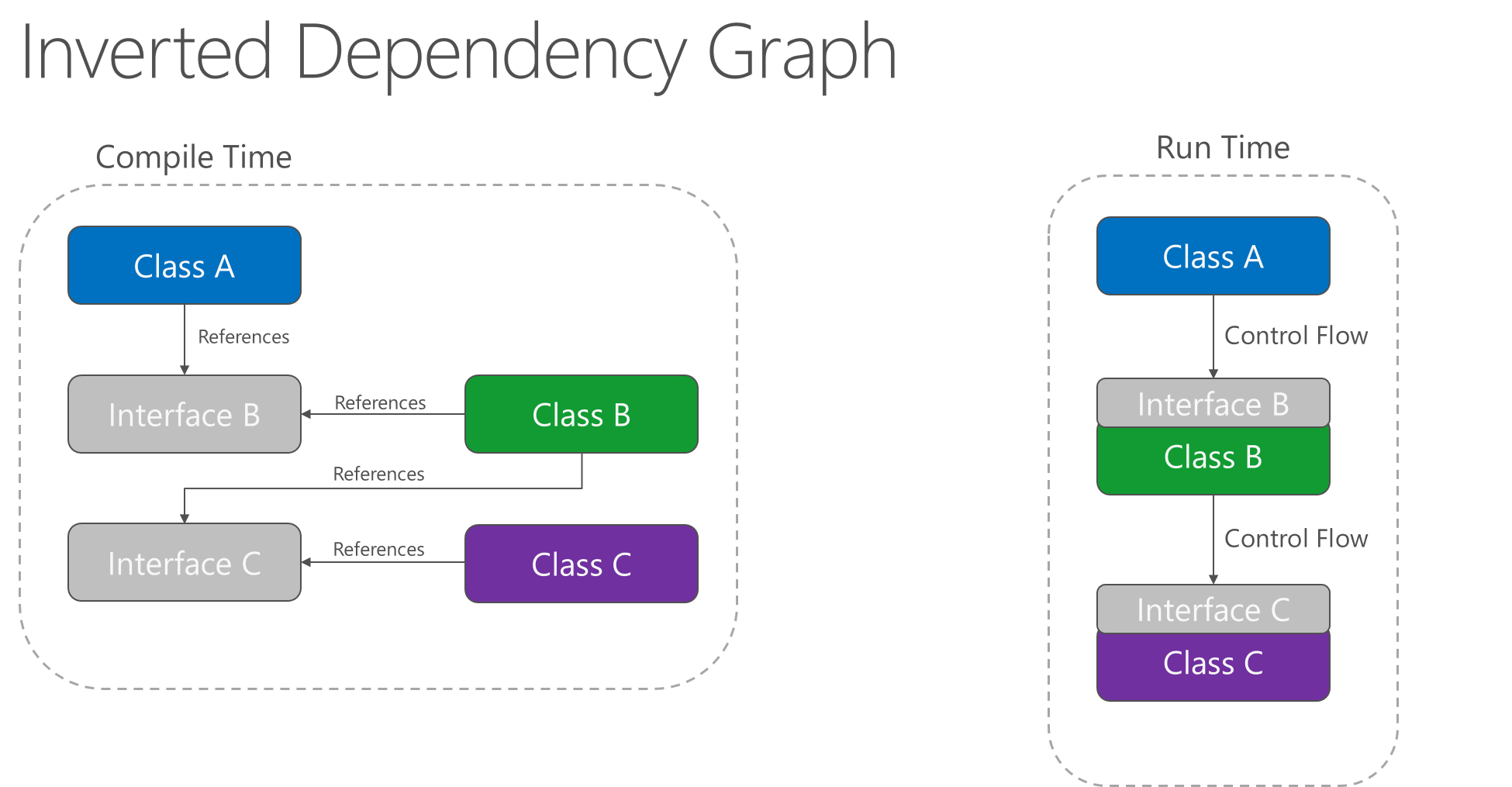
Figura 4-2. Grafico delle dipendenze inverse.
L'inversione delle dipendenze è un elemento chiave per costruire applicazioni con accoppiamento debole, perché consente di scrivere i dettagli dell'implementazione in modo che facciano riferimento ad astrazioni di alto livello e le implementino, piuttosto che il contrario. Le applicazioni così ottenute sono più testabili, modulari e gestibili. La pratica dell'inserimento di dipendenze è resa possibile dall'applicazione del principio di inversione delle dipendenze.
Dipendenze esplicite
Le classi e i metodi devono richiedere in modo esplicito gli oggetti in collaborazione di cui necessitano per funzionare correttamente. Viene chiamato Principio delle dipendenze esplicite. I costruttori di classi forniscono alle classi l'opportunità di individuare gli elementi necessari per essere in uno stato valido e per funzionare correttamente. Se si definiscono classi che possono essere create e chiamate ma che funzionano correttamente solo in presenza di alcuni componenti di infrastruttura o globali, queste classi si comportano in modo disonesto con i relativi client. Il contratto del costruttore indica al client che necessita solo degli elementi specificati, o addirittura di nessun elemento se la classe usa semplicemente un costruttore senza parametri, ma in realtà in fase di esecuzione necessita di qualcos'altro.
Se ci si attiene al principio delle dipendenze esplicite, le classi e i metodi comunicano esattamente ai relativi client ciò di cui hanno bisogno per funzionare. Seguire il principio rende il codice più autodocumentato e i contratti di codifica di contratti più intuitivi, perché gli utenti saranno sicuri che nel momento in cui forniscono quello che è richiesto sotto forma di metodi o parametri del costruttore, gli oggetti che stanno usando funzioneranno correttamente in fase di esecuzione.
Singola responsabilità
Il principio di singola responsabilità si applica alla programmazione orientata agli oggetti, ma può anche essere considerato un principio architetturale simile alla separazione dei concetti. Afferma che gli oggetti devono avere una sola responsabilità e un solo motivo per cambiare. Nello specifico, l'unica situazione in cui l'oggetto può cambiare è se il modo in cui svolge la sua unica responsabilità richiede di essere aggiornato. L'applicazione di questo principio favorisce l'elaborazione di sistemi modulari con accoppiamento debole in cui molti nuovi comportamenti possono essere implementati come nuove classi anziché aggiungere ulteriori responsabilità a classi esistenti. L'aggiunta di nuove classi è sempre una pratica più sicura rispetto alla modifica delle classi esistenti, dal momento che da queste nuove classi non dipende alcun codice.
In un'applicazione monolitica, è possibile applicare il principio di singola responsabilità ad alto livello e trasferirlo agli altri livelli dell'applicazione. La responsabilità della presentazione deve rimanere nel progetto dell'interfaccia utente, mentre la responsabilità dell'accesso ai dati deve essere mantenuta all'interno di un progetto di infrastruttura. La logica di business deve essere inclusa nel progetto principale dell'applicazione, dove può essere facilmente testata ed evolvere in modo indipendente da altre responsabilità.
Quando si applica questo principio all'architettura delle applicazioni portandolo fino all'endpoint logico, si ottengono i microservizi. Ogni microservizio deve avere una singola responsabilità. Se si presenta la necessità di estendere il comportamento di un sistema, è preferibile farlo aggiungendo ulteriori microservizi, anziché aggiungendo responsabilità a un microservizio esistente.
Altre informazioni sull'architettura dei microservizi
Don't Repeat Yourself (DRY)
In base al principio DRY, in un'applicazione va evitata la ripetizione di un comportamento relativo a un particolare concetto perché questa pratica è una frequente fonte di errori. A un certo punto, una modifica dei requisiti richiederà la modifica di questo comportamento. È probabile che almeno un'istanza del comportamento non venga aggiornata e che il sistema si comporti in modo incoerente.
Anziché duplicare la logica, è preferibile incapsularla in un costrutto di programmazione. Rendere il costrutto l'unica autorità su questo comportamento e fare in modo che qualsiasi altra parte dell'applicazione che richiede questo comportamento utilizzi il nuovo costrutto.
Nota
Evitare di associare tra loro comportamenti che sono solo casualmente ripetitivi. Ad esempio, il fatto che due costanti diverse hanno entrambe lo stesso valore non implica che dovrebbe essercene solo una, se concettualmente si riferiscono ad elementi diversi. È sempre preferibile associare la duplicazione all'astrazione errata.
Mancato riconoscimento della persistenza
Il mancato riconoscimento della persistenza riguarda i tipi che devono essere resi persistenti ma il cui codice non è influenzato dalla scelta della tecnologia di persistenza. In .NET tali tipi sono a volte definiti Plain Old CLR Object (POCO), in quanto non sono gravati dalla necessità di ereditare da una determinata classe base o di implementare un'interfaccia specifica. Il mancato riconoscimento della persistenza è utile perché consente allo stesso modello di business di essere reso permanente in più modi migliorando la flessibilità dell'applicazione. Le scelte di persistenza possono cambiare nel tempo, in funzione della tecnologia del database oppure possono servire ulteriori forme di persistenza oltre a quelle inizialmente presenti nell'applicazione, ad esempio, l'utilizzo di una cache Redis o di Azure Cosmos DB oltre a un database relazionale.
Alcuni esempi di violazioni di questo principio:
Una classe base obbligatoria.
Un'implementazione dell'interfaccia obbligatoria.
Classi responsabili del proprio salvataggio ad esempio, il criterio del record attivo.
Costruttore senza parametri obbligatorio.
Proprietà che richiedono una parola chiave virtuale.
Attributi di persistenza obbligatori.
Il requisito che le classi presentino una o più funzionalità o uno o più comportamenti precedenti rende permanente l'accoppiamento tra i tipi e aggiunge la scelta della tecnologia di persistenza, rendendo più difficoltoso adottare nuove strategie di accesso ai dati in futuro.
Contesti limitati
I contesti limitati sono un criterio centrale nell'approccio Domain-driven design. Rappresentano un modo per gestire la complessità in organizzazioni o applicazioni di grandi dimensioni tramite la suddivisione in moduli concettuali separati. Ogni modulo concettuale rappresenta quindi un contesto separato dagli altri, da qui l'aggettivo limitato, che può evolvere in modo indipendente. Ogni contesto limitato dovrebbe essere idealmente libero di scegliere i nomi per i concetti al suo interno e dovrebbe avere accesso esclusivo al proprio archivio di persistenza.
Come minimo, ogni singola applicazione web deve puntare ad essere il proprio contesto limitato, con un archivio di persistenza per il proprio modello di business, piuttosto che condividere un database con altre applicazioni. La comunicazione tra contesti limitati non avviene tramite un database condiviso bensì tramite interfacce di programmazione che consentono la generazione di eventi e logica di business in risposta alle modifiche che si verificano. I contesti limitati sono strettamente mappati a microservizi, anch'essi idealmente implementati come singoli contesti limitati.