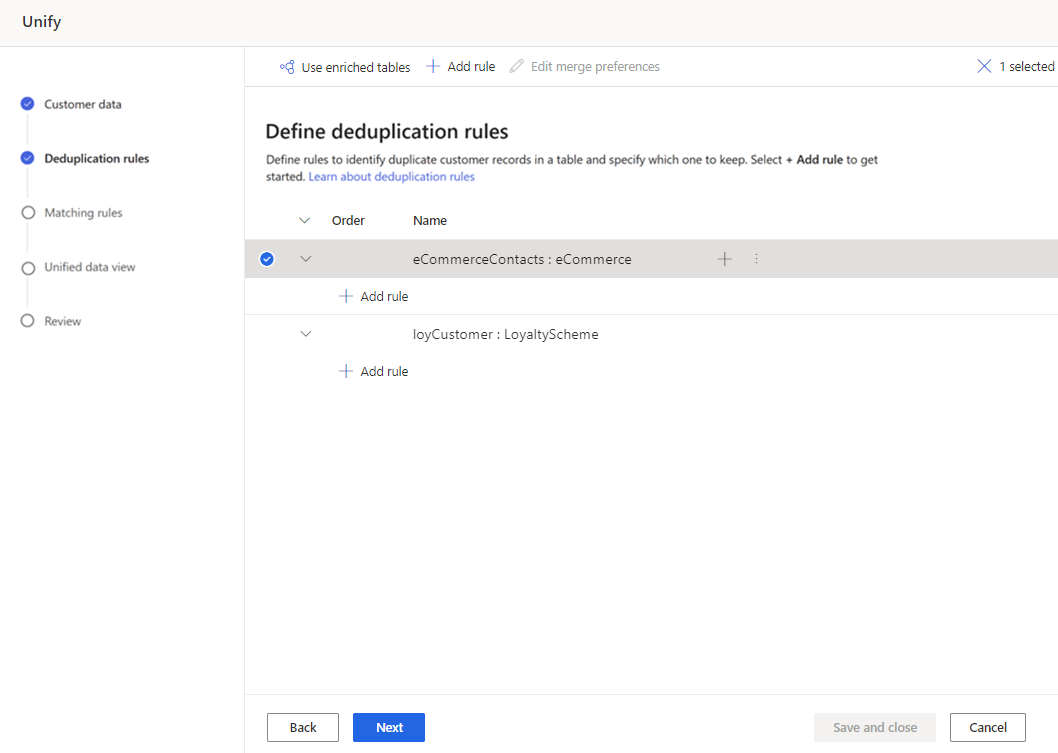
Rimuovi i duplicati in ogni tabella per l'unificazione dei dati
Il passaggio Regole di deduplicazione trova e rimuove i record duplicati per un cliente da una tabella di origine in modo che ogni cliente sia rappresentato da una singola riga in ogni tabella. Ogni tabella viene deduplicata separatamente utilizzando regole per identificare i record per un determinato cliente.
Le regole vengono elaborate in ordine. Dopo che tutte le regole sono state eseguite su tutti i record di una tabella, i gruppi di corrispondenza che condividono una riga comune vengono combinati in un unico gruppo di corrispondenza.
Definisci le regole di deduplicazione
Una buona regola identifica un cliente unico. Considerare i tuoi dati. Potrebbe essere sufficiente identificare i clienti in base a un campo come e-mail. Tuttavia, se desideri differenziare i clienti che condividono un'e-mail, puoi scegliere di avere una regola con due condizioni, corrispondenti a E-mail + Nome. Per ulteriori informazioni, consulta Best practice per la deduplicazione.
Nella pagina Regole di deduplicazione seleziona una tabella e quindi Aggiungi regola per definire le regole di deduplicazione.
Suggerimento
Se hai arricchito le tabelle a livello di origine dati per migliorare i risultati dell'unificazione, seleziona Usa tabelle arricchite nella parte superiore della pagina. Per altre informazioni, vedi Arricchimento per le origini dati.
Nel riquadro Aggiungi regola immetti le informazioni seguenti:
Seleziona campo: scegli dall'elenco dei campi disponibili della tabella di cui desideri verificare la presenza di duplicati. Scegli campi che sono probabilmente univoci per ogni singolo cliente. Ad esempio, un indirizzo e-mail o la combinazione di nome, città e numero di telefono.
Normalizza: Seleziona opzioni di normalizzazione per la colonna. La normalizzazione influisce solo sul passaggio di corrispondenza e non modifica i dati.
- Numeri: converte i simboli Unicode che rappresentano i numeri in numeri semplici.
- Simboli: rimuove simboli e caratteri speciali come !"#$%&'()*+,-./:;<=>? @[]^_`{|}~. Ad esempio, Head&Shoulder diventa HeadShoulder.
- Testo in minuscolo: converte i caratteri maiuscoli in minuscoli. "TUTTO MAIUSCOLO e titolo" diventa "tutto maiuscolo e titolo".
- Tipo (telefono, nome, indirizzo, organizzazione): standardizza nomi, titoli, numeri di telefono e indirizzi.
- Unicode in ASCII: converte i caratteri Unicode nella lettera ASCII equivalente. Ad esempio, la ề accentata viene convertita nel carattere e.
- Spazio vuoto: rimuove tutti gli spazi. Hello World diventa HelloWorld.
- Alias mapping: consente di caricare un elenco personalizzato di coppie di stringhe per indicare stringhe che dovrebbero sempre essere considerate una corrispondenza esatta.
- Bypass personalizzato: consente di caricare un elenco personalizzato di stringhe per indicare le stringhe che non devono mai corrispondere.
Precisione: imposta il livello di precisione. La precisione viene utilizzata per la corrispondenza esatta e quella fuzzy e determina come Chiudi devono essere due stringhe per essere considerate una corrispondenza.
- Di base: Scegli tra Basso (30%), Medio (60%), Alto (80%) ed Esatto (100%). Seleziona Esatto per abbinare solo i record che corrispondono al 100 percento.
- Personalizzato: Consente di impostare una percentuale per la corrispondenza dei record. Il sistema mette in corrispondenza solo i record che superano questa soglia.
Nome: nome della regola.
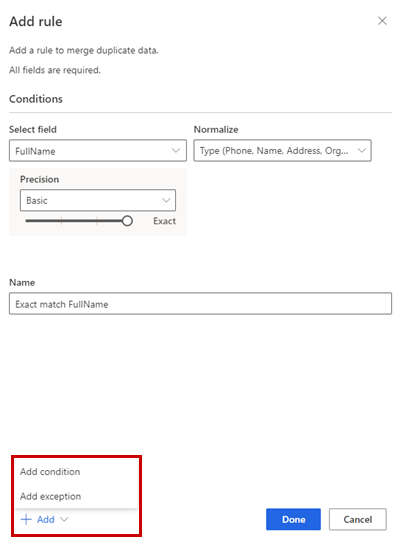
Facoltativamente, seleziona Aggiungi>Aggiungi condizione per aggiungere più condizioni alla regola. Le condizioni sono collegate a un operatore logico AND e quindi eseguite solo se tutte le condizioni sono soddisfatte.
Facoltativamente, scegli Aggiungi>Aggiungi eccezione per aggiungere eccezioni alla regola. Le eccezioni vengono utilizzate per affrontare rari casi di falsi positivi e falsi negativi.
Seleziona Fine per creare la regola.
Facoltativamente, aggiungi altre regole.
Seleziona una tabella e quindi Modifica preferenze di unione.
Nel riquadro Preferenze unione:
Scegli una delle tre opzioni per determinare quale record conservare se viene trovato un duplicato:
- Con più dati: identifica il record con le colonne con più dati come record vincitore. È l'opzione di unione predefinita.
- Piu recente: il record vincitore è quello più recente. Richiede una data o un campo numerico per definire la recency.
- Meno recente: il record vincitore è quello meno recente. Richiede una data o un campo numerico per definire la recency.
In caso di parità, il record vincente è quello con il valore della chiave primaria MAX(PK) o maggiore.
Facoltativamente, per definire le preferenze di unione sulle singole colonne di una tabella, seleziona Avanzate nella parte inferiore del riquadro. Ad esempio, puoi scegliere di conservare il messaggio e-mail più recente E l'indirizzo più completo da record diversi. Espandi la tabella per vedere tutte le colonne e definisci quale opzione utilizzare per le singole colonne. Se scegli un'opzione basata sulla recency, devi anche specificare un campo data/ora che definisca la recency.
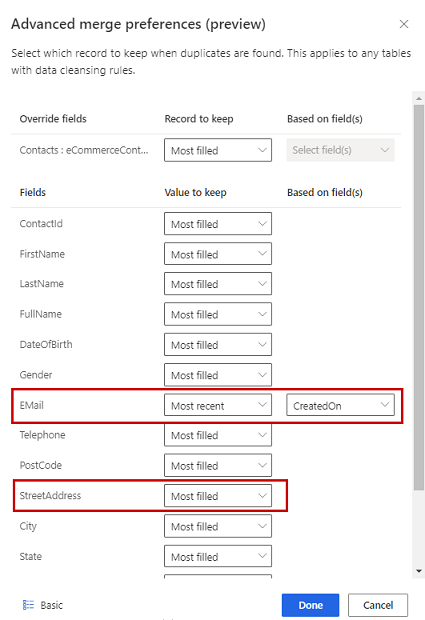
Seleziona Fine per applicare le preferenze di unione.
Dopo aver definito le regole di deduplicazione e le preferenze di unione, seleziona Avanti.
