Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questo articolo presuppone che tu sappia come utilizzare Code First Migrations negli scenari di base. In caso contrario, sarà necessario leggere Migrazioni Code First prima di continuare.
Prendi un caffè, devi leggere questo intero articolo
I problemi negli ambienti del team riguardano principalmente la fusione delle migrazioni quando due sviluppatori hanno generato migrazioni nella base di codice locale. Anche se i passaggi per risolverli sono piuttosto semplici, è necessario avere una conoscenza approfondita del funzionamento delle migrazioni. Non passare direttamente alla fine. Leggere l'intero articolo per assicurarsi di avere successo.
Alcune linee guida generali
Prima di esaminare come gestire l'unione delle migrazioni generate da più sviluppatori, ecco alcune linee guida generali per configurarti per il successo.
Ogni membro del team deve avere un database di sviluppo locale
Le migrazioni usano la tabella __MigrationsHistory per archiviare le migrazioni applicate al database. Se si hanno più sviluppatori che generano migrazioni diverse mentre cercano di lavorare sullo stesso database (e quindi condividere una tabella di __MigrationsHistory), le migrazioni diventeranno molto confuse.
Naturalmente, se si hanno membri del team che non generano migrazioni, non c'è alcun problema con cui condividono un database di sviluppo centrale.
Evitare migrazioni automatiche
La linea finale è che le migrazioni automatiche inizialmente sembrano valide negli ambienti del team, ma in realtà non funzionano. Se si vuole sapere perché, continuare a leggere, in caso contrario, è possibile passare alla sezione successiva.
Le migrazioni automatiche consentono di aggiornare lo schema del database in modo che corrisponda al modello corrente senza la necessità di generare file di codice (migrazioni basate su codice). Le migrazioni automatiche funzionerebbero molto bene in un ambiente di squadra se venissero utilizzate esclusivamente e non fossero mai generate migrazioni basate su codice. Il problema è che le migrazioni automatiche sono limitate e non gestiscono una serie di operazioni: ridenominazione di proprietà/colonna, spostamento di dati in un'altra tabella e così via. Per gestire questi scenari, si generano migrazioni basate su codice (e si modifica il codice con scaffolding) che vengono mescolate tra le modifiche gestite dalle migrazioni automatiche. Ciò rende impossibile unire le modifiche quando due sviluppatori controllano le migrazioni.
Informazioni sul funzionamento delle migrazioni
La chiave per usare correttamente le migrazioni in un ambiente del team è una conoscenza di base del modo in cui le migrazioni tiene traccia e usa informazioni sul modello per rilevare le modifiche del modello.
Prima migrazione
Quando si aggiunge la prima migrazione al progetto, si esegue un'operazione simile a Add-Migration First in Gestione pacchetti Console. Le principali operazioni eseguite con questo comando sono illustrate di seguito.
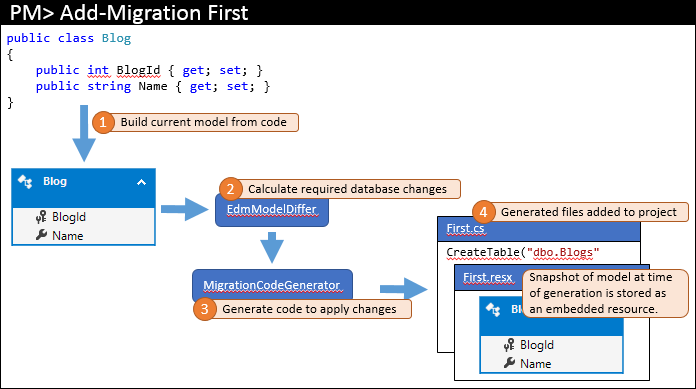
Il modello corrente viene calcolato dal tuo codice (1). Gli oggetti di database necessari vengono quindi calcolati in base al modello diverso (2): poiché si tratta della prima migrazione, il modello usa solo un modello vuoto per il confronto. Le modifiche necessarie vengono passate al generatore di codice per compilare il codice di migrazione richiesto (3) che viene quindi aggiunto alla soluzione di Visual Studio (4).
Oltre al codice di migrazione effettivo archiviato nel file di codice principale, le migrazioni generano anche alcuni file code-behind aggiuntivi. Questi file sono metadati usati dalle migrazioni e non sono elementi da modificare. Uno di questi file è un file di risorse (con estensione resx) che contiene uno snapshot del modello al momento della generazione della migrazione. Si noterà come viene usato nel passaggio successivo.
A questo punto è probabile che si esegua Update-Database per applicare le modifiche al database e quindi procedere all'implementazione di altre aree dell'applicazione.
Migrazioni successive
In seguito si torna e si apportano alcune modifiche al modello. Nell'esempio verrà aggiunta una proprietà URL al blog. Eseguire quindi un comando, esempio: Add-Migration AddUrl, per creare uno scaffolding per una migrazione per applicare le modifiche del database corrispondenti. I passaggi principali eseguiti da questo comando sono illustrati di seguito.
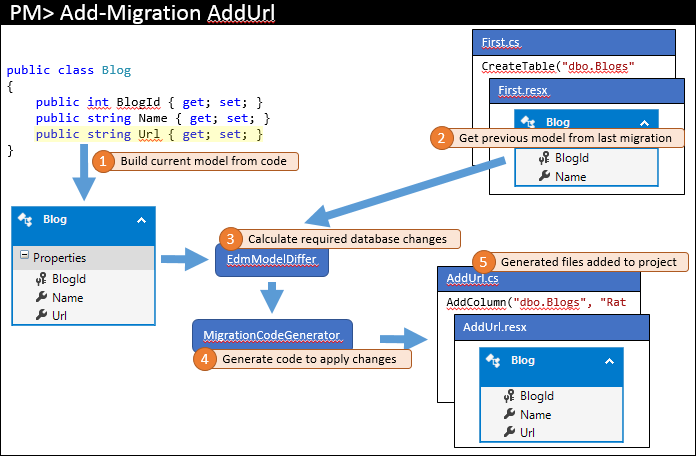
Proprio come l'ultima volta, il modello corrente viene calcolato dal codice (1). Tuttavia, questa volta sono presenti migrazioni esistenti, in modo che il modello precedente venga recuperato dalla migrazione più recente (2). Questi due modelli vengono confrontati per trovare le modifiche necessarie al database (3) e quindi il processo viene completato come in precedenza.
Questo stesso processo viene usato per eventuali altre migrazioni aggiunte al progetto.
Perché preoccuparsi dello snapshot del modello?
Ci si potrebbe chiedere perché EF si interessa dello snapshot del modello, anziché esaminare semplicemente il database. In tal caso, continuate a leggere. Se non si è interessati, è possibile ignorare questa sezione.
Esistono diversi motivi per cui Entity Framework mantiene lo snapshot del modello:
- Consente al database di discostarsi dal modello di Entity Framework. Queste modifiche possono essere apportate direttamente nel database oppure è possibile modificare il codice di scaffolding nelle migrazioni per apportare le modifiche. Ecco alcuni esempi di questa procedura in pratica:
- Si vuole aggiungere una colonna Inserted e Updated a una o più tabelle, ma non si desidera includere queste colonne nel modello di Entity Framework. Se le migrazioni esaminassero il database, proverebbero continuamente a eliminare queste colonne ogni volta che si genera una migrazione. Usando lo snapshot del modello, Entity Framework rileverà solo modifiche legittime al modello.
- Si desidera modificare il corpo di una stored procedure utilizzata per gli aggiornamenti al fine di includere la registrazione dei log. Se le migrazioni esaminassero questa stored procedure dal database, tenterebbero continuamente a ripristinarla a quella prevista da Entity Framework. Usando lo snapshot del modello, Entity Framework eseguirà lo scaffolding del codice solo per modificare la procedura memorizzata quando si modifica la forma della procedura nel modello di Entity Framework.
- Questi stessi principi si applicano all'aggiunta di indici aggiuntivi, incluse tabelle aggiuntive nel database, il mapping di Entity Framework a una vista di database che si trova su una tabella e così via.
- Il modello ef contiene più che solo la forma del database. La presenza dell'intero modello consente alle migrazioni di esaminare le informazioni sulle proprietà e le classi nel modello e su come vengono mappate alle colonne e alle tabelle. Queste informazioni consentono alle migrazioni di divenire più intelligenti nel codice per cui esegue lo scaffolding. Ad esempio, se si modifica il nome della colonna mappata da una proprietà alle migrazioni, è possibile rilevare la ridenominazione visualizzando che si tratta della stessa proprietà, operazione che non può essere eseguita solo se si dispone solo dello schema del database.
Cosa causa problematiche nei contesti di team
Il flusso di lavoro illustrato nella sezione precedente funziona bene quando si è un singolo sviluppatore che lavora su un'applicazione. Funziona anche bene in un ambiente del team se si è l'unica persona che apporta modifiche al modello. In questo scenario è possibile apportare modifiche al modello, generare migrazioni e inviarle al controllo del codice sorgente. Altri sviluppatori possono sincronizzare le modifiche ed eseguire Update-Database per applicare le modifiche dello schema.
I problemi iniziano a verificarsi quando ci sono più sviluppatori che apportano modifiche al modello EF e li inviano contemporaneamente al controllo del codice sorgente. Ciò che EF manca è un modo di prima classe per unire le migrazioni locali con le migrazioni inviate da un altro sviluppatore al controllo del codice sorgente dall'ultima sincronizzazione.
Esempio di conflitto del merge
Prima di tutto si esaminerà un esempio concreto di un conflitto di merge. Si continuerà con l'esempio esaminato in precedenza. Come punto di partenza si supponga che le modifiche apportate alla sezione precedente siano state archiviate dallo sviluppatore originale. Verranno monitorati due sviluppatori man mano che apportano modifiche alla codebase.
Monitoreremo il modello di Entity Framework e le migrazioni in seguito a una serie di modifiche. Come punto di partenza, entrambi gli sviluppatori hanno sincronizzato al repository del controllo del codice sorgente, come illustrato nell'immagine seguente.
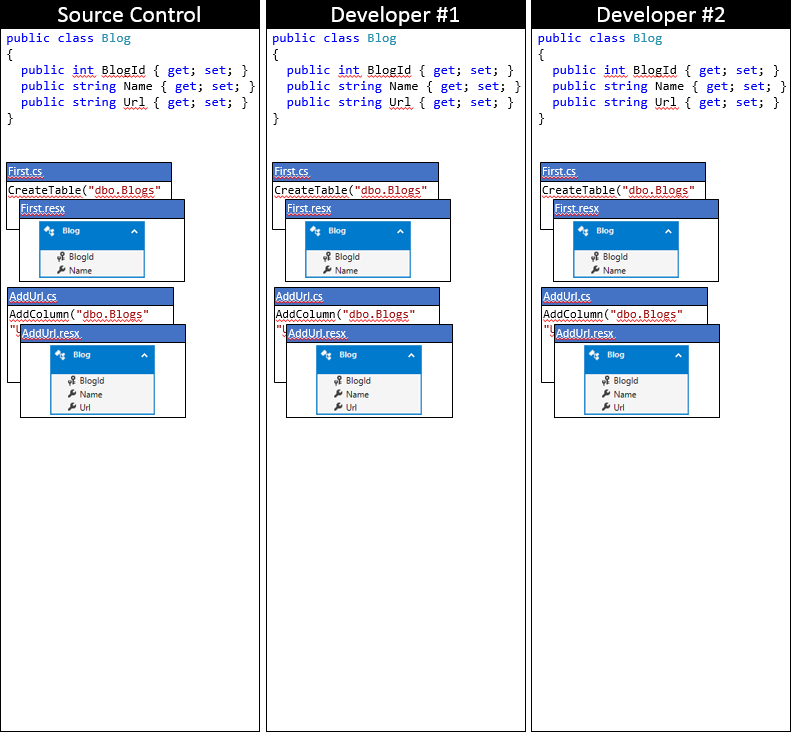
Lo sviluppatore n. 1 e lo sviluppatore #2 apportano ora alcune modifiche al modello ef nella codebase locale. Lo Developer #1 aggiunge una proprietà Rating a Blog e genera una migrazione AddRating per applicare le modifiche al database. Lo sviluppatore 2 aggiunge una proprietà Reader a Blog e genera la migrazione di AddReaders corrispondente. Entrambi gli sviluppatori eseguono Update-Database, per applicare le modifiche ai database locali e quindi continuare a sviluppare l'applicazione.
Nota
Le migrazioni sono precedute da un timestamp, quindi l'immagine rappresenta che la migrazione di AddReaders da Developer #2 viene eseguita dopo la migrazione di AddRating da Developer #1. Indipendentemente dal fatto che lo sviluppatore n. 1 o il numero 2 abbia generato prima di tutto la migrazione non fa alcuna differenza per i problemi relativi al lavoro in un team o al processo di unione che verranno esaminati nella sezione successiva.
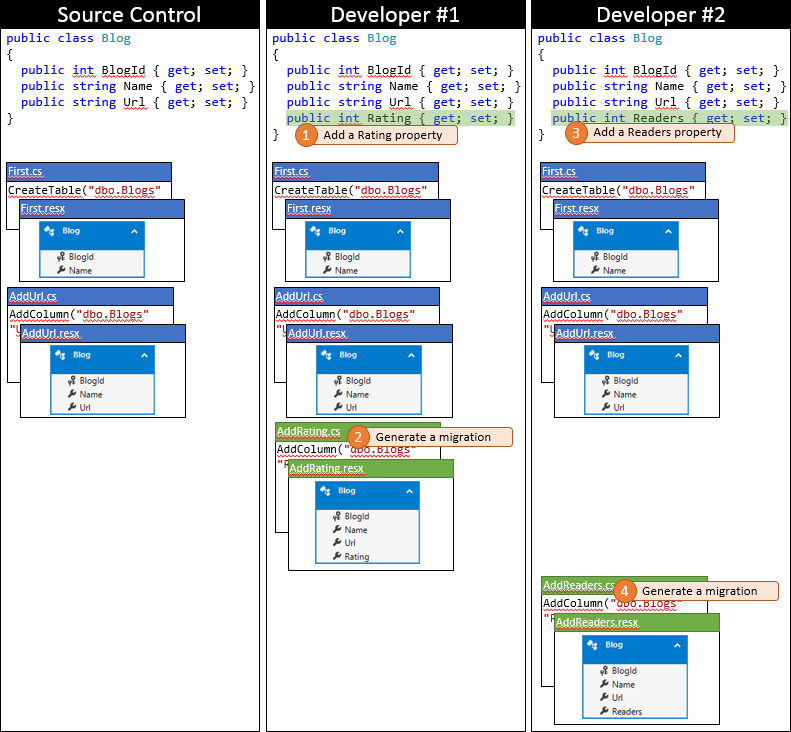
È un giorno fortunato per Developer #1, poiché riescono a inviare le modifiche per primi. Poiché nessun altro utente ha eseguito l'archiviazione dopo la sincronizzazione del repository, può inviare le modifiche senza eseguire alcuna unione.
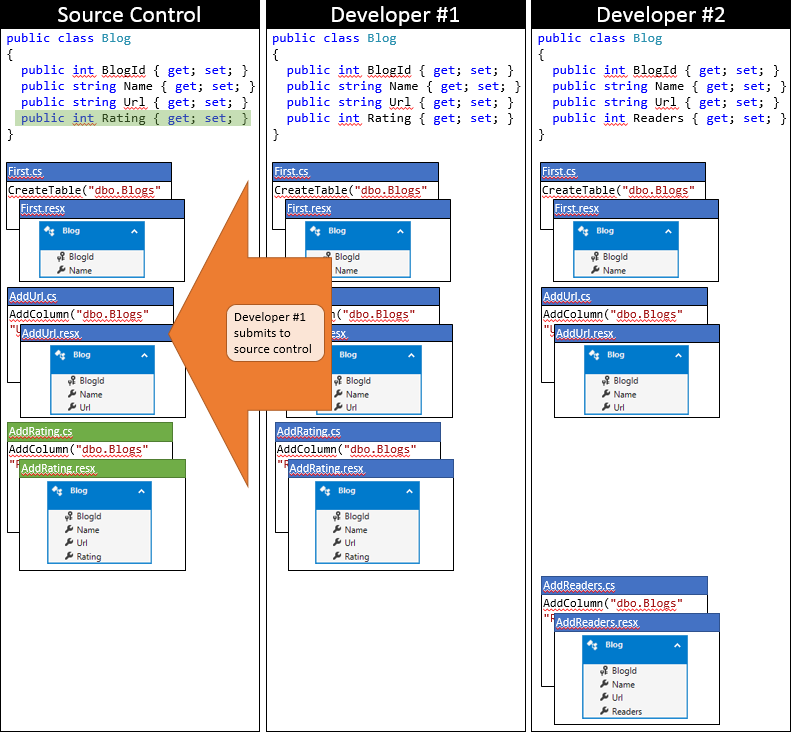
Ora è il momento per il Sviluppatore #2 di inviare. Non sono così fortunati. Poiché un altro utente ha inviato modifiche dopo la sincronizzazione, sarà necessario scaricare le modifiche e unirle. Il sistema di controllo del codice sorgente sarà probabilmente in grado di unire automaticamente le modifiche a livello di codice perché sono molto semplici. Lo stato del repository locale di Developer #2 dopo la sincronizzazione è illustrato nell'immagine seguente.
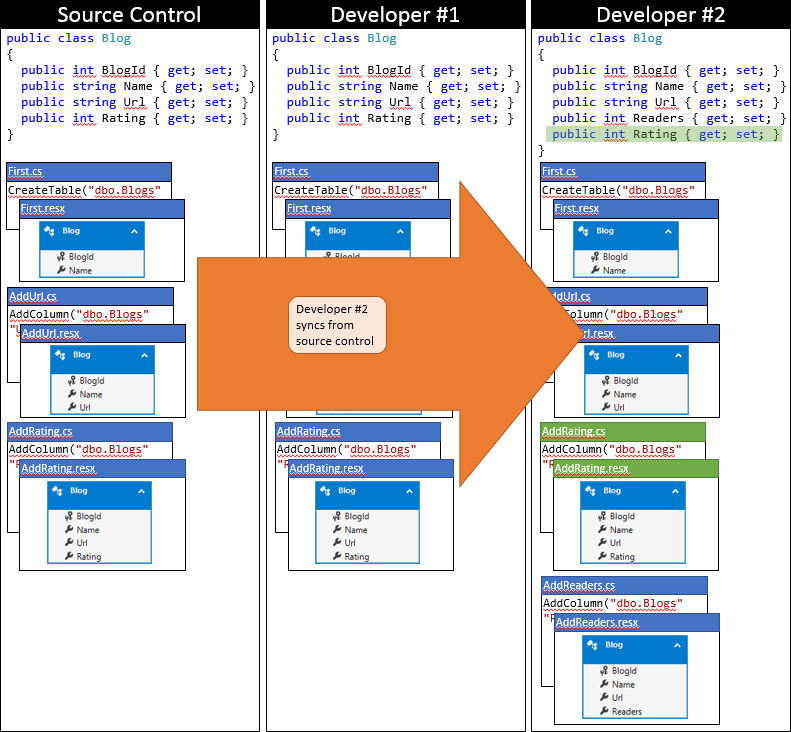
In questa fase Developer #2 può eseguire Update-Database che rileverà la nuova migrazione addRating (che non è stata applicata al database di Developer #2) e applicarla. Ora la colonna Rating viene aggiunta alla tabella Blogs e il database è sincronizzato con il modello.
Esistono tuttavia alcuni problemi:
- Anche se Update-Database applicherà la migrazione addRating verrà generato anche un avviso: Impossibile aggiornare il database in modo che corrisponda al modello corrente perché sono presenti modifiche in sospeso e la migrazione automatica è disabilitata... Il problema è che lo snapshot del modello archiviato nell'ultima migrazione (AddReader) manca la proprietà Rating nel blog (poiché non faceva parte del modello quando è stata generata la migrazione). Code First rileva che il modello nell'ultima migrazione non corrisponde al modello corrente e genera l'avviso.
- L'esecuzione dell'applicazione genera un'eccezione InvalidOperationException che indica che "Il modello che esegue il backup del contesto "BloggingContext" è stato modificato dopo la creazione del database. È consigliabile usare Migrazioni Code First per aggiornare il database..." Anche in questo caso, il problema è che lo snapshot del modello archiviato nell'ultima migrazione non corrisponde al modello corrente.
- Infine, si prevede che l'esecuzione di Add-Migration ora generi una migrazione vuota (poiché non sono state apportate modifiche da applicare al database). Tuttavia, poiché le migrazioni confrontano il modello corrente con quello dell'ultima migrazione (che non include la proprietà Rating), genererà effettivamente un'altra chiamata AddColumn per aggiungere la colonna Rating. Naturalmente, questa migrazione avrà esito negativo durante Update-Database perché la colonna Valutazione esiste già.
Risoluzione del conflitto di merge
La buona notizia è che non è troppo difficile gestire manualmente l'unione, purché si abbia una conoscenza del funzionamento delle migrazioni. Quindi, se sei passato direttamente a questa sezione... scusa, devi tornare indietro e leggere prima il resto dell'articolo!
Sono disponibili due opzioni, la più semplice consiste nel generare una migrazione vuota con il modello corrente corretto come snapshot. La seconda opzione consiste nell'aggiornare lo snapshot nell'ultima migrazione in modo che lo snapshot del modello sia corretto. La seconda opzione è un po' più difficile e non può essere usata in ogni scenario, ma è anche più pulita perché non comporta l'aggiunta di una migrazione aggiuntiva.
Opzione 1: Aggiungi una migrazione "merge" vuota
In questa opzione viene generata una migrazione vuota esclusivamente allo scopo di assicurarsi che la migrazione più recente contenga lo snapshot del modello corretto archiviato.
Questa opzione può essere usata indipendentemente da chi ha generato l'ultima migrazione. Nell'esempio che stiamo seguendo, il Developer #2 si occupa della fusione e ha generato l'ultima migrazione. Ma questi stessi passaggi possono essere usati se Developer #1 ha generato l'ultima migrazione. I passaggi si applicano anche se sono presenti più migrazioni: sono state esaminate solo due per semplificare l'operazione.
Il processo seguente può essere usato per questo approccio, a partire dal momento in cui ci si rende conto di avere modifiche che devono essere sincronizzate dal controllo del codice sorgente.
- Verificare che tutte le modifiche al modello in sospeso nella codebase locale siano state scritte in una migrazione. Questo passaggio garantisce di non perdere modifiche legittime quando si tratta di generare la migrazione vuota.
- Sincronizzare con il controllo del codice sorgente.
- Eseguire Update-Database per applicare le nuove migrazioni archiviate da altri sviluppatori. Nota:se non vengono visualizzati avvisi dal comando Update-Database, non sono state eseguite nuove migrazioni da altri sviluppatori e non è necessario eseguire ulteriori operazioni di unione.
- Eseguire Add-Migration <pick_a_name> –IgnoreChanges (ad esempio, Add-Migration Merge –IgnoreChanges). Verrà generata una migrazione con tutti i metadati (incluso uno snapshot del modello corrente), ma verranno ignorate le modifiche rilevate durante il confronto del modello corrente con lo snapshot nelle ultime migrazioni ( ovvero si ottiene un metodo Up e Down vuoto).
- Eseguire Update-Database per riapplicare la migrazione più recente con i metadati aggiornati.
- Continuare a sviluppare o inviare al controllo del codice sorgente (dopo aver eseguito naturalmente gli unit test).
Di seguito è riportato lo stato della codebase locale di Developer #2 dopo aver usato questo approccio.
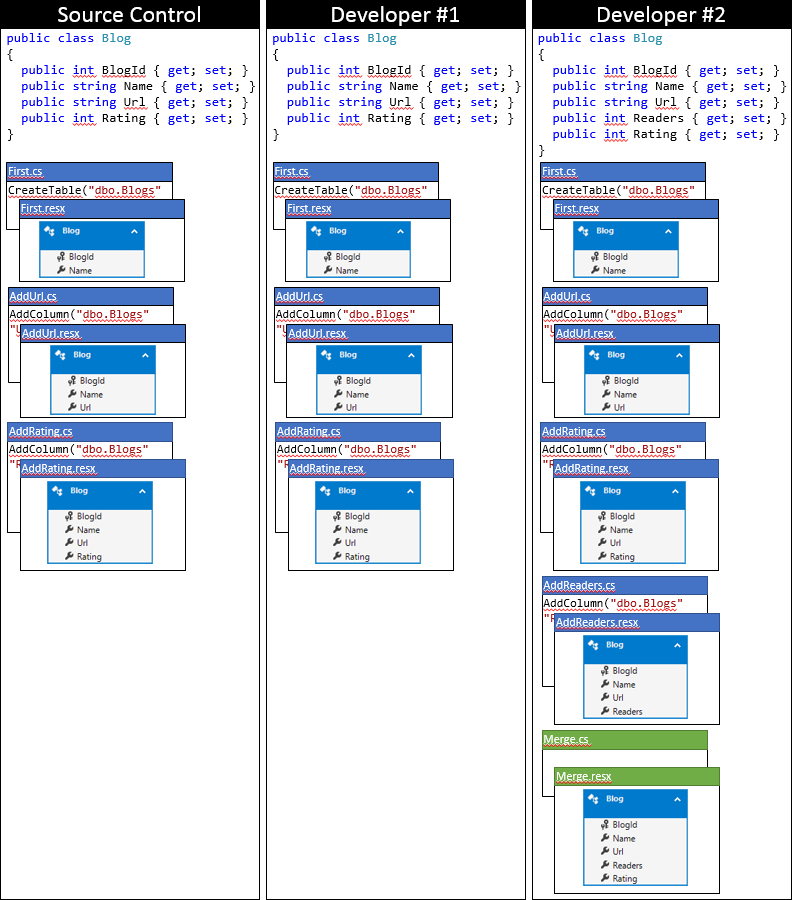
Opzione 2: Aggiornare lo snapshot del modello nell'ultima migrazione
Questa opzione è molto simile all'opzione 1, ma rimuove la migrazione vuota aggiuntiva, perché ammettiamolo, chi vuole file di codice extra nella sua soluzione?
Questo approccio è fattibile solo se la migrazione più recente esiste solo nella codebase locale e non è ancora stata inviata al controllo del codice sorgente , ad esempio se l'ultima migrazione è stata generata dall'utente che esegue l'unione. La modifica dei metadati delle migrazioni che altri sviluppatori potrebbero aver già applicato al database di sviluppo, o ancora peggio applicati a un database di produzione, può comportare effetti collaterali imprevisti. Durante il processo verrà eseguito il rollback dell'ultima migrazione nel database locale e verrà riapplicata con i metadati aggiornati.
Anche se l'ultima migrazione deve trovarsi solo nella codebase locale, non esistono restrizioni al numero o all'ordine delle migrazioni che lo procedono. Ci possono essere più migrazioni da più sviluppatori e si applicano gli stessi passaggi. Abbiamo appena esaminato due per semplicità.
Il processo seguente può essere usato per questo approccio, a partire dal momento in cui ci si rende conto di avere modifiche che devono essere sincronizzate dal controllo del codice sorgente.
- Verificare che tutte le modifiche al modello in sospeso nella codebase locale siano state scritte in una migrazione. Questo passaggio garantisce di non perdere nessuna modifica legittima quando arriva il momento di generare la migrazione vuota.
- Sincronizzare con il controllo del codice sorgente.
- Eseguire Update-Database per applicare le nuove migrazioni archiviate da altri sviluppatori. Nota:se non vengono visualizzati avvisi dal comando Update-Database, non sono state eseguite nuove migrazioni da altri sviluppatori e non è necessario eseguire ulteriori operazioni di unione.
- Eseguire Update-Database –TargetMigration <second_last_migration> (nell'esempio che stiamo seguendo sarebbe Update-Database –TargetMigration AddRating). Questo esegue il rollback del database allo stato della seconda ultima migrazione, in modo efficace "annullando l'applicazione" dell'ultima migrazione dal database. Nota:questo passaggio è necessario per assicurarsi di modificare i metadati della migrazione poiché i metadati vengono archiviati anche nella __MigrationsHistoryTable del database. Questo è il motivo per cui è consigliabile usare questa opzione solo se l'ultima migrazione si trova solo nella codebase locale. Se altri database avevano applicato l'ultima migrazione, è necessario eseguire il rollback e riapplicare l'ultima migrazione per aggiornare i metadati.
- Eseguire Add-Migration <full_name_including_timestamp_of_last_migration> (nell'esempio che stiamo seguendo, questo sarebbe qualcosa come Add-Migration 201311062215252_AddReaders). Nota:è necessario includere il timestamp in modo che le migrazioni sappiano di voler modificare la migrazione esistente anziché eseguire lo scaffolding di una nuova migrazione. I metadati dell'ultima migrazione verranno aggiornati in modo che corrispondano al modello corrente. Al termine del comando si riceverà l'avviso seguente, ma è esattamente quello che si vuole. "Solo il codice del progettista per la migrazione '201311062215252_AddReaders' è stato ri-scaffoldato. Per ri-scaffoldare l'intera migrazione, usare il parametro -Force."
- Eseguire Update-Database per riapplicare la migrazione più recente con i metadati aggiornati.
- Continuare a sviluppare o inviare al controllo del codice sorgente (dopo aver eseguito naturalmente gli unit test).
Di seguito è riportato lo stato della codebase locale di Developer #2 dopo aver usato questo approccio.
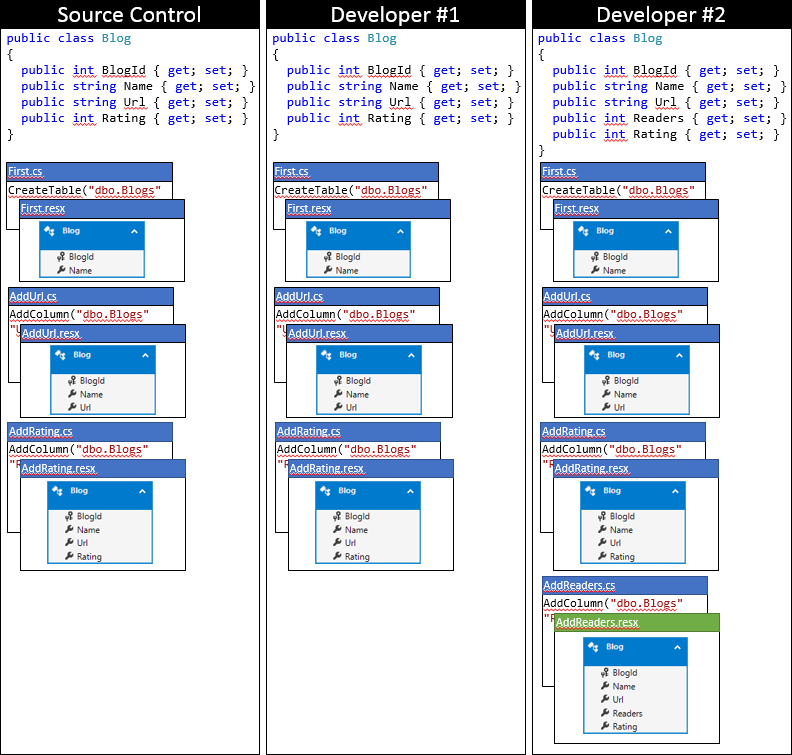
Riepilogo
Esistono alcune sfide quando si utilizzano le Code First Migrations in un ambiente di squadra. Tuttavia, una conoscenza di base del funzionamento delle migrazioni e di alcuni semplici approcci per la risoluzione dei conflitti di merge semplificano la risoluzione di questi problemi.
Il problema fondamentale è costituito da metadati non corretti archiviati nella migrazione più recente. Ciò causa che Code First rilevi erroneamente che il modello corrente e lo schema del database non corrispondono e esegua lo scaffolding di codice errato durante la prossima migrazione. Questa situazione può essere superata generando una migrazione vuota con il modello corretto o aggiornando i metadati nella migrazione più recente.
Collabora con noi su GitHub
L'origine di questo contenuto è disponibile in GitHub, in cui è anche possibile creare ed esaminare i problemi e le richieste pull. Per ulteriori informazioni, vedere la guida per i collaboratori.