Microsoft Entra Connect Sync: informazioni sul provisioning dichiarativo
Questo argomento illustra il modello di configurazione in Microsoft Entra Connect. Il modello è denominato provisioning dichiarativo e consente di modificare una configurazione con facilità. Molte operazioni descritte in questo argomento sono avanzate e non necessarie per la maggior parte degli scenari dei clienti.
Panoramica
Il provisioning dichiarativo è l'elaborazione di oggetti provenienti da una directory di origine connessa e determina il modo in cui l'oggetto e gli attributi devono essere trasformati da un'origine a una destinazione. Un oggetto viene elaborato in una pipeline di sincronizzazione e la pipeline è la stessa per le regole in ingresso e in uscita. Una regola in ingresso origina da uno spazio connettore e ha come destinazione il metaverse, mentre una regola in uscita ha origine nel metaverse e ha come destinazione uno spazio connettore.
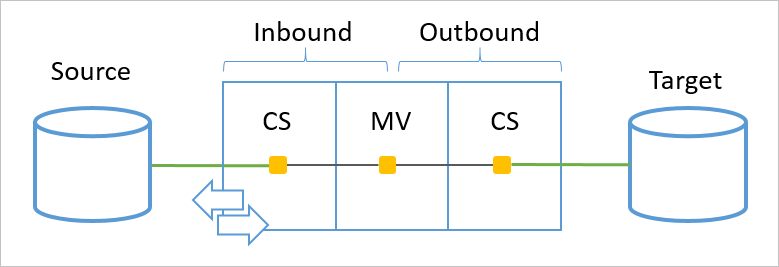
La pipeline include diversi moduli. Ognuno di essi è responsabile di un concetto nella sincronizzazione degli oggetti.
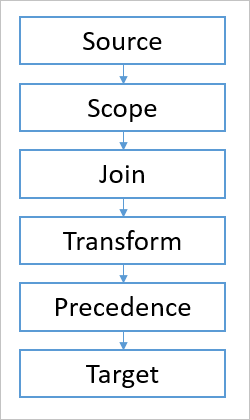
- Origine, l'oggetto di origine
- Ambito, consente di trovare tutte le regole di sincronizzazione che si trovano nell'ambito
- Join, determina la relazione tra spazio connettore e metaverse
- Trasformazione, calcola la modalità di trasformazione e il flusso degli attributi
- Precedenza, risolve i conflitti tra attributi
- Destinazione, l'oggetto di destinazione
Ambito
Il modulo scope valuta un oggetto e determina le regole che si trovano nell'ambito e devono essere incluse nell'elaborazione. A seconda dei valori degli attributi sull'oggetto, viene valutata la presenza di diverse regole di sincronizzazione nell'ambito. Ad esempio, un utente disabilitato senza alcuna cassetta postale di Exchange ha regole diverse rispetto a un utente abilitato che ha una cassetta postale.

L'ambito è definito sotto forma di gruppi e clausole. Le clausole si trovano all'interno di un gruppo. Tra tutte le clausole in un gruppo viene usato un operatore logico AND. Ad esempio, (department =IT AND country = Denmark). Viene usato un operatore logico OR tra gruppi.
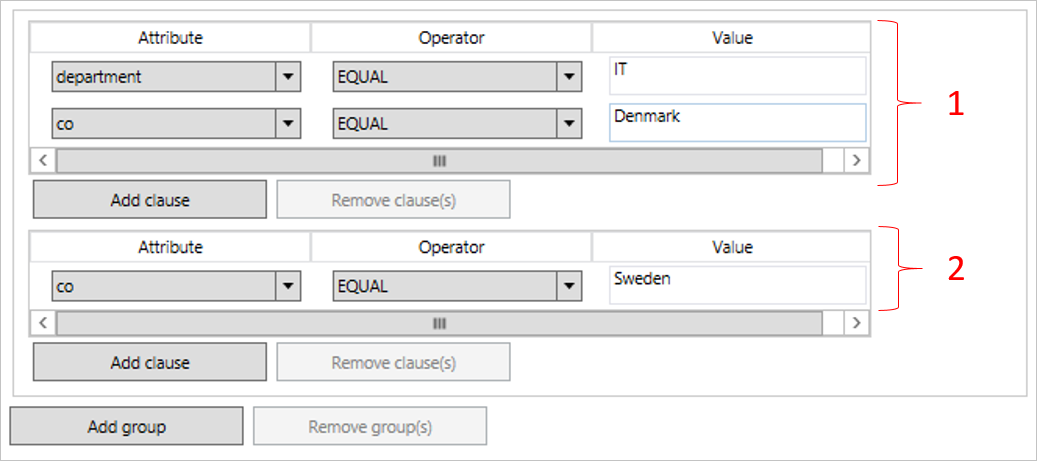
L'ambito in questa immagine deve essere letto come (department = IT AND country = Denmark) OR (country=Sweden). Se il gruppo 1 o il gruppo 2 viene valutato su true, la regola si trova nell'ambito.
Il modulo dell'ambito supporta le operazioni seguenti.
| Operazione | Descrizione |
|---|---|
| EQUAL, NOTEQUAL | Confronto di stringhe che valuta se il valore è uguale al valore dell'attributo. Per gli attributi multivalore, vedere ISIN e ISNOTIN. |
| LESSTHAN, LESSTHAN_OR_EQUAL | Confronto di stringhe che valuta se il valore è minore del valore dell'attributo. |
| CONTAINS, NOTCONTAINS | Confronto di stringhe che valuta se il valore è presente nel valore dell'attributo. |
| STARTSWITH, NOTSTARTSWITH | Confronto di stringhe che valuta se il valore è all'inizio del valore dell'attributo. |
| ENDSWITH, NOTENDSWITH | Confronto di stringhe che valuta se il valore è alla fine del valore dell'attributo. |
| GREATERTHAN, GREATERTHAN_OR_EQUAL | Confronto di stringhe che valuta se il valore è maggiore del valore dell'attributo. |
| ISNULL, ISNOTNULL | Valuta se l'attributo è assente dall'oggetto. Se l'attributo non è presente e quindi è null, la regola si trova nell'ambito. |
| ISIN, ISNOTIN | Valuta se il valore è presente nell'attributo definito. Questa operazione è la variante multivalore di EQUAL e NOTEQUAL. L'attributo deve essere un attributo multivalore e se il valore è presente in uno dei valori dell'attributo, la regola si trova nell'ambito. |
| ISBITSET, ISNOTBITSET | Valuta se un determinato bit è impostato. Può essere ad esempio usato per valutare i bit di userAccountControl per vedere se un utente è abilitato o disabilitato. |
| ISMEMBEROF, ISNOTMEMBEROF | Il valore deve contenere un nome distinto per un gruppo nello spazio connettore. Se l'oggetto è un membro del gruppo specificato, la regola si trova nell'ambito. |
Join.
Il modulo join nella pipeline di sincronizzazione provvede a trovare la relazione tra l'oggetto nell'origine e un oggetto nella destinazione. In una regola in ingresso, questa relazione sarebbe rappresentata da un oggetto in uno spazio connettore che trova una relazione con un oggetto nel metaverse.

L'obiettivo è verificare se è già presente un oggetto nel metaverse, creato da un altro connettore, con cui eseguire l'associazione. In una foresta di account e risorse, ad esempio, l'utente della foresta di account deve essere unito all'utente della foresta di risorse.
I join vengono usati principalmente nelle regole in ingresso per unire gli oggetti dello spazio connettore con lo stesso oggetto del metaverse.
I join sono definiti come uno o più gruppi. All'interno di un gruppo sono presenti clausole. Tra tutte le clausole in un gruppo viene usato un operatore logico AND. Viene usato un operatore logico OR tra gruppi. I gruppi vengono elaborati dall'alto verso il basso. Quando un gruppo trova esattamente una corrispondenza con un oggetto nella destinazione, non vengono valutate altre regole di unione. Se non vengono trovati oggetti o ne viene trovato più di uno, l'elaborazione continua con il gruppo di regole successivo. Per questo motivo, le regole devono essere create seguendo l'ordine dalla più esplicita alla più fuzzy.
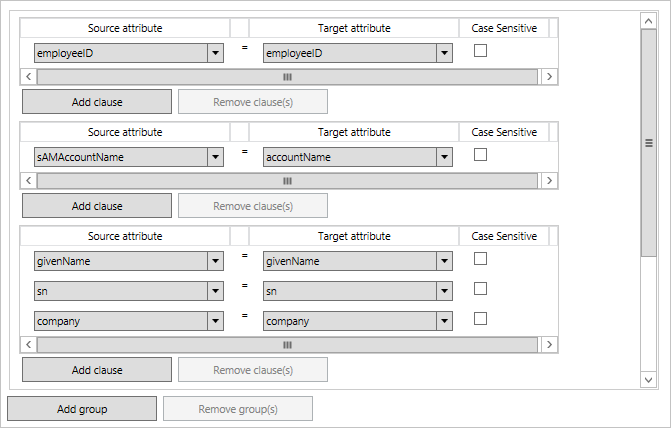
I join in questa immagine vengono elaborati dall'alto verso il basso. La pipeline di sincronizzazione verifica prima di tutto se è presente una corrispondenza in employeeID. Se non sono presenti corrispondenze, la seconda regola verifica se è possibile usare il nome account per unire gli oggetti. Se neanche in questo caso vengono trovate corrispondenze, la terza e ultima regola rappresenta una corrispondenza fuzzy che usa il nome dell'utente.
Se tutte le regole di join sono state valutate e non è presente esattamente una corrispondenza, verrà usato il valore di Link Type (Tipo di collegamento) indicato nella pagina Description (Descrizione). Se per questa impostazione è specificato il valore Provision(Provisioning), nella destinazione verrà creato un nuovo oggetto.
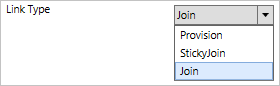
Un oggetto deve avere una sola regola di sincronizzazione con regole di join nell'ambito. Se sono presenti più regole di sincronizzazione in cui è definito il join, si verificherà un errore. La precedenza non viene usata per risolvere i conflitti di join. Un oggetto deve avere una regola di join nell'ambito per far sì che gli attributi vengano trasferiti nella stessa direzione in ingresso/in uscita. Se è necessario trasferire gli attributi sia in ingresso che in uscita nello stesso oggetto, è necessario avere una regola di sincronizzazione sia in ingresso che in uscita con il join.
Il join in uscita presenta un comportamento particolare quando prova a effettuare il provisioning di un oggetto in uno spazio connettore di destinazione. Viene usato l'attributo DN per tentare prima un join inverso. Se nello spazio connettore di destinazione esiste già un oggetto con lo stesso DN, gli oggetti verranno uniti.
Il modulo join viene valutato una sola volta quando una nuova regola di sincronizzazione entra nell'ambito. Un oggetto unito non verrà separato anche se i criteri del join non sono più soddisfatti. Per separare un oggetto è necessario che la regola di sincronizzazione che ha unito gli oggetti esca dall'ambito.
Eliminazione di metaverse
Un oggetto del metaverse è presente finché l'ambito contiene una regola di sincronizzazione con Link Type (Tipo di collegamento) impostato su Provision (Provisioning) o StickyJoin. Uno StickyJoin viene usato quando a un connettore non è consentito effettuare il provisioning di un nuovo oggetto nel metaverse, ma quando è unita in join, devono essere eliminato nell'origine prima che venga eliminato l'oggetto del metaverse.
Quando viene eliminato un oggetto del metaverse, tutti gli oggetti associati a una regola di sincronizzazione in uscita contrassegnata per il provisioning vengono contrassegnati per l'eliminazione.
Trasformazioni
Le trasformazioni vengono usate per definire la modalità di trasferimento degli attributi dall'origine alla destinazione. I flussi del trasferimento possono avere uno dei seguenti tipi: diretto, costante o espressione. In un flusso diretto, il valore dell'attributo viene passato così com'è, senza altre trasformazioni. Un valore costante imposta il valore specificato. Un'espressione usa il linguaggio delle espressioni del provisioning dichiarativo per specificare la modalità di trasformazione. Per dettagli sul linguaggio delle espressioni, vedere l'argomento Servizio di sincronizzazione Azure AD Connect: Informazioni sulle espressioni di provisioning dichiarativo .
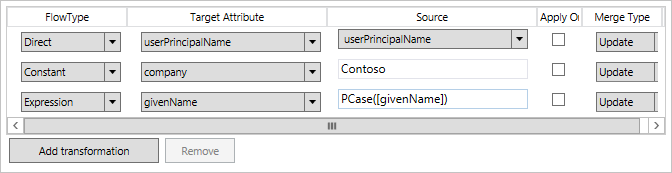
La casella di controllo Apply once (Applica una volta) definisce che l'attributo debba essere impostato solo quando l'oggetto viene inizialmente creato. Ad esempio, questa configurazione consente di impostare una password iniziale per un nuovo oggetto utente.
Unione di valori degli attributi
Nei flussi di attributi è disponibile un'impostazione per stabilire se gli attributi multivalore devono essere uniti da molti connettori diversi. Il valore predefinito è Update(Aggiorna) e indica che la regola di sincronizzazione con precedenza più alta avrà la priorità.
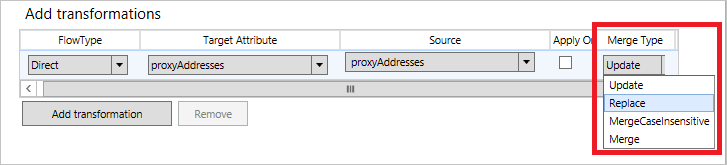
Sono disponibili anche Merge (Unisci) e MergeCaseInsensitive (Unisci senza distinzione maiuscole/minuscole). Queste opzioni consentono di unire i valori da diverse origini. Ad esempio, possono essere usate per unire l'attributo proxyAddresses di più foreste differenti. Quando si usano queste opzioni, tutte le regole di sincronizzazione nell'ambito per un oggetto devono usare lo stesso tipo di unione. Non è possibile definire Update (Aggiorna) da un connettore e Merge (Unisci) da un altro. In questo caso, viene visualizzato un errore.
La differenza tra Merge (Unisci) e MergeCaseInsensitive (Unisci senza distinzione maiuscole/minuscole) è la modalità di elaborazione dei valori di attributo duplicati. Il motore di sincronizzazione assicura che non vengano inseriti valori duplicati nell'attributo di destinazione. Con MergeCaseInsensitive(Unisci senza distinzione maiuscole/minuscole) non saranno presenti valori duplicati con solo una differenza tra maiuscole/minuscole. Ad esempio, nell'attributo di destinazione non saranno presenti né "SMTP:bob@contoso.com" né "smtp:bob@contoso.com" Merge (Unisci) verifica solo i valori esatti e potrebbero essere presenti più valori in cui è presente solo una differenza tra maiuscole/minuscole.
L'opzione Replace (Sostituisci) è come Update (Aggiorna), ma non viene usata.
Controllare il processo del flusso dell'attributo
Quando vengono configurate più regole di sincronizzazione in ingresso per lo stesso attributo metaverse, per determinare la regola prioritaria viene usata la precedenza. La regola di sincronizzazione con la precedenza più alta (valore numerico inferiore) fornisce il valore. Lo stesso concetto si applica alle regole in uscita. La regola di sincronizzazione con la precedenza più alta ha la priorità e fornisce il valore alla directory connessa.
In alcuni casi, invece di fornire un valore, la regola di sincronizzazione deve determinare il comportamento delle altre regole. In questo caso vengono usati alcuni valori letterali speciali.
Per le regole di sincronizzazione in ingresso è possibile usare il valore letterale NULL per indicare che nel flusso non è disponibile un valore da fornire. Un'altra regola con una precedenza inferiore può fornire un valore. Se nessuna regola ha fornito valori, l'attributo metaverse verrà rimosso. Per una regola in uscita, se NULL è il valore finale dopo l'elaborazione di tutte le regole di sincronizzazione, il valore viene rimosso nella directory connessa.
Il valore letterale AuthoritativeNull è simile a NULL, con la differenza che nessuna regola con una precedenza inferiore può fornire un valore.
Un flusso dell'attributo può anche usare IgnoreThisFlow. È simile a NULL in quanto indica che non è disponibile alcun valore da fornire, con la differenza che non rimuove un valore già esistente nella destinazione. È come se il flusso dell'attributi non sia mai stato presente.
Ecco un esempio:
In Out to AD - User Exchange hybrid (In uscita ad AD - Utente Exchange ibrido) è possibile trovare il flusso seguente:
IIF([cloudSOAExchMailbox] = True,[cloudMSExchSafeSendersHash],IgnoreThisFlow)
Questa espressione deve essere letta come: se la casella postale dell'utente si trova in Microsoft Entra ID, trasmettere l'attributo da Microsoft Entra ID ad Active Directory. In caso contrario, non ritrasmettere nulla ad Active Directory. In questo caso, il valore esistente rimarrà in Active Directory.
ImportedValue
La funzione ImportedValue è diversa da tutte le altre funzioni, perché il nome dell'attributo deve essere racchiuso tra virgolette invece che tra parentesi quadre:
ImportedValue("proxyAddresses").
La sincronizzazione in entrata prevede che un attributo che non abbia ancora raggiunto una directory connessa lo raggiunga a un certo punto, quindi, in genere, la sincronizzazione ottiene un valore di attributo dal rispettivo spazio connettore, anche se non è ancora stato esportato o se si è verificato un errore durante l'esportazione. In alcuni casi, tuttavia, è importante sincronizzare soltanto un valore esportato e confermato durante l'importazione dalla directory connessa. Questa funzione è disponibile in più regole di trasformazione predefinite in "In From AD/AAD", in cui l'attributo deve essere sincronizzato solo una volta che è stato confermato che il valore è stato esportato correttamente.
Un esempio di questa funzione è disponibile nella regola di sincronizzazione predefinita In from AD – User Common from Exchange (In ingresso da AD - Utente comune di Exchange), per il flusso di attributi ProxyAddresses con Hybrid Exchange. Ad esempio, quando viene aggiunto ProxyAddresses di un utente, la funzione ImportedValue restituirà il nuovo valore solo dopo che è stato confermato dal passaggio di importazione seguente:
proxyAddresses<- RemoveDuplicates(Trim(ImportedValue("proxyAddresses")))
Questa funzione è necessaria quando la directory di destinazione potrebbe modificare o rimuovere automaticamente un valore di attributo esportato, e vogliamo che la sincronizzazione elabori soltanto i valori di attributo confermati.
Precedenza
Quando più regole di sincronizzazione provano a inserire lo stesso valore di attributo nella destinazione, il valore di precedenza viene usato per determinare quale regola di sincronizzazione abbia la priorità. In caso di conflitto, l'attributo verrà specificato dalla regola con la precedenza più alta e il valore numerico più basso.

Questo ordinamento consente di definire flussi di attributi più precisi per un piccolo subset di oggetti. Le regole predefinite assicurano ad esempio che gli attributi di un account abilitato (User AccountEnabled) abbiano la precedenza su altri account.
È possibile definire la precedenza tra i connettori. Ciò consente ai connettori con i dati migliori di passare i valori per primi.
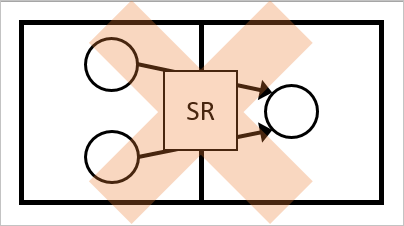
Più oggetti dallo stesso spazio connettore
Non è possibile avere più oggetti nello stesso spazio connettore, uniti nello stesso oggetto del metaverse. Questa configurazione viene indicata come ambigua anche se gli attributi nell'origine hanno lo stesso valore.
Passaggi successivi
- Per altre informazioni sul linguaggio delle espressioni, vedere Servizio di sincronizzazione Azure AD Connect: Informazioni sulle espressioni di provisioning dichiarativo.
- Per informazioni sull'uso del provisioning dichiarativo predefinito, vedere Servizio di sincronizzazione Azure AD Connect: Informazioni sulla configurazione predefinita.
- Per informazioni su come apportare una modifica pratica con il provisioning dichiarativo, vedere Servizio di sincronizzazione Azure AD Connect: come apportare modifiche alla configurazione predefinita.
- Per altre informazioni sull'interazione tra utenti e contatti, vedere Servizio di sincronizzazione Azure AD Connect: Informazioni su utenti e contatti.
Argomenti generali
- Servizio di sincronizzazione di Microsoft Entra Connect: Comprendere e personalizzare la sincronizzazione
- Integrare le identità locali con Microsoft Entra ID
Argomenti di riferimento
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per