Sviluppo di pacchetti di regole di informazioni riservate in Exchange 2013
Si applica a: Exchange Server 2013
Le istruzioni e lo schema XML presenti in questo argomento consentiranno di avviare la creazione dei file XML di base della prevenzione della perdita dati (DLP) che definiscono i tipi di informazioni riservate in un pacchetto di regole di classificazione. Dopo aver creato un file XML ben formato, è possibile importarlo usando l'interfaccia di amministrazione di Exchange o la shell di gestione di Exchange per creare una soluzione DLP Microsoft Exchange Server 2013. Un file XML che è un modello di criteri DLP personalizzato può contenere l'XML, ovvero il pacchetto di regole di classificazione. Per una panoramica sulla definizione dei modelli DLP come file XML, vedere Definire modelli DLP e tipi di informazione propri.
Cenni preliminari sul processo di creazione della regola
Il processo di creazione della regola è composto dai seguenti passaggi generali.
Preparazione di una serie di documenti di prova rappresentativi del loro ambiente di destinazione. Le caratteristiche principali da considerare per il set di documenti di test includono: un subset dei documenti contiene l'entità o l'affinità per cui viene creata la regola e un subset dei documenti non contiene l'entità o l'affinità per cui viene creata la regola.
Identificare le regole che soddisfano i requisiti di accettazione (precisione e richiamo) per individuare il contenuto qualificante. Questa operazione di identificazione può richiedere lo sviluppo di più condizioni all'interno di una regola, associate alla logica booleana, che insieme soddisfano i requisiti minimi di corrispondenza per identificare i documenti di destinazione.
Stabilire il livello di sicurezza consigliato per le regole basate sui requisiti di accettazione (precisione e richiamo). L'elemento della sicurezza consigliato può essere pensato come livello di sicurezza predefinito per la regola.
Convalidare le regole creando con esse l'istanza di uno schema e monitorando il contenuto di prova campione. In base ai risultati, regolare le regole o il livello di sicurezza per ottimizzare il contenuto rilevato riducendo al minimo i falsi positivi e i negativi. Continuare con il ciclo di convalida e con le modifiche delle regole fino a raggiungere un livello di individuazione del contenuto soddisfacente per gli esempi positivi e negativi.
Per informazioni sulla definizione dello schema XML per i file modello del criterio, vedere Sviluppo di file modello per il criterio DLP.
Descrizione delle regole
Per il motore di rilevamento delle informazioni riservate del criterio DLP è possibile creare due tipi di regole: Entità e affinità. La scelta del tipo di regola si basa sul tipo di logica di elaborazione che deve essere applicata all'elaborazione del contenuto, come descritto nelle sezioni precedenti. Le definizioni delle regole sono configurate in un documento XML nel formato descritto dallo schema XSD standardizzato delle regole. Le regole descrivono sia il tipo di contenuto da soddisfare che il livello di sicurezza in base a cui la corrispondenza descritta rappresenta il contenuto di destinazione. Il livello di sicurezza definisce la probabilità per l'entità di essere presente se viene trovato un criterio nel contenuto o la probabilità per l'affinità di essere presente se viene trovata una prova.
Struttura di base delle regole
La definizione delle regole è costituita da tre componenti principali:
Entità definisce la logica di corrispondenza e calcolo per tale regola
Affinità definisce la logica di corrispondenza per la regola
Stringhe localizzate localizzazione per nomi di regole e descrizioni relative
Vengono usati altri tre elementi di supporto che definiscono i dettagli dell'elaborazione e a cui si fa riferimento all'interno dei componenti principali: Keyword, Regex e Function. L'utilizzo dei riferimenti consente di servirsi di una singola definizione degli elementi di supporto, come il codice fiscale, in più regole di entità o affinità. La struttura di base delle regole in formato XML può essere considerata come segue.
<?xml version="1.0" encoding="utf-8"?>
<RulePackage xmlns="http://schemas.microsoft.com/office/2011/mce">
<RulePack id="DAD86A92-AB18-43BB-AB35-96F7C594ADAA">
<Version major="1" minor="0" build="0" revision="0"/>
<Publisher id="619DD8C3-7B80-4998-A312-4DF0402BAC04"/>
<Details defaultLangCode="en-us">
<LocalizedDetails langcode="en-us">
<PublisherName>DLP by EPG</PublisherName>
<Name>CSO Custom Rule Pack</Name>
<Description>This is a rule package for a EPG demo.</Description>
</LocalizedDetails>
</Details>
</RulePack>
<Rules>
<!-- Employee ID -->
<Entity id="E1CC861E-3FE9-4A58-82DF-4BD259EAB378" patternsProximity="300" recommendedConfidence="75">
<Pattern confidenceLevel="75">
<IdMatch idRef="Regex_employee_id" />
<Match idRef="Keyword_employee" />
</Pattern>
</Entity>
<Regex id="Regex_employee_id">(\s)(\d{9})(\s)</Regex>
<Keyword id="Keyword_employee">
<Group matchStyle="word">
<Term>Identification</Term>
<Term>Contoso Employee</Term>
</Group>
</Keyword>
<LocalizedStrings>
<Resource idRef="E1CC861E-3FE9-4A58-82DF-4BD259EAB378">
<Name default="true" langcode="en-us">
Employee ID
</Name>
<Description default="true" langcode="en-us">
A custom classification for detecting Employee ID's
</Description>
</Resource>
</LocalizedStrings>
</Rules>
</RulePackage>
Regole dell'entità
Le regole di entità sono destinate a identificatori ben definiti, ad esempio il numero di previdenza sociale, e sono rappresentate da una raccolta di modelli numerabili. Le regole dell'entità restituiscono un calcolo e il livello di sicurezza di una corrispondenza dove il calcolo indica il numero totale delle istanze dell'entità trovate e il livello di sicurezza indica la probabilità che l'entità specificata esista nel documento in questione. L'entità contiene l'attributo "Id" come identificatore univoco. L'identificatore viene utilizzato per la localizzazione, il controllo delle versioni e l'esecuzione di query. L'ID entità deve essere un GUID. L'ID entità non deve essere duplicato in altre entità o affinità. Viene fatto riferimento nella sezione stringhe localizzate.
Le regole di entità contengono modelli facoltativiAttributo di prossimità (predefinito = 300) usato quando si applica la logica booleana per specificare l'adiacenza di più modelli necessari per soddisfare la condizione di corrispondenza. L'elemento Entity contiene uno o più elementi pattern figlio, in cui ogni modello è una rappresentazione distinta dell'entità, ad esempio l'entità della carta di credito o l'entità di licenza del driver. L'elemento Pattern ha un attributo obbligatorio di confidenceLevel che rappresenta la precisione del modello in base al set di dati di esempio. L'elemento Pattern può avere tre elementi figlio:
IdMatch: questo elemento è obbligatorio.
Corrisponde
Qualsiasi
Se gli elementi Pattern restituiscono il valore "true", il modello è soddisfatto. Il conteggio per l'elemento Entity equivale alla somma di tutti i conteggi dell'elemento Pattern rilevato.

dove k è il numero di elementi Pattern per Entity.
Un elemento Pattern deve avere esattamente un elemento IdMatch. IdMatch rappresenta l'identificatore che il modello deve soddisfare, ad esempio un numero di carta di credito o un ID contribuente individuale. Il conteggio per un modello è il numero di IdMatch soddisfatti con l'elemento Pattern. L'elemento IdMatch ancora la finestra di prossimità per gli elementi Match.
Un altro sottoelemento facoltativo dell'elemento Pattern è l'elemento Match che rappresenta l'evidenza corroborativa che deve essere confrontata per supportare la ricerca dell'elemento IdMatch. Ad esempio, la regola di maggiore attendibilità potrebbe richiedere che, oltre a trovare un numero di carta di credito, nel documento siano presenti elementi aggiuntivi, all'interno di una finestra di prossimità della carta di credito, ad esempio indirizzo e nome. Questi elementi aggiuntivi verranno rappresentati tramite l'elemento Match o Qualsiasi elemento (descritto in dettaglio nella sezione Metodi e tecniche corrispondenti). Più elementi Match possono essere inclusi in una definizione pattern, che può essere inclusa direttamente nell'elemento Pattern o combinata usando l'elemento Any per definire la semantica corrispondente. Viene restituito true se viene trovata una corrispondenza nella finestra di prossimità ancorata al contenuto IdMatch.
Sia gli elementi IdMatch che Match non definiscono i dettagli del contenuto a cui devono essere abbinati, ma fanno invece riferimento tramite l'attributo idRef. Questo riferimento promuove la riutilizzabilità delle definizioni in più costrutti di pattern.
<Entity id="..." patternsProximity="300" >
<Pattern confidenceLevel="85">
<IdMatch idRef="FormattedSSN" />
<Any minMatches="1">
<Match idRef="SSNKeyword" />
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
<Pattern confidenceLevel="65">
<IdMatch idRef="UnformattedSSN" />
<Match idRef="SSNKeyword" />
<Any minMatches="1">
<Match idRef="USDate" />
<Match idRef="USAddress" />
<Match idRef="Name" />
</Any>
</Pattern>
</Entity>
Elemento Entity Id, rappresentato nel codice XML precedente da "..." deve essere un GUID a cui viene fatto riferimento nella sezione Stringhe localizzate.
Finestra di prossimità dello schema dell'entità
L'entità conserva il valore dell'attributo facoltativo patternsProximity (intero, predefinito = 300) utilizzato per trovare gli schemi. Per ogni modello, il valore dell'attributo definisce la distanza (in caratteri Unicode) dalla posizione IdMatch per tutte le altre corrispondenze specificate per tale modello. La finestra di prossimità viene ancorata dalla posizione IdMatch con la finestra che si estende a sinistra e a destra di IdMatch.

L'esempio seguente illustra in che modo la finestra di prossimità influisce sull'algoritmo corrispondente in cui l'elemento IdMatch SSN richiede almeno una delle corrispondenze di conferma di indirizzo, nome o data. Solo SSN1 e SSN4 generano una corrispondenza perché per SSN2 e SSN3 non viene trovata alcuna prova oppure ne viene trovata solo una parziale nella finestra di prossimità.

Il corpo del messaggio e ogni allegato vengono considerati come elementi indipendenti. Questa condizione significa che la finestra di prossimità non si estende oltre la fine di ognuno di questi elementi. Per ogni elemento (allegato o corpo), sia l'idMatch che l'evidenza corroborativa devono risiedere all'interno di ogni elemento.
Livello di sicurezza dell'entità
Il livello di sicurezza dell'elemento entità è la combinazione di tutti i livelli di sicurezza del modello soddisfatto. Vengono combinati usando l'equazione seguente:

dove k è il numero di elementi Pattern per l'entità e un criterio che non corrisponde restituisce un livello di confidenza pari a 0.
Tornando all'esempio del codice della struttura dell'elemento entità, se entrambi gli schemi vengono soddisfatti, il livello di sicurezza dell'entità è 94,75% in base al calcolo seguente:
CLEntity= 1-[(1-CLPattern1) x (1-CLPattern1)]
= 1-[(1-0,85) x (1-0,65)]
= 1-(0,15 x 0,35)
= 94.75%
Analogamente, se solo il secondo schema genera una corrispondenza, il livello di sicurezza dell'entità è 65% in base al calcolo seguente:
CLEntity= 1 - [(1 - CLPattern1) X (1 - CLPattern1)]
= 1 - [(1 - 0) X (1 - 0,65)]
= 1 - (1 X 0,35)
= 65%
Questi valori di sicurezza vengono assegnati nelle regole per schemi individuali in base al set di documenti di prova convalidati come parte del processo di creazione della regola.
Regole dell'affinità
Le regole di affinità sono destinate a contenuti senza identificatori ben definiti, ad esempio Sarbanes-Oxley o contenuti finanziari aziendali. Per questo contenuto, non è possibile trovare un singolo identificatore coerente e l'analisi richiede invece di determinare se è presente una raccolta di prove. Le regole di affinità non restituiscono un conteggio, ma restituiscono se trovate e il livello di confidenza associato. Il contenuto di affinità è rappresentato come una raccolta di evidenze indipendenti. Evidenza è un'aggregazione di corrispondenze necessarie entro una determinata prossimità. Per la regola affinità, la prossimità è definita dall'attributo evidencesProximity (il valore predefinito è 600) e dal livello di attendibilità minimo dall'attributo thresholdConfidenceLevel.
Le regole di affinità contengono l'attributo Id per l'identificatore univoco usato per la localizzazione, il controllo delle versioni e l'esecuzione di query. A differenza delle regole di entità, poiché le regole di affinità non si basano su identificatori ben definiti, non contengono l'elemento IdMatch.
Ogni regola di affinità contiene uno o più elementi evidence figlio che definiscono l'evidenza da trovare e il livello di attendibilità che contribuisce alla regola di affinità. L'affinità non viene considerata trovata se il livello di confidenza risultante è inferiore al livello di soglia. Ciascuna prova rappresenta logicamente la prova convalidante per questo "tipo" di documento e l'attributo confidenceLevel è la precisione per la prova nel set di dati di prova.
Gli elementi Evidence hanno uno o più elementi figlio Match e Any. Se tutti gli elementi figlio Match e Any vengono soddisfatti, viene trovata la prova e il livello di sicurezza contribuisce al calcolo del livello di sicurezza delle regole. La stessa descrizione si applica agli elementi Match e Any per le regole di affinità e per le regole di entità.
<Affinity id="..."
evidencesProximity="1000"
thresholdConfidenceLevel="65">
<Evidence confidenceLevel="40">
<Any>
<Match idRef="AssetsTerms" />
<Match idRef="BalanceSheetTerms" />
<Match idRef="ProfitAndLossTerms" />
</Any>
</Evidence>
<Evidence confidenceLevel="40">
<Any minMatches="2">
<Match idRef="TaxTerms" />
<Match idRef="DollarAmountTerms" />
<Match idRef="SECTerms" />
<Match idRef="SECFilingFormTerms" />
<Match idRef="DollarTotalRegex" />
</Any>
</Evidence>
</Affinity>
Finestra di prossimità di affinità
La finestra di prossimità per l'affinità è calcolata in modo diverso rispetto agli schemi dell'entità. La prossimità dell'affinità segue un modello di finestra scorrevole. L'algoritmo di prossimità dell'affinità tenta di trovare il numero massimo di prove corrispondenti nella finestra data. Le prove nella finestra di affinità devono avere un livello di sicurezza maggiore rispetto alla soglia definita per la regola dell'affinità da trovare.

Livello di sicurezza dell'affinità
Il livello di sicurezza dell'affinità equivale alla combinazione delle prove trovate all'interno della finestra di prossimità per la regola dell'affinità. Analogamente al livello di sicurezza della regola dell'entità, la differenza principale sta nell'applicazione della finestra di prossimità. Analogamente alle regole dell'entità, il livello di sicurezza dell'elemento Affinity è la combinazione di tutti i livelli di sicurezza delle prove soddisfatti, ma per la regola dell'affinità rappresenta solo la combinazione più elevata degli elementi di prova trovati all'interno della finestra di prossimità. I livelli di sicurezza delle prove sono combinati utilizzando la seguente equazione:
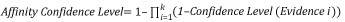
dove k è il numero di elementi di prova per l'affinità soddisfatti all'interno della finestra di prossimità.
Tornando all'esempio della figura 4 con la struttura della regola dell'affinità, se tutte e tre le prove vengono soddisfatte all'interno della finestra a scorrimento della prossimità, il livello di sicurezza dell'affinità è 85,6%, in base al calcolo in basso. Questo valore supera la soglia della regola di affinità pari a 65, che determina la corrispondenza delle regole.
CLAffinità= 1 - [(1 - CLEvidenza 1) X (1 - CLEvidenza 2) X (1 - CLEvidenza 2)]
= 1 - [(1 - 0,6) X (1 - 0,4) X (1 - 0,4)]
= 1 - (0,4 x 0,6 X 0,6)
= 85.6%

Usando la stessa definizione di regola di esempio, se solo la prima evidenza corrisponde perché la seconda evidenza si trova all'esterno della finestra di prossimità, il livello di probabilità di affinità più alto è del 60% in base al calcolo seguente e la regola di affinità non corrisponde perché la soglia di 65 non è stata raggiunta.
CLAffinità= 1 - [(1 - CLEvidenza 1) X (1 - CLEvidenza 2) X (1 - CLEvidenza 2)]
= 1 - [(1 - 0,6) X (1 - 0) X (1 - 0)]
= 1 - (0,4 x 1 X 1)
= 60%

Regolazione dei livelli di sicurezza
Uno degli aspetti principali del processo di creazione della regola è la regolazione dei livelli di sicurezza per le regole dell'entità e dell'affinità. Dopo la creazione delle definizioni di regole, eseguire la regola sul contenuto rappresentativo e raccogliere i dati di accuratezza. Confrontare i risultati restituiti per ciascuno schema o prova in base ai risultati previsti per i documenti di prova.

Se le regole soddisfano i requisiti di accettazione, ovvero il criterio o l'evidenza hanno una velocità di attendibilità superiore a una soglia stabilita (ad esempio, il 75%), l'espressione di corrispondenza è completa e può essere spostata al passaggio successivo.
Se il criterio o l'evidenza non soddisfa il livello di attendibilità, riautorarlo (ad esempio, aggiungere altre prove corroborative, rimuovere o aggiungere modelli/evidenze aggiuntivi e così via) e ripetere questo passaggio.
Quindi, regolare il livello di sicurezza per ciascuno schema o prova nelle regole basate sui risultati dal passaggio precedente. Per ogni modello o evidenza, aggregare il numero di True Positives (TP), subset dei documenti che contengono l'entità o l'affinità per cui viene creata la regola e che hanno generato una corrispondenza e il numero di falsi positivi (FP), un subset di documenti che non contengono l'entità o l'affinità per cui viene creata la regola e che hanno restituito anche una corrispondenza. Impostare il livello di sicurezza per ogni modello/prova mediante il seguente calcolo:
Livello di sicurezza = veri positivi / (veri positivi + falsi positivi)
| Modello o prova | Veri positivi | Falsi positivi | Livello di sicurezza |
|---|---|---|---|
| P1o E1 | 4 | 1 | 80% |
| P2o E2 | 2 | 2 | 50% |
| Pno En | 9 | 10 | 47% |
Utilizzo delle lingue locali nel file XML
Lo schema delle regole supporta l'archiviazione del nome e delle descrizione localizzati per ciascun elemento Entity e Affinity. Ciascun elemento Entity e Affinity deve contenere un elemento corrispondente nella sezione LocalizedStrings. Per localizzare ciascun elemento, includere un elemento Resource come figlio dell'elemento LocalizedStrings per archiviare nome e descrizioni per più impostazioni locali per ciascun elemento. L'elemento Resource include un attributo idRef obbligatorio che corrisponde all'attributo idRef corrispondente per ogni elemento localizzato. Gli elementi figlio Locale dell'elemento Resource contengono il nome localizzato e le descrizioni per ogni impostazione locale specificata.
<LocalizedStrings>
<Resource idRef="guid">
<Locale langcode="en-US" default="true">
<Name>affinity name en-us</Name>
<Description>
affinity description en-us
</Description>
</Locale>
<Locale langcode="de">
<Name>affinity name de</Name>
<Description>
affinity description de
</Description>
</Locale>
</Resource>
</LocalizedStrings>
Definizione dello schema XML per il pacchetto delle regole di classificazione
<?xml version="1.0" encoding="utf-8"?>
<xs:schema xmlns:mce="http://schemas.microsoft.com/office/2011/mce"
targetNamespace="http://schemas.microsoft.com/office/2011/mce"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
id="RulePackageSchema">
<xs:simpleType name="LangType">
<xs:union memberTypes="xs:language">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:enumeration value=""/>
</xs:restriction>
</xs:simpleType>
</xs:union>
</xs:simpleType>
<xs:simpleType name="GuidType" final="#all">
<xs:restriction base="xs:token">
<xs:pattern value="[0-9a-fA-F]{8}\-([0-9a-fA-F]{4}\-){3}[0-9a-fA-F]{12}"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulePackageType">
<xs:sequence>
<xs:element name="RulePack" type="mce:RulePackType"/>
<xs:element name="Rules" type="mce:RulesType">
<xs:key name="UniqueRuleId">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueProcessorId">
<xs:selector xpath="mce:Regex|mce:Keyword"></xs:selector>
<xs:field xpath="@id"/>
</xs:key>
<xs:key name="UniqueResourceIdRef">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:key>
<xs:keyref name="ReferencedRuleMustExist" refer="mce:UniqueRuleId">
<xs:selector xpath="mce:LocalizedStrings/mce:Resource"/>
<xs:field xpath="@idRef"/>
</xs:keyref>
<xs:keyref name="RuleMustHaveResource" refer="mce:UniqueResourceIdRef">
<xs:selector xpath="mce:Entity|mce:Affinity"/>
<xs:field xpath="@id"/>
</xs:keyref>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="RulePackType">
<xs:sequence>
<xs:element name="Version" type="mce:VersionType"/>
<xs:element name="Publisher" type="mce:PublisherType"/>
<xs:element name="Details" type="mce:DetailsType">
<xs:key name="UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="mce:LocalizedDetails"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:keyref name="DefaultLangCodeMustExist" refer="mce:UniqueLangCodeInLocalizedDetails">
<xs:selector xpath="."/>
<xs:field xpath="@defaultLangCode"/>
</xs:keyref>
</xs:element>
<xs:element name="Encryption" type="mce:EncryptionType" minOccurs="0" maxOccurs="1"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="VersionType">
<xs:attribute name="major" type="xs:unsignedShort" use="required"/>
<xs:attribute name="minor" type="xs:unsignedShort" use="required"/>
<xs:attribute name="build" type="xs:unsignedShort" use="required"/>
<xs:attribute name="revision" type="xs:unsignedShort" use="required"/>
</xs:complexType>
<xs:complexType name="PublisherType">
<xs:attribute name="id" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="LocalizedDetailsType">
<xs:sequence>
<xs:element name="PublisherName" type="mce:NameType"/>
<xs:element name="Name" type="mce:RulePackNameType"/>
<xs:element name="Description" type="mce:OptionalNameType"/>
</xs:sequence>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="DetailsType">
<xs:sequence>
<xs:element name="LocalizedDetails" type="mce:LocalizedDetailsType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="defaultLangCode" type="mce:LangType" use="required"/>
</xs:complexType>
<xs:complexType name="EncryptionType">
<xs:sequence>
<xs:element name="Key" type="xs:normalizedString"/>
<xs:element name="IV" type="xs:normalizedString"/>
</xs:sequence>
</xs:complexType>
<xs:simpleType name="RulePackNameType">
<xs:restriction base="xs:token">
<xs:minLength value="1"/>
<xs:maxLength value="64"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="NameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="1"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="OptionalNameType">
<xs:restriction base="xs:normalizedString">
<xs:minLength value="0"/>
<xs:maxLength value="256"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="RestrictedTermType">
<xs:restriction base="xs:string">
<xs:minLength value="1"/>
<xs:maxLength value="512"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RulesType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Entity" type="mce:EntityType"/>
<xs:element name="Affinity" type="mce:AffinityType"/>
</xs:choice>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Regex" type="mce:RegexType"/>
<xs:element name="Keyword" type="mce:KeywordType"/>
</xs:choice>
<xs:element name="LocalizedStrings" type="mce:LocalizedStringsType"/>
</xs:sequence>
</xs:complexType>
<xs:complexType name="EntityType">
<xs:sequence>
<xs:element name="Pattern" type="mce:PatternType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="patternsProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="recommendedConfidence" type="mce:ProbabilityType"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="PatternType">
<xs:sequence>
<xs:element name="IdMatch" type="mce:IdMatchType"/>
<xs:choice minOccurs="0" maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="AffinityType">
<xs:sequence>
<xs:element name="Evidence" type="mce:EvidenceType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="mce:GuidType" use="required"/>
<xs:attribute name="evidencesProximity" type="mce:ProximityType" use="required"/>
<xs:attribute name="thresholdConfidenceLevel" type="mce:ProbabilityType" use="required"/>
<xs:attribute name="workload" type="mce:WorkloadType"/>
</xs:complexType>
<xs:complexType name="EvidenceType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="confidenceLevel" type="mce:ProbabilityType" use="required"/>
</xs:complexType>
<xs:complexType name="IdMatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="MatchType">
<xs:attribute name="idRef" type="xs:string" use="required"/>
</xs:complexType>
<xs:complexType name="AnyType">
<xs:sequence>
<xs:choice maxOccurs="unbounded">
<xs:element name="Match" type="mce:MatchType"/>
<xs:element name="Any" type="mce:AnyType"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="minMatches" type="xs:nonNegativeInteger" default="1"/>
<xs:attribute name="maxMatches" type="xs:nonNegativeInteger" use="optional"/>
</xs:complexType>
<xs:simpleType name="ProximityType">
<xs:restriction base="xs:positiveInteger">
<xs:minInclusive value="1"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="ProbabilityType">
<xs:restriction base="xs:integer">
<xs:minInclusive value="1"/>
<xs:maxInclusive value="100"/>
</xs:restriction>
</xs:simpleType>
<xs:simpleType name="WorkloadType">
<xs:restriction base="xs:string">
<xs:enumeration value="Exchange"/>
<xs:enumeration value="Outlook"/>
</xs:restriction>
</xs:simpleType>
<xs:complexType name="RegexType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="KeywordType">
<xs:sequence>
<xs:element name="Group" type="mce:GroupType" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="id" type="xs:token" use="required"/>
</xs:complexType>
<xs:complexType name="GroupType">
<xs:sequence>
<xs:choice>
<xs:element name="Term" type="mce:TermType" maxOccurs="unbounded"/>
</xs:choice>
</xs:sequence>
<xs:attribute name="matchStyle" default="word">
<xs:simpleType>
<xs:restriction base="xs:NMTOKEN">
<xs:enumeration value="word"/>
<xs:enumeration value="string"/>
</xs:restriction>
</xs:simpleType>
</xs:attribute>
</xs:complexType>
<xs:complexType name="TermType">
<xs:simpleContent>
<xs:extension base="mce:RestrictedTermType">
<xs:attribute name="caseSensitive" type="xs:boolean" default="false"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="LocalizedStringsType">
<xs:sequence>
<xs:element name="Resource" type="mce:ResourceType" maxOccurs="unbounded">
<xs:key name="UniqueLangCodeUsedInNamePerResource">
<xs:selector xpath="mce:Name"/>
<xs:field xpath="@langcode"/>
</xs:key>
<xs:key name="UniqueLangCodeUsedInDescriptionPerResource">
<xs:selector xpath="mce:Description"/>
<xs:field xpath="@langcode"/>
</xs:key>
</xs:element>
</xs:sequence>
</xs:complexType>
<xs:complexType name="ResourceType">
<xs:sequence>
<xs:element name="Name" type="mce:ResourceNameType" maxOccurs="unbounded"/>
<xs:element name="Description" type="mce:DescriptionType" minOccurs="0" maxOccurs="unbounded"/>
</xs:sequence>
<xs:attribute name="idRef" type="mce:GuidType" use="required"/>
</xs:complexType>
<xs:complexType name="ResourceNameType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
<xs:complexType name="DescriptionType">
<xs:simpleContent>
<xs:extension base="xs:string">
<xs:attribute name="default" type="xs:boolean" default="false"/>
<xs:attribute name="langcode" type="mce:LangType" use="required"/>
</xs:extension>
</xs:simpleContent>
</xs:complexType>
</xs:schema>