Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
🚀 CI/CD per Microsoft Fabric con Azure DevOps e il
In questa esercitazione si usa la libreria python fabric-cicd per alzare di livello gli elementi modificati (ad esempio, un notebook specifico) dall'area di lavoro di sviluppo all'area di lavoro di test e infine per eseguire il prod.
1. Panoramica dello scenario
Incontra Alex , un responsabile di sviluppo che collabora con Microsoft Fabric.
Il team di Alex crea notebook, pipeline di dati, modelli semantici e report in un spazio di lavoro di Fabric di sviluppo. Quando le funzionalità sono pronte, Alex deve alzare di livello gli elementi modificati (ad esempio, un notebook specifico) dall'area di lavoro di sviluppo all'area di lavoro di test e infine a prod.
La sfida
I notebook di Alex usano il comando magico %%configure per collegarsi a una lakehouse specifica. Ciò significa che le definizioni del notebook contengono GUID hardcoded — ID area di lavoro, ID Lakehouse e ID endpoint SQL — che sono diversi in ogni ambiente.
Cosa si aspetta Alex
| Requisito | Soluzione |
|---|---|
| Distribuire gli elementi modificati uniti al ramo |
fabric-cicd
publish_all_items() distribuisce tutti i tipi di elementi nell'ambito definito |
| Definizione esplicita dell'ambito del tipo di elemento | Parametro items_in_scope della pipeline: è necessario specificare i tipi di elemento da distribuire |
| Flusso di lavoro di approvazione prima della distribuzione in test/prod | Ambienti ADO con gate di approvazione |
| Sostituzione automatica del GUID (dev → test/prod) |
fabric-cicd file di parametri (parameter.yml) |
| Gestione sicura delle credenziali | Azure Key Vault e gruppi di variabili ADO |
| Trigger automatizzato nell'unione nel ramo | Pipeline ADO con trigger di ramo |
Strumenti
| Tool | Scopo |
|---|---|
| Azure DevOps (ADO) | Orchestrazione CI/CD, hosting Git, approvazioni |
fabric-cicd Pacchetto Python |
Libreria open source di Microsoft per la distribuzione di elementi di Fabric |
| Azure Key Vault | Archivia in modo sicuro le credenziali del Service Principal |
| Service Principal (SPN) | Esegue l'autenticazione con l'API REST di Fabric |
2. Diagramma dell'architettura
Il diagramma seguente illustra il flusso del tutorial.

3. Prerequisiti
Prima di iniziare, assicurarsi di disporre dei seguenti elementi:
| # | Prerequisito | Dettagli |
|---|---|---|
| 1 | Organizzazione e progetto di Azure DevOps | Un progetto con Repos e Pipeline abilitate |
| 2 | Aree di lavoro di Microsoft Fabric | Tre aree di lavoro, ognuna per sviluppo, test e produzione |
| 3 | Service Principal (SPN) | Registrazione di un'app Entra ID (Azure AD) con un segreto client |
| 4 | Autorizzazioni SPN in Fabric | Il nome SPN deve essere aggiunto come Membro o Amministratore in ogni area di lavoro del Fabric di destinazione. |
| 5 | Azure Key Vault | Un Key Vault con tre segreti: ID tenant, ID client e segreto client |
| 6 | Integrazione Git di Fabric | L'area di lavoro di sviluppo deve essere connessa al dev ramo del repository ADO |
| 7 | Python 3.12+ | Usato nell'agente di pipeline per eseguire lo script di distribuzione |
| 8 |
fabric-cicd Pacchetto Python |
Libreria di distribuzione open source (PyPI) di Microsoft |
| 9 | Impostazione amministratore infrastruttura per SPN | Un amministratore di Infrastruttura deve abilitare "Le entità servizio possono usare le API di Infrastruttura" nel portale di amministrazione di Fabric in Impostazioni tenant |
💡 Suggerimento: Per abilitare l'accesso al principal del servizio in Fabric, un Amministratore di Fabric deve abilitare "I principal del servizio possono usare le API di Fabric" nel portale di amministrazione di Fabric in Tenant Settings.
Scaricare i file di origine
- Crea un fork del repository Fabric-samples nel tuo account GitHub.
- Clona il tuo fork sul computer locale.
git clone https://github.com/<your-account>/fabric-samples.git
cd fabric-samples
4. Configurazione iniziale di Azure DevOps
Questa sezione illustra tutte le risorse di Azure DevOps da configurare prima che la pipeline possa essere eseguita.
4.1 Integrazione di Azure Key Vault
Le credenziali dell'entità servizio (ID tenant, ID client e segreto) non devono mai essere archiviate in testo normale. Invece, archiviarli in Azure Key Vault.
Procedura per configurare Azure Key Vault
- Creare un Key Vault nel portale di Azure (o usarne uno esistente).
- Aggiungere tre segreti:
| Nome segreto | Descrzione | Valore di esempio |
|---|---|---|
aztenantid |
ID tenant di Azure AD/Entra ID | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx |
azclientid |
ID applicazione (client) del principale del servizio | xxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx |
azspnsecret |
Valore del segreto client dell'entità servizio | your-secret-value |
Concedere l'accesso: La connessione al servizio ADO (o l'identità del progetto ADO) deve disporre delle autorizzazioni Get ed List per i segreti nelle politiche di accesso del Key Vault (o ruolo RBAC
Key Vault Secrets User).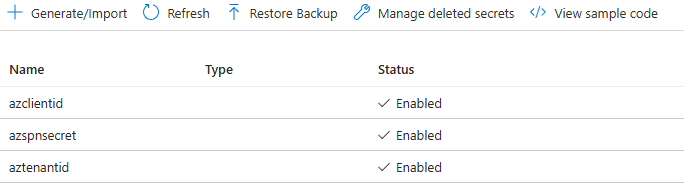

4.2 Gruppo di variabili: fabric_cicd_group_sensitive
Questo gruppo di variabili è collegato ad Azure Key Vault, ovvero i valori dei segreti vengono recuperati in fase di esecuzione e non vengono mai esposti nell'interfaccia utente ADO.
Passaggi per la creazione
- Passare a Pipeline → Library nel progetto ADO.
- Fare clic su + Gruppo di variabili.
- Denominarlo:
fabric_cicd_group_sensitive - Attivare Collega segreti da un insieme di credenziali delle chiavi di Azure come variabili.
- Selezionare la sottoscrizione di Azure e Key Vault.
- Fare clic su + Aggiungi e selezionare i tre segreti:
aztenantidazclientidazspnsecret
- Fare clic su Salva.
| Variable | Fonte | Sensibile? |
|---|---|---|
aztenantid |
Azure Key Vault (Archivio chiavi di Azure) | ✅ Sì |
azclientid |
Azure Key Vault (Archivio chiavi di Azure) | ✅ Sì |
azspnsecret |
Azure Key Vault (Archivio chiavi di Azure) | ✅ Sì |

Importante
Poiché queste variabili sono collegate a Key Vault, sono accessibili nella pipeline YAML come $(aztenantid), $(azclientid)e $(azspnsecret). Vengono mascherati automaticamente nei log.
4.3 Gruppo di variabili: fabric_cicd_group_non_sensitive
Questo gruppo di variabili archivia i valori di configurazione non segreti, in particolare i nomi delle aree di lavoro per ogni ambiente e il percorso della directory Git.
Passaggi per la creazione
- Passare a Pipeline → Library nel progetto ADO.
- Fare clic su + Gruppo di variabili.
- Nominalo:
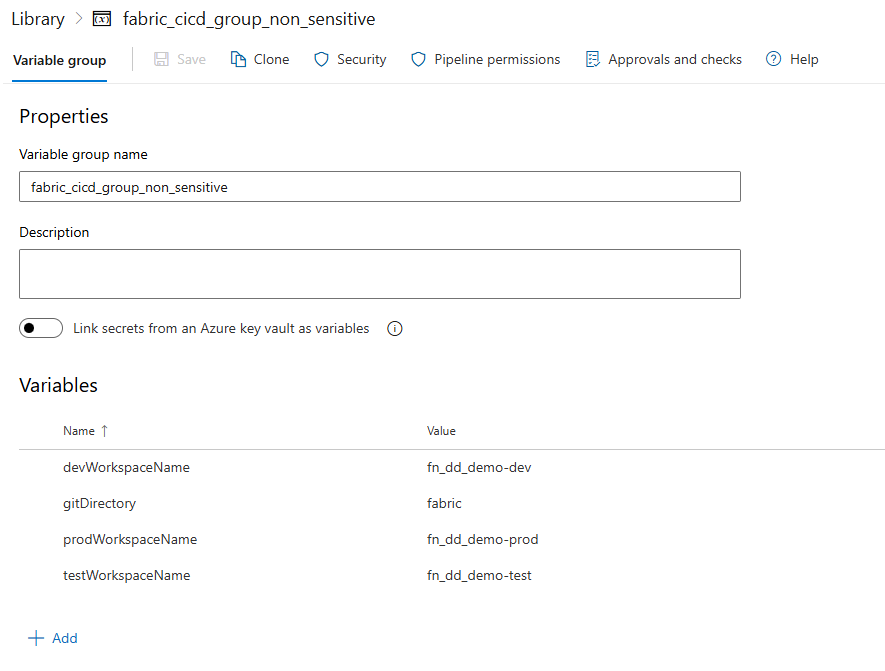
fabric_cicd_group_non_sensitive - Aggiungere le variabili seguenti:
| Nome variabile | Value | Descrzione |
|---|---|---|
devWorkspaceName |
MyProject-Dev |
Nome dell'area di lavoro DEV Fabric |
testWorkspaceName |
MyProject-Test |
Nome dell'area di lavoro TEST Fabric |
prodWorkspaceName |
MyProject-Prod |
Nome dell'area di lavoro PROD Fabric |
gitDirectory |
fabric |
La cartella nel tuo repository che contiene le definizioni degli elementi di Fabric |
Fare clic su Salva.

💡 Funzionamento nel codice: Lo script Python legge questi valori usando
os.environ. Ad esempio, quando si esegue la distribuzione intest, lo script costruisce il nometestWorkspaceNamedella variabile , lo converte in maiuscolo (TESTWORKSPACENAME) e lo legge dall'ambiente perché ADO inserisce automaticamente i valori del gruppo di variabili non sensibili come variabili di ambiente in maiuscolo.
4.4 Ambienti ADO e controlli di approvazione
Gli ambienti ADO consentono di aggiungere controlli di approvazione manuali prima che le distribuzioni procedano. Questa operazione è fondamentale per promuovere test e prod.
Passaggi per la creazione di ambienti
- Passare a Pipeline → Ambienti nel progetto ADO.
- Creare tre ambienti con i nomi esatti corrispondenti ai nomi dei rami:
| Nome dell'ambiente | Approvazione richiesta? | Responsabili dell'approvazione |
|---|---|---|
dev |
❌ No (distribuzione automatica) | — |
test |
✅ Sì | Team di amministrazione/Responsabile |
prod |
✅ Sì | Team di amministrazione/Responsabile |
Per
testeprodfare clic sull'ambiente → ⋮ (altre opzioni) → Approvazioni e controlli → + Aggiungi controllo → Approvazioni.Aggiungere gli approvatori necessari.
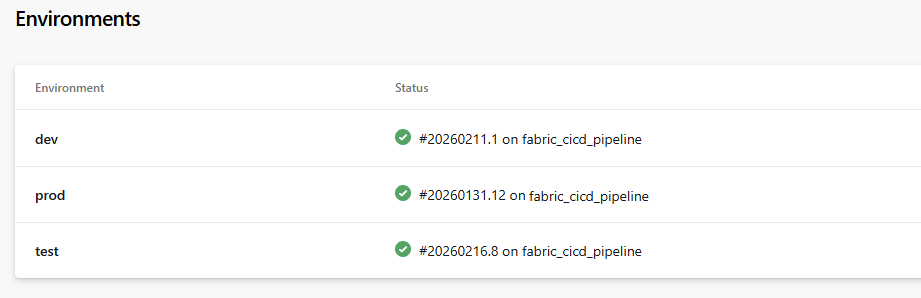

Visualizzazione dello stato dell'ambiente di esempio:
| Ambiente | Stato |
|---|---|
| Sviluppatore | ✅ #20260211.1 su fabric_cicd_pipeline |
| test | ✅ #20260216.8 in fabric_cicd_pipeline |
| prod | ✅ #20260131.12 su fabric_cicd_pipeline |
💡 Perché gli ambienti? La pipeline YAML usa processi
deploymentconenvironment: $(target_env). Quandotarget_envètestoprod, ADO sospende la pipeline e attende che i responsabili approvazione configurati approvino prima di procedere.
4.5 Strategia del branch Git
La strategia di diramazione è fondamentale per questa configurazione CI/CD. Sono necessari tre rami di lunga durata:

Punti chiave
| Branch | Connesso all'area di lavoro Fabric? | Scopo |
|---|---|---|
dev |
✅ Sì sincronizzato con l'area di lavoro DEV | Fonte di verità. Le modifiche apportate nel workspace DEV vengono confermate qui. |
test |
❌ No | Riceve gli elementi promossi tramite l'unione di pull request. Monitora ciò che viene distribuito in TEST. |
prod |
❌ No | Riceve gli elementi promossi tramite la fusione di PR. Tiene traccia di ciò che viene distribuito in PROD. |
Perché è connesso solo dev
- L'integrazione Git di Fabric sincronizza gli elementi dell'area di lavoro in modo bidirezionale con un ramo Git.
- I
testeprodrami non sono connessi alle aree di lavoro perché il pacchettofabric-cicdgestisce la distribuzione direttamente tramite la Fabric REST API. - Questi rami fungono da record di esattamente quali versioni degli elementi sono state alzate di livello a ogni ambiente.
4.6 Configurazione della pipeline ADO
Creare una pipeline in ADO che faccia riferimento al file YAML nel repository.
Steps
- Passare a Pipeline → Pipeline → Nuova pipeline.
- Scegliere Azure Repos Git e selezionare il repository.
- Scegliere File YAML di Azure Pipelines esistente.
- Punta al percorso:
Deploy-To-Fabric.yml(o ovunque lo abbia posizionato). -
Denominare la pipeline:
fabric_cicd_pipeline. - In Autorizzazioni pipeline verificare che abbia accesso a:
- Entrambi i gruppi di variabili (
fabric_cicd_group_sensitiveefabric_cicd_group_non_sensitive) - Tutti e tre gli ambienti (
dev,test,prod)
- Salva (non ancora eseguito).
⚠️ Suggerimento per l'autorizzazione: la prima volta che viene eseguita la pipeline, ADO potrebbe richiedere di autorizzare l'accesso ai gruppi di variabili e agli ambienti. Un amministratore ADO può pre-autorizzare questi elementi in Impostazioni → pipeline.
5. Approfondimento del codice: YAML della pipeline ADO
File:Deploy-To-Fabric.yml- disponibile nel repository GitHub scaricato in precedenza.
Di seguito è presentata la pipeline completa con annotazioni riga per riga.
# ──────────────────────────────────────────────────────────────
# TRIGGER: Runs automatically when code is pushed to dev, test, or prod
# Only triggers when changes are in the "fabric/" folder
# ──────────────────────────────────────────────────────────────
trigger:
branches:
include: [test, prod]
paths:
include:
- fabric/**
🔍 Attivatore di Spiegazione
- La pipeline viene attivata automaticamente sui commit ai rami
testoprod. Non viene attivato perchédevdevè il ramo di origine connesso all'integrazione Git di Fabric. - Il filtro
pathsgarantisce che si attivi solo quando vengono modificati file all'interno della directoryfabric/, evitando esecuzioni non necessarie dovute a cambiamenti nella documentazione, negli script, ecc. - In pratica: quando una richiesta pull viene unita da
dev→test, il commit di merge arriva nel ramotest, attivando la pipeline destinata all'ambiente di TEST.
# ──────────────────────────────────────────────────────────────
# PARAMETERS: Runtime input-which Fabric item types to deploy
# ──────────────────────────────────────────────────────────────
parameters:
- name: items_in_scope
displayName: Enter Fabric items to be deployed
type: string
default: '["Notebook","DataPipeline","Lakehouse","SemanticModel","Report","VariableLibrary"]'
🔍 Spiegazione-Parametri
- In questo modo viene definito un parametro di runtime che controlla i tipi di elementi di Fabric inclusi nell'ambito della distribuzione.
- Se questo parametro non è specificato, verranno distribuiti tutti i tipi di elemento supportati dal
fabric-cicdpacchetto. - Questa opzione funge anche da metodo per la distribuzione selettiva; ad esempio, è possibile passare solo
["Notebook"]per distribuire soltanto i notebook.
⚠️ Avviso di distribuzione selettiva: se si restringe
items_in_scopeper una distribuzione selettiva, non è consigliabile chiamareunpublish_all_orphan_items()nello script Python perché rimuoverà gli elementi dei tipi specificati initems_in_scopeche esistono nell'area di lavoro ma non sono presenti nel ramo di rilascio. Ad esempio, se si distribuisce solo["Notebook"]e nell'area di lavoro sono presenti Notebook che non si trovano nel ramo, questi verranno eliminati, anche se potrebbero essere ancora validi. Non rimuoverà elementi di altri tipi, ad esempio Pipeline, Report e così via. Utilizzareunpublish_all_orphan_items()solo quando il ramo rappresenta lo stato desiderato completo per i tipi di elemento nell'ambito.
# ──────────────────────────────────────────────────────────────
# VARIABLES: Environment-specific config & secrets
# ──────────────────────────────────────────────────────────────
variables:
- name: target_env
value: ${{ replace(variables['Build.SourceBranch'], 'refs/heads/', '') }}
- group: fabric_cicd_group_sensitive
- group: fabric_cicd_group_non_sensitive
🔍 Variabili di Spiegazione
| Variable | Funzionamento |
|---|---|
target_env |
Estrae dinamicamente il nome del ramo da Build.SourceBranch. Ad esempio, refs/heads/test → test. Questa singola variabile determina l'intero comportamento compatibile con l'ambiente. |
fabric_cicd_group_sensitive |
Estrae aztenantid, azclientid, azspnsecret da Azure Key Vault durante l'esecuzione. |
fabric_cicd_group_non_sensitive |
Esegue il pull dei nomi delle aree di lavoro e gitDirectory come variabili di ambiente semplici. |
# ──────────────────────────────────────────────────────────────
# STAGES & JOBS: Single deployment stage
# ──────────────────────────────────────────────────────────────
stages:
- stage: DeployToFabric
displayName: "Deploy to Fabric Workspace"
jobs:
- deployment: Deployment
displayName: "Deploy Resources"
environment: $(target_env) # ◀── THIS triggers the approval gate!
pool:
name: Azure Pipelines
strategy:
runOnce:
deploy:
steps:
🔍 attività Spiegazione-Distribuzione
| Elemento | Scopo |
|---|---|
deployment: (non job:) |
Per usare ambienti ADO è necessario un processo di distribuzione . Abilita controlli di approvazione, cronologia della distribuzione e audit trail. |
environment: $(target_env) |
Esegue il mapping all'ambiente ADO corrispondente al nome del ramo (dev, test o prod). Se le approvazioni sono configurate in tale ambiente, la pipeline viene sospesa fino all'approvazione. |
strategy: runOnce |
Esegue i passaggi di distribuzione esattamente una volta (anziché le strategie "canary" o di rollout). |
steps:
# Step 1: Checkout the source code
- checkout: self
# Step 2: Set up Python 3.12
- task: UsePythonVersion@0
inputs:
versionSpec: '3.12'
addToPath: true
displayName: "Set up Python Environment"
# Step 3: Install dependencies
- script: |
python -m pip install --upgrade pip
pip install fabric-cicd
displayName: "Install Fabric CICD Library"
# Step 4: Run the deployment script
- task: PythonScript@0
inputs:
scriptSource: 'filePath'
scriptPath: '.deploy/deploy-to-fabric.py'
arguments: >-
--aztenantid $(aztenantid)
--azclientid $(azclientid)
--azspsecret $(azspnsecret)
--items_in_scope ${{ parameters.items_in_scope }}
--target_env $(target_env)
displayName: 'Run deployment using fabric-cicd'
🔍 Passaggi di spiegazione
| Passo | Che cosa fa |
|---|---|
| Checkout | Clona il repository in modo che la pipeline abbia accesso alle definizioni degli elementi di Fabric nella fabric/ cartella e nello script di distribuzione. |
| Installazione di Python | Installa Python 3.12 nell'agente di compilazione. Il fabric-cicd pacchetto richiede Python 3.10+. |
| Installare le dipendenze | Installa il fabric-cicd pacchetto da PyPI. Questa è la libreria ufficiale di Microsoft per le distribuzioni automatizzate di Fabric. |
| Esegui Script | Esegue lo script di distribuzione Python, passando tutti gli argomenti necessari: credenziali SPN (da Key Vault), l'elenco dei tipi di elemento da distribuire e il nome dell'ambiente di destinazione. |
⚠️ Nota sulla sicurezza: i
$(aztenantid)valori ,$(azclientid)e$(azspnsecret)vengono recuperati dal gruppo di variabili collegate a Key Vault. Sono mascherati automaticamente nei log della pipeline, quindi vedrai***al posto dei valori effettivi.
6. Approfondimento del codice: Script di distribuzione Python
File:.deploy/deploy-to-fabric.py : disponibile nel repository GitHub scaricato in precedenza.
Questo è il cuore della distribuzione. Esaminiamo ogni sezione.
6.1 Importazioni e dipendenze
import os, argparse, requests, ast
from fabric_cicd import (
FabricWorkspace,
publish_all_items,
unpublish_all_orphan_items,
change_log_level,
append_feature_flag,
)
from azure.identity import ClientSecretCredential
| Import | Scopo |
|---|---|
os |
Accedere alle variabili di ambiente (valori del gruppo di variabili non sensibili) |
argparse |
Analizzare gli argomenti della riga di comando passati dalla pipeline |
requests |
Effettuare chiamate HTTP all'API REST di Fabric (per la ricerca dell'ID del workspace) |
fabric_cicd |
Libreria di Microsoft: gestisce l'elevato carico di distribuzione degli elementi di Fabric |
ClientSecretCredential |
Libreria di identità di Azure: esegue l'autenticazione usando le credenziali SPN |
6.2 Funzione di ricerca ID dell'area di lavoro
def get_workspace_id(p_ws_name, p_token):
url = "https://api.fabric.microsoft.com/v1/workspaces"
headers = {
"Authorization": f"Bearer {p_token.token}",
"Content-Type": "application/json"
}
response = requests.get(url, headers=headers)
ws_id = ''
if response.status_code == 200:
workspaces = response.json()["value"]
for workspace in workspaces:
if workspace["displayName"] == p_ws_name:
ws_id = workspace["id"]
return workspace["id"]
if ws_id == '':
return f"Error: Workspace {p_ws_name} could not found."
else:
return f"Error: {response.status_code}, {response.text}"
Scopo di questa funzione:
- Chiama l'API REST di Fabric (
GET /v1/workspaces) per elencare tutti gli spazi di lavoro a cui l'SPN ha accesso. - Cerca un'area di lavoro la cui
displayNamecorrispondenza corrisponde al nome dell'area di lavoro di destinazione. - Restituisce il GUID dell'area di lavoro se trovato, oppure un messaggio di errore.
💡 Perché non inserire manualmente l'ID dell'area di lavoro? Effettuando una ricerca dinamica per nome, lo script è più resiliente alla ricreazione dell'area di lavoro ed evita di memorizzare i GUID nel gruppo di variabili.
6.3 Flag di funzionalità e registrazione
append_feature_flag("enable_shortcut_publish")
change_log_level("DEBUG")
| Impostazione | Scopo |
|---|---|
enable_shortcut_publish |
Abilita la distribuzione dei Lakehouse shortcuts, una funzionalità opzionale attivata tramite il flag di funzionalità in fabric-cicd. |
DEBUG livello di log |
Fornisce output dettagliato durante la distribuzione, molto utile per la risoluzione dei problemi. L'argomento "DEBUG" è facoltativo: la chiamata change_log_level() senza di esso attiva la registrazione più dettagliata. Rimuovere il change_log_level() se i log di debug non sono necessari. |
6.4 Analisi degli argomenti
parser = argparse.ArgumentParser(description='Process Azure Pipeline arguments.')
parser.add_argument('--aztenantid', type=str, help='tenant ID')
parser.add_argument('--azclientid', type=str, help='SP client ID')
parser.add_argument('--azspsecret', type=str, help='SP secret')
parser.add_argument('--target_env', type=str, help='target environment')
parser.add_argument('--items_in_scope', type=str, help='Defines the item types to be deployed')
args = parser.parse_args()
Questi argomenti vengono passati dal passaggio YAML della pipeline. Il parser li rende disponibili come args.aztenantid, e args.azclientidcosì via.
6.5 Autenticazione
token_credential = ClientSecretCredential(
client_id=args.azclientid,
client_secret=args.azspsecret,
tenant_id=args.aztenantid,
)
Verrà creato un oggetto credenziale di Azure utilizzando l'ID client del Service Principal, il segreto e l'ID tenant. Questa credenziale viene usata entrambe per:
- Chiamata dell'API REST Fabric (ricerca dell'area di lavoro)
- Passaggio a
FabricWorkspaceper lafabric-cicddistribuzione
6.6 Risoluzione dinamica dell'area di lavoro
tgtenv = args.target_env # e.g., "test"
ws_name = f'{tgtenv}WorkspaceName' # e.g., "testWorkspaceName"
workspace_name = os.environ[ws_name.upper()] # reads TESTWORKSPACENAME from env vars
La parte intelligente: Il gruppo fabric_cicd_group_non_sensitive di variabili contiene variabili come devWorkspaceName, testWorkspaceNamee così via. ADO inserisce queste variabili come variabili di ambiente maiuscole. Lo script costruisce dinamicamente il nome della variabile in base all'ambiente di destinazione.
# Generate a token and look up the workspace ID
resource = 'https://api.fabric.microsoft.com/'
scope = f'{resource}.default'
token = token_credential.get_token(scope)
lookup_response = get_workspace_id(workspace_name, token)
if lookup_response.startswith("Error"):
raise ValueError(f"{lookup_response}. Perhaps workspace name is set incorrectly...")
else:
wks_id = lookup_response
6.7 Inizializzare FabricWorkspace & Deploy
repository_directory = os.environ["GITDIRECTORY"] # e.g., "fabric"
item_types = args.items_in_scope.strip("[]").split(",") # Convert string to list
target_workspace = FabricWorkspace(
workspace_id=wks_id,
environment=tgtenv,
repository_directory=repository_directory,
item_type_in_scope=item_types,
token_credential=token_credential,
)
# Deploy!
publish_all_items(target_workspace)
unpublish_all_orphan_items(target_workspace)
| Metodo | Che cosa fa |
|---|---|
FabricWorkspace(...) |
Inizializza il contesto di distribuzione: legge le definizioni degli elementi dal repository Git, carica i file di parametri per la sostituzione GUID e prepara il piano di distribuzione. |
publish_all_items() |
Distribuisce tutti gli elementi pertinenti nell'area di lavoro di destinazione. Gestisce la creazione di nuovi elementi e l'aggiornamento di quelli esistenti. |
unpublish_all_orphan_items() |
Rimuove gli elementi dall'area di lavoro di destinazione che non sono più presenti nel ramo Git, mantenendo pulita l'area di lavoro. |
⚠️ IMPORTANTE: Comprendere
unpublish_all_orphan_items(): Questo metodo eliminerà gli elementi dei tipi specificati initems_in_scopedallo spazio di lavoro di destinazione che non sono presenti nel ramo di rilascio (cioè, il ramo usato come origine per il pacchettofabric-cicd). Non tocca gli elementi di altri tipi. In questa esercitazione, iltestramo contiene tutti gli elementi destinati all'area di lavoro TEST, pertanto è possibile chiamareunpublish_all_orphan_items()in modo sicuro, rimuovendo solo gli elementi eliminati intenzionalmente dal ramo.Tuttavia, se si esegue una distribuzione selettiva (ad esempio, distribuendo solo i Notebook tramite un ambito ristretto
items_in_scope), procedere con cautela conunpublish_all_orphan_items()— eliminerebbe qualsiasi Notebook nell'ambiente di lavoro che non si trovano nel ramo, anche se sono ancora validi e semplicemente non fanno parte della distribuzione selettiva.
💡 Suggerimento:
unpublish_all_orphan_items()permette di escludere elementi specifici dalla rimozione passando un modello regex. Tutti gli elementi i cui nomi corrispondono all'espressione regolare verranno mantenuti nell'area di lavoro anche se non si trovano nel ramo di origine. Per altri dettagli ed esempi di utilizzo, vedere le informazioni di riferimento ufficiali sull'API.
7. Approfondimento del codice: File di parametri (sostituzione GUID)
Questo è il luogo in cui si verifica la magia , ovvero il modo %%configure in cui i GUID vengono scambiati per ogni ambiente.
Funzionamento
Il fabric-cicd pacchetto cerca un file denominato parameter.yml nella .deploy directory (o nella radice del repository). Questo file definisce regole di ricerca e sostituzione applicate alle definizioni degli elementi prima della distribuzione.
💡 Suggerimento: La funzionalità di
parameter.yml"trova e sostituisci" supporta molti approcci oltre a quanto illustrato in questo tutorial, tra cui modelli regex, sostituzioni con ambito file e altro ancora. Per l'elenco completo delle opzioni e dell'utilizzo avanzato, vedere la documentazione ufficiale: 👉fabric-cicd Parameter File Documentation
💡 Suggerimento — Libreria di variabili: È consigliabile sfruttare la libreria di variabili ogni volta che è possibile gestire valori specifici dell'ambiente, anziché basarsi esclusivamente sui
find_replacefile dei parametri. Le librerie di variabili offrono un modo centralizzato e riutilizzabile per gestire la configurazione in ambienti diversi. Per altre informazioni, vedere Introduzione alle librerie di variabili.
File:parameter.yml : disponibile nel repository GitHub scaricato in precedenza.
7.1 Struttura del file di parametri
find_replace:
- find_value: "bfddf0b6-5b74-461a-a963-e89ddc32f852" # DEV Workspace ID
replace_value:
test: " $workspace.$id" # Replaced with TEST workspace ID
prod: " $workspace.$id" # Replaced with PROD workspace ID
🔍 Comprensione di ciascuna voce
Voce 1 - Sostituzione ID area di lavoro
- find_value: "bfddf0b6-5b74-461a-a963-e89ddc32f852" # DEV Workspace ID
replace_value:
test: " $workspace.$id" # Auto-resolves to the TEST workspace's actual ID
prod: " $workspace.$id" # Auto-resolves to the PROD workspace's actual ID
-
find_value: GUID trovato nel comando del notebook — cioè l'ID dell'area di lavoro%%configureDEV. -
replace_value: Il$workspace.$idè un token predefinito infabric-cicdche viene risolto automaticamente nell'ID dell'area di lavoro di destinazione in fase di distribuzione. - Poiché
devnon è elencato inreplace_value, il GUID viene sostituito solo durante la distribuzione intestoprod.
Voce 2 — Sostituzione ID Lakehouse
- find_value: "981f2f9a-0436-4942-b158-019bd73cdf1c" # DEV DemoLakehouse GUID
replace_value:
test: "$items.Lakehouse.DemoLakehouse.$id" # Resolves to TEST Lakehouse ID
prod: "$items.Lakehouse.DemoLakehouse.$id" # Resolves to PROD Lakehouse ID
-
$items.Lakehouse.DemoLakehouse.$idè un token dinamico che cerca la Lakehouse denominataDemoLakehousenell'area di lavoro di destinazione e ne restituisce l'ID. -
Modello:
$items.<ItemType>.<ItemName>.$id
Voce 3 - Sostituzione dell'ID endpoint SQL (notazione dinamica)
- find_value: "91280ad0-b76e-4c98-a656-95d8f09a5e28" # DEV SQL Endpoint GUID
replace_value:
test: $items.Lakehouse.DemoLakehouse.$sqlendpointid # Resolved dynamically at deploy time
prod: $items.Lakehouse.DemoLakehouse.$sqlendpointid # Resolved dynamically at deploy time
- Anziché impostare come hardcoding il GUID dell'endpoint SQL per ogni ambiente (ad esempio,
204fd20c-e34c-4bef-9dce-4ecf53b0e878per TEST o29bda5ec-ebc7-466e-a618-ef5bbea75e13per PROD), questa voce usa la notazione dinamica —$items.Lakehouse.DemoLakehouse.$sqlendpointid. - Il
fabric-cicdpacchetto risolve questo problema in fase di distribuzione cercando l'ID endpoint SQL diDemoLakehouseLakehouse nell'area di lavoro di destinazione. In questo modo si elimina la necessità di trovare e gestire manualmente i GUID degli endpoint SQL in ambienti diversi.
7.2 Riepilogo dei token dinamici
| Token di accesso | Risolve in |
|---|---|
$workspace.$id |
GUID dell'area di lavoro di destinazione |
$items.Lakehouse.<name>.$id |
Il GUID di una Lakehouse denominata <name> nell'area di lavoro di destinazione |
$items.<ItemType>.<ItemName>.$id |
Modello generico per qualsiasi tipo di elemento |
$items.Lakehouse.<name>.$sqlendpointid |
GUID dell'endpoint SQL di un Lakehouse (risolto in modo dinamico) |
7.3 File di parametri del ramo di funzionalità (avanzato)
Per i team che usano rami di funzionalità (non solo dev), è presente un file di parametri variant in cui tutti e tre gli ambienti (sviluppo, test, prod) hanno sostituzioni:
- find_value: "d34e3a2a-96ba-4461-9a80-496894ca4cda" # Feature branch Workspace ID
replace_value:
dev: " $workspace.$id"
test: " $workspace.$id"
prod: " $workspace.$id"
Ciò è utile quando gli sviluppatori lavorano nei loro spazi di lavoro di Fabric e hanno bisogno di sostituire i GUID anche durante la distribuzione in DEV.
8. Flusso di distribuzione: esame dettagliato completo
Ecco il flusso completo quando Alex vuole promuovere un Notebook da dev a test:
Passaggio 1: 🔧 Lo sviluppatore apporta modifiche in DEV
Alex modifica il IngestApiData notebook nell'area di lavoro DEV Fabric (ad esempio, aggiunge una nuova cella). L'integrazione Git di Fabric sincronizza questa modifica al dev ramo automaticamente (o tramite un commit manuale).
Passaggio 2: 📋 Creare una richiesta pull (test di sviluppo →)
Alex crea una richiesta pull in ADO:
-
Ramo di origine:
dev -
Ramo di destinazione:
test - Titolo: "Alzare di livello gli elementi del blocco appunti modificati da testare"
La PR contiene tutti gli elementi modificati che Alex desidera distribuire nell'ambiente TEST.
Passaggio 3: ✅ Approvazione PR e merge
Un revisore (o l'amministratore di Alex) esamina una pull request:
- Controlla le modifiche apportate ai file di definizione del notebook
- Approva la richiesta pull
-
Completa l'unione → Le modifiche sono ora presenti nel
testramo
Passaggio 4: 🚀 Attivazione automatica della pipeline
Il commit di merge nel ramo test attiva il fabric_cicd_pipeline perché:
- Il
testramo si trova nell'elenco delincludetrigger - Le modifiche si trovano all'interno del
fabric/percorso
La pipeline inizia l'esecuzione:
Pipeline Variable: target_env = "test"
Passaggio 5: ⏸️ Fase di approvazione
Poiché la pipeline usa environment: $(target_env) e target_env = test, ADO controlla l'ambiente di test per verificare la presenza di controlli di approvazione.
- La pipeline si sospende e invia una notifica ai responsabili dell'approvazione configurati.
- L'amministratore esamina e fa clic su Approva.
Passaggio 6: ⚡ Esecuzione di script
Dopo l'approvazione, la pipeline:
- ⚙️ Configura Python 3.12
-
📦 Installa
fabric-cicd - Eseguito
deploy-to-fabric.pycon:
- Credenziali SPN da Key Vault
--target_env test--items_in_scope ["Notebook","Lakehouse",...]
Lo script Python:
- 🔐 Autentica utilizzando l'SPN
-
🔍
testWorkspaceNameRisolve → cerca l'ID dell'area di lavoro -
📄 Carica
parameter.ymle applica sostituzioni GUID - 📤 Pubblica elementi nell'area di lavoro TEST
- 🧹 Pulisce gli elementi orfani
Passaggio 7: ✅ Distribuzione completata
Il notebook viene ora distribuito nell'area di lavoro TEST con:
- ✅ La cella appena aggiunta presente
-
✅ Tutti i GUID in
%%configuresostituiti con i valori dell'ambiente TEST
9. Convalida: conferma di una distribuzione riuscita
Al termine della pipeline, verificare che la distribuzione sia riuscita:
Controllare 1: Stato della pipeline
In ADO → Pipeline → Esecuzioni, verificare che l'esecuzione della pipeline sia ✅ Completata con successo per l'ambiente test.
Verifica 2: Contenuto del notebook nello spazio di lavoro TEST
Aprire il IngestApiData notebook nell'area di lavoro TEST Fabric e verificare:
È presente una nuova cella: La cella appena aggiunta sviluppata in DEV dovrebbe ora essere visualizzata nella versione TEST del notebook.
I GUID vengono sostituiti nella Cella 1: Nel
%%configurecomando (in genere nella Cella 1), verificare che:
| Tipo GUID | Dovrebbe apparire | Non dovrebbe essere visualizzato |
|---|---|---|
| ID spazio di lavoro | ID area di lavoro di test |
|
| DemoLakehouse ID | TEST Lakehouse ID |
|
| ID del punto finale SQL | TEST SQL Endpoint ID (risolto in modo dinamico) |
91280ad0-...) |
✅ Successo! La
%%configurecella punta ora a TEST lakehouses e il nuovo lavoro di sviluppo è stato promosso in modo pulito.
10. Risoluzione dei problemi e problemi comuni
| Problema | Motivo | Soluzione |
|---|---|---|
| La pipeline ha esito negativo con "Area di lavoro non trovata" | Il nome dell'area di lavoro nel gruppo di variabili non corrisponde a Fabric | Verificare testWorkspaceName nel fabric_cicd_group_non_sensitive gruppo di variabili |
| I GUID non vengono sostituiti |
parameter.yml non nella posizione prevista |
Verificare che il file si trova nella .deploy/ cartella insieme allo script o nella radice del repository |
Permission denied errori da Fabric API |
SPN non ha accesso all'area di lavoro | Aggiungere il nome SPN come Membro o Amministratore nell'area di lavoro Fabric di destinazione. |
| La pipeline non viene attivata durante il merge | Mancata corrispondenza del filtro del percorso | Verificare che gli elementi di Fabric si trovino all'interno della fabric/ directory nel repository |
ModuleNotFoundError: fabric_cicd |
Pacchetto non installato | Verificare che il pip install fabric-cicd passaggio sia presente e abbia esito positivo |
| Notifica di approvazione non ricevuta | Ambiente non configurato | Verificare che il nome dell'ambiente ADO corrisponda esattamente a target_env (distinzione tra maiuscole e minuscole inclusa) |
| GUID dell'endpoint SQL non sostituito | Notazione dinamica non configurata correttamente | Verificare che $items.Lakehouse.<name>.$sqlendpointid la sintassi sia corretta e che la lakehouse esista nell'area di lavoro di destinazione |
os.environ errore di chiave |
Gruppo di variabili non collegato alla pipeline | Autorizzare la pipeline ad accedere fabric_cicd_group_non_sensitive |
| Errori di feature flag per le scorciatoie |
fabric-cicd versione troppo vecchia |
Eseguire l'aggiornamento fabric-cicd alla versione più recente: pip install fabric-cicd --upgrade |
11. Riepilogo
Questa esercitazione ha illustrato un flusso di lavoro CI/CD di livello di produzione per Microsoft Fabric usando Azure DevOps:
| Componente | Cosa Abbiamo Configurato |
|---|---|
| Azure Key Vault | Archivia in modo sicuro le credenziali SPN (ID tenant, ID client, segreto) |
| Gruppi di variabili ADO | Un collegamento sensibile a Key Vault, un semplice (nomi di area di lavoro) |
| Ambienti ADO |
dev, test, prod con controlli di approvazione su test e prod |
| Rami Git |
dev (connesso a Fabric) test e prod (destinazioni di distribuzione) |
| Pipeline YAML | Trigger automatici nell'unione di rami, selezione di elementi con parametri |
| Python Script | Autentica tramite SPN, risolve l'area di lavoro, viene distribuita tramite fabric-cicd |
| File di parametri | Scambia GUID DEV con valori specifici dell'ambiente usando token dinamici |
Risultati principali
-
Solo il ramo
devè connesso a un'area di lavoro Fabric — i ramitesteprodfungono da record di distribuzione. -
fabric-cicdI file di parametri gestiscono automaticamente la sostituzione GUID usando token dinamici come$workspace.$ide$items.Lakehouse.<name>.id. - Gli ambienti ADO con approvazioni forniscono la governance: nessuna distribuzione in ambienti più elevati senza approvazione esplicita.
- L'autenticazione dell'entità servizio tramite Azure Key Vault garantisce che le credenziali non vengano mai esposte nel codice o nei log.
📚 Altre informazioni: