Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un notebook Microsoft Fabric è un elemento di codice primario per lo sviluppo di processi Apache Spark ed esperimenti di apprendimento automatico. È una superficie interattiva basata sul Web usata da scienziati dei dati e ingegneri dei dati per scrivere codice che sfrutta visualizzazioni avanzate e testo Markdown. Questo articolo illustra come sviluppare notebook con operazioni sulle celle di codice ed eseguirli.
Sviluppare computer portatili / taccuini
I notebook sono costituiti da celle, ovvero singoli blocchi di codice o testo che possono essere eseguiti in modo indipendente o come gruppo.
Offriamo una gamma ricca di operazioni per sviluppare notebook:
- Aggiungere una cella
- Impostare il linguaggio primario
- Usare più linguaggi
- IntelliSense di tipo IDE
- Frammenti di codice
- Trascina e rilascia per inserire frammenti
- Trascina e rilascia per inserire immagini
- Formattare la cella di testo con i pulsanti della barra degli strumenti
- Annulla/Ripeti operazione della cella
- Spostare una cella
- Eliminare una cella
- Comprimere l'input di una cella
- Comprimere l'output di una cella
- Sicurezza dell'uscita delle celle
- Bloccare o congelare una cella
- Contenuto del notebook
- Compressione del markdown
- Trova e sostituisci
- Modalità a schermo intero in una cella
Aggiungere una cella
Esistono diversi modi per aggiungere una nuova cella al notebook.
Passare con il mouse sullo spazio tra due celle e selezionare Codice o Markdown.
Usare combinazioni di tasti in modalità comando. Premere A per inserire una cella al di sopra della cella corrente. Premere B per inserire una cella sotto la cella corrente.
Impostare il linguaggio primario
I notebook Fabric attualmente supportano quattro linguaggi Apache Spark:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- SparkR
È possibile impostare il linguaggio primario per le nuove celle aggiunte dall'elenco a discesa nella barra dei comandi superiore.
Usare più linguaggi
È possibile usare più linguaggi in un notebook specificando il comando magico del linguaggio all'inizio della cella. È anche possibile cambiare la lingua della cella dal selettore della lingua. Nella tabella seguente sono elencati i comandi magici per passare da una lingua all'altra delle celle.

| Comando magico | Lingua | Descrizione |
|---|---|---|
| %%pyspark | Pitone | Eseguire una query Python contro il contesto Apache Spark. |
| %%spark | Linguaggio di programmazione Scala | Esegui una query Scala sul contesto di Apache Spark. |
| %%sql | SparkSQL | Esegui una query SparkSQL sul Context di Apache Spark. |
| %%html | HTML | Eseguire n query HTML sul context di Apache Spark. |
| %%sparkr | R | Eseguire una query R nell'ambito del contesto Apache Spark. |
IntelliSense di tipo IDE
I notebook Fabric sono integrati nell'editor Monaco e consentono di aggiungere la funzionalità IntelliSense di tipo IDE all'editor di celle. L'evidenziazione della sintassi, il generatore di errori e i completamenti automatici del codice consentono di scrivere codice e identificare i problemi rapidamente.
Le funzionalità di IntelliSense hanno livelli di maturità diversi per i diversi linguaggi. La tabella seguente mostra le funzionalità supportate da Fabric:
| Lingue | Evidenziazione della sintassi | Generatore di errori di sintassi | Completamento del codice della sintassi | Completamento del codice della variabile | Completamento del codice della funzione di sistema | Completamento del codice della funzione utente | Indentazione intelligente | Piegatura del codice |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| Pitone | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| Spark (Scala) | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| SparkSQL | Sì | Sì | Sì | Sì | Sì | NO | Sì | Sì |
| SparkR | Sì | Sì | Sì | Sì | Sì | Sì | Sì | Sì |
| T-SQL | Sì | Sì | Sì | NO | Sì | Sì | Sì | Sì |
Nota
Per usare il completamento del codice IntelliSense, è necessario disporre di una sessione Apache Spark attiva.
Migliorare lo sviluppo Python con Pylance
Pylance, un server di linguaggio avanzato e ricco di funzionalità, è ora disponibile nel notebook di Fabric. Pylance semplifica lo sviluppo di Python con completamenti intelligenti, un rilevamento degli errori migliore e informazioni dettagliate sul codice migliorate. I miglioramenti principali includono un completamento automatico più intelligente, un supporto avanzato per le lambda, suggerimenti dei parametri migliorati, migliori informazioni al passaggio del mouse, un rendering migliorato delle docstring e un'evidenziazione degli errori. Con Pylance, la scrittura di codice Python e PySpark diventa più veloce, più accurata e più efficiente.
Frammenti di codice
I notebook di Fabric forniscono frammenti di codice che consentono di scrivere facilmente modelli di codice usati comunemente, come:
- Leggere i dati come un DataFrame di Apache Spark
- Disegno di grafici con Matplotlib
I frammenti di codice appaiono nei tasti di scelta rapida dello stile IntelliSense IDE insieme ad altri suggerimenti. Il contenuto del frammento di codice è allineato alla lingua della cella del codice. È possibile visualizzare frammenti di codice disponibili digitando Snippet. È anche possibile digitare qualsiasi parola chiave per visualizzare un elenco di frammenti di codice pertinenti. Ad esempio, se si digita leggi si visualizza l'elenco dei frammenti di codice per leggere i dati da varie origini dati.

Trascina e rilascia per inserire elementi
Usare trascina e rilascia per leggere comodamente i dati da Lakehouse explorer. Qui sono supportati più tipi di file; è possibile operare su file di testo, tabelle, immagini e così via. È possibile passare a una cella esistente o a una nuova cella. Il notebook genera il frammento di codice di conseguenza per visualizzare in anteprima i dati.

Trascina e rilascia per inserire immagini
Usa trascina e rilascia per inserire facilmente immagini dal tuo browser o computer locale in una cella di markdown.

Formattare la cella di testo con i pulsanti della barra degli strumenti
Per completare le azioni di markdown comuni, è possibile usare i pulsanti di formato nella barra degli strumenti delle celle di testo.

Annullare o ripetere le operazioni delle celle
Seleziona Annulla o Rifai, o premi Z o Shift+Z per annullare le operazioni di cella più recenti. È possibile annullare o ripetere fino a 10 delle ultime operazioni recenti sulle celle.

Operazioni di annullamento delle celle supportate:
- Inserire o eliminare una cella. È possibile revocare le operazioni eliminate selezionando Annulla (il contenuto di testo viene mantenuto insieme alla cella).
- Riorganizza cella.
- Cambia parametro.
- Converti tra cella codice e cella Markdown.
Nota
Le operazioni di testo all'interno delle celle e le operazioni di commento delle celle di codice non possono essere annullate. È possibile annullare o ripetere fino a 10 delle ultime operazioni recenti sulle celle.
Sposta una cella
È possibile trascinarle dalla parte vuota di una cella e rilasciarle nella posizione desiderata.
È anche possibile spostare la cella selezionata usando Sposta su e Sposta giù sulla barra multifunzione.

Eliminare una cella
Per eliminare una cella, selezionare il pulsante Elimina a destra della cella.
È anche possibile usare combinazioni di tasti in modalità comando. Premere D,D (D due volte) per eliminare la cella corrente.
Riduci l'input di una cella
Selezionare l'ellisse Altri comandi (...) nella barra degli strumenti della cella e Nascondi input per nascondere l'input della cella corrente. Per espanderlo di nuovo, selezionare Mostra input quando la cella è compressa.
Ridurre l'output di una cella
Selezionare le ellissi Altri comandi (...) sulla barra degli strumenti della cella e Nascondi output per nascondere l'output della cella corrente. Per espanderlo di nuovo, selezionare Mostra output quando l'output della cella è compresso.
Sicurezza dell'uscita della cella
È possibile usare i ruoli di accesso ai dati di OneLake (anteprima) per configurare l'accesso solo a cartelle specifiche in un lakehouse durante le query del notebook. Gli utenti senza accesso a una cartella o a una tabella visualizzano un errore non autorizzato durante l'esecuzione della query.
Importante
La sicurezza si applica solo durante l'esecuzione delle query. Le celle del notebook che contengono i risultati delle query possono essere visualizzate dagli utenti che non sono autorizzati a eseguire direttamente query sui dati.
Bloccare una cella
Le operazioni di blocco e congelamento delle celle consentono di rendere le celle di sola lettura o di impedire l'esecuzione delle celle di codice su base individuale.

Unire e separare le celle
È possibile usare Unisci con la cella precedente o Unisci con la cella successiva per unire le celle correlate in modo pratico.
La selezione di Dividi cella consente di dividere le istruzioni irrilevanti in più celle. L'operazione divide il codice in base alla posizione della riga del cursore.

Contenuto del notebook
Selezionando Strutture o Sommario, viene mostrata la prima intestazione markdown di qualsiasi cella markdown in una finestra della barra laterale per una navigazione rapida. La barra laterale Strutture è ridimensionabile e comprimibile, in modo da adattarsi allo schermo nel miglior modo possibile. Selezionare il pulsante Sommario nella barra dei comandi del notebook per aprire o nascondere la barra laterale.

Compressione del markdown
L'opzione di compressione markdown consente di nascondere le celle sotto una cella markdown che contiene un'intestazione. La cella markdown e le relative celle nascoste vengono trattate allo stesso modo di un insieme di celle multi-selezionate contigue durante l'esecuzione di operazioni sulle celle.

Trova e sostituisci
L'opzione trova e sostituisci è uno strumento che aiuta a abbinare e individuare le parole chiave o le espressioni all'interno del contenuto del notebook. È anche possibile sostituire facilmente la stringa di destinazione con una nuova stringa.

Modalità schermo intero in una cella
La modalità full-size consente di concentrarsi completamente sulla scrittura e la modifica del codice all'interno di una singola cella, perfetta per una logica lunga o complessa. È possibile attivare o disattivare questa modalità facendo clic sul pulsante espandi cella nella barra degli strumenti delle celle per espandere la cella e uscire facendo clic su Torna alle dimensioni predefinite.

Completamento del codice inline di Copilot (anteprima)
Il completamento del codice inline di Copilot è una funzionalità basata sull'intelligenza artificiale che consente di scrivere codice Python più velocemente ed in modo più efficiente nei notebook di Fabric. Questa funzionalità fornisce suggerimenti intelligenti e in grado di supportare il contesto durante la digitazione del codice. Riduce le attività ripetitive, riduce al minimo gli errori di sintassi e accelera lo sviluppo integrando facilmente nel flusso di lavoro del notebook.
Vantaggi principali
- Completamenti basati sull'intelligenza artificiale: Genera suggerimenti in base al contesto del notebook usando un modello sottoposto a training su milioni di righe di codice.
- Aumenta la produttività: Consente di scrivere funzioni complesse, ridurre la codifica ripetitiva e velocizzare l'esplorazione di librerie non note.
- Riduce gli errori: Riduce al minimo gli errori di digitazione e di sintassi con completamenti intelligenti e con riconoscimento del contesto.
- Configurazione minima: Integrata nei notebook Fabric e non richiede alcuna installazione. È sufficiente abilitarlo e iniziare a scrivere codice.
Come funziona
Abilitare i suggerimenti di codice inline usando l'opzione nella parte inferiore del notebook.

Durante la digitazione, i suggerimenti vengono visualizzati in testo grigio chiaro, premere TAB per accettare o modificare. I suggerimenti sono basati sulle celle precedenti del notebook.

Nota
L'abilitazione del completamento del codice inline di Copilot utilizza più unità di capacità.
Limitazioni correnti
- Attualmente, il completamento del codice inline di Copilot supporta il linguaggio Python e utilizza il contesto delle celle precedenti e degli schemi Lakehouse.
- I suggerimenti prendono in considerazione i dati degli schemi Lakehouse.
- Quando sono presenti molte tabelle o colonne, viene usato solo un subset di elementi dello schema.
- Le tabelle create dinamicamente (tramite Spark) non vengono riconosciute in tempo reale.
- I completamenti in linea sono principalmente limitati al contesto delle celle precedenti e agli schemi di Lakehouse. Le azioni copilot a livello di notebook e la diagnostica descritte nelle sezioni seguenti possono usare un contesto notebook più ampio (struttura e stato di runtime) senza richiedere l'avvio di una sessione Spark.
Azioni a livello di notebook Copilot
Copilot supporta funzionalità a livello di notebook in più passaggi che vanno oltre le singole celle. È possibile usare Copilot per generare codice tra celle, eseguire il refactoring della logica in funzioni riutilizzabili, riepilogare interi flussi di lavoro e convalidare l'output del notebook. Copilot comprende il contesto dell'area di lavoro, gli schemi lakehouse collegati, le tabelle e i file, la struttura del notebook e lo stato di runtime ed è immediatamente compatibile con il contesto senza richiedere l'avvio di una sessione Spark.
Per informazioni dettagliate sul riquadro della chat e sui comandi slash, vedere Usare il riquadro della chat di Copilot.
Informazioni dettagliate sulle prestazioni con Copilot
Copilot visualizza le raccomandazioni di ottimizzazione in base alle dimensioni dei dati, ai modelli di join e al comportamento di runtime. Ad esempio, può proporre strategie di join efficienti, aiutare a evitare le sequenze casuali dei dati, individuare i problemi di qualità dei dati e suggerire refactoring per migliorare il riutilizzo e la manutenibilità. Queste informazioni dettagliate vengono visualizzate nelle conversazioni di Copilot e allineate al /optimize comando.
Correzione con Copilot
Quando si verifica un errore di una cella o di un processo Spark, viene visualizzata un'opzione Correzione con Copilot sotto la cella non riuscita. Copilot fornisce un riepilogo degli errori, la probabile causa principale, le correzioni consigliate e la possibilità di applicare automaticamente le modifiche con una differenza di approvazione. È anche possibile usare il /fix comando nella chat di Copilot per eseguire la diagnostica mirata in una cella specifica o nell'intero notebook.
Per altre informazioni, vedere Diagnosticare gli errori dei notebook con Copilot.
Eseguire i notebook
È possibile eseguire le celle di codice nel notebook singolarmente o tutte insieme. Lo stato e l'avanzamento di ogni cella sono visualizzati nel notebook.
Esegui una cella
Esistono diversi modi per eseguire il codice in una cella.
Passare con il puntatore del mouse sulla cella che si desidera eseguire e selezionare il pulsante Esegui cella oppure premere CTRL + INVIO.
Usare combinazioni di tasti in modalità comando. Premere Maiusc+Invio per eseguire la cella corrente e selezionare la cella successiva. Premere Alt+Invio per eseguire la cella attiva e inserire una nuova cella.
Esegui tutte le celle
Selezionare il pulsante Esegui tutte per eseguire tutte le celle del notebook corrente in sequenza.
esegui tutte le celle sopra o sotto
Espandere l'elenco a discesa dal pulsante Esegui tutto, quindi selezionare Esegui celle sopra per eseguire tutte le celle sopra la sequenza corrente. Selezionare Esegui celle sotto per eseguire la cella corrente e tutte le celle sotto di essa in sequenza.

Annulla tutte le celle in esecuzione
Seleziona Annulla tutto per interrompere le celle che sono in esecuzione o quelle che attendono in coda.
Termina sessione
Arresta sessione annulla le celle in attesa e in esecuzione e arresta la sessione corrente. È possibile riavviare una nuova sessione selezionando nuovamente l'opzione Esegui.

Test di riferimento
Esecuzione di un Notebook di riferimento
Oltre al riferimento all'API di esecuzione notebookutils, è anche possibile utilizzare il comando magico %run <notebook name> per fare riferimento a un altro notebook nel contesto del notebook attuale. Tutte le variabili definite nel notebook di riferimento sono disponibili nel notebook corrente. Il comando magic %run supporta le chiamate annidate, ma non quelle ricorsive. Viene generata un'eccezione se la profondità dell'istruzione è maggiore di cinque.
Esempio: %run Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
La guida di riferimento del notebook funziona sia in modalità interattiva che in pipeline.
Nota
- Il comando
%runsupporta attualmente solo notebook di riferimento nella stessa area di lavoro con il notebook corrente. - Il comando
%runsupporta attualmente solo fino a quattro tipi di valore di parametro:int,float,boolestring. L'operazione di sostituzione delle variabili non è supportata. - Il comando
%runnon supporta un riferimento annidato con una profondità maggiore di cinque.
Esecuzione di uno script di riferimento
Il comando %run consente anche di eseguire file Python o SQL archiviati nelle risorse predefinite del notebook, in modo da eseguire facilmente i file di codice sorgente nel notebook.
%run [-b/--builtin -c/--current] [script_file.py/.sql] [variables ...]
Per le opzioni:
- -b/-builtin: Questa opzione indica che il comando trova ed esegue il file di script specificato dalle risorse integrate del notebook.
- -c/--current: questa opzione garantisce che il comando usi sempre le risorse predefinite del notebook corrente, anche se il notebook corrente fa riferimento ad altri notebook.
Esempi:
Per eseguire script_file.py dalle risorse predefinite:
%run -b script_file.pyPer eseguire script_file.sql dalle risorse predefinite:
%run -b script_file.sqlPer eseguire script_file.py dalle risorse predefinite con variabili specifiche:
%run -b script_file.py { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Nota
Se il comando non contiene -b/-builtin, tenta di trovare ed eseguire l'elemento del notebook all'interno della stessa area di lavoro anziché le risorse predefinite.
Esempio di utilizzo per il caso di esecuzione annidata:
- Si supponga di avere due notebook.
- Notebook1: contiene script_file1.py nelle risorse predefinite
- Notebook2: contiene script_file2.py nelle risorse predefinite
- Usiamo Notebook1 come notebook principale con il contenuto:
%run Notebook2. - Poi, in Notebook2 l'istruzione di utilizzo sono:
- Per eseguire script_file1.py in Notebook1(notebook principale), il codice è:
%run -b script_file1.py - Per eseguire script_file2.py in Notebook2(notebook corrente), il codice sarà:
%run -b -c script_file2.py
- Per eseguire script_file1.py in Notebook1(notebook principale), il codice è:
Esploratore di variabili
I notebook di Fabric comprendono un'opzione predefinita Esplora variabili che consente di visualizzare l'elenco con il nome, il tipo, la lunghezza e il valore delle variabili nella sessione corrente di Spark per le celle PySpark (Python). Altre variabili vengono visualizzate automaticamente man mano che vengono definite nelle celle di codice. Facendo clic su ciascuna intestazione di colonna, le variabili nella tabella vengono ordinate.
Per aprire o nascondere l'Esploratore variabili, selezionare Variabili sulla barra degli strumenti del notebook Visualizza.

Nota
L'esploratore di variabili supporta solo Python.
Indicatore di stato delle celle
Sotto la cella viene visualizzato il relativo stato di esecuzione dettagliato, che indica lo stato di avanzamento corrente. Al termine dell'esecuzione della cella, viene visualizzato un riepilogo con la durata totale e l'ora di fine, che viene conservato per riferimento futuro.

Indicatore di stato sessione
Configurazione del timeout della sessione
Nell'angolo inferiore sinistro è possibile selezionare lo stato della sessione per ottenere altre informazioni sulla sessione corrente:

Nella finestra popup è disponibile un'opzione per reimpostare il timeout su x minuti o ore.

Scegli per quanto tempo vuoi una sessione ininterrotta e premi applica. Il timeout della sessione viene reimpostato con il nuovo valore e sei pronto per procedere.
È anche possibile impostare il timeout come descritto in:
- Impostazioni di amministrazione dell'area di lavoro Progettazione dati in Microsoft Fabric
- Comando magico di configurazione della sessione Spark
Rimanere connessi: Durante l'accesso, se viene visualizzata la finestra di dialogo Mantieni l'accesso, selezionare Sì per disattivare il timeout della sessione inattiva per la sessione corrente.
Importante
Non selezionare la casella di controllo Non visualizzare più questa opzione, perché verrà bloccata in modo permanente nelle impostazioni di accesso. Questa opzione potrebbe non essere visualizzata se l'amministratore del tenant ha disabilitato l'impostazione Mantieni l'accesso (KMSI).
Richiedere una modifica dei criteri: Se è necessaria una durata di sessione più lunga, chiedere all'amministratore del tenant di estendere i criteri di durata del timeout della sessione inattiva. A tale scopo, passare a Impostazioni > organizzazione Security &Privacy > Idle Session Timeout all'interno dell'interfaccia di amministrazione di Microsoft 365.
Nota
Se si seleziona KMSI e/o si estende il tempo di timeout della sessione inattiva, aumenta il rischio di accesso a un computer sbloccato.
In che modo ABT e il timeout della sessione inattiva influiscono sulle esecuzioni prolungate dei notebook di Fabric?
Se il tenant utilizza il timeout basato sull'attività (ABT), i processi interattivi di lunga durata nei notebook di Fabric potrebbero essere influenzati dalla politica di timeout della sessione inattiva di Microsoft 365. Questa funzionalità di sicurezza è progettata per disconnettere gli utenti dai dispositivi inattivi e non gestiti, anche se un processo notebook è ancora in esecuzione. Mentre l'attività in altre app di Microsoft 365 può mantenere attiva la sessione, i dispositivi inattivi vengono disconnessi per impostazione predefinita.
Perché gli utenti si disconnessono anche quando un processo del notebook è ancora in esecuzione?
Il timeout delle sessioni inattive dà priorità alla sicurezza terminando automaticamente le sessioni sui dispositivi inattivi per impedire l'accesso non autorizzato. Anche quando è in corso un'esecuzione del notebook, la sessione termina se il dispositivo non mostra alcuna attività. Mantenere aperte le sessioni nei dispositivi inattive comprometterebbe la sicurezza, motivo per cui viene applicato il comportamento corrente.
Indicatore del lavoro Apache Spark in linea
I notebook di Fabric sono basati su Apache Spark. Le celle di codice vengono eseguite nel cluster di Apache Spark in remoto. Viene fornito un indicatore di stato del processo Spark con una barra di avanzamento in tempo reale che consente di comprendere lo stato di esecuzione del processo. Il numero di attività per ogni processo o fase consente di identificare il livello parallelo del processo Spark. È anche possibile eseguire un'analisi più approfondita dell'interfaccia utente Spark di uno specifico processo (o fase) selezionando il collegamento al nome del processo (o della fase).
È anche possibile trovare il log in tempo reale a livello di cella accanto all'indicatore di stato e la Diagnostica può fornire suggerimenti utili per perfezionare ed eseguire il debug del codice. Quando richiesto, Copilot può usare le informazioni sui processi in fase di esecuzione per evidenziare raccomandazioni sulle prestazioni e sull'affidabilità. Se un processo o una cella non riesce, il punto di ingresso Correzione con Copilot è disponibile per diagnosticare e risolvere il problema.

In Altre azioni, è possibile passare facilmente alla pagina dei dettagli dell'applicazione Spark e alla pagina dell'interfaccia utente Web Spark.

Redazione segreta
Per evitare che le credenziali vengano accidentalmente divulgate durante l'esecuzione dei notebook, i notebook di Fabric supportano l'offuscamento dei segreti per nascondere i valori segreti visualizzati nell'output della cella con [REDACTED]. La redazione dei segreti è applicabile per Python, Scala e R.

Comandi magici in un notebook
Comandi magici integrati
È possibile usare i comandi magic di IPython noti nei notebook di Fabric. Esaminare l'elenco seguente di comandi magici attualmente disponibili.
Nota
Questi sono gli unici comandi magic supportati nella pipeline di Fabric: %%pyspark, %%spark, %%csharp, %%sql, %%configure.
Comandi magici di linea disponibili: %lsmagic, %time, %timeit, %history, %run, %load, %alias, %alias_magic, %autoawait, %autocall, %automagic, %bookmark, %cd, %colors, %dhist, %dirs, %doctest_mode, %killbgscripts, %load_ext, %logoff, %logon, %logstart, %logstate, %logstop, %magic, %matplotlib, %page, %pastebin, %pdef, %pfile, %pinfo, %pinfo2, %popd, %pprint, %precision, %prun, %psearch, %psource, %pushd, %pwd, %pycat, %quickref, %rehashx, %reload_ext, %reset, %reset_selective, %sx, %system, %tb, %unalias, %unload_ext, %who, %who_ls, %whos, %xdel, %xmode.
Il notebook di Fabric supporta anche i comandi di gestione delle librerie migliorati %pip e %conda. Per altre informazioni sull'utilizzo, vedere Gestire le librerie Apache Spark in Microsoft Fabric.
Comandi magici delle celle disponibili: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%configure, %%html, %%bash, %%markdown, %%perl, %%script, %%sh.
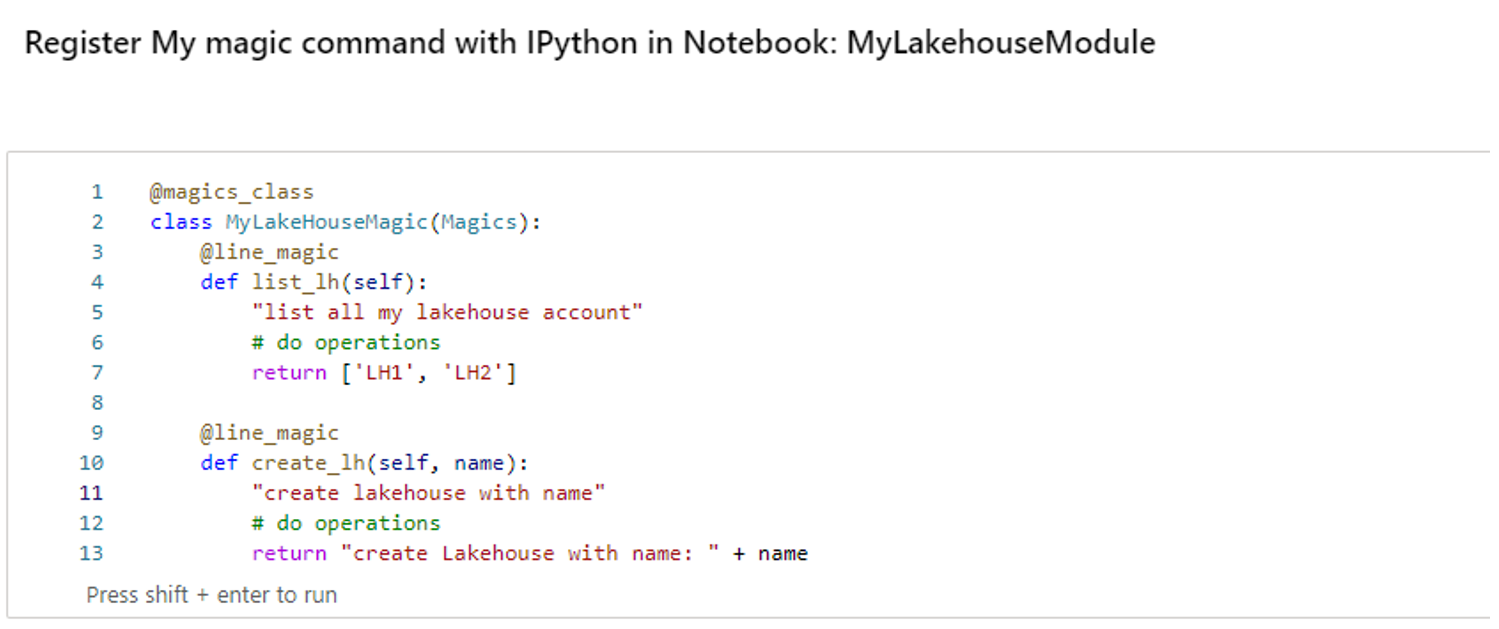
Comandi magici personalizzati
È anche possibile creare comandi magic più personalizzati per soddisfare esigenze specifiche. Ecco un esempio:
Creare un notebook con il nome "MyLakehouseModule".
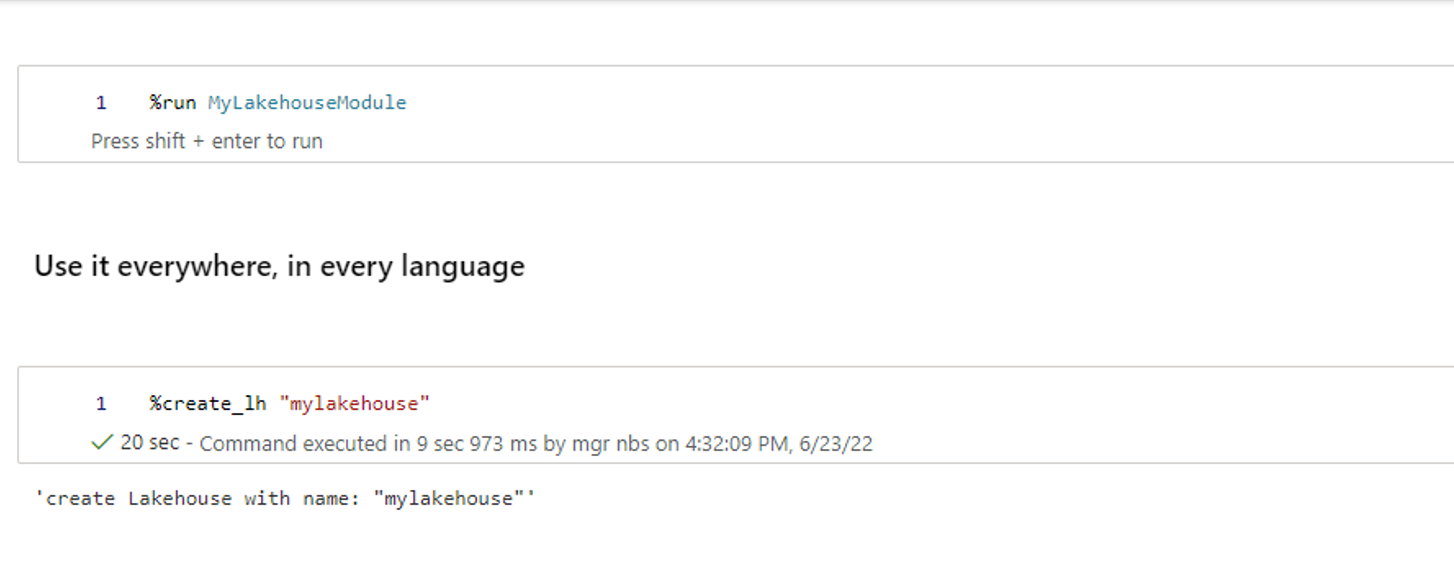
In un altro notebook, fare riferimento a "MyLakehouseModule" e ai relativi comandi magici. Questo processo consente di organizzare facilmente il progetto con notebook che usano linguaggi diversi.


IPython Widget
IPython Widgets sono oggetti Python con evento che hanno una rappresentazione nel browser. È possibile usare i widget IPython come controlli a basso codice (ad esempio, dispositivo di scorrimento o casella di testo) nel notebook, proprio come il Jupyter Notebook. Attualmente funziona solo in un contesto Python.
Per usare i widget IPython
Prima di usare il framework Widget Jupyter, importare il modulo ipywidgets.
import ipywidgets as widgetsUsare la funzione visualizza di primo livello per eseguire il rendering di un widget o lasciare un'espressione di tipo widget nell'ultima cella della riga di codice.
slider = widgets.IntSlider() display(slider)Esegui la cella. Il widget viene visualizzato nell'area di output.
slider = widgets.IntSlider() display(slider)
Usare più chiamate display() per eseguire più volte il rendering della stessa istanza del widget. Rimangono sincronizzati tra loro.
slider = widgets.IntSlider() display(slider) display(slider)
Per eseguire il rendering di due widget indipendenti l'uno dall'altro, creare due istanze del widget:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)



Widget supportati
| Tipo di widget | Widget |
|---|---|
| Widget numerici | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Elementi booleani | Pulsante di commutazione, Casella di controllo, Valido |
| Widget di selezione | Dropdown, RadioButton, Seleziona, Cursore di Selezione, Cursore di Intervallo di Selezione, Pulsanti Toggle, Seleziona Multiplo |
| Widget di stringa | Testo, Area di testo, Casella combinata, Password, Etichetta, HTML, HTML Matematica, Immagine, Pulsante |
| Widget per la riproduzione delle animazioni | Selezione data, Selezione colori, Controller |
| Widget di contenitore o layout | Box, HBox, VBox, GridBox, Accordion, Tabulazioni, Impilato |
Limitazioni note
I widget seguenti non sono ancora supportati. Sono disponibili le seguenti soluzioni alternative:
Funzionalità Soluzione alternativa Widget di risultato È invece possibile usare la funzione print() per scrivere testo in stdout. widgets.jslink() È possibile usare la funzione widgets.link() per collegare due widget simili. Widget FileUpload Non ancora supportato. La funzione display globale di Fabric non supporta la visualizzazione di più widget in una chiamata ( ad esempio, display(a, b)). Questo comportamento è diverso dalla funzione display di IPython.
Se si chiude un notebook che contiene un widget IPython, non sarà possibile vedere o interagire con esso fino a quando non si esegue di nuovo la cella corrispondente.
La funzione interact (ipywidgets.interact) non è supportata.
Integrare un portatile
Designare una cella di parametri
Per parametrizzare il notebook, selezionare i puntini di sospensione (...) per accedere ai comandi Altro nella barra degli strumenti della cella. Selezionare quindi Attiva/Disattiva la cella di parametri per designare la cella come cella di parametri.

La cella di parametro è utile per integrare un notebook in una pipeline. L'attività della pipeline cerca la cella di parametri e tratta questa cella come valore predefinito per i parametri passati in fase di esecuzione. Il motore di esecuzione aggiunge una nuova cella sotto la cella dei parametri con parametri di input per sovrascrivere i valori predefiniti.
Assegnare i valori dei parametri di una pipeline
Dopo aver creato un notebook con parametri, è possibile eseguirlo da una pipeline con l'attività del notebook di Fabric. Dopo aver aggiunto l'attività all'area di lavoro della pipeline, è possibile impostare i valori dei parametri nella sezione Parametri di base della scheda Impostazioni.

Quando si assegnano i valori dei parametri, è possibile usare il linguaggio delle espressioni della pipeline o le funzioni e variabili.
I parametri del notebook supportano tipi semplici come int, float, bool e string. Tipi complessi come list e dict non sono ancora supportati. Per passare un tipo complesso, valutare la possibilità di serializzarlo in un formato stringa (ad esempio JSON) e quindi deserializzarlo all'interno del notebook. L'esempio seguente illustra come passare una stringa JSON dalla pipeline al notebook e deserializzarla:

Il codice Python seguente illustra come deserializzare la stringa JSON in un dizionario Python:
import json
# Deserialize the JSON string into a Python dictionary
params = json.loads(json_string)
# Access the individual parameters
param1 = params.get("param1")
param2 = params.get("param2")
Assicurarsi che il nome del parametro nella cella del codice del parametro corrisponda al nome del parametro nella pipeline.
Comando magico di configurazione della sessione Spark
È possibile personalizzare la sessione di Spark con il comando magic %%configure. Il notebook di Fabric supporta vCores personalizzati, la memoria del driver e dell'executor, le proprietà di Apache Spark, i punti di montaggio, i pool e il lakehouse predefinito della sessione del notebook. Possono essere usati sia nelle attività dei notebook interattivi che dei notebook pipeline. È consigliabile eseguire il comando %%configure all'inizio del notebook, oppure riavviare la sessione Spark per rendere effettive le impostazioni.
%%configure
{
// You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory": "28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g"]
"driverCores": 4, // Recommended values: [4, 8, 16, 32, 64]
"executorMemory": "28g",
"executorCores": 4,
"jars": ["abfs[s]: //<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar", "wasb[s]: //<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":
{
// Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows": "3000",
"spark.log.level": "ALL"
},
"defaultLakehouse": { // This overwrites the default lakehouse for current session
"name": "<lakehouse-name>",
"id": "<(optional) lakehouse-id>",
"workspaceId": "<(optional) workspace-id-that-contains-the-lakehouse>" // Add workspace ID if it's from another workspace
},
"mountPoints": [
{
"mountPoint": "/myMountPoint",
"source": "abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>"
},
{
"mountPoint": "/myMountPoint1",
"source": "abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path1>"
},
],
"environment": {
"id": "<environment-id>",
"name": "<environment-name>"
},
"sessionTimeoutInSeconds": 1200,
"useStarterPool": false, // Set to true to force using starter pool
"useWorkspacePool": "<workspace-pool-name>"
}
Nota
- È consigliabile impostare lo stesso valore per "DriverMemory" ed "ExecutorMemory" in %%configure. Anche i valori "driverCores" ed "executorCores" devono essere uguali.
- Il "defaultLakehouse" sovrascriverà il lakehouse bloccato in Lakehouse Explorer, ma ciò funziona solo nella sessione del notebook corrente.
- È possibile usare %%configure nelle pipeline di Fabric, ma se non è impostata nella prima cella di codice, l'esecuzione della pipeline non riesce a causa del mancato riavvio della sessione.
- Il %%configure usato in notebookutils.notebook.run viene ignorato, ma quando utilizzato in il %run, il notebook continua ad eseguire.
- Le proprietà di configurazione Spark standard devono essere usate nel corpo "conf". Fabric non supporta i riferimenti di primo livello per le proprietà di configurazione di Spark.
- Alcune proprietà speciali di Spark, tra cui "spark.driver.cores", "spark.executor.cores", "spark.driver.memory", "spark.executor.memory" e "spark.executor.instances", non hanno effetto nel corpo "conf".
È anche possibile usare il %%configure comando magic per inserire in modo dinamico i valori di configurazione dalla libreria di variabili nel notebook.
%%configure
{
"defaultLakehouse": {
"name": {
"variableName": "$(/**/myVL/LHname)"
},
"id": {
"variableName": "$(/**/myVL/LHid)"
},
"workspaceId": {
"variableName": "$(/**/myVL/WorkspaceId)"
}
}
}
In questo esempio:
-
myVLè il nome della libreria di variabili. -
LHname,LHideWorkspaceIdsono chiavi variabili definite nella libreria. - Tutte le variabili devono essere definite come tipo String nella libreria di variabili, anche per i valori GUID.
- È
workspaceIdobbligatorio quando il lakehouse si trova in un'area di lavoro diversa rispetto al notebook corrente. - Questi valori vengono risolti in fase di esecuzione a seconda dell'ambiente attivo, ad esempio Sviluppo, Test, Prod.
In questo modo è possibile cambiare configurazione, ad esempio la lakehouse predefinita senza modificare il codice del notebook.
Configurazione della sessione con parametri da una pipeline
La configurazione della sessione parametrizzata consente di sostituire il valore in %%configure magic con i parametri di esecuzione dell'attività del notebook della pipeline. Quando si prepara la cella di codice %%configure, è possibile eseguire l'override dei valori predefiniti (configurabili anche, 4 e "2000" nell'esempio seguente) con un oggetto simile al seguente:
{
"parameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"parameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"parameterName": "rows",
"defaultValue": "2000"
}
}
}
Un notebook utilizza il valore predefinito se si esegue un notebook direttamente in modalità interattiva o se l'attività del notebook della pipeline non fornisce alcun parametro che corrisponde a "activityParameterName".
Durante l'esecuzione di una pipeline, è possibile configurare le impostazioni dell'attività del notebook della pipeline come indicato di seguito.

Se si desidera modificare la configurazione della sessione, il nome dei parametri dell'attività del notebook della pipeline deve essere lo stesso di parameterName nel notebook. In questo esempio di esecuzione di una pipeline, driverCores in %%configure vengono sostituiti da 8 e livy.rsc.sql.num-rows vengono sostituiti da 4000.
Nota
- Se un'esecuzione della pipeline ha esito negativo perché è stato usato il comando magic %%configure, è possibile trovare maggiori informazioni sull'errore eseguendo la cella magic %%configure nella modalità interattiva del notebook.
- Le esecuzioni pianificate del notebook non supportano la configurazione della sessione con parametri.
Gestione dei log di Python in un notebook
È possibile trovare i log Python e impostare livelli di log e formato differenti seguendo il codice di esempio qui di seguito:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Visualizzare la cronologia dei comandi di input
Il notebook di Fabric supporta il comando magic %history per stampare la cronologia dei comandi di input eseguita nella sessione corrente. Rispetto al comando Jupyter Ipython standard, %history è compatibile con più contesti di lingua nel notebook.
%history [-n] [range [range ...]]
Per le opzioni:
- -n: Stampa il numero di esecuzione.
Dove l'intervallo può essere:
- N: Stampa il codice della N-esima cella eseguita.
- M-N: codice di stampa dalla Mth alla Nth cella eseguita.
Esempio:
- Stampa la cronologia degli input dalla prima alla seconda cella eseguita:
%history -n 1-2
Tasti di scelta rapida
Analogamente a Jupyter Notebook, i notebook di Fabric hanno un'interfaccia utente modale. La tastiera esegue diverse operazioni a seconda della modalità in cui si trova la cella del notebook. I notebook di Fabric supportano le due modalità seguenti per una cella di codice specificata, ovvero la modalità di comando e la modalità di modifica.
Una cella è in modalità di comando quando non è presente un cursore di testo che richiede di digitare. Quando una cella è in modalità di comando, è possibile modificare il notebook nel suo complesso, ma non digitare in singole celle. Immettere la modalità comando premendo ESC o usando il mouse per selezionare un punto all'esterno dell'area dell'editor di una cella.

La modalità di modifica può essere indicata da un cursore di testo che richiede di digitare nell'area dell'editor. Quando una cella si trova in modalità di modifica, è possibile digitare nella cella. Per passare alla modalità di modifica, premere Invio o usare il mouse per selezionare l'area dell'editor di una cella.



Scorciatoie da tastiera in modalità di comando
| Azione | Scorciatoie da tastiera per notebook |
|---|---|
| Eseguire la cella attuale e selezionare di seguito | MAIUSC+INVIO |
| Esegui la cella corrente e inserisci sotto | alt+invio |
| Esegui la cella attuale | Ctrl+Invio |
| Selezionare la cella in alto | Attivo |
| Selezionare la cella in basso | Giù |
| Seleziona la cella precedente | Okay |
| Seleziona la cella successiva | J |
| Inserisci cella sopra | Un |
| Inserire la cella in basso | B |
| Elimina le celle selezionate | D, D |
| Passare alla modalità di modifica | Entrare |
Tasti di scelta rapida in modalità di modifica
Usando i tasti di scelta rapida seguenti, è possibile esplorare ed eseguire facilmente il codice nei notebook di Fabric in modalità di modifica.
| Azione | Scorciatoie da tastiera per notebook |
|---|---|
| Sposta il cursore verso l'alto | Attivo |
| Sposta il cursore verso il basso | Giù |
| Annulla | CTRL + Z |
| Rifare | CTRL + Y |
| Inserimento o rimozione di commenti | CTRL+ / Commentare: CTRL + K + C Rimuovere il commento: CTRL + K + U |
| Cancella la parola prima | CTRL + BACKSPACE |
| Elimina parola dopo | CTRL+CANC |
| Vai all'inizio della cella | CTRL + Home |
| Vai alla fine della cella | Ctrl + Fine |
| Vai una parola a sinistra | CTRL + Freccia Sinistra |
| Vai una parola a destra | Ctrl + freccia destra |
| Seleziona tutto | CTRL + A |
| Rientro | CTRL+ ] |
| Rimuovi rientro | CTRL + [ |
| Passare alla modalità comandi | Esc |
Per trovare tutti i tasti di scelta rapida, selezionare Visualizza sulla barra multifunzione del notebook e quindi selezionare Tasti di scelta rapida.
Contenuto correlato
- Visualizzazione dei notebook
- Introduzione a Fabric NotebookUtils
- Diagnosticare gli errori dei notebook con Copilot