Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:✅ Ingegneria dei dati e data science di Fabric
Quando si crea Microsoft Fabric dal portale di Azure, viene aggiunto automaticamente al tenant di Fabric associato alla sottoscrizione usata per creare la capacità. Con la configurazione semplificata in Microsoft Fabric, non è necessario collegare la capacità al tenant di Fabric. Ciò è possibile dal momento che la capacità appena creata verrà elencata nel riquadro delle impostazioni di amministrazione. Questa configurazione offre un'esperienza più rapida affinché gli amministratori inizino a configurare la capacità per i loro team di analisi aziendale.
Per apportare modifiche alle impostazioni di ingegneria dei dati/data science in una capacità, è necessario disporre del ruolo di amministratore per tale capacità. Per ulteriori informazioni sui ruoli che è possibile assegnare agli utenti in una capacità, vedere Ruoli nelle capacità.
Usare la procedura seguente per gestire le impostazioni di ingegneria dei dati/scienza per la capacità Microsoft Fabric:
Selezionare l'opzione Impostazioni per aprire il riquadro delle impostazioni per il proprio account Fabric. Selezionare Portale di amministrazione nella sezione Governance e informazioni dettagliate.
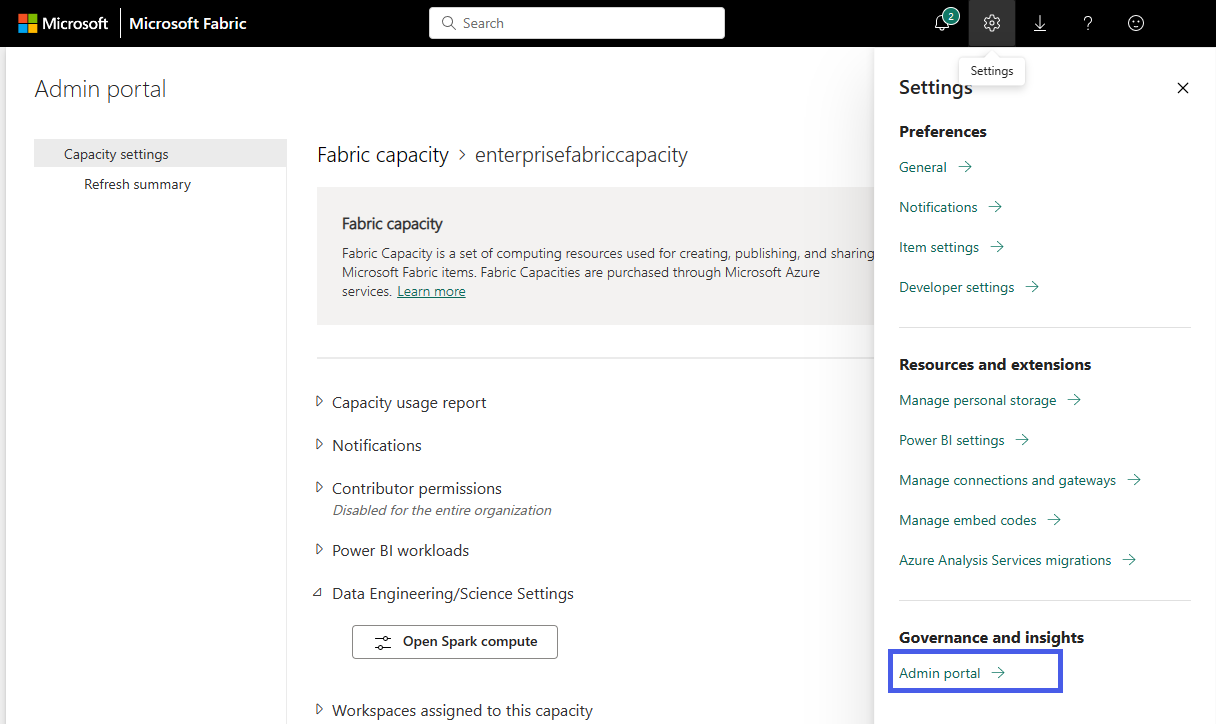
Scegliere l'opzione Impostazioni capacità per espandere il menu e selezionare la scheda Capacità infrastruttura . Qui dovrebbero essere visualizzate le capacità create nel tenant. Scegliere la capacità da configurare.
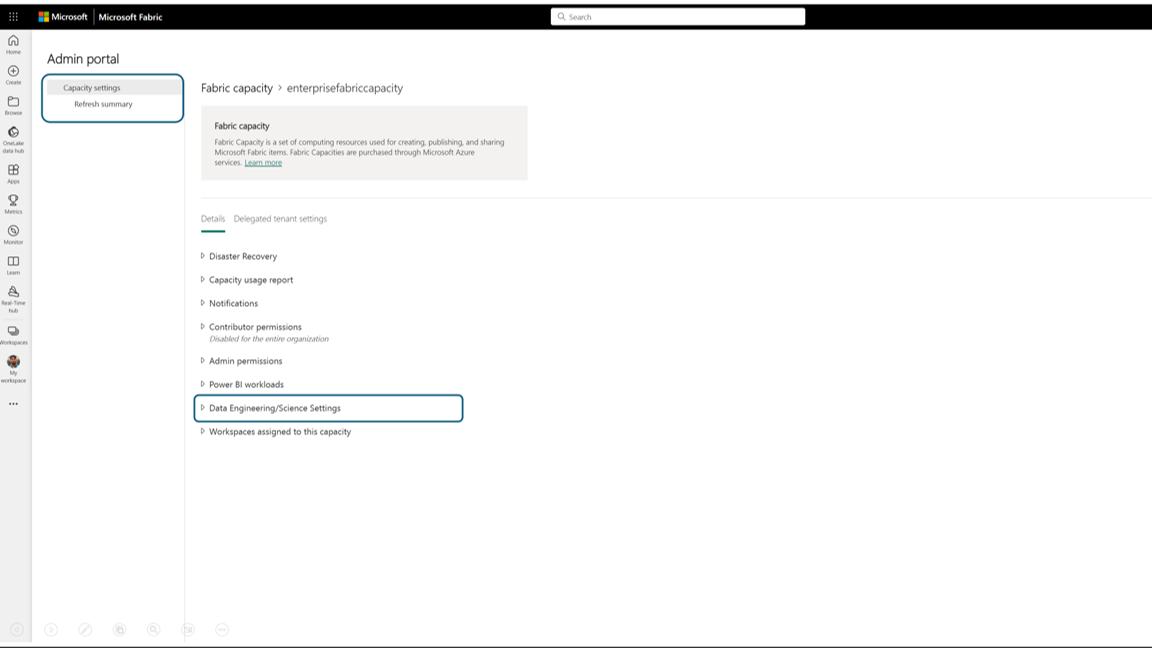
Si passa al riquadro dei dettagli della capacità, in cui è possibile visualizzare l'utilizzo e altri controlli di amministrazione per la capacità. Passare alla sezione Impostazioni ingegneria dei dati/data science e selezionare Apri calcolo Spark. Configurare i parametri seguenti:


Nota
Almeno un'area di lavoro deve essere collegata alla capacità Fabric per esplorare le impostazioni di ingegneria/scienza dei dati dal portale di amministrazione della capacità Fabric.
Controllo amministratore: Disabilitare l'utilizzo del pool di avvio
Gli amministratori della capacità possono ora scegliere di disabilitare l'utilizzo dello Starter Pool nelle aree di lavoro collegate alla capacità. Se disabilitato, gli utenti e gli amministratori dell'area di lavoro non visualizzeranno più il pool di avvio come opzione di calcolo. Devono invece usare pool personalizzati creati e gestiti in modo esplicito dall'amministratore della capacità.
Questa funzionalità offre una governance centralizzata per l'utilizzo del calcolo, assicurando un maggiore controllo sul ridimensionamento, sui costi e sul comportamento di pianificazione.
Suggerimento
Questa impostazione è particolarmente utile nelle organizzazioni di grandi dimensioni che vogliono standardizzare i modelli di calcolo ed evitare l'utilizzo arbitrario tramite pool di avvio predefiniti.
Controllo amministratore: interruttore di bursting a livello di lavoro
Microsoft Fabric supporta 3× bursting per i VCore Spark, consentendo a un singolo processo di usare temporaneamente più core di calcolo rispetto alla capacità di base. Ciò migliora le prestazioni del processo durante i picchi di attività consentendo l'utilizzo completo della capacità.
In qualità di amministratore della capacità, puoi ora controllare questo comportamento usando l'opzione "Disabilita bursting a livello di job" disponibile nel portale di amministrazione:
Località:
Admin Portal → Capacity Settings → [Select Capacity] → Data Engineering/Science Settings → Spark ComputeComportamento:
- Abilitato (impostazione predefinita): un singolo processo Spark può usare il limite di burst completo (fino a 3× VCore Spark).
- Disabilitato: i singoli processi Spark sono limitati all'allocazione della capacità di base, mantenendo la concorrenza ed evitando il monopolio.
Nota
Questo interruttore è disponibile solo quando si eseguono processi Spark su Capacity di Fabric. Se l'opzione Fatturazione automatica con scalabilità è abilitata, questo interruttore viene disabilitato automaticamente perché:
- La fatturazione con scalabilità automatica segue un modello con pagamento in base al consumo puro.
- Non esiste una finestra di smussamento per consentire picchi di utilizzo e bilanciarli nell'arco di 24 ore.
- Il bursting è una funzionalità della capacità riservata, non della scalabilità automatica del calcolo su richiesta.
Casi d'uso ed esempi
| Sceneggiatura | Impostazione | Comportamento |
|---|---|---|
| Carico di lavoro ETL elevato | Bursting abilitato (impostazione predefinita) | Il processo può usare l'intera capacità burst (ad esempio, 384 VCore Spark in F64). |
| Notebook interattivi multiutente | Bursting disabilitato | L'utilizzo dei lavori è limitato (ad esempio, 128 VCore Spark in F64), migliorando il parallelismo. |
| La fatturazione Autoscale è abilitata | Controllo bursting non disponibile | Tutti gli utilizzi di Spark vengono fatturati su richiesta; nessun bursting dalla capacità di base. |
Suggerimento
Usare questa opzione per ottimizzare la velocità effettiva o la concorrenza:
- Mantieni il bursting abilitato per processi e pipeline di grandi dimensioni.
- Disabilitarla per ambienti interattivi o condivisi con molti utenti.
Pool di capacità per ingegneria dei dati e data science in Microsoft Fabric
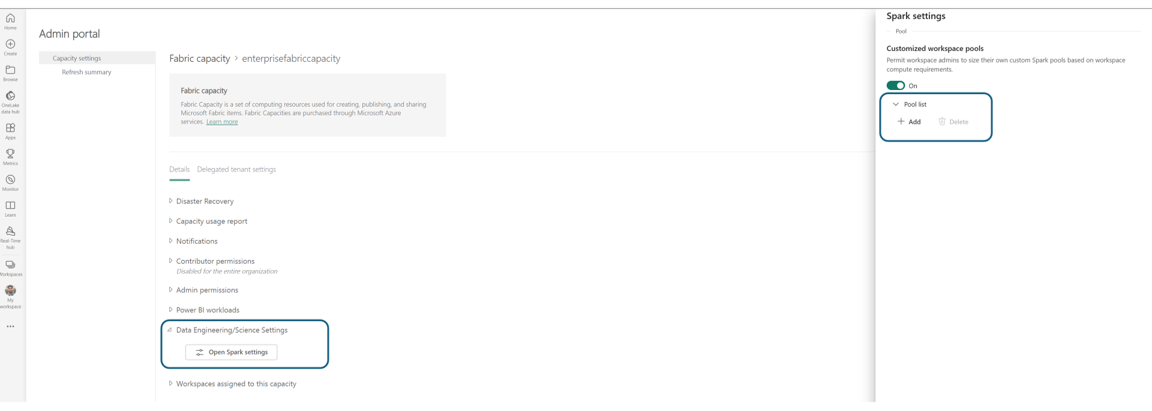
Nella sezione Elenco pool nelle Impostazioni di Spark, fare clic su Aggiungi per creare un pool personalizzato per la capacità di Fabric.
Si passa alla pagina di creazione del pool, in cui è possibile:
- Specificare il nome del pool
- Selezionare la famiglia di nodi e le dimensioni del nodo
- Impostare nodi Min e Max
- Abilitare/disabilitare la scalabilità automatica e l'allocazione dinamica degli executor
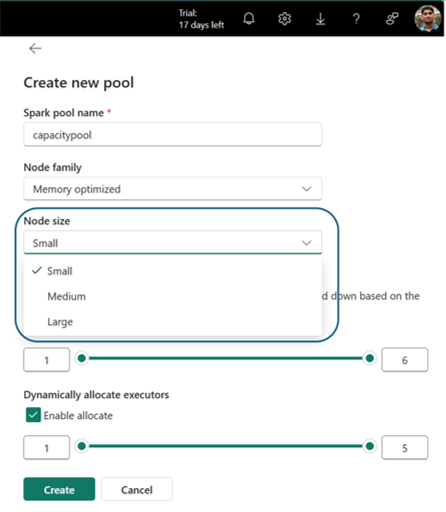
Selezionare Crea per salvare le impostazioni.



Nota
I pool personalizzati a livello di capacità hanno una latenza di avvio di 2-3 minuti. Per velocizzare l'avvio della sessione Spark (<5 secondi), usare i pool di avvio se abilitati.
Dopo la creazione, il pool di capacità diventa disponibile in:
- Menu a tendina Selezione del pool nelle impostazioni dell'area di lavoro
- Pagina Impostazioni di calcolo dell'ambiente nelle aree di lavoro
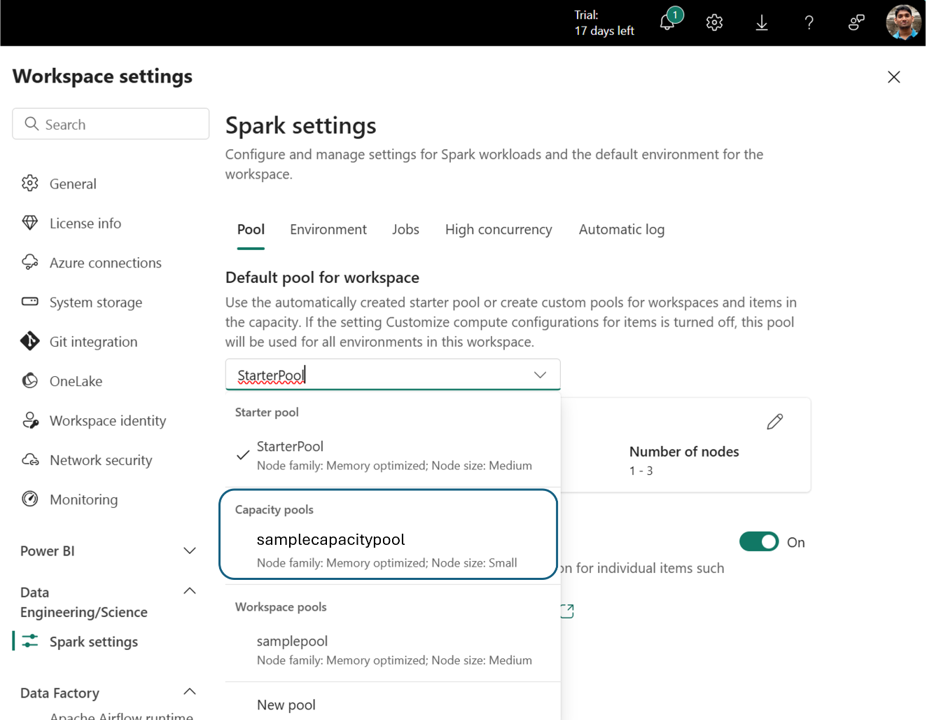
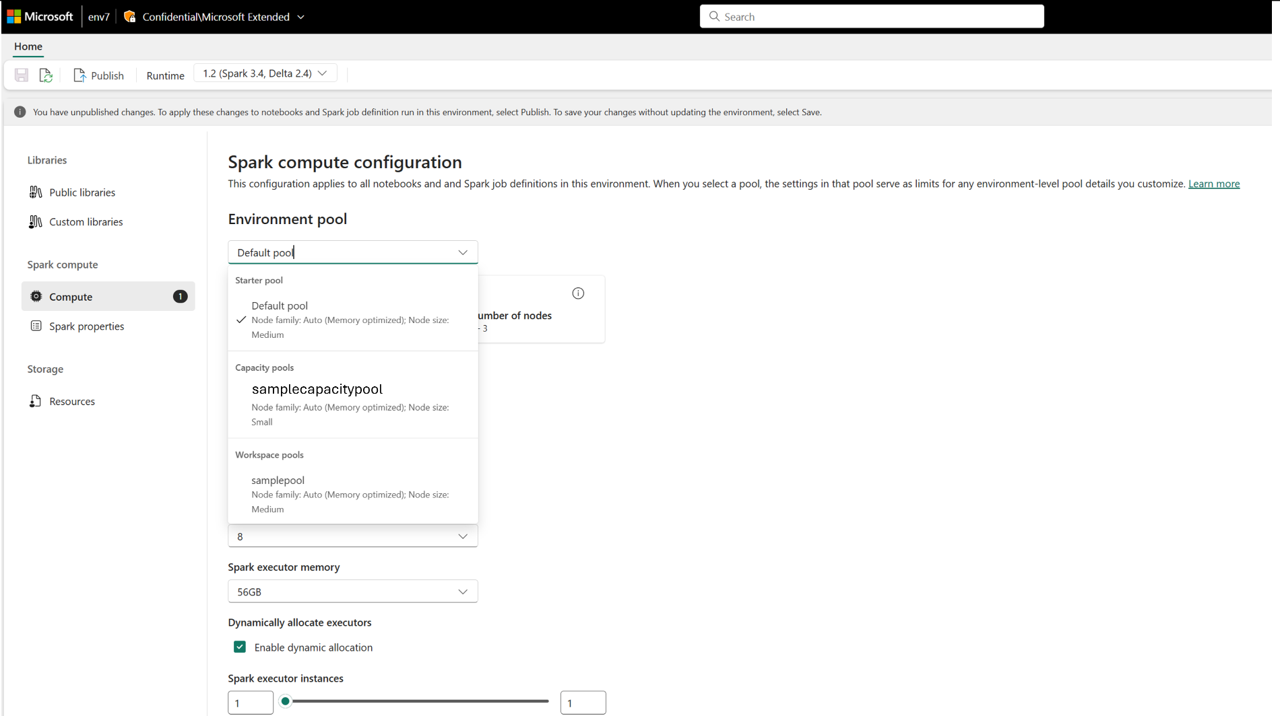
Ciò consente la governance centralizzata delle risorse di calcolo. Gli amministratori possono creare pool standardizzati e, facoltativamente, disabilitare la personalizzazione a livello di area di lavoro, impedendo agli amministratori nelle aree di lavoro di modificare le impostazioni del pool o crearne di personalizzate.

