Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo quickstart illustra come creare una definizione di processo Spark che contiene codice Python con Spark Structured Streaming per portare i dati in un lakehouse e quindi servirli tramite un endpoint di analisi SQL. Dopo aver completato questa guida introduttiva, si avrà una definizione di un job Spark che viene eseguito continuamente e l'endpoint di analisi SQL può visualizzare i dati in ingresso.
Creare uno script Python
Utilizzare il seguente script Python per creare una tabella Delta di streaming in un lakehouse utilizzando Apache Spark. Lo script legge un flusso di dati generati (una riga al secondo) e lo scrive in modalità di accodamento in una tabella Delta denominata streamingtable. Archivia i dati e le informazioni relative al checkpoint nella lakehouse specificata.
Usare il codice Python seguente che usa Spark Structured Streaming per ottenere dati in una tabella lakehouse.
from pyspark.sql import SparkSession if __name__ == "__main__": # Start Spark session spark = SparkSession.builder \ .appName("RateStreamToDelta") \ .getOrCreate() # Table name used for logging tableName = "streamingtable" # Define Delta Lake storage path deltaTablePath = f"Tables/{tableName}" # Create a streaming DataFrame using the rate source df = spark.readStream \ .format("rate") \ .option("rowsPerSecond", 1) \ .load() # Write the streaming data to Delta query = df.writeStream \ .format("delta") \ .outputMode("append") \ .option("path", deltaTablePath) \ .option("checkpointLocation", f"{deltaTablePath}/_checkpoint") \ .start() # Keep the stream running query.awaitTermination()Salvare lo script come file Python (.py) nel computer locale.
Creare un lakehouse
Usare i passaggi seguenti per creare un lakehouse:
Passare all'area di lavoro desiderata o crearne una nuova, se necessario.
Per creare una lakehouse, selezionare Nuovo elemento nell'area di lavoro, quindi selezionare Lakehouse nel pannello visualizzato.
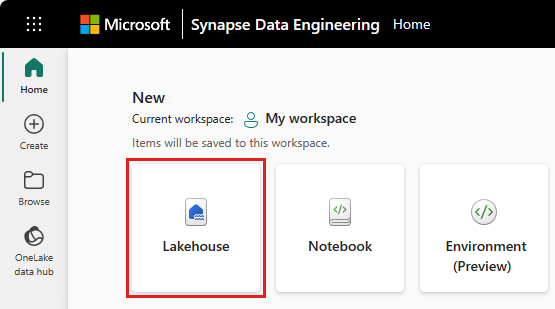
Immettere il nome del lakehouse e selezionare Crea.

Creare una definizione di processo Spark
Per creare una definizione di processo Spark, usare i passaggi seguenti:
Nella stessa area di lavoro in cui è stata creata una lakehouse selezionare Nuovo elemento.
Nel pannello visualizzato, in Recupera dati selezionare Spark Job Definition (Definizione processo Spark).
Immettere il nome della definizione di job Spark e selezionare Crea.
Selezionare Carica, quindi selezionare il file Python creato nel passaggio precedente.
Sotto Riferimento al Lakehouse, scegli il lakehouse che hai creato.
Impostare la politica di ripetizione per la definizione del processo Spark
Utilizzare i passaggi seguenti per impostare i criteri di tentativi per la definizione del processo Spark.
Dal menu in alto, selezionare l’icona Impostazione.
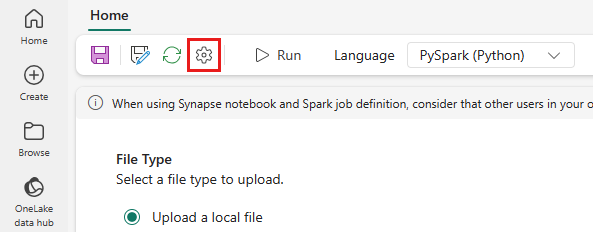
Aprire la scheda Ottimizzazione e impostare il trigger Criteri di ripetizione su Attivato.
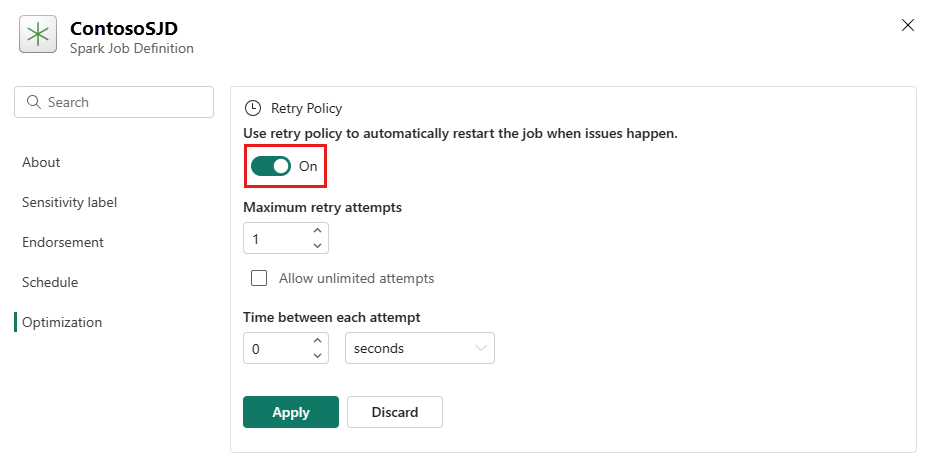
Definire il numero massimo di tentativi o selezionare Consenti tentativi illimitati.
Specificare il tempo tra ogni tentativo e selezionare Applica.


Nota
Esiste un limite di durata di 90 giorni per l’impostazione della politica di ripetizione. Dopo aver abilitato la politica di ripetizione, l'attività verrà riavviata conformemente alla politica entro 90 giorni. Dopo questo periodo, il criterio di ripetizione smetterà automaticamente di funzionare e il processo verrà terminato. Gli utenti dovranno quindi riavviare manualmente il processo, che a sua volta riabiliterà i criteri di ripetizione.
Eseguire e monitorare la definizione dell'attività Spark
Nel menu in alto, selezionare l’icona Esegui.
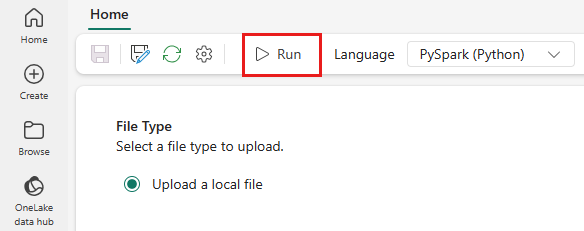
Controllare se la definizione del processo Spark è stata inviata correttamente e funziona.

Visualizzare i dati usando un endpoint di Analisi SQL
Dopo l'esecuzione dello script, viene creata una tabella denominata streamingtable con timestamp e colonne di valore nella lakehouse. È possibile visualizzare i dati usando l'endpoint di analisi SQL:
Nell'area di lavoro, apri la Lakehouse.
Passare all'endpoint di analisi SQL dall'angolo superiore destro.
Nel riquadro di spostamento a sinistra, espandere Schemas > dbo >Tables, selezionare streamingtable per visualizzare in anteprima i dati.