Destinazioni e impostazioni gestite dei dati di Dataflow Gen2
Dopo aver pulito e preparato i dati con Dataflow Gen2, è bene trasferire i dati in una destinazione. A tale scopo, usare le funzionalità di destinazione dei dati in Dataflow Gen2. Con questa funzionalità, è possibile scegliere tra destinazioni diverse, ad esempio AZURE SQL, Fabric Lakehouse e molte altri ancora. Dataflow Gen2 scrive quindi i dati nella destinazione e da qui è possibile usare i dati per ulteriori analisi e report.
L'elenco seguente contiene le destinazioni dati supportate.
- Database SQL di Azure
- Esplora dati di Azure (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- Database KQL dell'infrastruttura
- Database SQL dell'infrastruttura
Punti di ingresso
Ogni query di dati nel flusso di dati Gen2 può avere una destinazione dati. Le funzioni e gli elenchi non sono supportati; l'applicazione è possibile solo alle query tabulari. È possibile specificare la destinazione dei dati per ogni query singolarmente ed è possibile usare più destinazioni diverse all'interno del flusso di dati.
Esistono tre punti di ingresso principali per specificare la destinazione dei dati:
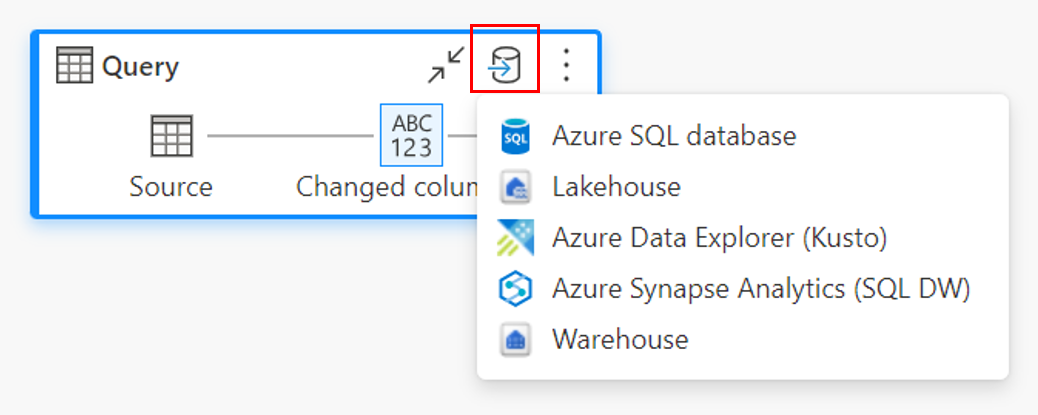
Attraverso la barra multifunzione superiore.
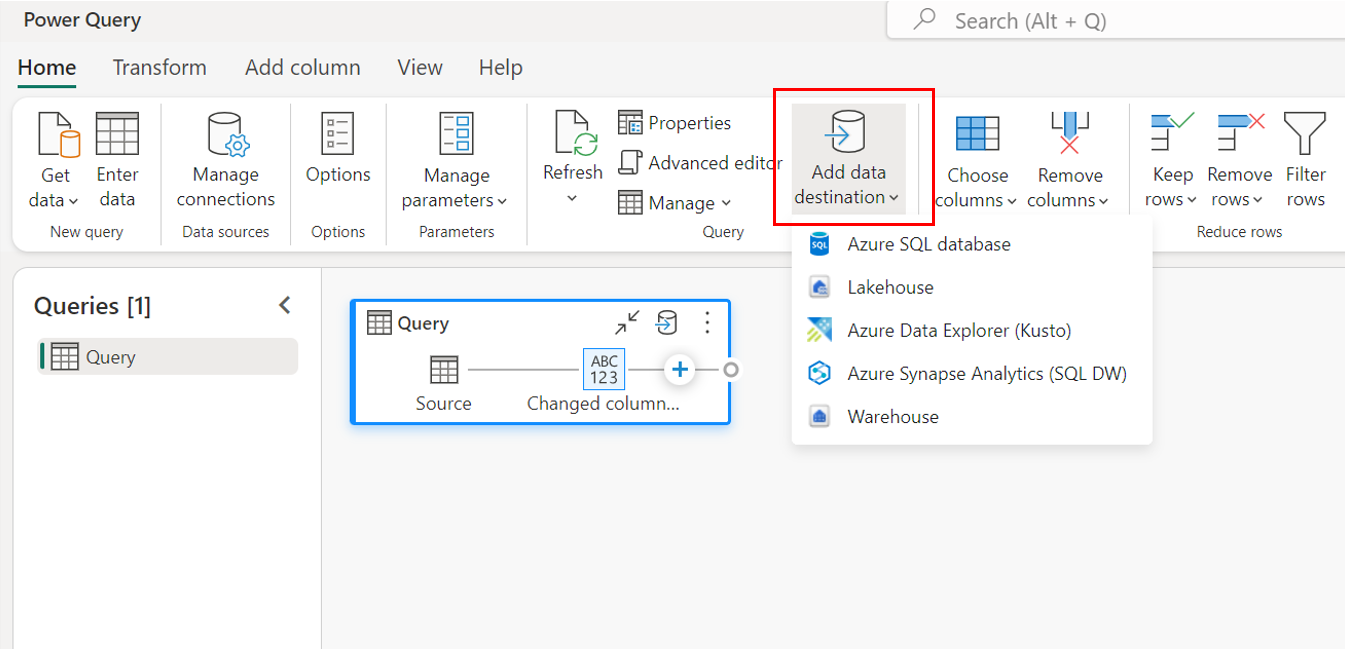
Tramite le impostazioni di query.
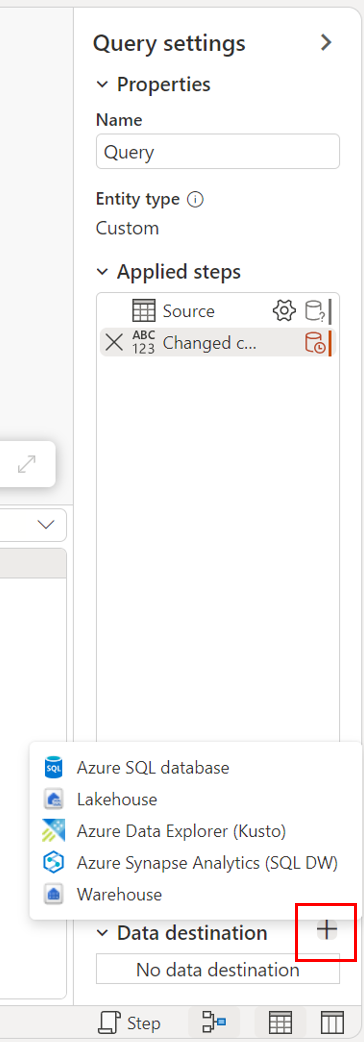
Tramite la visualizzazione diagramma.
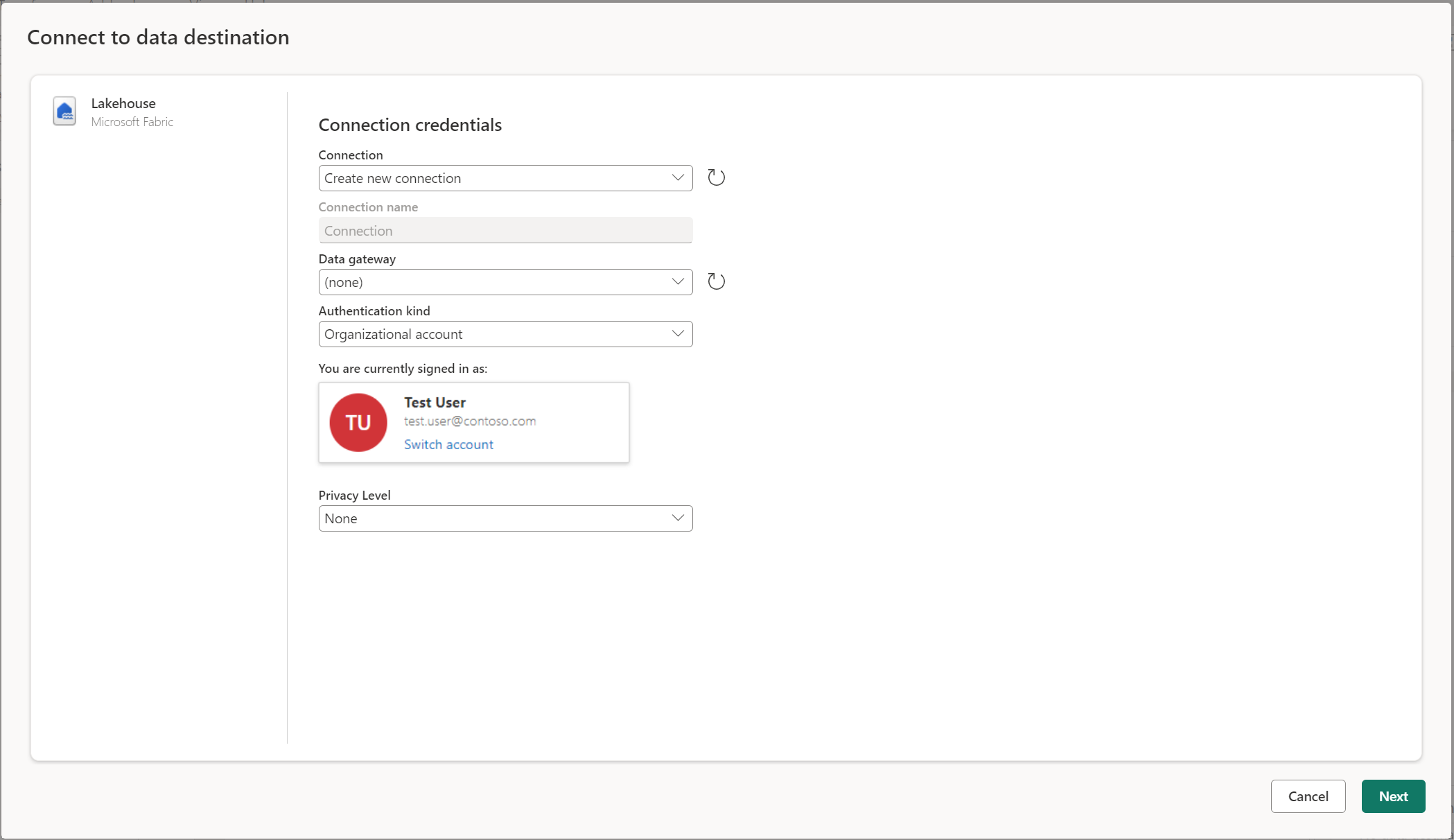
Connettersi alla destinazione dati
La connessione alla destinazione dati è simile alla connessione a un'origine dati. Le connessioni possono essere usate sia per la lettura che per la scrittura dei dati, poiché si dispone delle autorizzazioni appropriate per l'origine dati. È necessario creare una nuova connessione o selezionare una connessione esistente e quindi selezionare Avanti.
Creare una nuova tabella o sceglierne una esistente
Durante il caricamento nella destinazione dati, è possibile creare una nuova tabella o selezionarne una esistente.
Creare una nuova tabella
Quando si sceglie di creare una nuova tabella, durante l'aggiornamento del flusso di dati Gen2 viene creata una nuova tabella nella destinazione dati. Se la tabella viene eliminata in futuro passando manualmente alla destinazione, il flusso di dati ricrea la tabella durante l'aggiornamento successivo del flusso di dati.
Per impostazione predefinita, il nome tabella ha lo stesso nome della query. Se nel nome della tabella sono presenti caratteri non validi che la destinazione non supporta, il nome tabella viene modificato automaticamente. Ad esempio, molte destinazioni non supportano spazi o caratteri speciali.
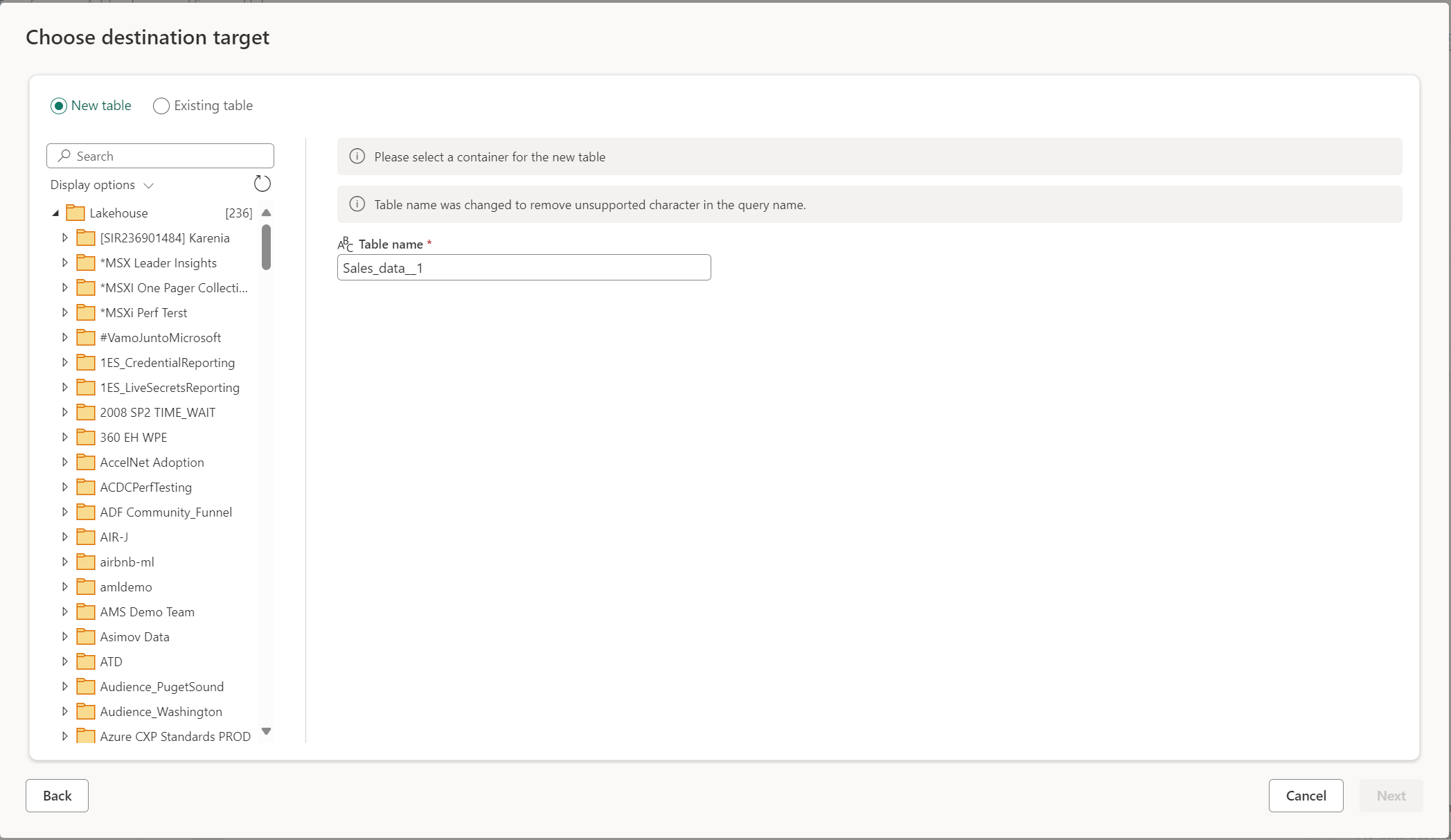
Successivamente, è necessario selezionare il contenitore di destinazione. Se si sceglie una delle destinazioni dati di Fabric, è possibile usare lo strumento di navigazione per selezionare l'artefatto Fabric in cui caricare i dati. Per le destinazioni di Azure, è possibile specificare il database durante la creazione della connessione o selezionare il database dall'esperienza di navigazione.
Utilizza una tabella esistente
Per scegliere una tabella esistente, usare l'interruttore nella parte superiore dello strumento di navigazione. Quando si sceglie una tabella esistente, è necessario selezionare sia l'artefatto/database dell'infrastruttura che la tabella usando lo strumento di navigazione.
Quando si usa una tabella esistente, la tabella non può essere ricreata in alcuno scenario. Se si elimina manualmente la tabella dalla destinazione dati, il flusso di dati Gen2 non ricrea la tabella al successivo aggiornamento.
Impostazioni gestite per le nuove tabelle
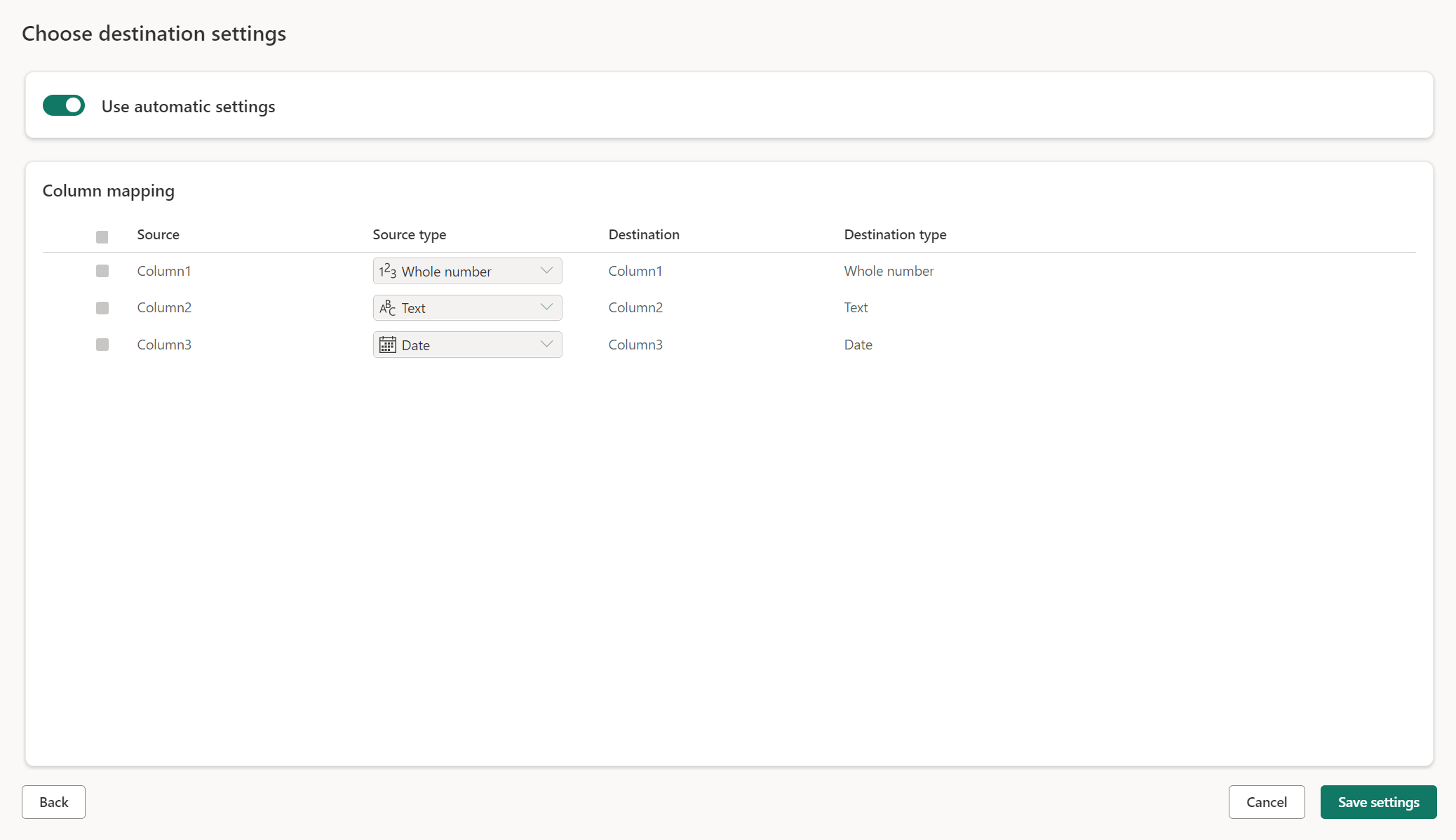
Quando si carica in una nuova tabella, le impostazioni automatiche sono attivate per impostazione predefinita. Se si usano le impostazioni automatiche, il flusso di dati Gen2 gestisce automaticamente il mapping. Le impostazioni automatiche forniscono il comportamento seguente:
Sostituzione del metodo di aggiornamento: i dati vengono sostituiti a ogni aggiornamento del flusso di dati. Tutti i dati nella destinazione vengono rimossi. I dati nella destinazione vengono sostituiti con i dati di output del flusso di dati.
Mapping gestito: il mapping viene gestito per l'utente. Quando è necessario apportare modifiche ai dati/query per aggiungere un'altra colonna o modificare un tipo di dati, il mapping viene modificato automaticamente per questa modifica quando si ripubblica il flusso di dati. Non è necessario passare all'esperienza di destinazione dei dati ogni volta che si apportano modifiche al flusso di dati, consentendo di apportare facilmente modifiche allo schema quando si ripubblica il flusso di dati.
Eliminare e ricreare la tabella: per consentire queste modifiche allo schema, ad ogni aggiornamento del flusso di dati la tabella viene eliminata e ricreata. L'aggiornamento del flusso di dati potrebbe causare la rimozione di relazioni o misure aggiunte in precedenza alla tabella.
Nota
Attualmente, l'impostazione automatica è supportata solo per Lakehouse e il database SQL di Azure come destinazione dati.
Impostazioni manuali
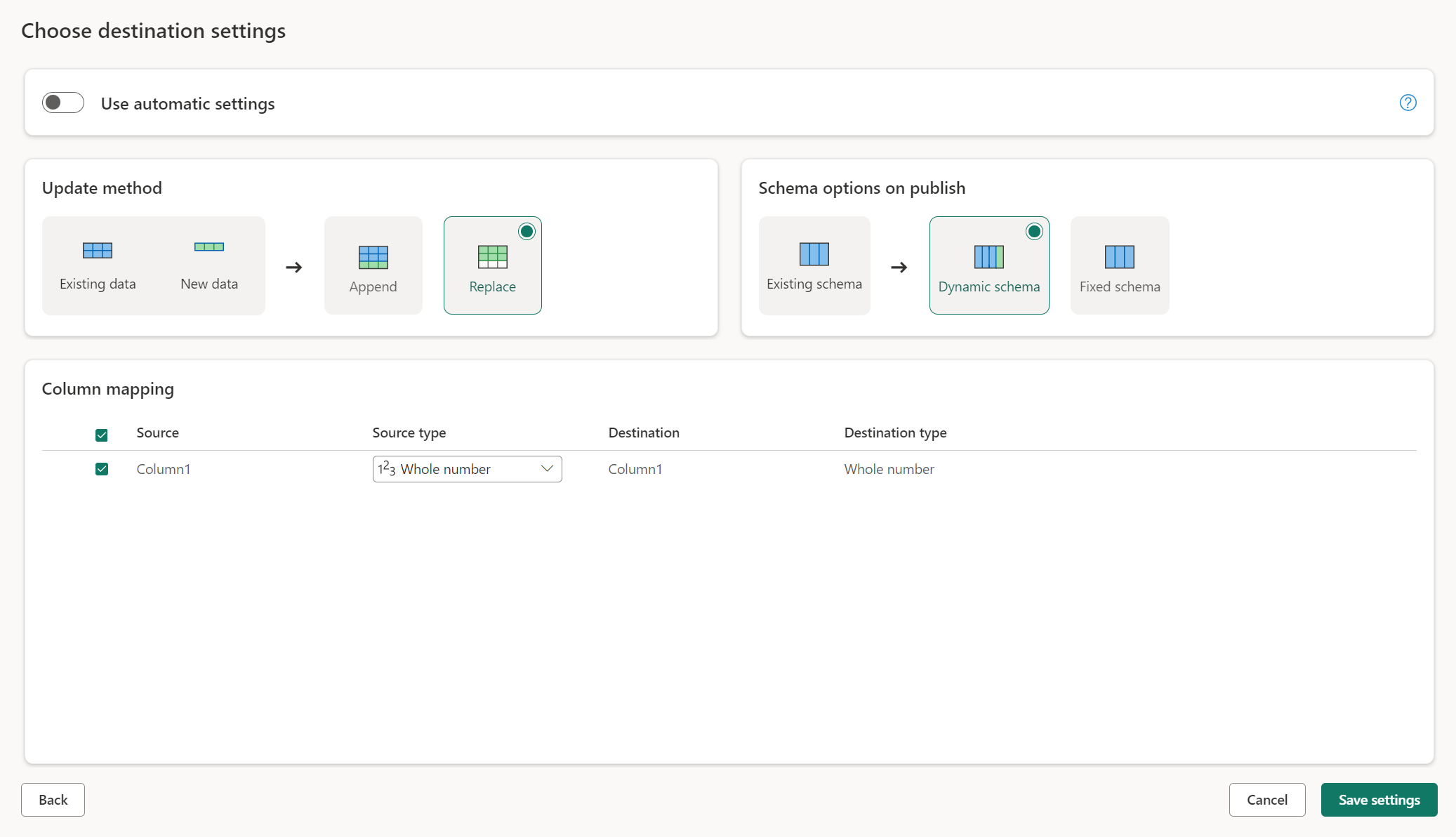
Disattivando Usa impostazioni automatiche, si ottiene il controllo completo su come caricare i dati nella destinazione dei dati. È possibile apportare modifiche al mapping delle colonne modificando il tipo di origine o escludendo qualsiasi colonna non necessaria nella destinazione dati.
Metodi di aggiornamento
La maggior parte delle destinazioni supporta sia l'accodamento che la sostituzione come metodi di aggiornamento. Tuttavia, i database KQL di Fabric ed Esplora dati di Azure non supportano la sostituzione come metodo di aggiornamento.
Sostituisci: ad ogni aggiornamento del flusso di dati i dati vengono eliminati dalla destinazione e sostituiti dai dati di output del flusso di dati.
Accoda: ad ogni aggiornamento del flusso di dati, i dati di output del flusso di dati vengono accodati ai dati esistenti nella tabella di destinazione dati.
Opzioni dello schema per la pubblicazione
Le opzioni dello schema per la pubblicazione si applicano solo quando il metodo di aggiornamento è la sostituzione. Quando si aggiungono dati, le modifiche apportate allo schema non sono possibili.
Schema dinamico: quando si sceglie lo schema dinamico, è possibile consentire le modifiche dello schema nella destinazione dei dati quando si ripubblica il flusso di dati. Poiché non si usa il mapping gestito, è comunque necessario aggiornare il mapping delle colonne nel flusso di destinazione di flusso del flusso di dati quando si apportano modifiche alla query. Quando si aggiorna il flusso di dati, la tabella viene eliminata e ricreata. L'aggiornamento del flusso di dati potrebbe causare la rimozione di relazioni o misure aggiunte in precedenza alla tabella.
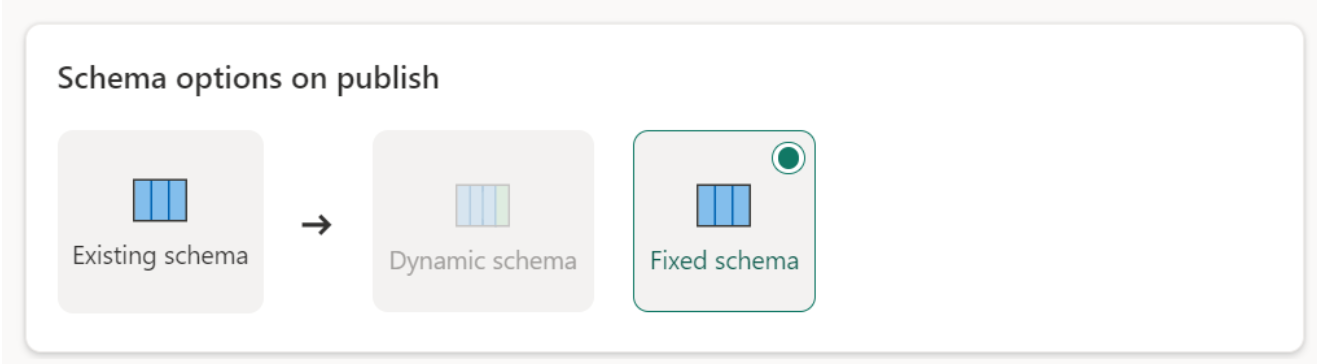
Schema fisso: quando si sceglie uno schema fisso, le modifiche allo schema non sono possibili. Quando il flusso di dati viene aggiornato, vengono eliminate e sostituite solo le righe della tabella con i dati di output del flusso di dati. Qualsiasi relazione o misura sulla tabella rimane intatta. Se si apportano modifiche alla query nel flusso di dati, la pubblicazione del flusso di dati ha esito negativo se rileva che lo schema della query non corrisponde allo schema di destinazione dei dati. Usare questa impostazione quando non si prevede di modificare lo schema e di avere relazioni o misure aggiunte alla tabella di destinazione.
Nota
Quando si caricano dati nel magazzino, è supportato solo lo schema fisso.
Tipi di origine dati supportati per destinazione
| Tipi di dati supportati per posizione di archiviazione: | DataflowStagingLakehouse | Output Azure DB (SQL) | Output Azure Data Explorer | Output Fabric Lakehouse (LH) | Output Fabric Warehouse (WH) | Output dell'infrastruttura database SQL (SQL) |
|---|---|---|---|---|---|---|
| Azione | No | No | No | No | No | No |
| Qualsiasi | No | No | No | No | No | No |
| Binario | No | No | No | No | No | Numero |
| Valuta | Sì | Sì | Sì | Sì | No | Sì |
| DateTimeZone | Sì | Sì | Sì | No | No | Sì |
| Durata | No | No | Sì | No | No | No |
| Funzione | No | No | No | No | No | No |
| None | No | No | No | No | No | No |
| Null | No | No | No | No | No | No |
| Tempistica | Sì | Sì | No | No | No | Sì |
| Type | No | No | No | No | No | No |
| Strutturato (Elenco, Record, Tabella) | No | No | No | No | No | No |
Argomenti avanzati
Uso della gestione temporanea prima del caricamento in una destinazione
Per migliorare le prestazioni dell'elaborazione delle query, la gestione temporanea può essere usata all'interno di flussi di dati Gen2 per usare l'ambiente di calcolo di Fabric per eseguire le query.
Quando la gestione temporanea è abilitata nelle query (comportamento predefinito), i dati vengono caricati nel percorso di gestione temporanea, ovvero un Lakehouse interno accessibile solo dai flussi di dati stessi.
L'uso dei percorsi di gestione temporanea può migliorare le prestazioni in alcuni casi in cui la riduzione della query all'endpoint di analisi SQL è più veloce rispetto all'elaborazione della memoria.
Quando si caricano dati in Lakehouse o in altre destinazioni non di magazzino, per impostazione predefinita si disabilita la funzionalità di gestione temporanea per migliorare le prestazioni. Quando si caricano dati nella destinazione dati, i dati sono scritti direttamente nella destinazione dei dati senza usare la gestione temporanea. Se si vuole usare la gestione temporanea per la query, è possibile abilitarla di nuovo.
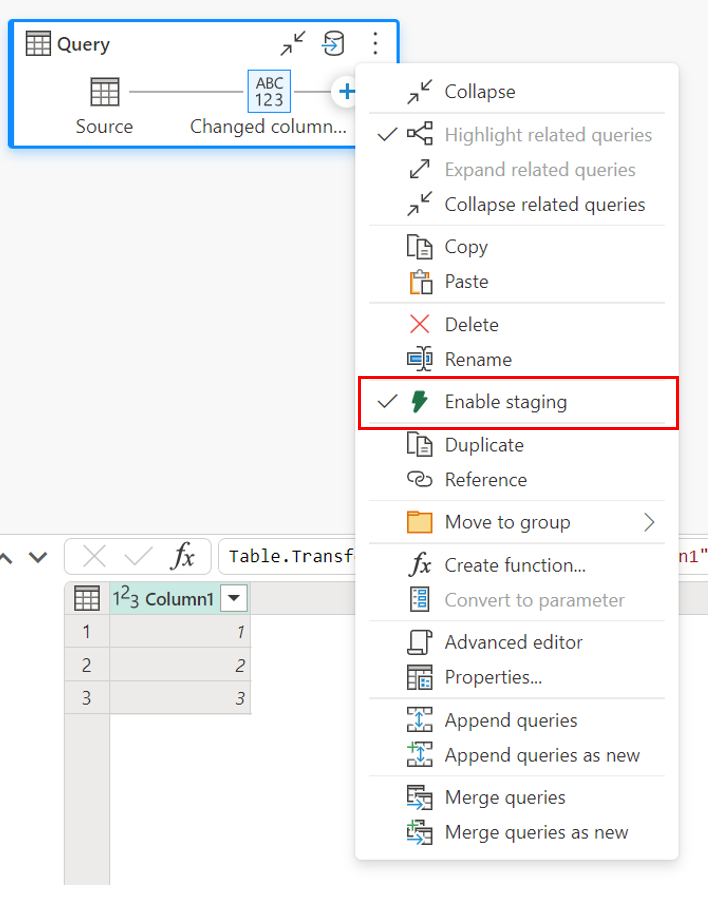
Per abilitare la gestione temporanea, fare clic con il pulsante destro del mouse sulla query e abilitare la gestione temporanea selezionando il pulsante Abilita gestione temporanea. La query diventa quindi blu.
Caricare i dati nel magazzino
Quando si caricano dati nel magazzino, la gestione temporanea è necessaria prima dell'operazione di scrittura nella destinazione dei dati. Questo requisito migliora le prestazioni. Attualmente, è supportato solo il caricamento nella stessa area di lavoro del flusso di dati. Verificare che la gestione temporanea sia abilitata per tutte le query caricate nel magazzino.
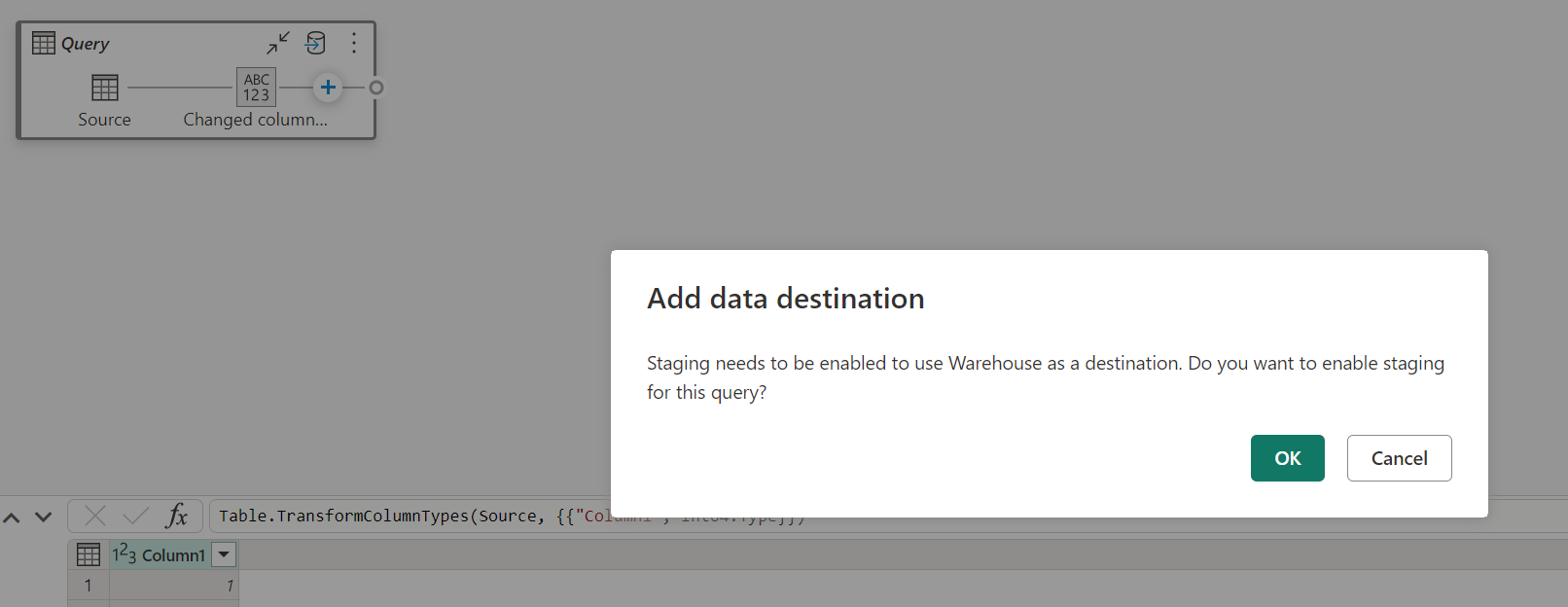
Quando la gestione temporanea è disabilitata e si sceglie Magazzino come destinazione di output, viene visualizzato un avviso per abilitare la gestione temporanea prima di poter configurare la destinazione dei dati.
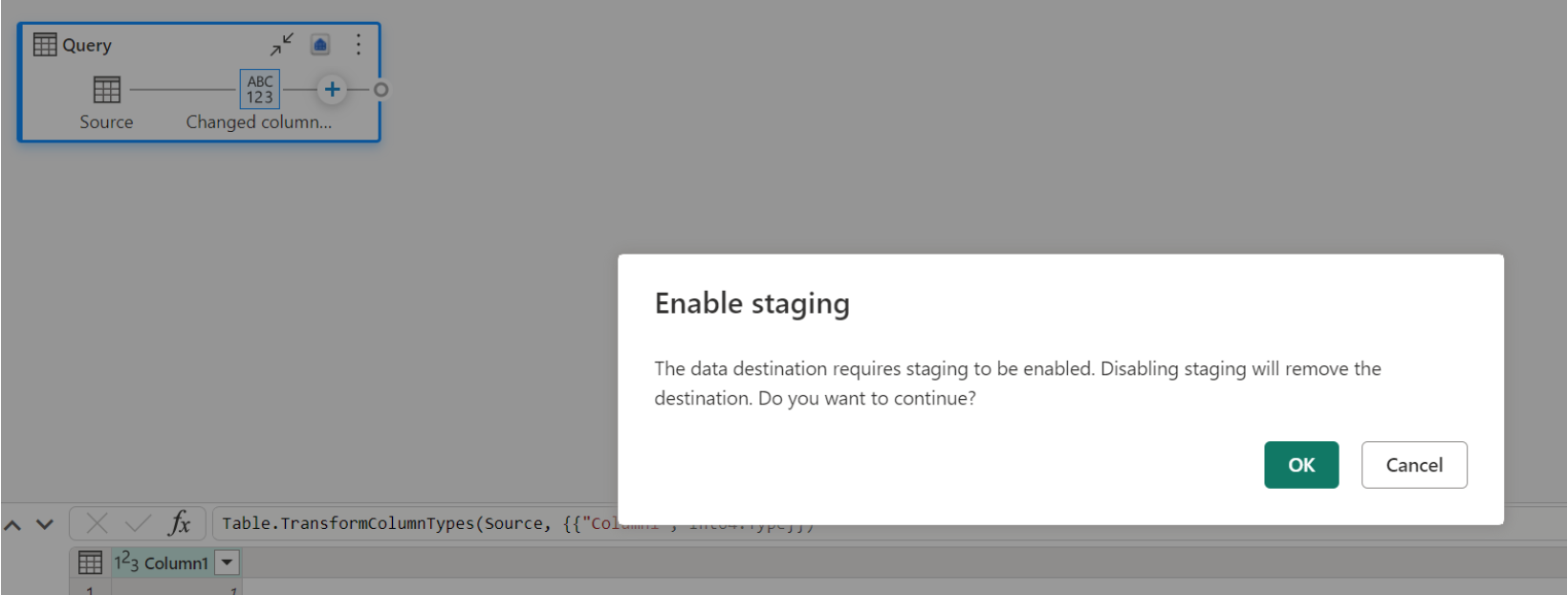
Se si dispone già di un magazzino come destinazione e si tenta di disabilitare la gestione temporanea, viene visualizzato un avviso. È possibile rimuovere il magazzino come destinazione o ignorare l'azione di gestione temporanea.
Vacuuming your Lakehouse data destination
Quando si usa Lakehouse come destinazione per Dataflow Gen2 in Microsoft Fabric, è fondamentale eseguire una manutenzione regolare per garantire prestazioni ottimali e una gestione efficiente dell'archiviazione. Un'attività di manutenzione essenziale consiste nel vuoto della destinazione dei dati. Questo processo consente di rimuovere i file meno vecchi a cui non viene più fatto riferimento dal log della tabella Delta, ottimizzando così i costi di archiviazione e mantenendo l'integrità dei dati.
Perché il vuoto è importante
- Ottimizzazione archiviazione: nel corso del tempo, le tabelle Delta accumulano file obsoleti che non sono più necessari. L'aspirapolvere consente di pulire questi file, liberando spazio di archiviazione e riducendo i costi.
- Miglioramento delle prestazioni: la rimozione di file non necessari può migliorare le prestazioni delle query riducendo il numero di file da analizzare durante le operazioni di lettura.
- Integrità dei dati: garantire che vengano conservati solo i file rilevanti consente di mantenere l'integrità dei dati, impedendo potenziali problemi con i file non inviati che potrebbero causare errori di lettura o danneggiamento delle tabelle.
Come eseguire il vuoto per la destinazione dei dati
Per eseguire il vuoto delle tabelle Delta in Lakehouse, seguire questa procedura:
- Passare a Lakehouse: dall'account di Microsoft Fabric passare alla lakehouse desiderata.
- Accedere alla manutenzione della tabella: in Lakehouse Explorer fare clic con il pulsante destro del mouse sulla tabella da gestire o usare i puntini di sospensione per accedere al menu contestuale.
- Selezionare le opzioni di manutenzione: scegliere la voce di menu Manutenzione e selezionare l'opzione Vacuum .
- Eseguire il comando vacuum: impostare la soglia di conservazione (il valore predefinito è sette giorni) ed eseguire il comando vacuum selezionando Esegui adesso.
Procedure consigliate
- Periodo di conservazione: impostare un intervallo di conservazione di almeno sette giorni per assicurarsi che gli snapshot precedenti e i file di cui non è stato eseguito il commit non vengano rimossi prematuramente, che potrebbero compromettere i lettori e i writer simultanei delle tabelle.
- Manutenzione regolare: pianificare il vuoto regolare come parte della routine di manutenzione dei dati per mantenere ottimizzate e pronte per l'analisi le tabelle Delta.
Incorporando il vuoto nella strategia di manutenzione dei dati, è possibile garantire che la destinazione Lakehouse rimanga efficiente, conveniente e affidabile per le operazioni del flusso di dati.
Per informazioni più dettagliate sulla manutenzione delle tabelle in Lakehouse, vedere la documentazione sulla manutenzione delle tabelle Delta.
Nullable
In alcuni casi quando si dispone di una colonna che ammette i valori Null, viene rilevata da Power Query come colonna che non ammette i valori Null e quando si scrive nella destinazione dati, il tipo di colonna non ammette i valori Null. Durante l'aggiornamento si verifica l'errore seguente:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
Per forzare le colonne che ammettono i valori Null, è possibile provare la procedura seguente:
Eliminare la tabella dalla destinazione dati.
Rimuovere la destinazione dati dal flusso di dati.
Passare al flusso di dati e aggiornare i tipi di dati usando il codice di Power Query seguente:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Aggiungere la destinazione dati.
Conversione e aumento dei tipi di dati
In alcuni casi, il tipo di dati all'interno del flusso di dati è diverso da quello supportato nella destinazione dati; di seguito vi sono alcune conversioni predefinite che sono state messe in atto per garantire che i dati siano ancora in grado di ottenere i dati nella destinazione dati:
| Destinazione | Tipo di dati flusso di dati | Tipo di dati di destinazione |
|---|---|---|
| Fabric Warehouse | Int8.Type | Int16.Type |