Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un modello di apprendimento automatico è un file sottoposto a training per il riconoscimento di determinati tipi di criteri. Il training di un modello viene eseguito su un set di dati, fornendogli un algoritmo che può usare per ragionare e apprendere da questi set di dati. Dopo aver eseguito il training del modello, è possibile usarlo per ragionare sui dati nuovi al modello e per fare previsioni su tali dati.
In MLflow, un modello di apprendimento automatico può includere più versioni. In questo caso, ogni versione può rappresentare un'iterazione del modello. Questo articolo illustra come interagire con i modelli di Machine Learning per tenere traccia e confrontare le iterazioni del modello.
Questo articolo illustra come:
- Creare modelli di Machine Learning in Microsoft Fabric
- Gestire e tenere traccia delle versioni del modello
- Confrontare le prestazioni del modello tra le versioni
- Applicare modelli per la valutazione e l'inferenza
Creare un modello di Machine Learning
È possibile creare un modello di Machine Learning dall'interfaccia utente Fabric o a livello di codice con l'API MLflow. In MLflow i modelli usano un formato di creazione di pacchetti standard che funziona con vari strumenti downstream, tra cui l'inferenza batch in Apache Spark. Il formato salva un modello in diversi "sapori" che diversi strumenti downstream possono comprendere.
Per creare un modello di Machine Learning dall'interfaccia utente:
- Selezionare un'area di lavoro data science esistente o creare una nuova area di lavoro.
- Creare un nuovo elemento tramite l'area di lavoro o usando il pulsante Crea:
- Spazio di lavoro
- Selezionare l'area di lavoro.
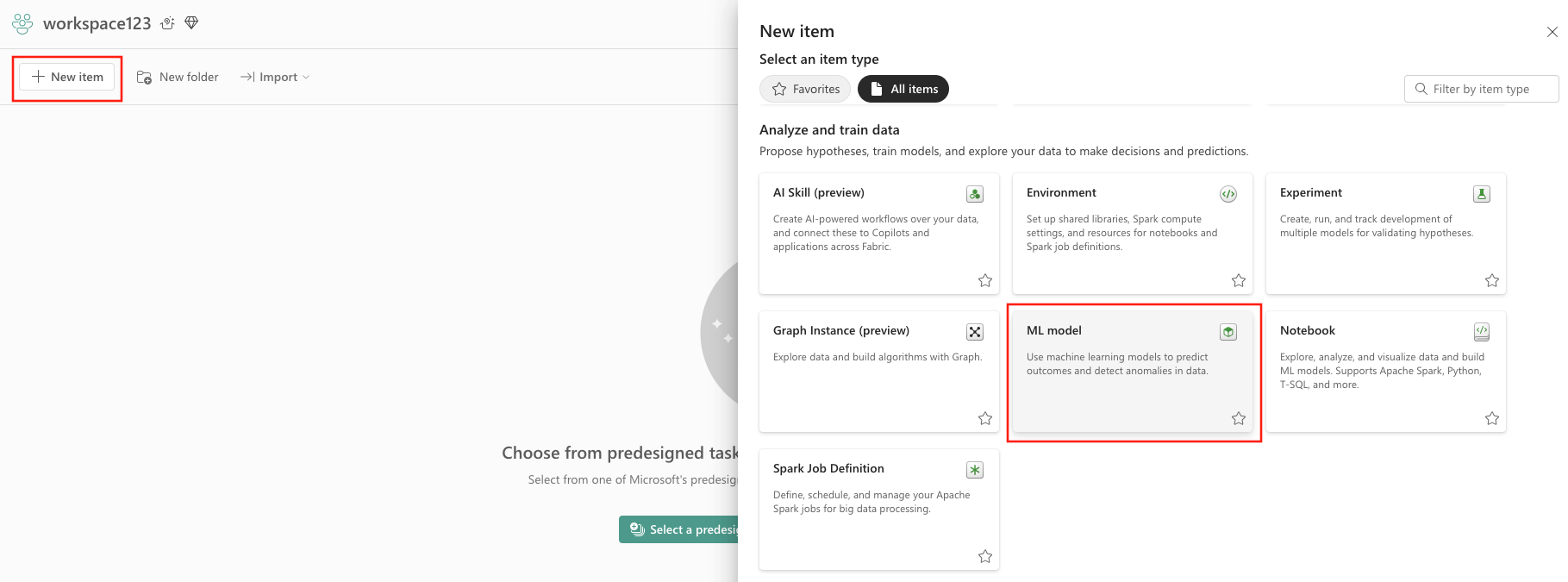
- Selezionare Nuovo elemento.
- Selezionare Modello di Machine Learning in Analizza ed esegui il training dei dati.
- Pulsante Crea:
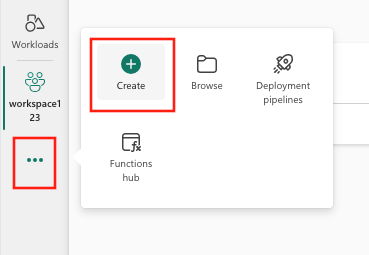
- Selezionare dal menu verticale Crea, che è disponibile in ....
- Selezionare Modello di Machine Learning in Analisi scientifica dei dati.

- Selezionare dal menu verticale Crea, che è disponibile in ....
- Spazio di lavoro
- Dopo la creazione del modello, è possibile iniziare ad aggiungere versioni del modello per tenere traccia delle metriche e dei parametri di esecuzione. Registrare o salvare le esecuzioni dell'esperimento in un modello esistente.



È anche possibile creare un modello di Machine Learning direttamente dall'esperienza di creazione con l'API mlflow.register_model() . Se non esiste un modello di apprendimento automatico registrato con il nome specificato, l'API lo crea in automatico.
import mlflow
model_uri = "runs:/{}/model-uri-name".format(run.info.run_id)
mv = mlflow.register_model(model_uri, "model-name")
print("Name: {}".format(mv.name))
print("Version: {}".format(mv.version))
Gestisci le versioni all'interno di un modello di apprendimento automatico
Un modello di apprendimento automatico contiene una raccolta di versioni del modello per il rilevamento e il confronto semplificati. All'interno di un modello, un data scientist può spostarsi tra diverse versioni del modello per esplorare i parametri e le metriche sottostanti. I data scientist possono anche eseguire confronti tra versioni del modello per identificare se i modelli più recenti potrebbero produrre risultati migliori.
Note
Con il supporto di MLflow 3 in Fabric, ogni modello registrato con mlflow.<flavor>.log_model(model, name="...") crea un'entità LoggedModel collegata all'esecuzione di origine, ai parametri, alle metriche, ai set di dati e all'ambiente. È possibile aprire un oggetto LoggedModel dalla pagina dell'esperimento e registrarlo come nuovo modello di Machine Learning o una nuova versione di un modello esistente. Per informazioni dettagliate, vedere MLflow 3 in Fabric Data Science.
Tenere traccia dei modelli di apprendimento automatico
Una versione del modello di apprendimento automatico rappresenta un singolo modello registrato per il rilevamento.
![]()
Ogni versione del modello include le informazioni seguenti:
| Proprietà | Descrzione |
|---|---|
| Ora di creazione | Data e ora di creazione del modello. |
| Esecuzione Nome | Identificatore dell'esecuzione dell'esperimento usato per creare questa versione specifica del modello. |
| Iperparametri | Salvato come coppie chiave-valore. Entrambe le chiavi e i valori sono stringhe. |
| Metrics | Eseguire le metriche salvate come coppie chiave-valore. Il valore è numerico. |
| Schema del modello/firma | Descrizione degli input e degli output del modello. |
| File registrati | File registrati in qualsiasi formato. Ad esempio, è possibile registrare immagini, ambiente, modelli e file di dati. |
| Etichette | Metadati personalizzati come coppie chiave-valore associate alle esecuzioni. Informazioni su come applicare tag. |
Applicare tag ai modelli di Machine Learning
L'assegnazione di tag MLflow per le versioni del modello consente agli utenti di allegare metadati personalizzati a versioni specifiche di un modello registrato nel Registro modelli MLflow. Questi tag, archiviati come coppie chiave-valore, consentono di organizzare, tenere traccia e distinguere tra le versioni del modello, semplificando la gestione dei cicli di vita del modello. I tag possono essere usati per indicare lo scopo del modello, l'ambiente di distribuzione o qualsiasi altra informazione pertinente, semplificando la gestione dei modelli più efficiente e il processo decisionale all'interno dei team.
Questo codice illustra come eseguire il training di un modello RandomForestRegressor usando Scikit-learn, registrare il modello e i parametri con MLflow e quindi registrare il modello nel Registro modelli MLflow con tag personalizzati. Questi tag forniscono metadati utili, ad esempio il nome del progetto, il reparto, il team e il trimestre del progetto, semplificando la gestione e la traccia della versione del modello.
import mlflow.sklearn
from mlflow.models import infer_signature
from sklearn.datasets import make_regression
from sklearn.ensemble import RandomForestRegressor
# Generate synthetic regression data
X, y = make_regression(n_features=4, n_informative=2, random_state=0, shuffle=False)
# Model parameters
params = {"n_estimators": 3, "random_state": 42}
# Model tags for MLflow
model_tags = {
"project_name": "grocery-forecasting",
"store_dept": "produce",
"team": "stores-ml",
"project_quarter": "Q3-2023"
}
# Log MLflow entities
with mlflow.start_run() as run:
# Train the model
model = RandomForestRegressor(**params).fit(X, y)
# Infer the model signature
signature = infer_signature(X, model.predict(X))
# Log parameters and the model
mlflow.log_params(params)
mlflow.sklearn.log_model(model, artifact_path="sklearn-model", signature=signature)
# Register the model with tags
model_uri = f"runs:/{run.info.run_id}/sklearn-model"
model_version = mlflow.register_model(model_uri, "RandomForestRegressionModel", tags=model_tags)
# Output model registration details
print(f"Model Name: {model_version.name}")
print(f"Model Version: {model_version.version}")
Dopo aver applicato i tag, è possibile visualizzarli direttamente nella pagina dei dettagli della versione del modello. Inoltre, i tag possono essere aggiunti, aggiornati o rimossi da questa pagina in qualsiasi momento.

Confronta e filtra i modelli di apprendimento automatico
Per confrontare e valutare la qualità delle versioni del modello di apprendimento automatico, è possibile confrontare i parametri, le metriche e i metadati tra le versioni selezionate.
Confronta visivamente i modelli di apprendimento automatico
È possibile confrontare visivamente le esecuzioni all'interno di un modello esistente. Il confronto visivo consente di passare in rassegna e spostarsi facilmente tra più versioni.

Per confrontare le esecuzioni, è possibile:
- Selezionare un modello di apprendimento automatico esistente che contiene più versioni.
- Selezionare Visualizza e quindi passare alla visualizzazione Elenco modelli. È anche possibile selezionare l'opzione Visualizza elenco di modelli direttamente dalla visualizzazione dei dettagli.
- È possibile personalizzare le colonne all'interno della tabella. Espandi il riquadro Personalizza colonne. Da qui è possibile selezionare le proprietà, le metriche, i tag e gli iperparametri da visualizzare.
- Infine, è possibile selezionare più versioni nel riquadro di confronto delle metriche, per confrontarne i risultati. Da questo riquadro è possibile personalizzare i grafici con le modifiche apportate al titolo del grafico, al tipo di visualizzazione, all'asse X, all'asse Y e altro ancora.
Confrontare i modelli di apprendimento automatico usando l'API MLflow
I data scientist possono anche usare MLflow per eseguire ricerche tra più modelli salvati nell'area di lavoro. Visitare la documentazione di MLflow per esplorare altre API di MLflow per interagire con il modello.
from pprint import pprint
from mlflow import MlflowClient
client = MlflowClient()
for rm in client.search_registered_models():
pprint(dict(rm), indent=4)
Applicare modelli di apprendimento automatico
Dopo aver eseguito il training di un modello in un set di dati, è possibile applicare tale modello a dati che non ha mai visto, per generare previsioni. Questa tecnica dell’uso di un modello è chiamata punteggio o inferenza.
Fabric supporta più approcci per l'applicazione dei modelli sottoposti a training:
- Assegnazione dei punteggi batch Applicare il modello su larga scala tra set di dati di grandi dimensioni usando Apache Spark. Questo è l'ideale per generare stime sui dati cronologici o pianificati.
- Assegnazione dei punteggi in tempo reale Distribuire il modello a un endpoint per le stime su richiesta, utile per le applicazioni che necessitano di risultati immediati.
Per iniziare a applicare i modelli, scegliere l'approccio più adatto allo scenario: