Procedura: Aggiungere dati di Azure Cosmos DB con mirroring con altri database con mirroring in Microsoft Fabric (anteprima)
In questa guida aggiungere due contenitori di Azure Cosmos DB per NoSQL da database separati usando il mirroring dell'infrastruttura.
È possibile unire dati da Cosmos DB con qualsiasi altro database, warehouse o lakehouse con mirroring all'interno della stessa area di lavoro infrastruttura.
Importante
Il mirroring per Azure Cosmos DB è attualmente in anteprima. I carichi di lavoro di produzione non sono supportati durante l'anteprima. Attualmente sono supportati solo gli account Azure Cosmos DB per NoSQL.
Prerequisiti
- Un account Azure Cosmos DB per NoSQL già presente.
- Se non si ha un abbonamento ad Azure, prova gratuitamente Azure Cosmos DB per NoSQL.
- Se si ha già un abbonamento ad Azure, creare un nuovo account Azure Cosmos DB per NoSQL.
- Capacità di Infrastruttura esistente. Se non si ha una capacità esistente, avviare una versione di valutazione di Fabric.
- Abilitare il mirroring nel tenant o nell'area di lavoro di Fabric. Se la funzionalità non è già abilitata, abilitare il mirroring nel tenant di Fabric.
- L'account Azure Cosmos DB per NoSQL deve essere configurato per il mirroring dell'infrastruttura. Per altre informazioni, vedere Requisiti dell'account.
Suggerimento
Durante l'anteprima pubblica, è consigliabile usare una copia di test o sviluppo dei dati di Azure Cosmos DB esistenti che possono essere ripristinati rapidamente da un backup.
Configurare il mirroring e i prerequisiti
Configurare il mirroring per il database NoSQL di Azure Cosmos DB. Se non si è certi di come configurare il mirroring, vedere l'esercitazione configurare il database con mirroring.
Passare al portale infrastruttura.
Creare una nuova connessione usando le credenziali dell'account Azure Cosmos DB.
Eseguire il mirroring del primo database usando la connessione configurata.
A questo punto, eseguire il mirroring del secondo database.
Attendere che la replica finisca lo snapshot iniziale dei dati per entrambi i mirror.
Creare una query che unisce i database
A questo punto, usare l'endpoint di analisi SQL per creare una query tra due elementi del database con mirroring, senza la necessità di spostamento dei dati. Entrambi gli elementi devono trovarsi nella stessa area di lavoro.
Passare a uno dei database con mirroring nel portale di Infrastruttura.
Passare da Azure Cosmos DB con mirroring all'endpoint di analisi SQL.

Nel menu selezionare + Magazzini. Selezionare l'elemento endpoint di analisi SQL per l'altro database con mirroring.
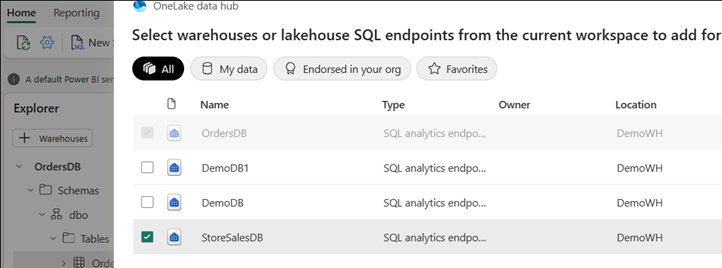
Aprire il menu di scelta rapida per la tabella e selezionare Nuova query SQL. Scrivere una query di esempio che combina entrambi i database.
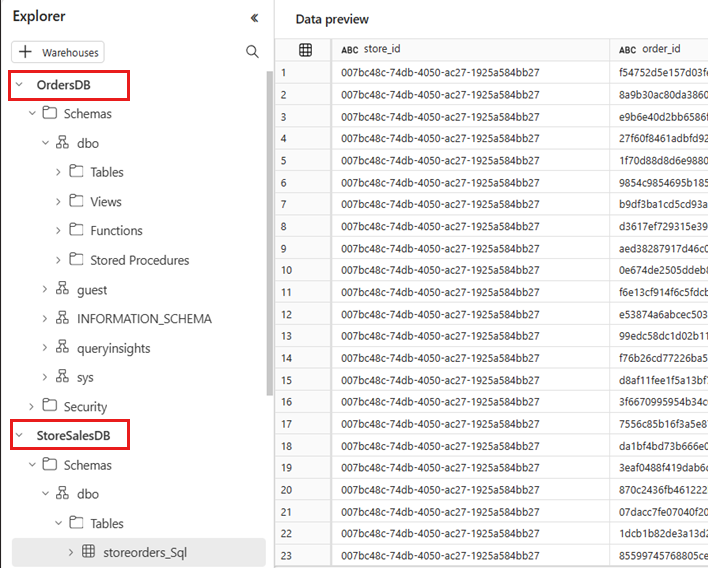
Ad esempio, questa query viene eseguita in più contenitori e database, senza alcun spostamento dei dati. In questo esempio si presuppone il nome della tabella e delle colonne. Usare tabelle e colonne personalizzate durante la scrittura della query SQL.
SELECT product_category_count = COUNT (product_category), product_category FROM [StoreSalesDB].[dbo].[storeorders_Sql] as StoreSales INNER JOIN [dbo].[OrdersDB_order_status] as OrderStatus ON StoreSales.order_id = OrderStatus.order_id WHERE order_status='delivered' AND OrderStatus.order_month_year > '6/1/2022' GROUP BY product_category ORDER BY product_category_count descÈ possibile aggiungere dati da altre origini ed eseguire query senza problemi. L'infrastruttura semplifica e semplifica l'interazione dei dati dell'organizzazione.

Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per