Procedura: Accedere ai dati di Azure Cosmos DB con mirroring in Lakehouse e ai notebook da Microsoft Fabric (anteprima)
Questa guida illustra come accedere ai dati di Azure Cosmos DB con mirroring in Lakehouse e ai notebook da Microsoft Fabric (anteprima).
Importante
Il mirroring per Azure Cosmos DB è attualmente in anteprima. I carichi di lavoro di produzione non sono supportati durante l'anteprima. Attualmente sono supportati solo gli account Azure Cosmos DB per NoSQL.
Prerequisiti
- Un account Azure Cosmos DB per NoSQL già presente.
- Se non si ha un abbonamento ad Azure, prova gratuitamente Azure Cosmos DB per NoSQL.
- Se si ha già un abbonamento ad Azure, creare un nuovo account Azure Cosmos DB per NoSQL.
- Capacità di Infrastruttura esistente. Se non si ha una capacità esistente, avviare una versione di valutazione di Fabric.
- Abilitare il mirroring nel tenant o nell'area di lavoro di Fabric. Se la funzionalità non è già abilitata, abilitare il mirroring nel tenant di Fabric.
- L'account Azure Cosmos DB per NoSQL deve essere configurato per il mirroring dell'infrastruttura. Per altre informazioni, vedere Requisiti dell'account.
Suggerimento
Durante l'anteprima pubblica, è consigliabile usare una copia di test o sviluppo dei dati di Azure Cosmos DB esistenti che possono essere ripristinati rapidamente da un backup.
Configurare il mirroring e i prerequisiti
Configurare il mirroring per il database NoSQL di Azure Cosmos DB. Se non si è certi di come configurare il mirroring, vedere l'esercitazione configurare il database con mirroring.
Passare al portale infrastruttura.
Creare una nuova connessione e un database con mirroring usando le credenziali dell'account Azure Cosmos DB.
Attendere che la replica finisca lo snapshot iniziale dei dati.
Accedere ai dati con mirroring in Lakehouse e ai notebook
Usare Lakehouse per estendere ulteriormente il numero di strumenti che è possibile usare per analizzare i dati con mirroring di Azure Cosmos DB per NoSQL. In questo caso si usa Lakehouse per creare un notebook Spark per eseguire query sui dati.
Passare di nuovo alla home page del portale di Infrastruttura.
Nel menu di spostamento selezionare Crea.
Selezionare Crea, individuare la sezione Ingegneria dei dati e quindi selezionare Lakehouse.
Specificare un nome per Lakehouse e quindi selezionare Crea.
Selezionare ora Recupera dati e quindi Nuovo collegamento. Nell'elenco delle opzioni di scelta rapida selezionare Microsoft OneLake.
Selezionare il database Di Azure Cosmos DB per NoSQL con mirroring nell'elenco dei database con mirroring nell'area di lavoro Infrastruttura. Selezionare le tabelle da usare con Lakehouse, selezionare Avanti e quindi crea.
Aprire il menu di scelta rapida per la tabella in Lakehouse e selezionare Notebook nuovo o esistente.
Viene aperto automaticamente un nuovo notebook e viene caricato un dataframe usando
SELECT LIMIT 1000.Eseguire query come
SELECT *l'uso di Spark.df = spark.sql("SELECT * FROM Lakehouse.OrdersDB_customers LIMIT 1000") display(df)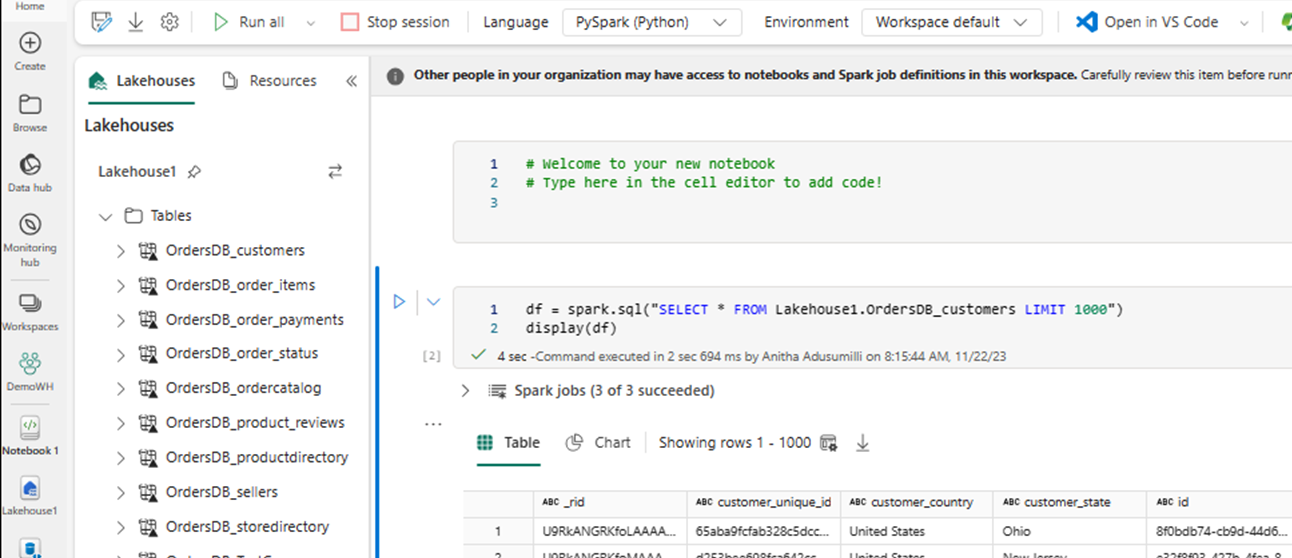
Nota
In questo esempio si presuppone il nome della tabella. Usare la propria tabella durante la scrittura della query Spark.

Eseguire il writeback con Spark
Infine, è possibile usare il codice Spark e Python per scrivere nuovamente i dati nell'account Azure Cosmos DB di origine dai notebook in Fabric. È possibile eseguire questa operazione per scrivere i risultati analitici in Cosmos DB, che possono quindi essere usati come piano di gestione per le applicazioni OLTP.
Creare quattro celle di codice all'interno del notebook.
Prima di tutto, eseguire una query sui dati con mirroring.
fMirror = spark.sql("SELECT * FROM Lakehouse1.OrdersDB_ordercatalog")Suggerimento
I nomi delle tabelle in questi blocchi di codice di esempio presuppongono uno schema di dati specifico. È possibile sostituirlo con i nomi di tabella e colonna personalizzati.
Ora trasformare e aggregare i dati.
dfCDB = dfMirror.filter(dfMirror.categoryId.isNotNull()).groupBy("categoryId").agg(max("price").alias("max_price"), max("id").alias("id"))Configurare quindi Spark per eseguire il writeback nell'account Azure Cosmos DB per NoSQL usando le credenziali, il nome del database e il nome del contenitore.
writeConfig = { "spark.cosmos.accountEndpoint" : "https://xxxx.documents.azure.com:443/", "spark.cosmos.accountKey" : "xxxx", "spark.cosmos.database" : "xxxx", "spark.cosmos.container" : "xxxx" }Infine, usare Spark per eseguire il writeback nel database di origine.
dfCDB.write.mode("APPEND").format("cosmos.oltp").options(**writeConfig).save()Eseguire tutte le celle di codice.
Importante
Le operazioni di scrittura in Azure Cosmos DB utilizzeranno le unità richiesta (UR).
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per