Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo documento fornisce linee guida specifiche per il ripristino dei dati Fabric in caso di disastro regionale.
Scenario di esempio
Molte sezioni di materiale sussidiario in questo documento usano lo scenario di esempio seguente ai fini della spiegazione e dell'illustrazione. Fare riferimento a questo scenario in base alle esigenze.
Si supponga di avere una capacità C1 nell'area A con un'area di lavoro W1. Se hai attivato il ripristino di emergenza per la capacità C1, i dati di OneLake vengono replicati in un backup nella regione B. Se la regione A subisce un'interruzione, il servizio Fabric in C1 esegue il failover nella regione B.
Nota
Queste indicazioni per il ripristino si applicano solo quando l'area primaria ha un'area secondaria associata Azure e Fabric è supportata nell'area abbinata.
Questo scenario è illustrato nell'immagine seguente. La casella a sinistra mostra l'area in cui si verifica l'interruzione. La casella al centro rappresenta la disponibilità continua dei dati dopo il failover e la casella a destra mostra la situazione completamente coperta dopo che il cliente agisce per ripristinare il funzionamento completo dei servizi.
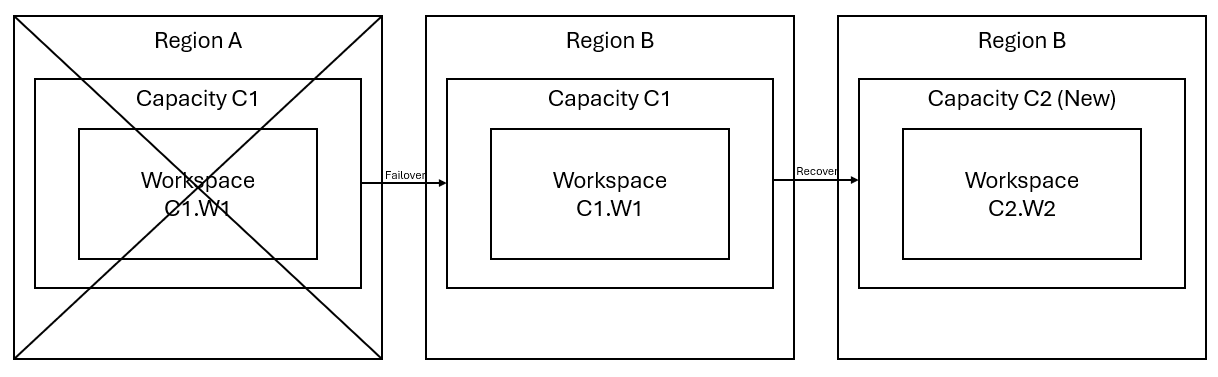
Ecco il piano di ripristino generale:
Creare una nuova capacità Fabric C2 in una nuova regione.
Creare una nuova area di lavoro W2 in C2, inclusi gli elementi corrispondenti con gli stessi nomi di C1.W1.
Copiare i dati dal C1.W1 interrotto al C2.W2.
Per ripristinare la piena funzionalità degli elementi, seguire le istruzioni dedicate per ciascun componente.
Questo piano di ripristino presuppone che la regione di origine del tenant rimanga operativa. Se l'area principale del tenant riscontra un'interruzione, i passaggi descritti in questo documento dipendono dal ripristino, che deve essere avviato e completato per la prima volta da Microsoft.
Piani di ripristino specifici per esperienza
Le sezioni seguenti forniscono guide dettagliate per ogni Fabric esperienza per aiutare i clienti attraverso il processo di ripristino.
Ingegneria dei dati
Questa guida illustra le procedure di ripristino per l'esperienza di ingegneria dei dati. Copre i data lakehouse, i notebook e le definizioni dei processi Spark.
Lakehouse
I lakehouse dell'area originale rimangono non disponibili per i clienti. Per ripristinare un lakehouse, i clienti possono ricrearlo nell'area di lavoro C2.W2. È consigliabile adottare due approcci per il recupero di lakehouse:
Approccio 1: usare uno script personalizzato per copiare tabelle e file Lakehouse Delta
I clienti possono ricreare i lakehouses usando uno script Scala personalizzato.
Creare il lakehouse (ad esempio, LH1) nell'area di lavoro appena creata C2.W2.
Creare un nuovo notebook nell'area di lavoro C2.W2.
Per ripristinare le tabelle e i file dal lakehouse originale, fare riferimento ai dati utilizzando percorsi di OneLake, come abfss (vedere Connessione a Microsoft OneLake). È possibile usare l'esempio di codice seguente (vedere Introduzione a Microsoft Spark Utilities) nel notebook per ottenere i percorsi ABFS di file e tabelle dal lakehouse originale. (Sostituisci C1. W1 con il nome effettivo dell'area di lavoro)
notebookutils.fs.ls('abfs[s]://<C1.W1>@onelake.dfs.fabric.microsoft.com/<item>.<itemtype>/<Tables>/<fileName>')Usare l'esempio di codice seguente per copiare tabelle e file nel lakehouse appena creato.
Per le tabelle Delta, è necessario copiare una tabella alla volta per ripristinarla nel nuovo lakehouse. Nel caso dei file Lakehouse, è possibile copiare la struttura di file completa con tutte le cartelle sottostanti con una singola esecuzione.
Contatta il team di supporto per ottenere il timestamp del failover necessario nello script.
%%spark val source="abfs path to original Lakehouse file or table directory" val destination="abfs path to new Lakehouse file or table directory" val timestamp= //timestamp provided by Support notebookutils.fs.cp(source, destination, true) val filesToDelete = notebookutils.fs.ls(s"$source/_delta_log") .filter{sf => sf.isFile && sf.modifyTime > timestamp} for(fileToDelete <- filesToDelete) { val destFileToDelete = s"$destination/_delta_log/${fileToDelete.name}" println(s"Deleting file $destFileToDelete") notebookutils.fs.rm(destFileToDelete, false) } notebookutils.fs.write(s"$destination/_delta_log/_last_checkpoint", "", true)Dopo aver eseguito lo script, le tabelle vengono visualizzate nella nuova lakehouse.
Approccio 2: Usare Azure Storage Explorer per copiare file e tabelle
Per recuperare file o tabelle specifici dalla lakehouse originale, usare Azure Storage Explorer. Per informazioni dettagliate, vedere Integrate OneLake con Azure Storage Explorer. Per grandi dimensioni di dati, utilizzare l'approccio 1.
Nota
I due approcci descritti in precedenza recuperano sia i metadati che i dati per le tabelle in formato Delta, perché i metadati si trovano in modalità condivisa e archiviati con i dati in OneLake. Per le tabelle formattate non Delta (ad esempio, CSV, Parquet e così via) create usando script/comandi DDL (Spark Data Definition Language), l'utente è responsabile della gestione e della ripetizione dei comandi/script DDL Spark per recuperarli.
Recupero di viste del lago materializzate di Fabric
Le viste materializzate di Lake dell'area originale continuano a non essere disponibili per i clienti dopo il failover. Le pianificazioni degli aggiornamenti e la cronologia di esecuzione non vengono replicate nell'area secondaria. Per recuperarli, completare i passaggi seguenti dopo aver recuperato i dati di Lakehouse.
- Ripristinare le tabelle Lakehouse usando l'approccio 1 o l'approccio 2 descritto in precedenza. Copiare solo le tabelle di origine.
- Recupera i notebook che contengono le definizioni MLV. Fare riferimento alla sezione Notebook per i passaggi di ripristino.
- Eseguire i notebook ripristinati per ricreare gli MLV nel nuovo Lakehouse. Per informazioni sulla creazione di MLV, vedere Creare una Lake View materializzata. Se le MLV sono state copiate anche nel passaggio precedente, eseguire CREATE OR REPLACE nel momento in cui li si ricrea.
- Ricreare manualmente le operazioni di aggiornamento MLV nella nuova area di lavoro. La cronologia di pianificazione e le metriche di esecuzione non sono recuperabili.
- Se i feed MLV forniscono dati ai modelli semantici o ai report, verificare e aggiornare i riferimenti all'ID Lakehouse e all'ID del set di dati in base alle esigenze. Riconnettere i report al modello semantico aggiornato e convalidare l'aggiornamento dei dati.
Suggerimento
Per ridurre al minimo le modifiche al codice durante l'esecuzione di notebook dopo il failover, usare gli stessi nomi di area di lavoro e Lakehouse nella nuova area di lavoro(in particolare quando si usa il nome Area di lavoro o Lakehouse nelle convenzioni di denominazione). Le pianificazioni di aggiornamento, la cronologia di esecuzione e le metriche operative iniziano di nuovo nell'area ripristinata. Pianificare un periodo di riferimento quando si stabiliscono nuove soglie di monitoraggio.
Notebook
I notebook dell'area primaria rimangono non disponibili per i clienti e il codice nei notebook non viene replicato nell'area secondaria. Per ripristinare il codice notebook nella nuova area, sono disponibili due approcci per ripristinarne il contenuto.
Approccio 1: ridondanza gestita dall'utente con l'integrazione Git (in anteprima pubblica)
Il modo migliore per renderlo facile e rapido consiste nell'usare l'integrazione di Fabric Git, quindi sincronizzare il notebook con il repository ADO. Dopo il failover del servizio in un'altra area, è possibile usare il repository per ricompilare il notebook nella nuova area di lavoro creata.
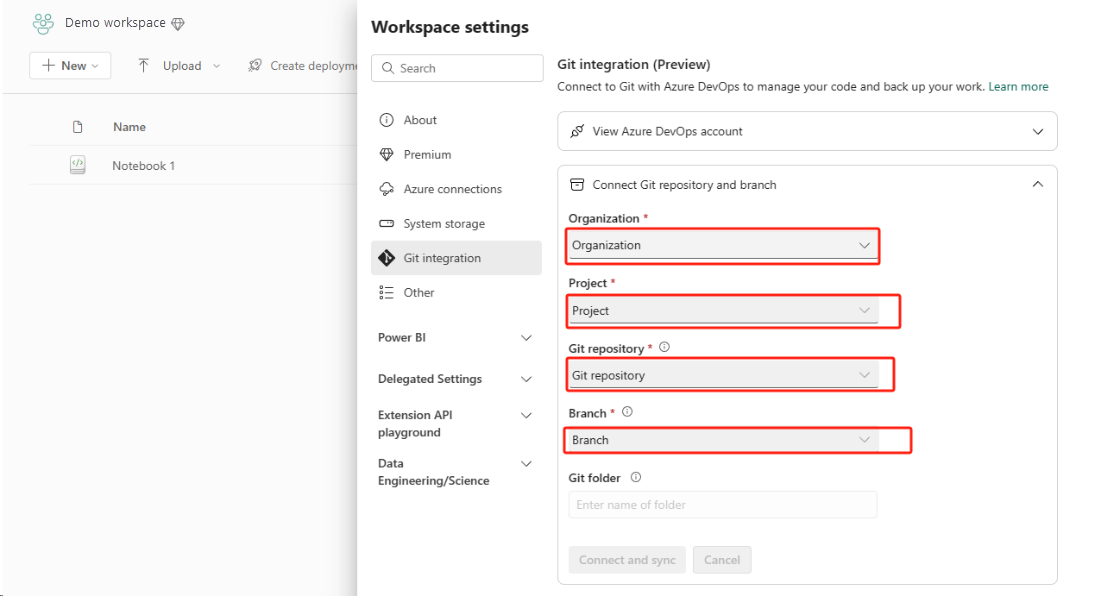
Configurare l'integrazione Git per l'area di lavoro e selezionare Connetti e sincronizza con il repository ADO.
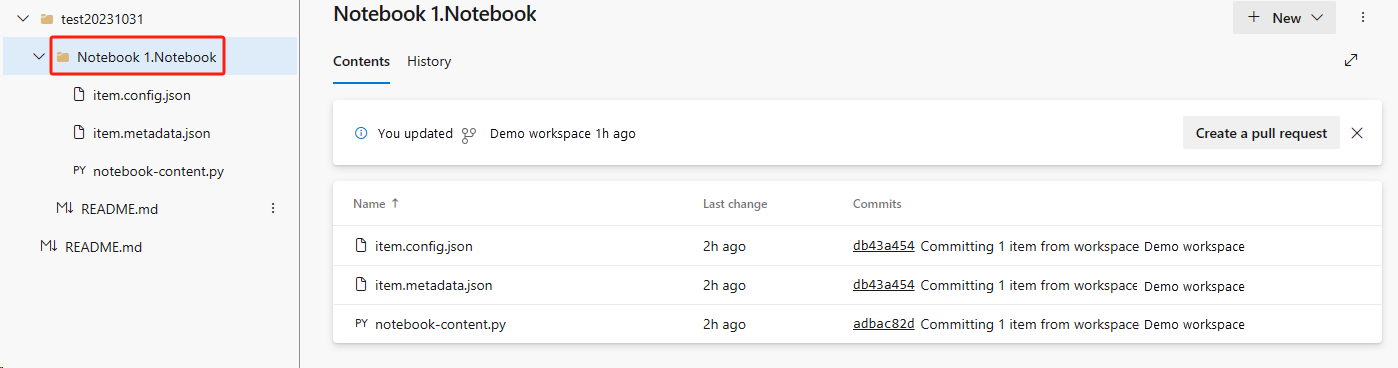
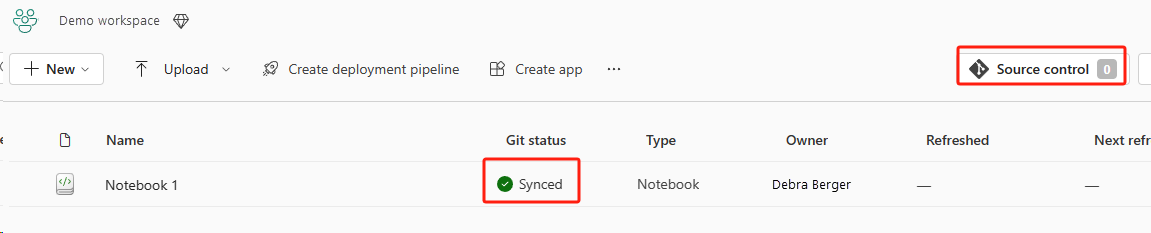
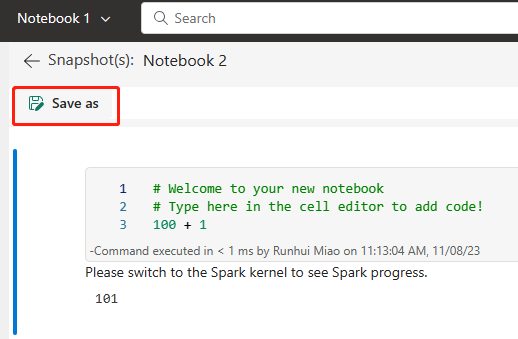
L'immagine seguente mostra il notebook sincronizzato.
Ripristinare il notebook dal repository ADO.
Nell'area di lavoro appena creata connettersi di nuovo al repository ADO Azure.
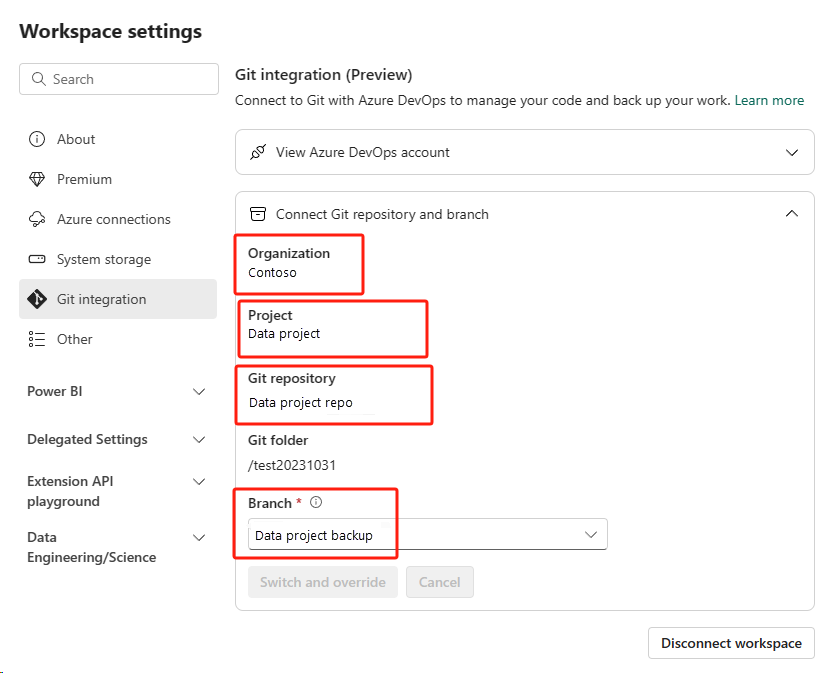
Selezionare il pulsante Controllo del codice sorgente. Selezionare quindi il ramo pertinente del repository. Quindi, selezionare Aggiorna tutto. Viene visualizzato il notebook originale.
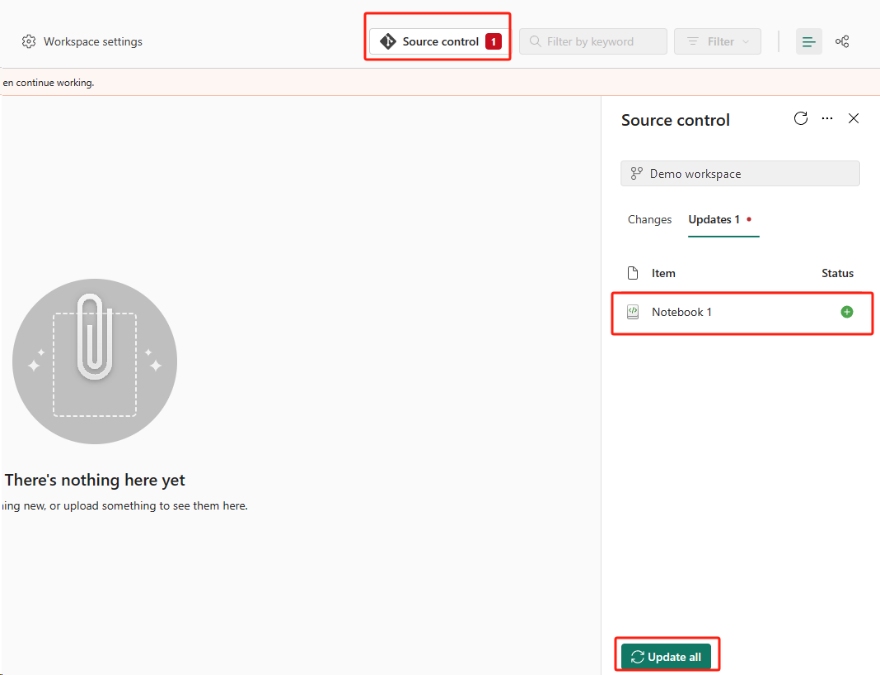
Se il notebook originale ha un lakehouse predefinito, gli utenti possono fare riferimento alla sezione Lakehouse per recuperarlo e quindi connettere il lakehouse appena ripristinato al notebook appena ripristinato.
L'integrazione Git non supporta la sincronizzazione di file, cartelle o snapshot del notebook in Esplora risorse del notebook.
Se il notebook originale contiene file in Esplora risorse del notebook:
Assicurarsi di salvare i file o le cartelle su un disco locale o in un'altra posizione.
Caricare nuovamente il file dal disco locale o dalle unità cloud nel notebook ripristinato.
Se esiste uno snapshot del notebook originale, salvare anche questo nel sistema di controllo della versione o sul disco locale.
Per maggiori informazioni sull'integrazione Git, vedere Introduzione all'integrazione Git.
Approccio 2: approccio manuale al backup del contenuto del codice
Se non si usa l'approccio di integrazione Git, è possibile salvare la versione più recente del codice, i file in Esplora risorse e lo snapshot del notebook in un sistema di controllo della versione, ad esempio Git, e ripristinare manualmente il contenuto del notebook dopo un'emergenza:
Usare la funzionalità "Importa notebook" per importare il codice del notebook da ripristinare.
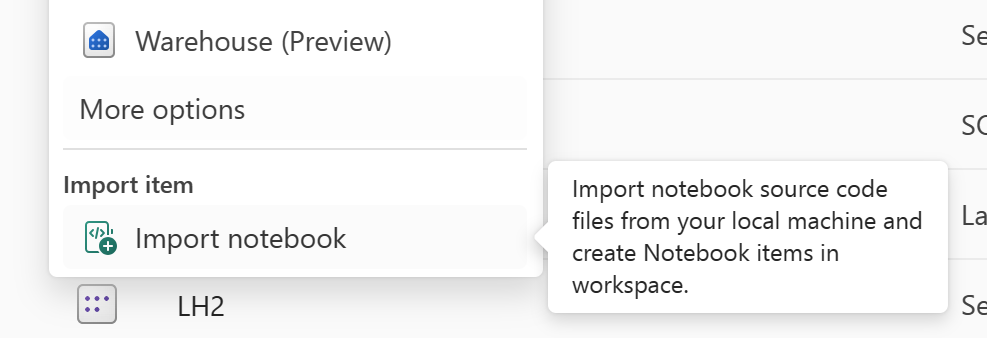
Dopo l'importazione, passare all'area di lavoro desiderata (ad esempio "C2.W2") per accedervi.
Se il notebook originale ha un lakehouse predefinito, fare riferimento alla sezione Lakehouse. Connettere quindi il lakehouse appena ripristinato (con lo stesso contenuto del lakehouse predefinito originale) al notebook appena ripristinato.
Se il notebook originale contiene file o cartelle in Esplora risorse, caricare nuovamente i file o le cartelle salvati nel sistema di controllo della versione dell'utente.
Definizione di lavoro Spark
Le definizioni dei processi Spark (SJD) dall'area primaria rimangono non disponibili per i clienti e il file di definizione principale e il file di riferimento nel notebook verranno replicati nell'area secondaria tramite OneLake. Se si vuole ripristinare l'SJD nella nuova area, è possibile seguire i passaggi manuali descritti di seguito per ripristinare l'SJD. Le esecuzioni storiche del SJD non verranno recuperate.
È possibile ripristinare gli elementi SJD copiando il codice dall'area originale usando Azure Storage Explorer e riconnettendo manualmente i riferimenti lakehouse dopo l'emergenza.
Creare un nuovo elemento SJD (ad esempio, SJD1) nella nuova area di lavoro C2.W2, con le stesse impostazioni e configurazioni dell'elemento SJD originale (ad esempio, linguaggio, ambiente e così via).
Usare Azure Storage Explorer per copiare lib, main e snapshot dall'elemento SJD originale al nuovo elemento SJD.
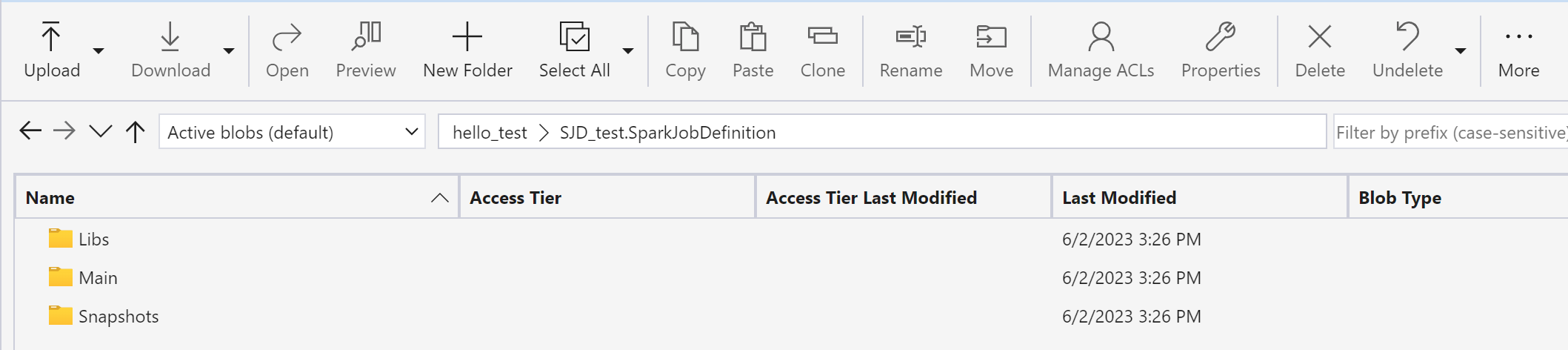
Il contenuto del codice verrà visualizzato nell'SJD appena creato. È necessario aggiungere manualmente il riferimento Lakehouse appena ripristinato al processo (vedere i Passaggi di ripristino di Lakehouse). Gli utenti dovranno immettere nuovamente manualmente gli argomenti della riga di comando originali.
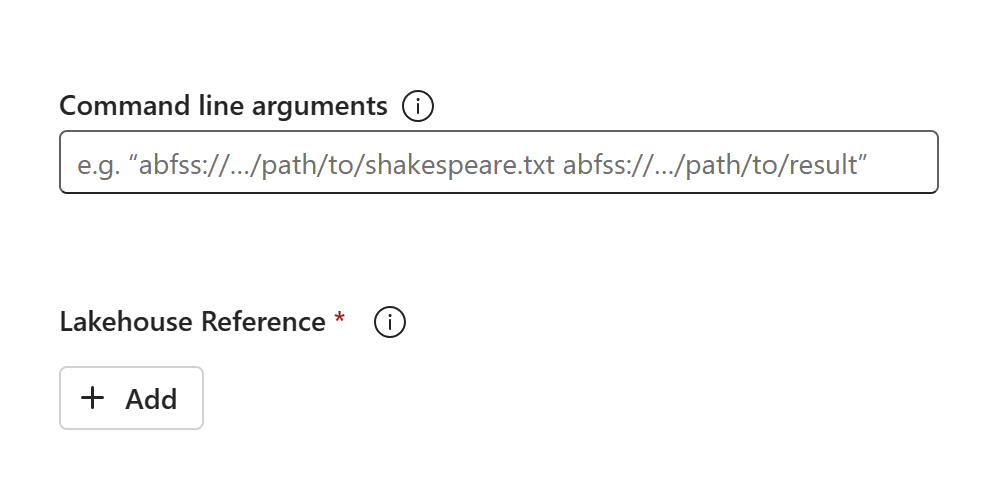
È ora possibile eseguire o pianificare il nuovo SJD ripristinato.
Per informazioni dettagliate sulle Azure Storage Explorer, vedere Integrate OneLake con Azure Storage Explorer.
Data science
Questa guida illustra le procedure di ripristino per l'esperienza di data science. Vengono illustrati i modelli e gli esperimenti di Machine Learning.
Modello ed esperimento di Machine Learning
Gli elementi di data science dell'area primaria rimangono non disponibili per i clienti e il contenuto e i metadati nei modelli di Machine Learning e gli esperimenti non verranno replicati nell'area secondaria. Per ripristinarli completamente nella nuova area, salvare il contenuto del codice in un sistema di controllo della versione (ad esempio Git) ed eseguire manualmente il contenuto del codice dopo l'emergenza.
Recuperare il notebook. Fare riferimento ai Passaggi di ripristino del notebook.
La configurazione, le metriche eseguite in passato e i metadati non verranno replicati nell'area abbinata. Sarà necessario rieseguire ogni versione del codice di data science per ripristinare completamente i modelli e gli esperimenti di Machine Learning dopo l'emergenza.
Data Warehouse
Questa guida illustra le procedure di ripristino per l'esperienza di Data Warehouse. Copre i magazzini.
Magazzino
I magazzini della regione originale rimangono non disponibili per i clienti. Per recuperare i magazzini, eseguire i seguenti due passaggi.
Creare un nuovo lakehouse provvisorio nell'area di lavoro C2.W2 per i dati che copierai dal data warehouse originale.
Popolare le tabelle Delta del magazzino utilizzando Esplora magazzino e le funzionalità T-SQL (vedere Tables in data warehousing in Microsoft Fabric).
Nota
È consigliabile mantenere il codice del data warehouse (schema, tabella, vista, stored procedure, definizioni di funzione e codici di sicurezza) con controllo delle versioni e salvato in una posizione sicura (ad esempio Git) in base alle procedure di sviluppo.
Inserimento di dati tramite Lakehouse e codice T-SQL
Nell'area di lavoro appena creata C2.W2:
Creare un lakehouse provvisorio "LH2" in C2.W2.
Recuperare le tabelle Delta nel lakehouse temporaneo dal Data Warehouse originale seguendo i Passaggi di ripristino di Lakehouse.
Creare un nuovo warehouse "WH2" in C2.W2.
Connetti il lakehouse provvisorio nell'Explorer del magazzino.
A seconda della modalità di distribuzione delle definizioni di tabella prima dell'importazione dei dati, il T-SQL effettivo usato per le importazioni può variare. È possibile usare l'approccio INSERT INTO, SELECT INTO o CREATE TABLE AS SELECT per ripristinare le tabelle warehouse dai lakehouse. Più avanti nell'esempio si usa la versione INSERT INTO. Se si usa il codice seguente, sostituire gli esempi con i nomi effettivi di tabella e colonna.
USE WH1 INSERT INTO [dbo].[aggregate_sale_by_date_city]([Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit]) SELECT [Date],[City],[StateProvince],[SalesTerritory],[SumOfTotalExcludingTax],[SumOfTaxAmount],[SumOfTotalIncludingTax], [SumOfProfit] FROM [LH11].[dbo].[aggregate_sale_by_date_city] GOInfine, devi modificare la stringa di connessione nelle applicazioni usando il data warehouse di Fabric.
Nota
Per i clienti che necessitano di ripristino di emergenza tra aree e continuità aziendale completamente automatizzata, è consigliabile mantenere due configurazioni di Fabric Warehouse in aree Fabric separate e mantenere la parità di codice e dati eseguendo distribuzioni regolari e inserimento di dati in entrambi i siti.
Il database con mirroring
I database specchiati dall'area primaria continuano a non essere disponibili per i clienti e le impostazioni del database non vengono replicate nell'area secondaria. Per ripristinarlo in caso di errore a livello di area, è necessario ricreare il database con mirroring in un'altra area di lavoro da un'area diversa.
Data Factory
Gli elementi di Data Factory dell'area primaria rimangono non disponibili per i clienti e le impostazioni e la configurazione nelle pipeline o negli elementi di dataflow gen2 non verranno replicati nell'area secondaria. Per ripristinare questi elementi in caso di errore a livello di area, è necessario ricreare gli elementi di integrazione dei dati in un'altra area di lavoro da un'area diversa. Nelle sezioni seguenti vengono offerte informazioni dettagliate in proposito.
Flussi di dati Gen2
Se si vuole ripristinare un elemento Dataflow Gen2 nella nuova area, è necessario esportare un file PQT in un sistema di controllo della versione, ad esempio Git, e quindi ripristinare manualmente il contenuto di Dataflow Gen2 dopo l'emergenza.
Dall'elemento Dataflow Gen2, nella scheda Home dell'editor di Power Query selezionare Esporta modello.
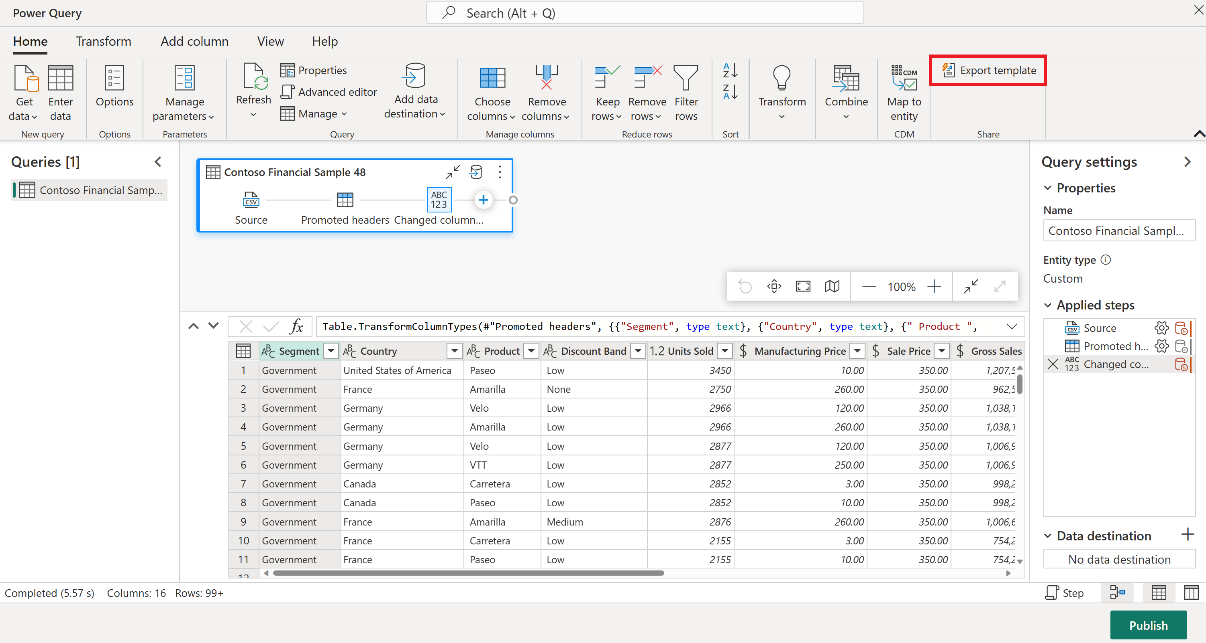
Nella finestra di dialogo Esporta modello immettere un nome (obbligatorio) e una descrizione (facoltativa) per questo modello. Al termine, seleziona OK.
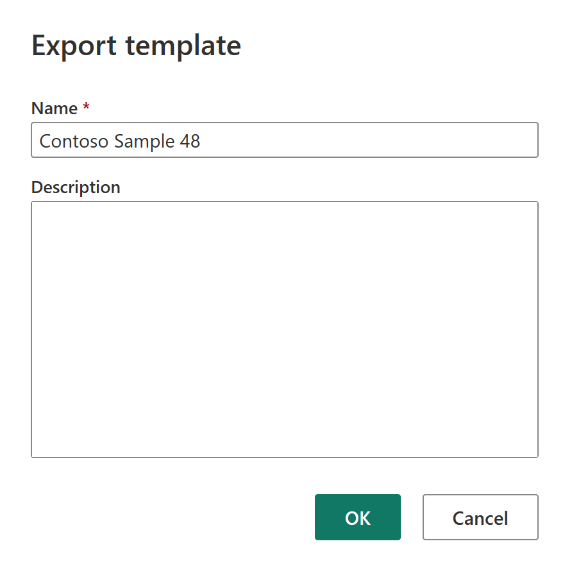
Dopo l'emergenza, creare un nuovo elemento Dataflow Gen2 nella nuova area di lavoro "C2.W2".
Nel riquadro di visualizzazione corrente dell'editor di Power Query selezionare Importa da un modello di Power Query.
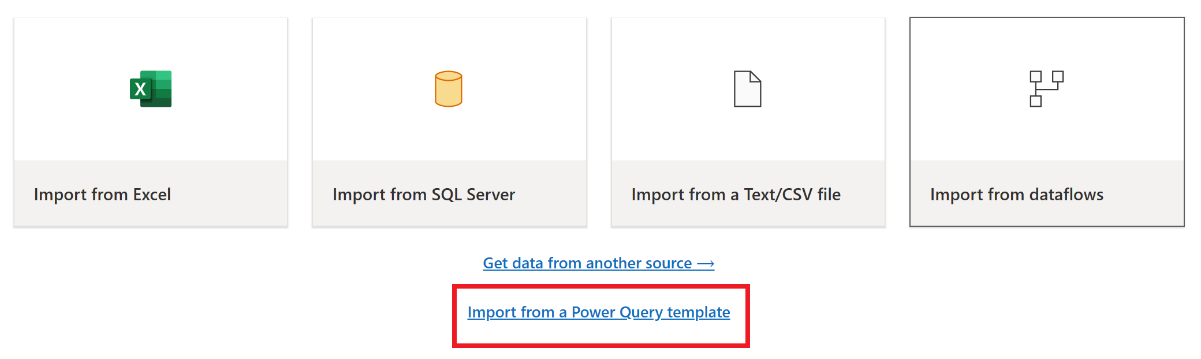
Nella finestra di dialogo Apri, accedere alla cartella di download predefinita e selezionare il file con estensione pqt salvato nei passaggi precedenti. Quindi selezionare Apri.
Il modello viene quindi importato nel nuovo elemento Dataflow Gen2.
La funzionalità Salva con nome dei flussi di dati non è supportata in caso di ripristino di emergenza.
Pipelines
I clienti non possono accedere alle pipeline in caso di emergenza a livello di area e le configurazioni non vengono replicate nell'area abbinata. È consigliabile creare pipeline critiche in più aree di lavoro in aree diverse.
Operazione di copia
Gli utenti CopyJob devono intraprendere misure proattive per proteggersi da un'emergenza regionale. L'approccio seguente garantisce che, dopo un disastro regionale, i CopyJobs di un utente rimangano disponibili.
Ridondanza gestita dall'utente con l'integrazione Git (in anteprima pubblica)
Il modo migliore per semplificare e velocizzare questo processo consiste nell'usare l'integrazione Git di Fabric, quindi sincronizzare CopyJob con il repo ADO. Dopo il failover del servizio in un'altra area, è possibile usare il repository per ricompilare CopyJob nella nuova area di lavoro creata.
Configura l'integrazione Git dell'area di lavoro e seleziona connetti e sincronizza con il repository ADO.
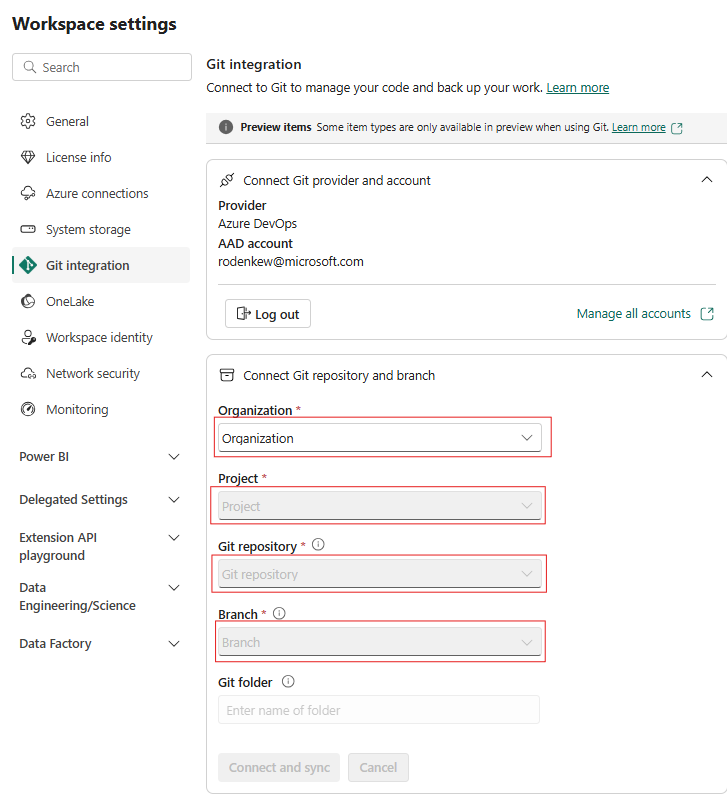
L'immagine seguente mostra il CopyJob sincronizzato.
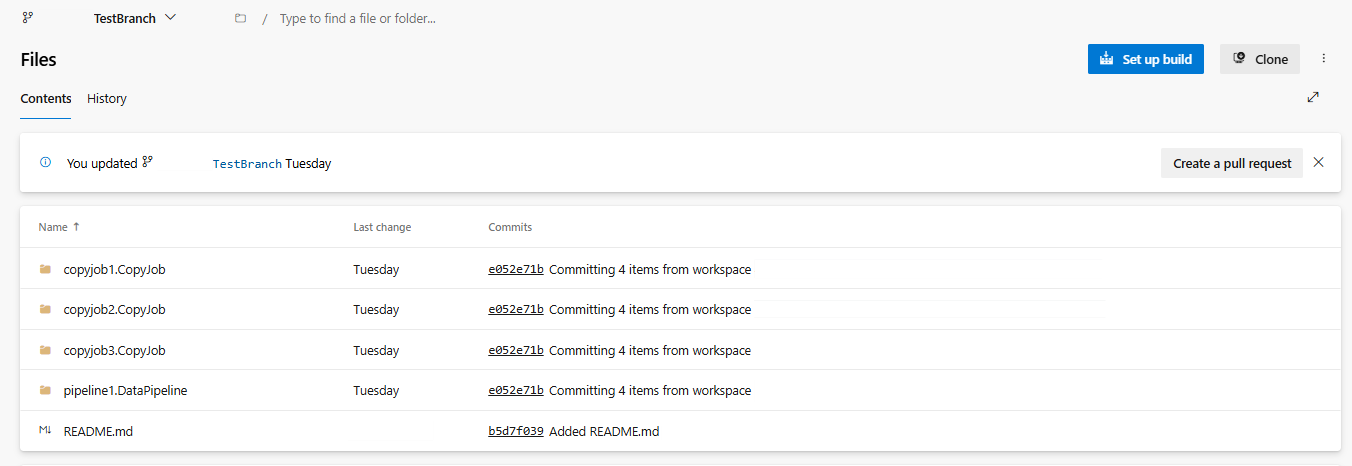
Ripristinare CopyJob dal repository ADO.
Nell'area di lavoro appena creata, collegarsi e sincronizzare nuovamente il repo Azure ADO. Tutti gli elementi Fabric in questo repository vengono scaricati automaticamente nella nuova area di lavoro.
Se l'originale CopyJob utilizza una Lakehouse, gli utenti possono fare riferimento alla sezione Lakehouse per recuperare la Lakehouse e quindi connettere il CopyJob appena recuperato alla Lakehouse appena recuperata.
Per maggiori informazioni sull'integrazione Git, vedere Introduzione all'integrazione Git.
Attività Apache Airflow
Gli utenti di Apache Airflow Job in Fabric devono intraprendere misure proattive per proteggersi da un disastro regionale.
Si consiglia di gestire la ridondanza con l'integrazione di Fabric con Git. Prima di tutto, sincronizzare il processo Airflow con il repository ADO. Se il servizio esegue il failover in un'altra area, è possibile usare il repository per ricompilare il processo Airflow nella nuova area di lavoro creata.
Ecco i passaggi per ottenere questo risultato:
Configurare l'integrazione Git dell'area di lavoro e selezionare "Connetti e sincronizza" con il repository ADO.
Successivamente, si noterà che il processo Airflow è stato sincronizzato con il repository ADO.
Se è necessario ripristinare il processo Airflow dal repository ADO, creare una nuova area di lavoro, connettersi e sincronizzare nuovamente il repository ADO Azure. Tutti gli elementi Fabric, incluso Airflow, in questo repository verranno scaricati automaticamente nella tua nuova area di lavoro.
Intelligence in tempo reale
Questa guida illustra le procedure di ripristino per l'esperienza di intelligence in tempo reale. Vengono illustrati database/set di query KQL e eventstream.
Modello grafico/Set di query
Gli elementi Graph Model e Graph Queryset dall'area primaria rimangono non disponibili per i clienti e questi elementi non vengono replicati nell'area secondaria. Per procedere al recupero, creazione o utilizzo di una capacità in una regione differente, è necessario ricreare gli elementi Graph Model e Graph Queryset in quella posizione.
Creare o usare una capacità di Fabric esistente in un'area diversa che non è interessata dall'emergenza.
Creare una nuova area di lavoro o usare un'area di lavoro esistente in tale capacità.
Ricreare l'elemento Modello grafico nell'area di lavoro secondaria (a cui si fa riferimento nel passaggio 2). Riconfigurare la definizione del modello, inclusi nodi, archi e così via, in modo che corrisponda al modello grafico originale.
Se la lakehouse originale si trova nell'area di errore, recuperarla prima seguendo la sezione Lakehouse.
Connettere una Lakehouse come origine dati OneLake per il nuovo elemento del modello Graph appena creato. Utilizzare il lakehouse recuperato se si trovava nell'area in panne, oppure riconnettersi al lakehouse esistente, se ancora disponibile.
Riconfigurare le pianificazioni o le connessioni di caricamento dei dati per il modello Graph nella nuova area di lavoro.
Ricreare l'elemento Graph Queryset nell'area di lavoro secondaria. Immettere manualmente le query e le eventuali configurazioni di query salvate dall'insieme di query Graph originale.
Database/set di query KQL
Gli utenti del database/queryset KQL devono intraprendere misure proattive per proteggersi da un disastro regionale. L'approccio seguente garantisce che, in caso di emergenza a livello di area, i dati nei set di query dei database KQL rimangano sicuri e accessibili.
Usare la procedura seguente per garantire una soluzione di ripristino di emergenza efficace per i database e i set di query KQL.
Stabilire database KQL indipendenti: configurare due o più database/set di query KQL indipendenti su capacità dedicate di Fabric. Devono essere configurati in due aree Azure diverse (preferibilmente aree abbinate di Azure) per ottimizzare la resilienza.
Replicare le attività di gestione: qualsiasi azione di gestione eseguita in un database KQL deve essere replicata nell'altro. In questo modo entrambi i database rimangono sincronizzati. Le attività principali da replicare includono:
Tabelle: assicurarsi che le strutture di tabella e le definizioni dello schema siano coerenti tra i database.
Mapping: duplicare tutti i mapping necessari. Assicurarsi che le origini dati e le destinazioni siano allineate correttamente.
Criteri: assicurarsi che entrambi i database abbiano criteri simili in materia di conservazione dei dati, accesso e altri criteri pertinenti simili.
Gestire l'autenticazione e l'autorizzazione: per ogni replica, configurare le autorizzazioni necessarie. Assicurarsi che vengano stabiliti livelli di autorizzazione appropriati, concedendo l'accesso al personale richiesto e mantenendo gli standard di sicurezza.
Inserimento di dati parallelo: per mantenere i dati coerenti e pronti in più aree, caricare lo stesso set di dati in ogni database KQL contemporaneamente all'inserimento.
Eventstream
Un flusso di eventi è una posizione centralizzata nella piattaforma Fabric per l'acquisizione, la trasformazione e il routing di eventi in tempo reale a varie destinazioni (ad esempio, lakehouse, database KQL/queryset) con un'esperienza senza codice. Finché le destinazioni sono supportate dal ripristino di emergenza, gli eventstream non perderanno dati. Pertanto, i clienti devono usare le funzionalità di ripristino di emergenza di tali sistemi di destinazione per garantire la disponibilità dei dati.
I clienti possono anche ottenere la ridondanza geografica distribuendo carichi di lavoro Eventstream identici in più aree Azure come parte di una strategia attiva/attiva multisito. Grazie all'approccio attivo/attivo multi-sito, i clienti possono accedere al proprio carico di lavoro in una qualsiasi delle aree distribuite. Questo approccio è il più complesso e costoso per il ripristino di emergenza, ma nella maggior parte delle situazioni può ridurre i tempi di ripristino quasi a zero. Per avere una ridondanza geografica completa, i clienti possono
Creare repliche delle origini dati in aree diverse.
Creare elementi Eventstream nelle aree corrispondenti.
Connettere questi nuovi elementi alle origini dati identiche.
Aggiungere destinazioni identiche per ogni eventstream in aree diverse.
Map
Gli elementi mappati dall'area primaria rimangono non disponibili per i clienti e gli elementi della mappa non vengono replicati nell'area secondaria.
Se si desidera ripristinare un elemento della Mappa in caso di emergenza, configurare l'integrazione Fabric Git e sincronizzare l'elemento Mappa con il repository Git.
Durante il ripristino, dopo aver configurato la nuova area o la nuova capacità in Fabric, è possibile usare il repository per ricompilare l'elemento mappa nella nuova area di lavoro creata. Poiché la nuova area di lavoro è vuota, Git sync ottiene il contenuto dal repository nell'area di lavoro vuota. Questo passaggio riporta l'elemento Map in vita.
Nota
Se l'elemento map originale include un set di query lakehouse o KQL configurato, fare riferimento alla sezione Lakehouse e alla sezione queryset KQL per recuperarli per primi. Dopo che queste dipendenze sono state prese in considerazione, connettere il lakehouse appena ripristinato e il set di query all'elemento Map appena ripristinato.
Ontologia
Gli utenti di ontologia devono adottare misure proattive per prepararsi al recupero dai disastri regionali. L'approccio descritto di seguito garantisce che, in seguito a un disastro regionale, la tua Ontologia rimanga recuperabile e possa essere ripristinata rapidamente.
Il modo più semplice e rapido per abilitare il ripristino consiste nell'usare l'integrazione Fabric Git e sincronizzare l'ontologia con un repository di Azure DevOps (ADO). Se il servizio esegue il failover in un'altra area, è possibile usare questo repository per ricompilare l'ontologia in un'area di lavoro appena creata.
Gli elementi di ontologia nell'area primaria non sono disponibili per i clienti dopo un'emergenza a livello di area e gli elementi di ontologia non vengono replicati nell'area secondaria.
Per ripristinare un elemento Ontologia durante un'emergenza, configurare l'integrazione Git di Fabric e sincronizzare l'elemento Ontologia con il repository ADO in anticipo.
Durante il ripristino, dopo aver configurato la nuova area e la nuova capacità in Fabric, è possibile usare il repository per ricompilare l'elemento Ontology in una nuova area di lavoro. Poiché la nuova area di lavoro è vuota, Git sync esegue il pull del contenuto dal repository nell'area di lavoro, ripristinando in modo efficace l'elemento Ontology.
Nota
Se l'elemento ontologia originale ha una lakehouse configurata, fare riferimento alla sezione Lakehouse per recuperare la lakehouse prima. Dopo che tali dipendenze sono state prese in considerazione, collegare il Lakehouse appena ripristinato all'elemento Ontologia appena ripristinato.
Database transazionale
In questa guida vengono descritte le procedure di ripristino per l'esperienza del database transazionale.
SQL database
Per proteggersi da un errore a livello di area, gli utenti dei database SQL possono adottare misure proattive per esportare periodicamente i dati e usare i dati esportati per ricreare il database in una nuova area di lavoro quando necessario.
A tale scopo, è possibile usare lo strumento dell'interfaccia della riga di comando di SqlPackage che fornisce la portabilità del database e facilita le distribuzioni di database.
- Usare lo strumento SqlPackage per esportare il database in un
.bacpacfile. Per altri dettagli, vedere Esportare un database con SqlPackage . - Archiviare il
.bacpacfile in un percorso sicuro che si trova in un'area diversa rispetto al database. Gli esempi includono l'archiviazione del file.bacpacin un lakehouse che si trova in un'area diversa, usando un account Azure Storage con ridondanza geografica o usando un altro supporto di archiviazione sicuro che si trova in un'area diversa. - Se il database SQL e l'area non sono disponibili, è possibile usare il
.bacpacfile con SqlPackage per ricreare il database in un'area di lavoro in una nuova area - Area di lavoro C2. W2 nell'area B come descritto nello scenario precedente. Seguire i passaggi descritti in Importare un database con SqlPackage per ricreare il database con il.bacpacfile.
Il database ricreato è un database indipendente dal database originale e riflette lo stato dei dati al momento dell'operazione di esportazione.
Considerazioni sul failback
Il database ricreato è un database indipendente. I dati aggiunti al database ricreato non vengono riflessi nel database originale. Se si prevede di eseguire il failback nel database originale quando l'area principale diventa disponibile, sarà necessario prendere in considerazione la riconciliazione manuale dei dati dal database ricreato al database originale.
Platform
La piattaforma fa riferimento ai servizi condivisi e all'architettura sottostanti applicabili a tutti i carichi di lavoro. Questa sezione illustra le procedure di ripristino per le esperienze condivise. Copre le librerie di variabili.
Libreria di variabili
Microsoft Fabric librerie variabili consentono agli sviluppatori di personalizzare e condividere le configurazioni degli elementi all'interno di un'area di lavoro, semplificando la gestione del ciclo di vita del contenuto. Dal punto di vista del ripristino di emergenza, gli utenti della libreria delle variabili devono proteggere in modo proattivo contro un disastro regionale. Questa operazione può essere eseguita tramite l'integrazione di Fabric Git, che garantisce che dopo un'emergenza a livello di area rimanga disponibile la libreria delle variabili di un utente. Per ripristinare una libreria di variabili, è consigliabile:
Usare l'integrazione Git di Fabric per sincronizzare la libreria delle variabili con il repository ADO. In caso di emergenza, è possibile usare il repository per ricompilare la libreria delle variabili nella nuova area di lavoro creata. Seguire questa procedura:
- Connettere l'area di lavoro al repository Git come descritto qui.
- Assicurarsi di mantenere WS e il repository sincronizzato con commit e aggiornamento.
- Ripristino: in caso di emergenza, usare il repository per ricompilare la libreria di variabili in una nuova area di lavoro:
Nell'area di lavoro appena creata, collegarsi e sincronizzare nuovamente il repo Azure ADO.
Tutti gli elementi Fabric in questo repository vengono scaricati automaticamente nella nuova area di lavoro.
Dopo aver sincronizzato gli elementi da Git, aprire le librerie di variabili nella nuova area di lavoro e selezionare manualmente il valore attivo desiderato.
Chiavi gestite dal cliente per aree di lavoro Fabric
È possibile usare chiavi gestite dal cliente (CMK) archiviate in Azure Key Vault per aggiungere un ulteriore livello di crittografia su chiavi gestite da Microsoft per i dati inattivi. Nel caso in cui Fabric diventi inaccessibile o inoperabile in un'area, i relativi componenti eseguiranno il failover in un'istanza di backup. Durante il failover, la funzionalità CMK supporta operazioni di sola lettura. Finché il servizio Azure Key Vault rimane integro e le autorizzazioni per il vault sono intatte, Fabric continuerà a connettersi alla tua chiave e permetterà di leggere normalmente i dati. Ciò significa che le operazioni seguenti non sono supportate durante il failover: l'abilitazione e la disabilitazione dell'impostazione cmk dell'area di lavoro e l'aggiornamento della chiave.