Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
La funzione è una funzione dbscan_fl() definita dall'utente che raggruppa un set di dati usando l'algoritmo DBSCAN.
Prerequisiti
- Il plug-in Python deve essere abilitato nel cluster. Questa operazione è necessaria per Python inline usato nella funzione .
- Il plug-in Python deve essere abilitato nel database. Questa operazione è necessaria per Python inline usato nella funzione .
Sintassi
T | invoke dbscan_fl(funzionalità, cluster_col metric_params, metriche, min_samples epsilon, , )
Altre informazioni sulle convenzioni di sintassi.
Parametri
| Nome | Digita | Obbligatorio | Descrizione |
|---|---|---|---|
| features | dynamic |
✔️ | Matrice contenente i nomi delle colonne delle funzionalità da usare per il clustering. |
| cluster_col | string |
✔️ | Nome della colonna in cui archiviare l'ID del cluster di output per ogni record. |
| epsilon | real |
✔️ | Distanza massima tra due campioni da considerare come vicini. |
| min_samples | int |
Numero di campioni in un quartiere per un punto da considerare come punto centrale. | |
| metrico | string |
Metrica da usare per il calcolo della distanza tra i punti. | |
| metric_params | dynamic |
Argomenti di parole chiave aggiuntivi per la funzione metrica. |
- Per una descrizione dettagliata dei parametri, vedere la documentazione di DBSCAN
- Per l'elenco delle metriche, vedere i calcoli delle distanze
Definizione di funzione
È possibile definire la funzione incorporando il codice come funzione definita da query o creandola come funzione archiviata nel database, come indicato di seguito:
Definire la funzione usando l'istruzione let seguente. Non sono necessarie autorizzazioni.
Importante
Un'istruzione let non può essere eseguita autonomamente. Deve essere seguita da un'istruzione di espressione tabulare. Per eseguire un esempio funzionante di kmeans_fl(), vedere l'esempio.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
// Write your query to use the function here.
Esempio
Nell'esempio seguente viene usato l'operatore invoke per eseguire la funzione .
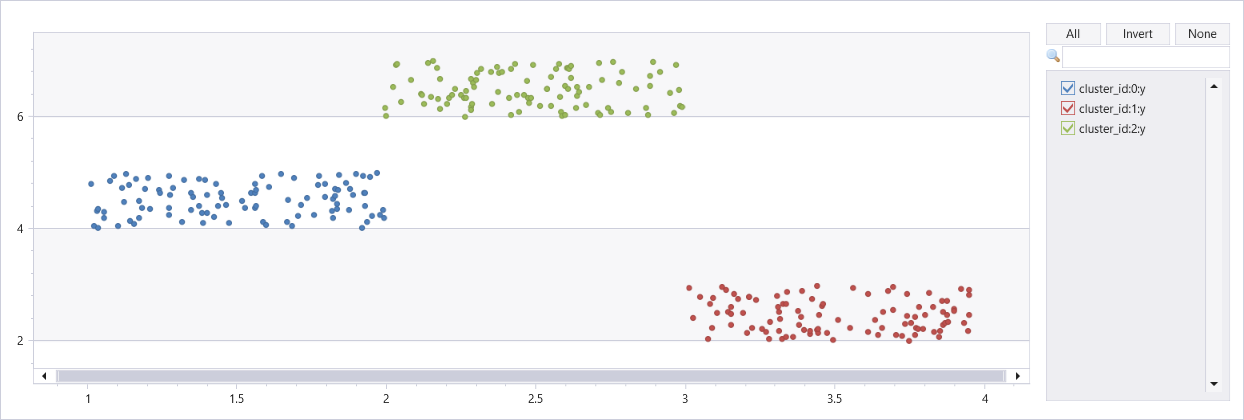
Clustering di set di dati artificiali con tre cluster
Per usare una funzione definita da query, richiamarla dopo la definizione della funzione incorporata.
let dbscan_fl=(tbl:(*), features:dynamic, cluster_col:string, epsilon:double, min_samples:int=10,
metric:string='minkowski', metric_params:dynamic=dynamic({'p': 2}))
{
let kwargs = bag_pack('features', features, 'cluster_col', cluster_col, 'epsilon', epsilon, 'min_samples', min_samples,
'metric', metric, 'metric_params', metric_params);
let code = ```if 1:
from sklearn.cluster import DBSCAN
from sklearn.preprocessing import StandardScaler
features = kargs["features"]
cluster_col = kargs["cluster_col"]
epsilon = kargs["epsilon"]
min_samples = kargs["min_samples"]
metric = kargs["metric"]
metric_params = kargs["metric_params"]
df1 = df[features]
mat = df1.values
# Scale the dataframe
scaler = StandardScaler()
mat = scaler.fit_transform(mat)
# see https://docs.scipy.org/doc/scipy/reference/spatial.distance.html for the various distance metrics
dbscan = DBSCAN(eps=epsilon, min_samples=min_samples, metric=metric, metric_params=metric_params) # 'minkowski', 'chebyshev'
labels = dbscan.fit_predict(mat)
result = df
result[cluster_col] = labels
```;
tbl
| evaluate python(typeof(*),code, kwargs)
};
union
(range x from 1 to 100 step 1 | extend x=rand()+3, y=rand()+2),
(range x from 101 to 200 step 1 | extend x=rand()+1, y=rand()+4),
(range x from 201 to 300 step 1 | extend x=rand()+2, y=rand()+6)
| extend cluster_id=int(null)
| invoke dbscan_fl(pack_array("x", "y"), "cluster_id", epsilon=0.6, min_samples=4, metric_params=dynamic({'p':2}))
| render scatterchart with(series=cluster_id)