Operatore summarize
Si applica a: ✅Microsoft Fabric✅Azure Esplora dati✅ Azure Monitor✅Microsoft Sentinel
Produce una tabella che aggrega il contenuto della tabella di input.
Sintassi
T | summarize [ SummarizeParameters ] [[Column =] Aggregation [, ...]] [by [Column =] GroupExpression [, ...]]
Altre informazioni sulle convenzioni di sintassi.
Parametri
| Nome | Digita | Obbligatorio | Descrizione |
|---|---|---|---|
| Istogramma | string |
Nome della colonna del risultato. Il valore predefinito è un nome derivato dall'espressione. | |
| Aggregazione | string |
✔️ | una chiamata a una funzione di aggregazione, ad esempio count() o avg(), con i nomi di colonna come argomenti. |
| GroupExpression | scalare | ✔️ | un'espressione scalare che può fare riferimento ai dati di input. L'output conterrà un numero di record uguale al numero di valori distinti di tutte le espressioni di gruppo. |
| SummarizeParameters | string |
Zero o più parametri separati da spazi sotto forma di Valore nome = che controllano il comportamento. Vedere i parametri supportati. |
Nota
Se la tabella di input è vuota, l'output varia a seconda che l'espressione GroupExpression venga usata o meno:
- Se GroupExpression non è specificata, l'output sarà una singola riga vuota.
- Se GroupExpression è specificata, l'output non avrà righe.
Parametri supportati
| Nome | Descrizione |
|---|---|
hint.num_partitions |
Specifica il numero di partizioni usate per condividere il carico delle query nei nodi del cluster. Vedere query shuffle |
hint.shufflekey=<key> |
La shufflekey query condivide il carico delle query sui nodi del cluster, usando una chiave per partizionare i dati. Vedere query shuffle |
hint.strategy=shuffle |
La shuffle query strategica condivide il carico delle query sui nodi del cluster, in cui ogni nodo elabora una partizione dei dati. Vedere query shuffle |
Valori restituiti
Le righe di input vengono disposte in gruppi con gli stessi valori delle espressioni by . Vengono quindi calcolate per ogni gruppo le funzioni di aggregazione specificate, generando una riga per ogni gruppo. Il risultato contiene le colonne by , oltre ad almeno una colonna per ogni aggregazione calcolata. Alcune funzioni di aggregazione restituiscono più colonne.
Il risultato contiene un numero di righe uguale al numero di combinazioni distinte di valori by (che potrebbe essere zero). Se non vengono fornite chiavi di gruppo, il risultato contiene un singolo record.
Per riepilogare intervalli di valori numerici, usare bin() per ridurre gli intervalli a valori discreti.
Nota
- Anche se è possibile specificare espressioni arbitrarie per le espressioni di aggregazione e raggruppamento, è preferibile usare nomi di colonna semplici o applicare
bin()a una colonna numerica. - I bin orari automatici per le colonne di data/ora non sono più supportati. Usare i bin espliciti in alternativa. Ad esempio:
summarize by bin(timestamp, 1h).
Valori predefiniti delle aggregazioni
La tabella seguente riepiloga i valori predefiniti delle aggregazioni:
| Operatore | Default value |
|---|---|
count(), countif(), , dcountif(), count_distinct()sum(), variance()sumif()varianceif(), stdev()dcount()stdevif() |
0 |
make_bag(), make_bag_if(), make_list(), make_list_if(), make_set()make_set_if() |
matrice dinamica vuota ([]) |
| Tutti gli altri | Null |
Nota
Quando si applicano queste aggregazioni alle entità che includono valori Null, i valori Null vengono ignorati e non vengono inseriti nel calcolo. Per esempi, vedere Aggrega i valori predefiniti.
Esempi
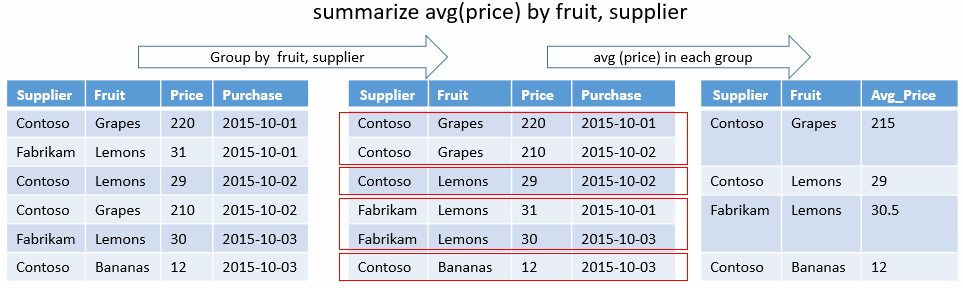
combinazione univoca
La query seguente determina quali combinazioni univoche di State e EventType ci sono per le tempeste che hanno causato un infortunio diretto. Non ci sono funzioni di aggregazione, ma solo chiavi group-by. L'output mostrerà solo le colonne per tali risultati.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Output
La tabella seguente mostra solo le prime 5 righe. Per visualizzare l'output completo, eseguire la query.
| Provincia | EventType |
|---|---|
| TEXAS | Vento di tempesta |
| TEXAS | Piena improvvisa |
| TEXAS | Clima invernale |
| TEXAS | Vento forte |
| TEXAS | Alluvione |
| ... | ... |
Timestamp minimo e massimo
Trova le tempeste di pioggia minime e massime nelle Hawaii. Non esiste alcuna clausola group-by, quindi nell'output è presente una sola riga.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Output
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
valori distinti
La query seguente calcola il numero di tipi di eventi storm univoci per ogni stato e ordina i risultati in base al numero di tipi storm univoci:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Output
La tabella seguente mostra solo le prime 5 righe. Per visualizzare l'output completo, eseguire la query.
| Provincia | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| PENNSYLVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
Istogramma
Nell'esempio seguente viene calcolato un tipo di evento temporale istogramma con tempeste che durano più di 1 giorno. Poiché Duration ha molti valori, usare bin() per raggruppare i valori in intervalli di 1 giorno.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Output
| EventType | Durata | EventCount |
|---|---|---|
| Siccità | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Colpo | 30.00:00:00 | 14 |
| Alluvione | 30.00:00:00 | 20 |
| Pioggia intensa | 29.00:00:00 | 42 |
| ... | ... | ... |
Aggrega i valori predefiniti
Quando l'input dell'operatore summarize ha almeno una chiave group-by vuota, anche il risultato è vuoto.
Quando l'input dell'operatore summarize non ha una chiave group-by vuota, il risultato è i valori predefiniti delle aggregazioni usate in summarize Per altre informazioni, vedere Valori predefiniti delle aggregazioni.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Output
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
Il risultato di avg_x(x) è NaN dovuto alla divisione per 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Output
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Output
| set_x | list_x |
|---|---|
| [] | [] |
La media aggregata somma tutti i valori non Null e conta solo quelli che hanno partecipato al calcolo (non prenderanno in considerazione i valori Null).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Output
| sum_y | avg_y |
|---|---|
| 15 | 5 |
Il conteggio regolare conterà i valori Null:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Output
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Output
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |