Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il riconoscimento ottico dei caratteri (OCR) consente di individuare ed estrarre il testo dalle immagini o dallo schermo.
Sebbene la maggior parte degli scenari richieda la gestione del testo in una lingua specifica, in alcuni casi le fonti sono multilingue.
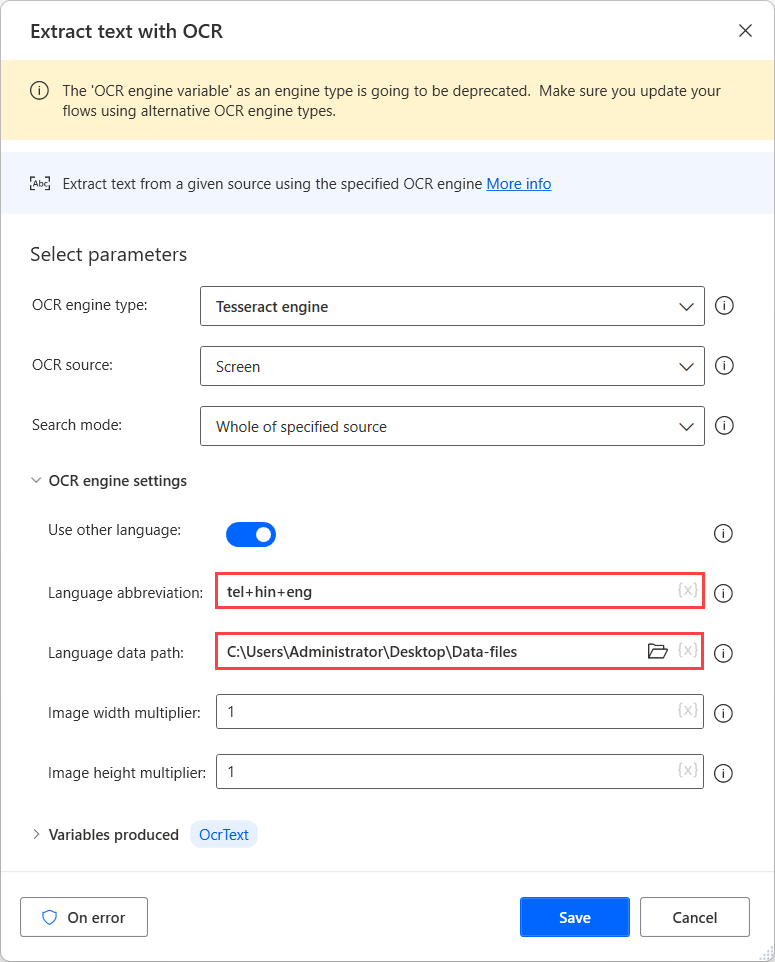
Per eseguire l'OCR su queste fonti, utilizza un motore Tesseract nella rispettiva azione OCR e abilita l'opzione Usa altre lingue nelle impostazioni del motore.
Quando l'opzione Usa altre lingue è abilitata, l'azione visualizza due impostazioni aggiuntive: i campi Abbreviazione lingua e Percorso dati lingua.
Il campo Abbreviazione lingua indica al motore quale lingua cercare durante l'OCR. Il campo Percorso dati lingua contiene i file di dati della lingua (.traineddata) utilizzato per addestrare il motore OCR.

Dopo aver scaricato i file di dati per le lingue necessarie, spostali in una cartella comune per renderli disponibili nello stesso percorso.
Quindi, seleziona la cartella creata nel campo Percorso dati lingua e popola i codici lingua corrispondenti nel campo Abbreviazione lingua. Per separare i codici lingua, utilizza il carattere più (+).
Nota
Puoi trovare tutti i codici lingua disponibili nella fonte dei file di dati della lingua. Nell'esempio seguente, i codici utilizzati rappresentano Telugu, hindi e inglese.