Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
In base all'analisi, pianificare l'integrazione e identificare il modello migliore per i requisiti. L'elenco seguente dei modelli di integrazione non è esaustivo. È possibile che una combinazione di questi modelli si adatti meglio allo scenario.
Ogni modello risolve scenari aziendali e vincoli tecnici specifici:
- Modello di trigger istantaneo: questo modello riflette il modo in cui gli utenti interagiscono con i sistemi. Un'azione guidata dall'utente attiva una serie predefinita di azioni.
- Modello basato su eventi: questo modello richiede un trigger automatico, ad esempio una risposta agli eventi che si verificano in un determinato sistema.
- Modello di consolidamento dei dati: questo modello è essenziale per le organizzazioni con più sistemi di gestione che richiedono un quadro completo dei dati nei vari sistemi.
- Modello di architettura orientata ai servizi: questo modello prevede in genere più flussi tra sistemi, consentendo l'integrazione modulare e scalabile in ambienti complessi.
- Modello di sincronizzazione: questo modello mantiene i dati sincronizzati tra database diversi e soddisfa i requisiti normativi e delle prestazioni.
Modello di attivazione istantanea
Il modello di trigger istantaneo è guidato dall'utente e intuitivo. Avvia un flusso di integrazione quando un utente esegue un'azione, ad esempio premendo un pulsante in un'app power. Questo modello è ideale per scenari in cui i dati sono necessari su richiesta e non continuamente.
Scenario di esempio
Power App consente ai responsabili del prodotto di esaminare il feedback dei clienti e creare piani di azione. Alcune specifiche tecniche vengono archiviate nel sistema Product Lifecycle Management di Oracle. Anziché copiare l'intero set di dati in Dataverse, l'app include un pulsante per recuperare i dati quando necessario.
I motivi per l'integrazione anziché reindirizzare gli utenti a Oracle includono:
- Esperienza utente scarsa
- Problemi di sicurezza
- Costi di licenza
Data l'efficacia dei costi delle integrazioni di Power Platform, uno di questi motivi potrebbe giustificare l'implementazione.
Progettazione del flusso
Usare un flusso cloud istantaneo attivato da un pulsante premuto nell'applicazione.
Questo diagramma illustra il modello di trigger istantaneo, in cui un'azione avviata dall'utente recupera i dati da un sistema esterno e lo scrive in Dataverse:
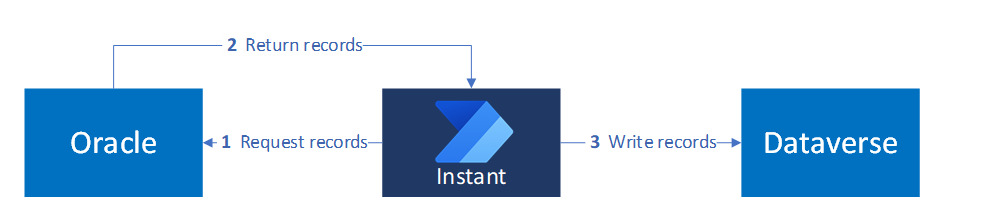
Il flusso include questi passaggi:
- Richiedere record da Oracle usando parametri (ad esempio ID prodotto) forniti dall'app.
- Restituisce i record da Oracle all'app.
- Scrivere record in Dataverse.
Questi dati vengono quindi riflessi nell'interfaccia di Power Apps.
Considerazioni:
- I modelli di dati tra Oracle e Dataverse possono differire, richiedendo passaggi di trasformazione.
- I trigger istantanei non sono veramente istantanei. Il tempo di esecuzione dipende dalla complessità della disponibilità e della trasformazione del sistema.
- Aggiungere indicatori visivi nell'app per mostrare lo stato di avanzamento e consentire l'annullamento se l'operazione richiede troppo tempo.
- Nelle organizzazioni di grandi dimensioni, le richieste simultanee da molti utenti possono sovraccaricare il sistema.
- Le integrazioni possono avere esito negativo per diversi motivi. Assicurarsi che l'app fornisca commenti e suggerimenti agli utenti durante l'esecuzione. Evitare scenari in cui gli utenti selezionano un pulsante e non ricevono alcuna risposta, con un'esperienza utente scarsa.
Modello basato su eventi
Le architetture guidate dagli eventi (note anche come trigger automatici) rispondono alle modifiche nei sistemi senza interazione diretta dell'utente. Ad esempio, i trigger possono essere configurati per rispondere a un record creato in Dataverse, messaggi di posta elettronica in arrivo, file aggiunti a OneDrive e qualsiasi numero di altri eventi. Questo modello è intuitivo e scalabile, rendendolo ideale per automatizzare i processi aziendali in base agli eventi di sistema.
Scenario di esempio
Un reparto del servizio clienti usa un'app connessa a Dataverse per lavorare sui casi e fornire automaticamente aggiornamenti ai clienti, senza scrivere messaggi di posta elettronica manualmente. Solo modifiche specifiche, ad esempio l'aggiunta di una nota o la modifica dello stato, devono attivare le notifiche.
Usare un trigger automatizzato in Power Automate per rispondere a questi eventi. Il flusso è in ascolto delle modifiche nei record di Dataverse e invia notifiche quando vengono soddisfatte le condizioni definite.
Questo diagramma mostra il modello di trigger automatico, in cui le modifiche in Dataverse avviano automaticamente azioni downstream che aggiornano i clienti con le informazioni sui casi pertinenti:
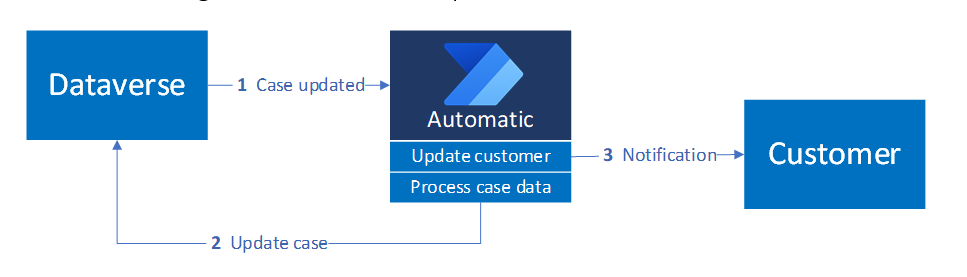
Configurazione trigger
Configurare il flusso come segue:
- Indicare il tipo di modifica da monitorare.
- Definire le colonne da rispondere usando il parametro Select Columns .
- Usare il parametro Filter Rows (Filtra righe ) per garantire che solo le modifiche dello stato rivolte ai clienti attivino il flusso, oltre a qualsiasi altro requisito di filtraggio.
Evitare di implementare questa logica nel flusso stesso usando un'azione If . Usare i parametri del trigger per ridurre le esecuzioni non necessarie e migliorare le prestazioni.
Evitare conflitti logici
Valutare la logica dell'evento per evitare comportamenti imprevisti:
- Evitare cicli in cui un evento attiva un'azione che ritenta lo stesso evento.
- Impedire a più aggiornamenti di causare notifiche rapide e ripetute.
- Progettare flussi per gestire i casi perimetrali ed evitare esecuzioni eccessive.
Considerazioni sul volume e sulla frequenza
Comprendere il volume previsto di eventi attivati. I servizi di notifica (posta elettronica, SMS e altri) limitano il numero di messaggi che è possibile inviare in un determinato intervallo di tempo.
- Stimare il numero di eventi al giorno o al mese.
- Implementare meccanismi di limitazione della velocità o della frequenza.
- Preparare un piano di mitigazione per picchi imprevisti nella frequenza degli eventi.
Modello di consolidamento dei dati
Il consolidamento dei dati (noto anche come trigger pianificato) consente alle organizzazioni di unificare le informazioni in più sistemi per supportare i processi operativi e di creazione di report. Anche se l'analisi richiede spesso set di dati completi, i casi d'uso operativi si concentrano sul recupero solo dei dati necessari per completare le attività aziendali.
Scenario di esempio
Una società usa tre sistemi legacy per gestire le funzioni aziendali di base: SAP per ordini e account crediti, Oracle per l'inventario dei prodotti e IBM per la gestione dei contenuti correlata al cliente. L'organizzazione ha commissionato a una nuova app Power Platform di usare l'intelligenza artificiale per prevedere l'azione migliore successiva per ogni cliente in base ai dati cronologici. L'app deve raccogliere informazioni pertinenti da tutti e tre i sistemi e generare un piano di azione di vendita per i responsabili delle vendite per guidare l'engagement.
Approccio di integrazione
L'integrazione non richiede aggiornamenti in tempo reale o trigger basati su eventi. Usare invece un processo pianificato in base alla frequenza con cui il personale addetto alle vendite interagisce con i clienti.
In questo caso d'uso, un trigger pianificato consolida i dati come segue:
- Richiede solo i dati necessari da ogni sistema
- Restituisce i dati in un formato compatibile con Dataverse
- Carica i dati nel modello di intelligenza artificiale per l'analisi
Questo diagramma illustra il modello di consolidamento dei dati pianificato, in cui un processo ricorrente raccoglie informazioni da più sistemi e carica il set di dati combinato in Dataverse:
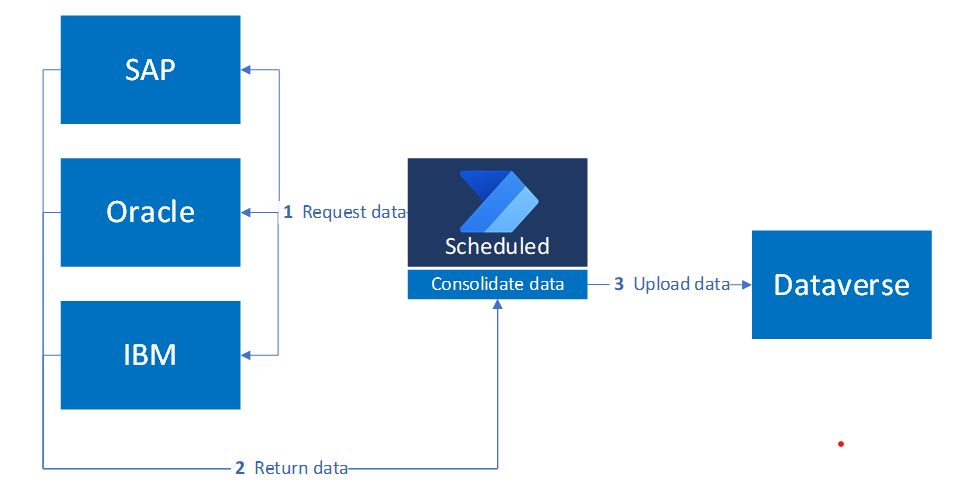
Configurazione del trigger programmato
I trigger pianificati offrono opzioni di ricorrenza flessibili, da una volta al secondo a una volta all'anno. Sono prevedibili in tempi, ma possono diventare imprevedibili nel volume se l'ambito dei dati si espande o la crescita supera le aspettative.
- Monitorare il tempo di esecuzione del flusso per evitare sovrapposizioni o ritardi
- Implementare misure di sicurezza per evitare una riduzione delle prestazioni
- Usare Application Insights o strumenti simili per garantire che il flusso venga eseguito in modo coerente
Mitigazione dei rischi
Se un flusso pianificato richiede più tempo del previsto, potrebbe interrompere i processi aziendali. Ad esempio, un flusso progettato per l'esecuzione ogni 10 minuti potrebbe non riuscire se il completamento richiede più di 10 minuti.
- Monitorare il runtime e impostare avvisi per individuare le anomalie
- Pianificare la scalabilità man mano che aumenta il volume di dati
- Garantire visibilità sull'integrità del flusso per evitare errori non rilevati
Modello di integrazione orientata ai servizi
Le organizzazioni di grandi dimensioni spesso gestiscono più sistemi tra i reparti. Questi sistemi si evolvono per dipendere l'uno dall'altro per completare i processi aziendali. Il livello di integrazione collega questi sistemi, consentendo a ognuno di eseguire la relativa funzione di base, abilitando al tempo stesso la comunicazione tra sistemi.
Scenario di esempio rivisitato
Si continuerà con lo scenario di esempio in cui l'organizzazione usa più sistemi per gestire parti diverse dell'azienda. SAP gestisce gli ordini e i crediti degli account, Oracle gestisce l'inventario dei prodotti e IBM archivia la documentazione finanziaria interna. Dataverse esegue app per le vendite, il servizio clienti e la gestione dei prodotti. SharePoint supporta la collaborazione interna e la gestione della knowledge base, mentre le API Maersk automatizzano i processi logistici.
Questo diagramma illustra il modello basato sugli eventi in un panorama multi-sistema, in cui gli aggiornamenti in vari sistemi aziendali attivano flussi automatizzati che coordinano i dati e le azioni tra di essi:
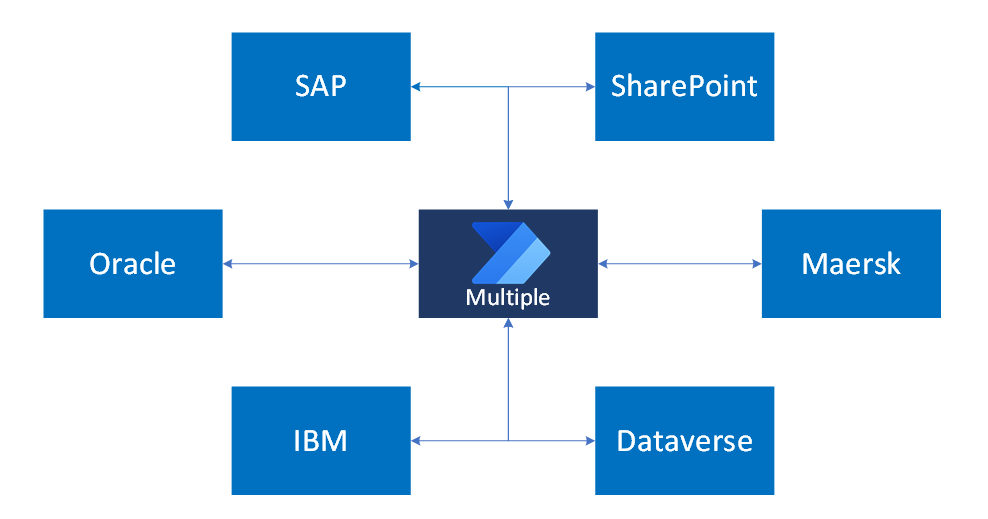
Ogni sistema interagisce con altri utenti tramite eventi pianificati o azioni manuali dell'utente. Nessun flusso singolo serve tutti i casi d'uso. La soluzione richiede invece più flussi personalizzati in base a trigger e processi aziendali specifici.
Evitare flussi monolitici
La creazione di un flusso di grandi dimensioni per gestire tutte le integrazioni non è pratica. Presenta problemi di prestazioni, sicurezza e manutenzione. Al contrario:
- Creare flussi modulari per ogni trigger e processo
- Ottimizzare i flussi per casi d'uso specifici
- Ridimensionare il panorama dell'integrazione con componenti gestibili
Ottimizzare i processi tra sistemi
Cercate opportunità per consolidare la logica laddove appropriato. Ad esempio, se un documento in SharePoint deve essere inviato sia a SAP che a Oracle durante lo stesso evento, si potrebbe essere tentati di creare un flusso che legge il file una sola volta e lo scrive in entrambi i sistemi. Prima di tutto, tuttavia, valutare se la logica che si sta creando è troppo rigida. In un ampio panorama, cambia il modo in cui i processi aziendali operano attraverso i sistemi con la stessa frequenza delle modifiche apportate a tali sistemi.
Evitare l'eccessiva consolidazione. I processi aziendali e le configurazioni di sistema cambiano frequentemente. La logica rigida e centralizzata riduce la flessibilità e aumenta il sovraccarico di manutenzione.
Progetta flussi che siano:
- Modulare e gestibile
- Scalabilità tra reparti e sistemi
- Resiliente alle modifiche apportate alla logica di business e al comportamento del sistema
Questo modello comporta un'architettura orientata ai servizi, talvolta denominata "architettura spaghetti", in cui i sistemi sono interconnessi attraverso flussi ben definiti e creati appositamente.
Modello di sincronizzazione dei dati
Usare la sincronizzazione dei dati quando sistemi identici archiviano i dati in database separati. Anche se l'archiviazione due volte degli stessi dati potrebbe sembrare inefficiente, questo modello supporta esigenze aziendali specifiche, ad esempio prestazioni e conformità alle normative.
- Prestazioni: l'accesso ai dati locali migliora la velocità di risposta, soprattutto nei settori sensibili alla latenza.
- Conformità: le normative legali potrebbero richiedere l'archiviazione dei dati entro i confini nazionali. Le organizzazioni spesso distribuiscono istanze locali con processi di sincronizzazione per soddisfare questi requisiti.
Scenario di esempio
Un'azienda di dispositivi medici opera in più regioni in Europa, in collaborazione con le istituzioni mediche locali. Le leggi di ogni area sono chiare sui dati medici, che devono essere archiviate entro i confini di tale area. Le informazioni sugli ordini, i prodotti e la spedizione possono essere archiviate transfrontaliere. Per soddisfare i requisiti normativi, l'azienda ha creato un'istanza dell'app di gestione dei clienti Power Platform e Dataverse in ogni area.
Per supportare le operazioni di vendita, l'azienda vuole sincronizzare i dati non sensibili, ad esempio i dettagli di contatto, gli ordini e la spedizione, in tutte le istanze. I dati medici sono esclusi dalla sincronizzazione.
Approccio di integrazione
Utilizza un flusso cloud automatico attivato dagli aggiornamenti al record di account. Configurare i filtri per:
- Monitorare solo i campi consentiti
- Impedire la sincronizzazione dei dati con restrizioni
Questo approccio comporta un'integrazione mirata basata su eventi che supporta la conformità e l'efficienza operativa.
Questo diagramma illustra il modello di sincronizzazione basato su eventi, in cui gli aggiornamenti in un ambiente Dataverse attivano automaticamente gli aggiornamenti corrispondenti in un altro:
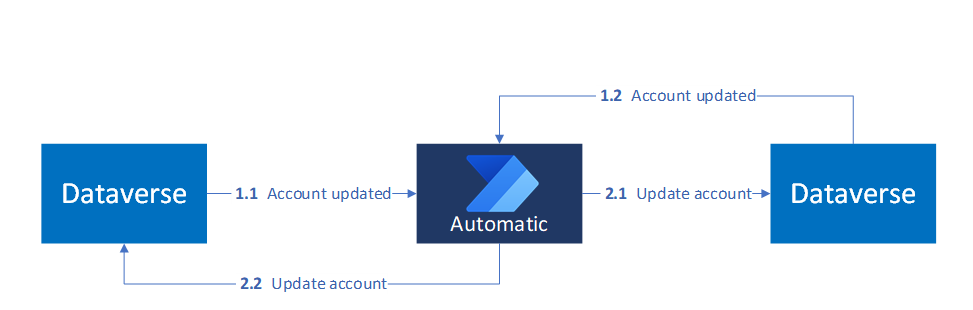
Aspettative del tempo di risposta
Impostare aspettative realistiche per la velocità di sincronizzazione. Power Automate è asincrono e non garantisce prestazioni in tempo reale. Se gli utenti aziendali prevedono una disponibilità immediata dei dati, chiarire le limitazioni all'inizio del processo di progettazione.
- Valutare se Power Automate soddisfa le esigenze di prestazioni
- Evitare la sovraingegnerizzazione per l'accesso in tempo reale, salvo che sia giustificato dai requisiti aziendali.
Molte richieste di accesso in tempo reale non hanno un caso aziendale sicuro. Classificare in ordine di priorità chiarezza, scalabilità e gestibilità nella progettazione dell'integrazione.
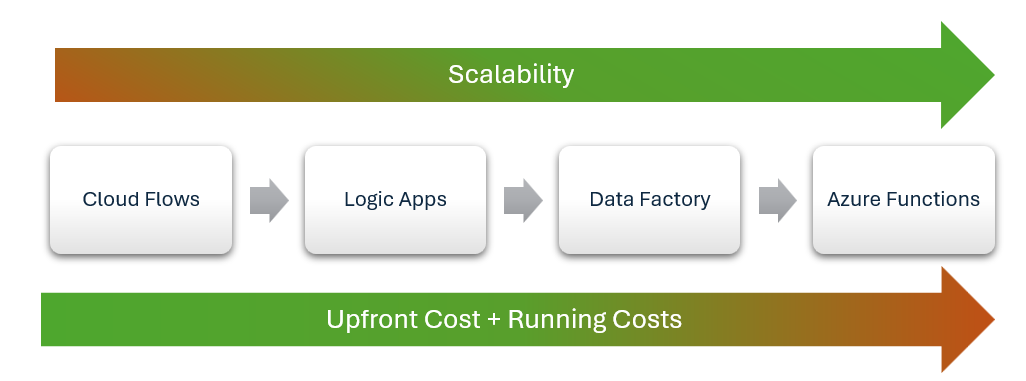
Oltre i flussi cloud
Quando si seleziona uno strumento di integrazione, iniziare con Power Automate come opzione predefinita. Offre un'efficienza dei costi incomparabile sia per lo sviluppo che per la manutenzione.
Power Automate è lo strumento di integrazione preferito per molti scenari perché:
- Offre uno sviluppo rapido con connettori a basso codice
- Riduce al minimo i costi di manutenzione a lungo termine
- Supporta un'ampia gamma di attivatori e sistemi
- Scalabilità ottimale per la maggior parte degli scenari aziendali
Il codice personalizzato, Funzioni di Azure, Data Factory o bus di servizio potrebbe offrire un maggiore controllo o prestazioni migliori, ma aggiunge complessità e costi. Usare queste opzioni solo quando Power Automate non soddisfa le esigenze aziendali o tecniche.
Scenario di esempio
Un servizio bancario online vuole qualificare i clienti per i prestiti più rapidamente. Il processo di qualificazione prevede calcoli complessi e il recupero dei dati da più sistemi per arrivare a un punteggio di rischio finale. In seguito a una valutazione iniziale, il servizio bancario ha considerato il flusso cloud inadatto in base alla complessità dei calcoli.
Tuttavia, in questo caso un approccio ibrido è la risposta:
- Power Automate per gestire la raccolta dei dati con connettori integrati
- Calcoli complessi incapsulati in codice personalizzato in esecuzione come funzione di Azure, che possono essere ridimensionati in modo indipendente o in un connettore personalizzato
Questo approccio ibrido bilancia le prestazioni, la scalabilità e i costi.
Strategia di integrazione
Non scegliere gli strumenti in modo isolato. Combina invece i loro punti di forza. Per esempio:
- Usare Power Automate per orchestrazione e connettività
- Usare Funzioni di Azure per attività a elevato utilizzo di calcolo
- Usare connettori personalizzati per estendere le funzionalità quando necessario
Ogni decisione di integrazione deve considerare il costo totale di proprietà. Le soluzioni personalizzate possono sembrare potenti, ma spesso richiedono un budget più elevato per lo sviluppo, le licenze e il supporto. Giustificare costi più elevati con un valore aziendale chiaro.