Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
I valori del cluster creano automaticamente gruppi con valori simili usando un algoritmo di corrispondenza fuzzy e quindi esegue il mapping del valore di ogni colonna al gruppo con corrispondenza migliore. Questa trasformazione è utile quando si lavora con i dati con molte varianti diverse dello stesso valore ed è necessario combinare i valori in gruppi coerenti.
Si consideri una tabella di esempio con una colonna ID che contiene un set di ID e una colonna Person contenente un set di versioni con maiuscole e minuscole dei nomi Miguel, Mike, William e Bill.
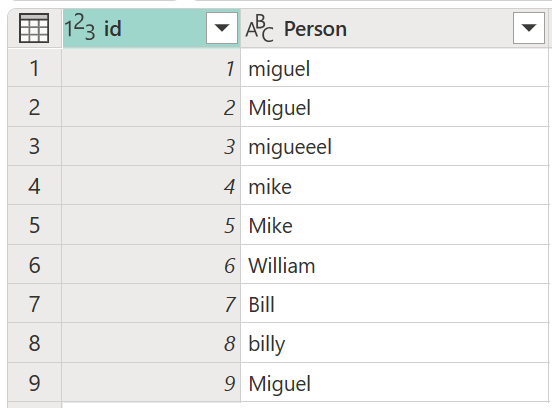
In questo esempio, il risultato che si sta cercando è una tabella con una nuova colonna che mostra i gruppi di valori corretti della colonna Person e non tutte le diverse varianti delle stesse parole.
Annotazioni
La funzionalità Valori cluster è disponibile solo per Power Query Online.
Creare una colonna di tipo Cluster
Per raggruppare i valori, selezionare prima la colonna Person , passare alla scheda Aggiungi colonna nella barra multifunzione e quindi selezionare l'opzione Valori cluster .
![]()
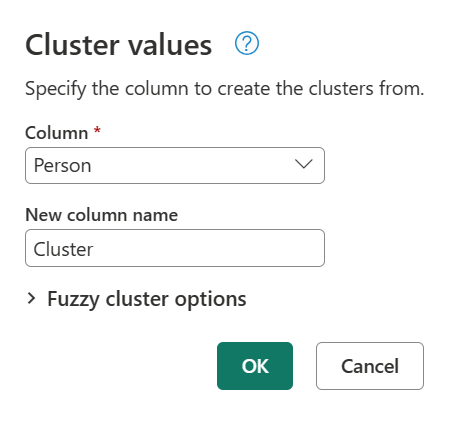
Nella finestra di dialogo Valori cluster confermare la colonna da cui creare i cluster e immettere il nuovo nome della colonna. In questo caso, denominare la nuova colonna Cluster.
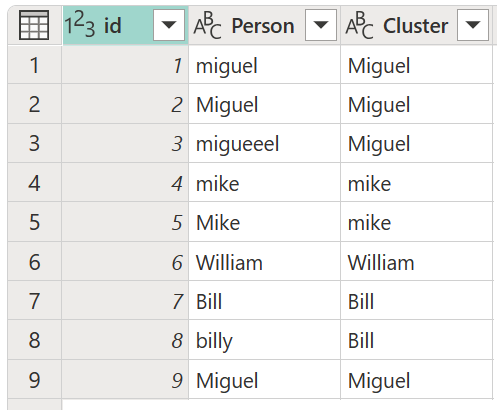
Il risultato di tale operazione è illustrato nell'immagine seguente.
Annotazioni
Per ogni cluster di valori, Power Query seleziona l'istanza più frequente dalla colonna selezionata come istanza "canonica". Se si verificano più istanze con la stessa frequenza, Power Query seleziona la prima.
Uso delle opzioni del cluster fuzzy
Le opzioni seguenti sono disponibili per i valori di clustering in una nuova colonna:
- Soglia di somiglianza (facoltativa): questa opzione indica come devono essere raggruppati due valori simili. L'impostazione minima di zero (0) determina il raggruppamento di tutti i valori. L'impostazione massima di 1 consente solo il raggruppamento di valori che corrispondono esattamente. Il valore predefinito è 0.8.
- Ignora maiuscole/minuscole: quando vengono confrontate le stringhe di testo, si ignorano le maiuscole e minuscole. Questa opzione è abilitata per impostazione predefinita.
- Raggruppare combinando parti di testo: l'algoritmo tenta di combinare parti di testo (ad esempio combinando Micro e soft in Microsoft) per raggruppare i valori.
- Mostra punteggi di somiglianza: mostra i punteggi di somiglianza tra i valori di input e i valori rappresentativi calcolati dopo il clustering fuzzy.
- Tabella di trasformazione (facoltativa) : è possibile selezionare una tabella di trasformazione che esegue il mapping dei valori (ad esempio il mapping di MSFT a Microsoft) per raggrupparli.
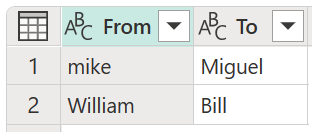
Per questo esempio viene usata una nuova tabella di trasformazione con il nome Tabella trasformazione personale per illustrare come è possibile eseguire il mapping dei valori. Questa tabella di trasformazione include due colonne:
- Da: stringa di testo da cercare nella tabella.
- To: stringa di testo da utilizzare per sostituire la stringa di testo nella colonna From .
Importante
È importante che la tabella di trasformazione abbia gli stessi nomi di colonne e colonne come illustrato nell'immagine precedente (devono essere denominati "Da" e "A"), altrimenti Power Query non riconoscerà questa tabella come tabella di trasformazione e non verrà eseguita alcuna trasformazione.
Usando la query creata in precedenza, fare doppio clic sul passaggio Valori raggruppati, quindi nella finestra di dialogo Valori cluster espandere Opzioni cluster fuzzy. In Opzioni cluster fuzzy abilitare l'opzione Mostra punteggi di somiglianza . Per Tabella trasformazione (facoltativo) selezionare la query con la tabella di trasformazione.
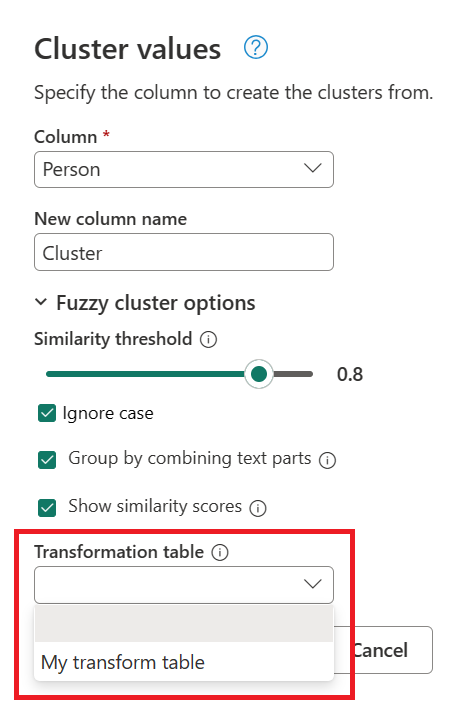
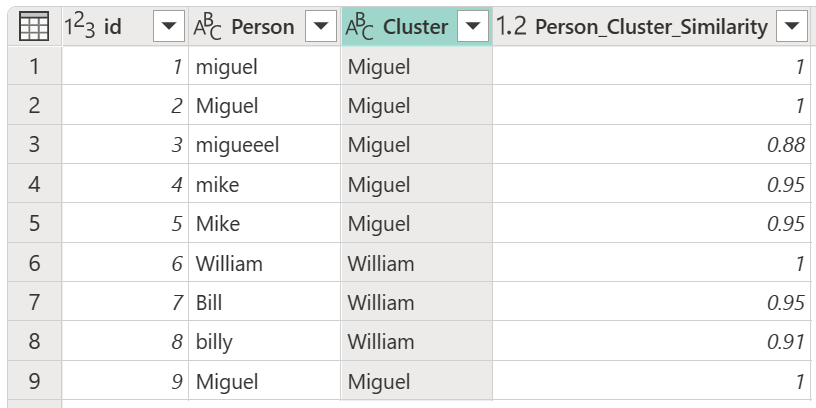
Dopo aver selezionato la tabella di trasformazione e aver abilitato l'opzione Mostra punteggi di somiglianza , selezionare OK. Il risultato di questa operazione fornisce una tabella contenente lo stesso ID e le colonne Person della tabella originale, ma include anche due nuove colonne denominate Cluster e Person_Cluster_Similarity. La colonna Cluster contiene le versioni digitate correttamente e maiuscole dei nomi Miguel per le versioni di Miguel e Mike e William per le versioni di Bill, Billy e William. La colonna Person_Cluster_Similarity contiene i punteggi di somiglianza per ognuno dei nomi.
Principi della tabella di trasformazione
Si potrebbe notare che la tabella di trasformazione nella sezione precedente sembrava indicare che le istanze di Mike vengono modificate in Miguel e le istanze di William vengono modificate in Bill. Tuttavia, nella tabella risultante, le istanze dei nomi "Bill" e "billy" sono state invece modificate in William. Nella tabella di trasformazione, invece di essere un percorso diretto From a To, la tabella è simmetrica nel clustering, ovvero "Mike" equivale a "Miguel" e viceversa. Il risultato degli equivalenti specificati nella tabella di trasformazione dipende dalle regole seguenti:
- Se esiste una maggioranza di valori identici, questi valori hanno la precedenza sui valori non rientrati.
- Se non esiste la maggior parte dei valori, il valore visualizzato per primo ha la precedenza.
Ad esempio, nella tabella originale usata in questo articolo, le versioni di Miguel (sia "miguel" che Miguel) nella colonna Person costituiscono la maggior parte delle istanze del nome Miguel e Mike. Inoltre, il nome Miguel con maiuscole iniziali costituisce la maggior parte del nome Miguel. Quindi, associando Miguel e i suoi derivati e Mike e i suoi derivati nella tabella di trasformazione, il nome Miguel viene usato nella colonna Cluster .
Tuttavia, per i nomi William, Bill e "billy", non esiste la maggioranza dei valori poiché tutti e tre sono univoci. Poiché William appare per la prima volta, William viene usato nella colonna Cluster . Se "billy" fosse apparso per la prima volta nella tabella, nella colonna Cluster verrà usato "billy". Inoltre, poiché non esiste la maggior parte dei valori, viene usato il caso usato dai singoli nomi. Ovvero, se William è il primo, William con una maiuscola "W" viene usato come valore del risultato; se "billy" è il primo, viene usato "billy" con un minuscolo "b".