Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Se il flusso di dati che si sta sviluppando è sempre più grande e complesso, ecco alcune operazioni che è possibile eseguire per migliorare la progettazione originale.
Suddividerli in più flussi di dati
Non eseguire tutte le operazioni in un flusso di dati. Non solo un singolo flusso di dati complesso rende più lungo il processo di trasformazione dei dati, ma rende anche più difficile comprendere e riutilizzare il flusso di dati. È possibile interrompere il flusso di dati in più flussi di dati separando le tabelle in flussi di dati diversi, oppure dividendo una singola tabella in più flussi di dati. È possibile usare il concetto di tabella calcolata o di una tabella collegata per compilare parte della trasformazione in un flusso di dati e riutilizzarla in altri flussi di dati.
Dividere i flussi di trasformazione dati dai flussi di staging/estrazione dei dati.
La presenza di alcuni flussi di dati solo per l'estrazione di dati (ossia, flussi di dati di staging) e altri solo per la trasformazione dei dati non è utile solo per la creazione di un'architettura a più livelli, ma anche per ridurre la complessità dei flussi di dati. Alcuni passaggi consentono di estrarre dati dall'origine dati, ad esempio ottenere dati, navigazione e modifiche al tipo di dati. Separando i flussi di dati di staging e i flussi di dati di trasformazione, è possibile semplificare lo sviluppo dei flussi di dati.
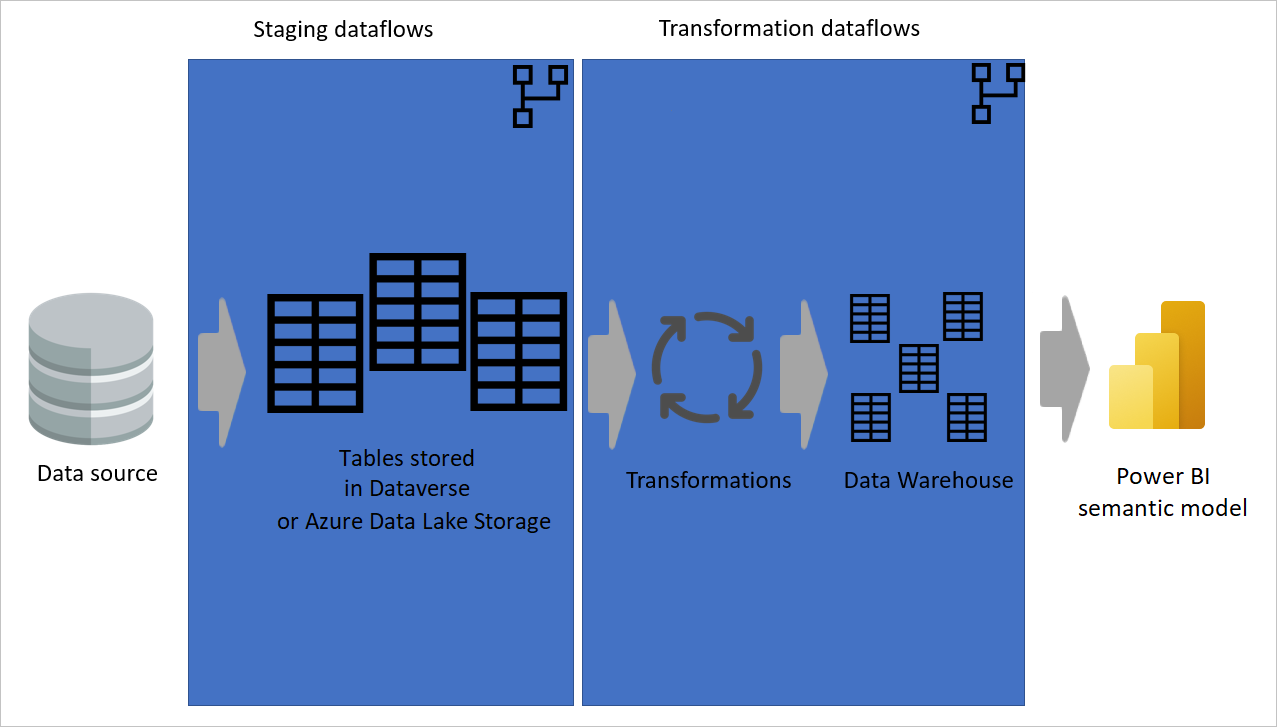
Immagine che mostra i dati estratti da un'origine dati verso flussi di dati di staging, in cui le tabelle vengono archiviate in Dataverse o in Azure Data Lake Storage. I dati vengono quindi spostati nei flussi di dati di trasformazione in cui i dati vengono trasformati e convertiti nella struttura del data warehouse. I dati vengono quindi spostati nel modello semantico.
Usare funzioni personalizzate
Le funzioni personalizzate sono utili negli scenari in cui è necessario eseguire un certo numero di passaggi per una serie di query provenienti da origini diverse. Le funzioni personalizzate possono essere sviluppate tramite l'interfaccia grafica nell'editor di Power Query o usando uno script M. Le funzioni possono essere riutilizzate in un flusso di dati in tutte le tabelle necessarie.
La presenza di una funzione personalizzata consente di avere una sola versione del codice sorgente, quindi non è necessario duplicare il codice. Di conseguenza, la gestione della logica di trasformazione di Power Query e dell'intero flusso di dati è molto più semplice. Per altre informazioni, vedere il post di blog seguente: Funzioni personalizzate semplificate in Power BI Desktop.
Nota
A volte è possibile ricevere una notifica che indica che è necessaria una capacità Premium per aggiornare un flusso di dati con una funzione personalizzata. È possibile ignorare questo messaggio e riaprire l'editor del flusso di dati. Questo in genere risolve il problema a meno che la funzione non faccia riferimento a una query "abilitata per il caricamento".
Posizionare le query nelle cartelle
L'uso di cartelle per le query consente di raggruppare le query correlate. Quando si sviluppa il flusso di dati, dedicare un po' di tempo in più per disporre le query in cartelle più sensate. Usando questo approccio, è possibile trovare le query più facilmente in futuro e gestire il codice è molto più semplice.
Usare tabelle calcolate
Le tabelle calcolate non solo rendono il flusso di dati più comprensibile, ma offrono anche prestazioni migliori. Quando si usa una tabella calcolata, le altre tabelle a cui viene fatto riferimento ottengono dati da una tabella "già elaborata e archiviata". La trasformazione è molto più semplice e veloce.
Sfruttare i vantaggi del motore di calcolo avanzato
Per i flussi di dati sviluppati nel portale di amministrazione di Power BI, assicurati di utilizzare il motore di calcolo avanzato eseguendo prima i join e le trasformazioni di filtro in una tabella calcolata, prima di eseguire altri tipi di trasformazioni.
Suddividere molti passaggi in più query
È difficile tenere traccia di un numero elevato di passaggi in una tabella. È invece consigliabile suddividere un numero elevato di passaggi in più tabelle. È possibile usare abilita Caricamento per altre query e disabilitarle se sono query intermedie, caricando solo la tabella finale tramite il flusso di dati. Quando si hanno più query con passaggi più piccoli in ognuno di essi, è più facile usare il diagramma delle dipendenze e tenere traccia di ogni query per un'ulteriore analisi, anziché scavare in centinaia di passaggi in una query.
Aggiungere le proprietà per le query e i passaggi
La documentazione è la chiave per avere codice facile da gestire. In Power Query è possibile aggiungere proprietà alle tabelle e anche ai passaggi. Il testo aggiunto nelle proprietà viene visualizzato come descrizione comando quando si passa con il mouse su tale query o passaggio. Questa documentazione consente di mantenere il modello in futuro. Con un'occhiata a una tabella o a un passaggio, è possibile capire cosa sta succedendo, anziché dover ripensare e ricordare quanto fatto in quel passaggio.
Assicurarsi che la capacità si trovi nella stessa regione
I flussi di dati attualmente non supportano più paesi o aree geografiche. La capacità Premium deve trovarsi nella stessa area del tenant di Power BI.
Separare le origini locali dalle origini cloud
È consigliabile creare un flusso di dati separato per ogni tipo di origine, ad esempio locale, cloud, SQL Server, Spark e Dynamics 365. La separazione dei flussi di dati in base al tipo di origine facilita la risoluzione dei problemi rapidi ed evita limiti interni quando si aggiornano i flussi di dati.
Separare i flussi di dati in base all'aggiornamento pianificato necessario per le tabelle
Se si dispone di una tabella delle transazioni di vendita che viene aggiornata nel sistema di origine ogni ora e si dispone di una tabella di mapping del prodotto che viene aggiornata ogni settimana, suddividere queste due tabelle in due flussi di dati con pianificazioni di aggiornamento dati diverse.
Evitare di pianificare l'aggiornamento per le tabelle collegate nella stessa area di lavoro
Se vieni regolarmente bloccato dai flussi di dati che contengono tabelle collegate, potrebbe essere causato da un flusso di dati dipendente corrispondente nella stessa area di lavoro bloccata durante l'aggiornamento del flusso di dati. Tale blocco garantisce l'accuratezza transazionale e garantisce che entrambi i flussi di dati vengano aggiornati correttamente, ma possono impedire la modifica.
Se si configura una pianificazione separata per il flusso di dati collegato, i flussi di dati possono essere aggiornati inutilmente e impedire la modifica del flusso di dati. Esistono due raccomandazioni per evitare questo problema:
- Non impostare una pianificazione di aggiornamento per un flusso di dati collegato nella stessa area di lavoro del flusso di dati di origine.
- Se si vuole configurare una pianificazione dell'aggiornamento separatamente e si vuole evitare il comportamento di blocco, spostare il flusso di dati in un'area di lavoro separata.