Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
L'uso di tabelle calcolate in un flusso di dati offre vantaggi. Questo articolo descrive i casi d'uso per le tabelle calcolate e descrive come funzionano in background.
Che cos'è una tabella calcolata?
Una tabella rappresenta l'output dei dati di una query creata in un flusso di dati, dopo l'aggiornamento del flusso di dati. Rappresenta i dati di un'origine e, facoltativamente, le trasformazioni applicate. In alcuni casi, è possibile creare nuove tabelle che sono una funzione di una tabella inserita in precedenza.
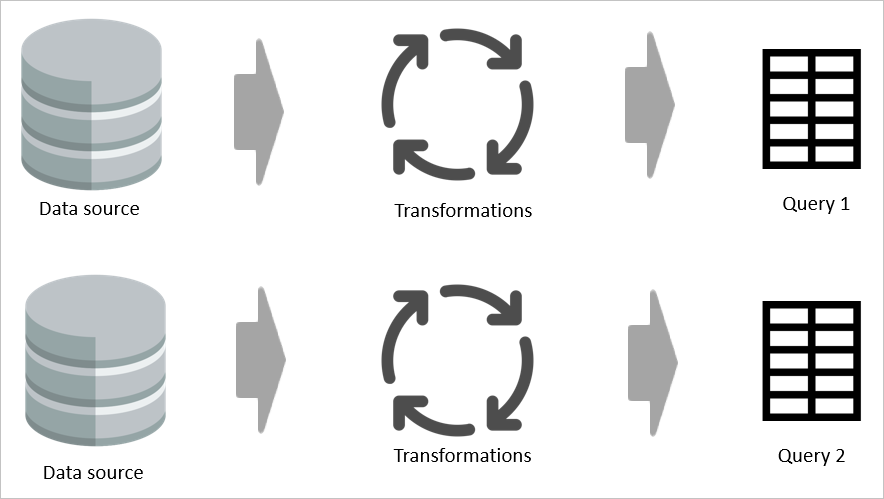
Sebbene sia possibile ripetere due volte le query che hanno creato una tabella e applicare nuove trasformazioni, questo approccio presenta svantaggi: i dati vengono inseriti due volte e il carico sull'origine dati viene raddoppiato.
Le tabelle calcolate risolvono entrambi i problemi. Le tabelle calcolate sono simili ad altre tabelle in quanto ottengono dati da un'origine ed è possibile applicare ulteriori trasformazioni per crearle. I dati provengono tuttavia dal flusso di dati di archiviazione usato e non dall'origine dati originale. Ovvero, sono stati creati in precedenza da un flusso di dati e quindi riutilizzati.
Le tabelle calcolate possono essere create facendo riferimento a una tabella nello stesso flusso di dati o facendo riferimento a una tabella creata in un flusso di dati diverso.

Perché usare una tabella calcolata?
L'esecuzione di tutti i passaggi di trasformazione in una tabella può essere lenta. Possono esserci molti motivi per questo rallentamento: l'origine dati potrebbe essere lenta o le trasformazioni che si stanno eseguendo potrebbero dover essere replicate in due o più query. Potrebbe essere vantaggioso inserire prima i dati dall'origine e quindi riutilizzarlo in una o più tabelle. In questi casi, è possibile scegliere di creare due tabelle: una che recupera i dati dall'origine dati e un'altra, una tabella calcolata, che applica più trasformazioni ai dati già scritti nel data lake usato da un flusso di dati. Questa modifica può aumentare le prestazioni e il riutilizzo dei dati, risparmiando tempo e risorse.
Ad esempio, se due tabelle condividono anche una parte della logica di trasformazione, senza una tabella calcolata, la trasformazione deve essere eseguita due volte.
Tuttavia, se viene usata una tabella calcolata, la parte comune (condivisa) della trasformazione viene elaborata una sola volta e archiviata in Azure Data Lake Storage. Le trasformazioni rimanenti vengono quindi elaborate dall'output della trasformazione comune. In generale, questa elaborazione è molto più veloce.
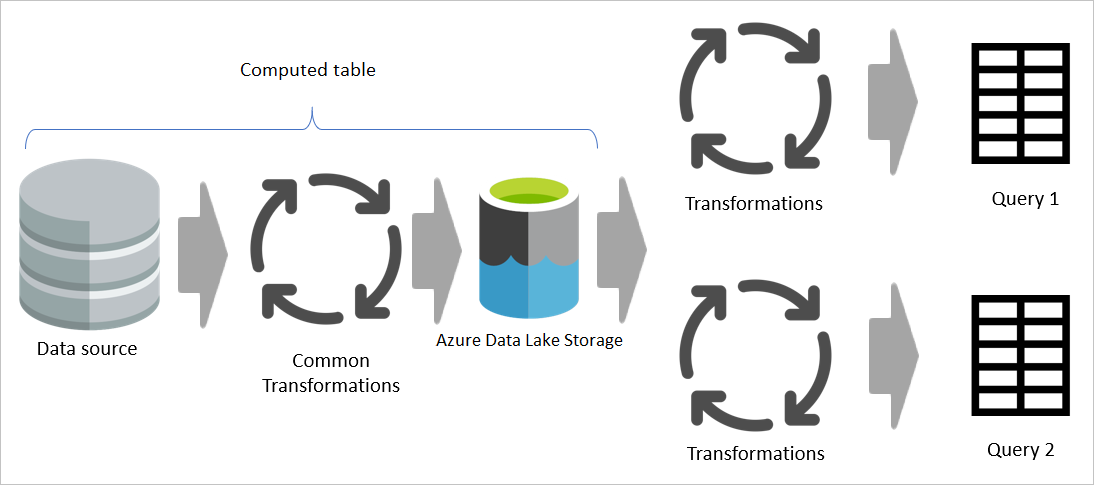
Una tabella calcolata fornisce un'unica posizione come codice sorgente per la trasformazione e accelera la trasformazione perché deve essere eseguita una sola volta anziché più volte. Anche il carico sull'origine dati viene ridotto.
Scenario di esempio per l'uso di una tabella calcolata
Se si compila una tabella aggregata in Power BI per velocizzare il modello di dati, è possibile compilare la tabella aggregata facendo riferimento alla tabella originale e applicando altre trasformazioni. Usando questo approccio, non è necessario replicare la trasformazione dall'origine (la parte che proviene dalla tabella originale).
Ad esempio, la figura seguente mostra una tabella Orders.

Usando un riferimento da questa tabella, è possibile creare una tabella calcolata.
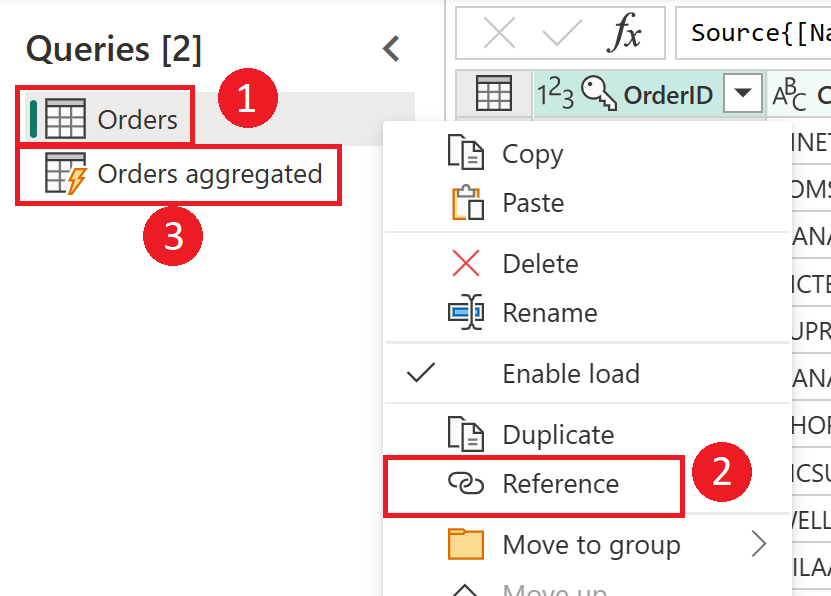
Screenshot che mostra come creare una tabella calcolata dalla tabella Orders. Fare prima clic con il pulsante destro del mouse sulla tabella Orders nel riquadro Query, selezionare l'opzione Riferimento dal menu a discesa. Questa azione crea la tabella calcolata, rinominata qui in Ordini aggregati.
La tabella calcolata può avere ulteriori trasformazioni. Ad esempio, è possibile usare Group By per aggregare i dati a livello di cliente.
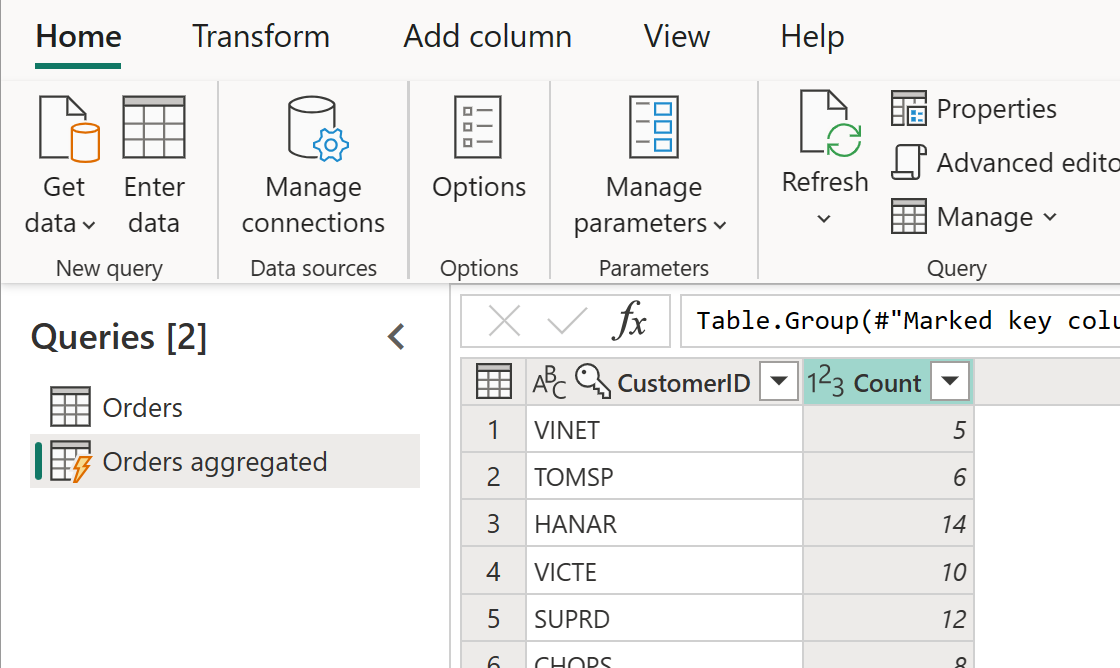
Ciò significa che la tabella Orders Aggregated recupera i dati dalla tabella Orders e non nuovamente dall'origine dati. Poiché alcune delle trasformazioni che devono essere eseguite sono già state eseguite nella tabella Orders, le prestazioni sono migliori e la trasformazione dei dati è più veloce.
Tabella calcolata in altri flussi di dati
È anche possibile creare una tabella calcolata in altri flussi di dati. Può essere creato recuperando dati da un flusso di dati con il connettore di flussi di dati di Microsoft Power Platform.
L'immagine evidenzia il connettore dei flussi di dati di Power Platform dalla finestra di scelta dell'origine dati di Power Query. È inclusa anche una descrizione che indica che una tabella del flusso di dati può essere compilata sopra i dati di un'altra tabella del flusso di dati, che è già persistente nell'archiviazione.
Il concetto della tabella calcolata consiste nel rendere persistente una tabella nell'archiviazione e in altre tabelle di origine, in modo da ridurre il tempo di lettura dall'origine dati e condividere alcune delle trasformazioni comuni. Questa riduzione può essere ottenuta recuperando dati da altri flussi di dati tramite il connettore del flusso di dati o facendo riferimento a un'altra query nello stesso flusso di dati.
Tabella calcolata: con trasformazioni o senza?
Ora che si sa che le tabelle calcolate sono ideali per migliorare le prestazioni della trasformazione dei dati, una buona domanda da porre è se le trasformazioni devono essere sempre posticipate alla tabella calcolata o se devono essere applicate alla tabella di origine. Vale a dire, i dati devono essere sempre inseriti in una tabella e quindi trasformati in una tabella calcolata? Quali sono i vantaggi e i svantaggi?
Caricare dati senza trasformazione per file di testo/CSV
Quando un'origine dati non supporta la riduzione delle query ,ad esempio file di testo/CSV, l'applicazione di trasformazioni durante l'acquisizione di dati dall'origine è poco utile, soprattutto se i volumi di dati sono di grandi dimensioni. La tabella di origine deve semplicemente caricare i dati dal file Text/CSV senza applicare alcuna trasformazione. Le tabelle calcolate possono quindi ottenere dati dalla tabella di origine ed eseguire la trasformazione sui dati inseriti.
Si potrebbe chiedere, qual è il valore della creazione di una tabella di origine che inserisce solo i dati? Una tabella di questo tipo può comunque essere utile, perché se i dati dell'origine vengono usati in più tabelle, riduce il carico sull'origine dati. Inoltre, i dati possono ora essere riutilizzati da altri utenti e flussi di dati. Le tabelle calcolate sono particolarmente utili negli scenari in cui il volume di dati è di grandi dimensioni o quando si accede a un'origine dati tramite un gateway dati locale, perché riducono il traffico dal gateway e il carico sulle origini dati sottostanti.
Eseguire alcune delle trasformazioni comuni per una tabella SQL
Se l'origine dati supporta il folding delle query, è consigliabile eseguire alcune delle trasformazioni nella tabella di origine perché la query viene eseguita sull'origine dati e solo i dati trasformati vengono recuperati da essa. Queste modifiche migliorano le prestazioni complessive. Il gruppo di trasformazioni che è comune nelle tabelle calcolate downstream dovrebbe essere applicato alla tabella di origine, in modo che possano essere riportate all'origine. Altre trasformazioni applicabili solo alle tabelle downstream devono essere eseguite nelle tabelle calcolate.