Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Annotazioni
I livelli di privacy non sono attualmente disponibili nei flussi di dati di Power Platform, ma il team del prodotto sta lavorando per abilitare questa funzionalità.
Se hai usato Power Query per un certo periodo, è probabile che tu abbia fatto questa esperienza. Stai effettuando query quando improvvisamente ricevi un errore che nessuna ricerca online, modifica delle query o martellare sulla tastiera può rimediare. Un errore simile al seguente:
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
O forse:
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Questi Formula.Firewall errori sono il risultato del firewall per la privacy dei dati di Power Query (noto anche come firewall), che a volte può sembrare che esista solo per frustrare gli analisti dei dati in tutto il mondo. Crederci o meno, tuttavia, il firewall serve uno scopo importante. In questo articolo si apprenderà meglio come funziona. Grazie a una maggiore comprensione, si spera di poter diagnosticare e correggere meglio gli errori del firewall in futuro.
Che cos'è?
Lo scopo del firewall per la privacy dei dati è semplice: esiste per impedire a Power Query di perdere involontariamente dati tra origini.
Perché è necessario? Insomma, potresti certamente creare alcuni M che passerebbero un valore SQL a un feed OData. Ma questa sarebbe una perdita intenzionale di dati. L'autore del mashup (o almeno dovrebbe) sapere che stava facendo questo. Perché quindi la necessità di protezione contro la perdita involontaria di dati?
La risposta? Ripiegamento.
Ripiegabile?
La riduzione è un termine che fa riferimento alla conversione di espressioni in M (ad esempio filtri, ridenominazione, join e così via) in operazioni su un'origine dati non elaborata (ad esempio SQL, OData e così via). Una parte importante della potenza di Power Query deriva dal fatto che Power Query può convertire le operazioni eseguite da un utente tramite l'interfaccia utente in linguaggi SQL complessi o in altri linguaggi di origine dati back-end, senza che l'utente abbia la necessità di conoscere le lingue indicate. Gli utenti ottengono il vantaggio delle prestazioni delle operazioni native dell'origine dati, con la facilità d'uso di un'interfaccia utente in cui tutte le origini dati possono essere trasformate usando un set comune di comandi.
Come parte del folding, Power Query talvolta potrebbe determinare che il modo più efficiente per eseguire un determinato mashup consiste nell'acquisire dati da un'origine e passarli a un'altra. Ad esempio, se si aggiunge un piccolo file CSV a una tabella SQL enorme, probabilmente non si vuole che Power Query legga il file CSV, legga l'intera tabella SQL e quindi le unisce nel computer locale. È probabile che Power Query inline i dati CSV in un'istruzione SQL e chieda al database SQL di eseguire il join.
Questo è il modo in cui può verificarsi una perdita di dati involontaria.
Si supponga di aggiungere dati SQL che includevano i numeri di previdenza sociale dei dipendenti con i risultati di un feed OData esterno e si scoprì improvvisamente che i numeri di previdenza sociale da SQL venivano inviati al servizio OData. Brutte notizie, giusto?
Questo è il tipo di scenario che il firewall deve impedire.
Come funziona?
Il firewall esiste per impedire che i dati di un'origine vengano inviati involontariamente a un'altra origine. Abbastanza semplice.
Quindi, come fa a compiere questa missione?
A tale scopo, suddividere le query M in un elemento denominato partizioni e quindi applicare la regola seguente:
- Una partizione può accedere a origini dati compatibili o fare riferimento ad altre partizioni, ma non a entrambe.
Semplice... ma confuso. Che cos'è una partizione? Che cosa rende due origini dati "compatibili"? E perché il firewall deve prestare attenzione se una partizione vuole accedere a un'origine dati e fare riferimento a una partizione?
Analizziamo la regola precedente passo dopo passo, spezzettandola in parti.
Che cos'è una partizione?
Al livello più semplice, una partizione è solo una raccolta di uno o più passaggi di query. La partizione più granulare possibile (almeno nell'implementazione corrente) è un singolo passaggio. Le partizioni più grandi possono talvolta includere più query. Altre informazioni su questo argomento più avanti.
Se non si ha familiarità con i passaggi, è possibile visualizzarli a destra della finestra dell'editor di Power Query dopo aver selezionato una query nel riquadro Passaggi applicati . I passaggi consentono di tenere traccia di tutto ciò che si esegue per trasformare i dati nella forma finale.
Partizioni che fanno riferimento ad altre partizioni
Quando una query viene valutata con il firewall attivo, il firewall divide la query e tutte le relative dipendenze in partizioni, ovvero gruppi di fasi. Ogni volta che una partizione fa riferimento a un elemento in un'altra partizione, il firewall sostituisce il riferimento con una chiamata a una funzione speciale denominata Value.Firewall. In altre parole, il firewall non consente alle partizioni di accedere direttamente tra loro. Tutti i riferimenti vengono modificati per passare attraverso il firewall. Si pensi al firewall come un guardiano. Una partizione che fa riferimento a un'altra partizione deve ottenere l'autorizzazione del firewall per farlo e il firewall controlla se i dati a cui si fa riferimento sono consentiti nella partizione.
Tutto questo potrebbe sembrare piuttosto astratto, quindi diamo un esempio.
Si supponga di avere una query denominata Employees, che esegue il pull di alcuni dati da un database SQL. Si supponga di avere anche un'altra query (EmployeesReference), che fa semplicemente riferimento ai dipendenti.
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Employees
in
Source;
Queste query vengono suddivise in due partizioni: una per la query Employees e una per la query EmployeesReference (che fa riferimento alla partizione Employees). Quando si valuta con il firewall attivato, queste query vengono riscritte come segue:
shared Employees = let
Source = Sql.Database(…),
EmployeesTable = …
in
EmployeesTable;
shared EmployeesReference = let
Source = Value.Firewall("Section1/Employees")
in
Source;
Si noti che il riferimento semplice alla query Employees viene sostituito da una chiamata a Value.Firewall, a cui viene fornito il nome completo della query Employees.
Quando employeesReference viene valutato, il firewall intercetta la chiamata a Value.Firewall("Section1/Employees"), che ora ha la possibilità di controllare se (e come) i dati richiesti passano alla partizione EmployeesReference. Può eseguire un numero qualsiasi di operazioni: negare la richiesta, mettere in buffer i dati richiesti (che impedisce ulteriori trasferimenti all'origine dati originale) e così via.
Questo è il modo in cui il firewall mantiene il controllo sul flusso di dati tra le partizioni.
Partizioni che accedono direttamente alle origini dati
Si supponga di definire una query Query1 con un passaggio (si noti che questa query in un unico passaggio corrisponde a una partizione firewall) e che questo singolo passaggio accede a due origini dati: una tabella di database SQL e un file CSV. In che modo il firewall gestisce questo problema, poiché non esiste alcun riferimento alla partizione e quindi non ci sono chiamate a Value.Firewall che possa intercettare? Si esaminerà ora la regola indicata in precedenza:
- Una partizione può accedere a origini dati compatibili o fare riferimento ad altre partizioni, ma non entrambe.
Per consentire l'esecuzione della query single-partition-but-two-data-sources, le due origini dati devono essere "compatibili". In altre parole, deve essere corretto che i dati vengano condivisi in modo bidirezionale tra di essi. Ciò significa che i livelli di privacy di entrambe le origini devono essere Pubblici o entrambi essere Organizzativi, poiché sono le uniche due combinazioni che consentono la condivisione in entrambe le direzioni. Se entrambe le origini sono contrassegnate come Private o una è contrassegnata come Public e una è contrassegnata come Organizzazione oppure viene contrassegnata con un'altra combinazione di livelli di privacy, la condivisione bidirezionale non è consentita. Non è sicuro per entrambi essere valutati nella stessa partizione. In questo modo si potrebbe verificare una fuga di dati (a causa del folding) e il firewall non avrebbe alcun modo per impedirlo.
Cosa accade se si tenta di accedere a origini dati incompatibili nella stessa partizione?
Formula.Firewall: Query 'Query1' (step 'Source') is accessing data sources that have privacy levels which cannot be used together. Please rebuild this data combination.
Si spera ora di comprendere meglio uno dei messaggi di errore elencati all'inizio di questo articolo.
Questo requisito di compatibilità si applica solo all'interno di una determinata partizione. Se una partizione fa riferimento ad altre partizioni, le origini dati delle partizioni a cui si fa riferimento non devono essere compatibili tra loro. Questo perché il firewall può memorizzare nel buffer i dati, impedendo così una ulteriore riduzione rispetto all'origine dati originale. I dati vengono caricati in memoria e trattati come se provenissero da nessuna parte.
Perché non fare entrambe?
Si supponga di definire una query con un passaggio (che corrisponde di nuovo a una partizione) che accede a due altre query, ovvero due altre partizioni. Cosa accade se si desiderasse, nello stesso passaggio, anche per accedere direttamente a un database SQL? Perché una partizione non può fare riferimento ad altre partizioni e accedere direttamente a origini dati compatibili?
Come illustrato in precedenza, quando una partizione fa riferimento a un'altra partizione, il firewall funge da gatekeeper per tutti i dati che passano alla partizione. A tale scopo, deve essere in grado di controllare i dati consentiti. Se ci sono origini dati accessibili all'interno della partizione e un flusso di dati in arrivo da altre partizioni, questa perde la capacità di essere il gatekeeper, poiché il flusso di dati in entrata potrebbe essere divulgato a una delle origini dati interamente accessibili senza che se ne accorga. Di conseguenza, il firewall impedisce a una partizione che accede ad altre partizioni di accedere direttamente a qualsiasi origine dati.
Cosa accade quindi se una partizione tenta di fare riferimento ad altre partizioni e di accedere direttamente alle origini dati?
Formula.Firewall: Query 'Query1' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Ora si spera di comprendere meglio l'altro messaggio di errore elencato all'inizio di questo articolo.
Partizioni approfondite
Come probabilmente si può immaginare dalle informazioni precedenti, il modo in cui le query vengono partizionate finisce per essere incredibilmente importante. Se sono presenti alcuni passaggi che fanno riferimento ad altre query e altri passaggi che accedono alle origini dati, si spera ora di riconoscere che il disegno dei limiti delle partizioni in determinate posizioni causa errori del firewall, mentre la creazione in altre posizioni consente l'esecuzione della query solo correttamente.
In che modo le query vengono partizionate esattamente?
Questa sezione è probabilmente la più importante per comprendere il motivo per cui vengono visualizzati gli errori del firewall e comprendere come risolverli (laddove possibile).
Ecco un riepilogo generale della logica di partizionamento.
- Partizionamento iniziale
- Crea una partizione per ciascun passaggio di ogni query
- Fase statica
- Questa fase non dipende dai risultati della valutazione. Si basa invece sul modo in cui le query sono strutturate.
- Taglio dei parametri
- Taglia le partizioni simili a parametri, ovvero quelle che:
- Non fa riferimento ad altre partizioni
- Non contiene chiamate di funzione
- Non è ciclico (vale a dire, non si riferisce a se stesso)
- Si noti che la "rimozione" di una partizione lo include in modo efficace in qualsiasi altra partizione vi faccia riferimento.
- La rifilatura delle partizioni dei parametri consente il funzionamento dei riferimenti ai parametri usati nelle chiamate di funzione alla sorgente dati, ad esempio
Web.Contents(myUrl), invece di generare errori del tipo "la partizione non può fare riferimento a origini dati e altri passaggi".
- Taglia le partizioni simili a parametri, ovvero quelle che:
- Raggruppamento (statico)
- Le partizioni vengono unite in ordine di dipendenza inferiore. Nelle partizioni unite risultanti, le seguenti sono separate:
- Partizioni in query diverse
- Partizioni che non fanno riferimento ad altre partizioni (e pertanto sono autorizzate ad accedere a un'origine dati)
- Le partizioni che fanno riferimento ad altre partizioni (e sono pertanto escluse dall'accesso a una fonte dati)
- Le partizioni vengono unite in ordine di dipendenza inferiore. Nelle partizioni unite risultanti, le seguenti sono separate:
- Taglio dei parametri
- Questa fase non dipende dai risultati della valutazione. Si basa invece sul modo in cui le query sono strutturate.
- Fase dinamica
- Questa fase dipende dai risultati della valutazione, incluse le informazioni sulle origini dati a cui accedono varie partizioni.
- Taglio
- Taglia le partizioni che soddisfano tutti i requisiti seguenti:
- Non accede ad alcuna origine dati
- Non fa riferimento ad alcuna partizione che accede alle origini dati
- Non è ciclico
- Taglia le partizioni che soddisfano tutti i requisiti seguenti:
- Raggruppamento (dinamico)
- Ora che le partizioni non necessarie vengono tagliate, provare a creare partizioni di origine il più grandi possibile. Questa creazione viene eseguita unendo le partizioni usando le stesse regole descritte nella fase di raggruppamento statica precedente.
Cosa significa tutto questo?
Verrà ora illustrato un esempio per illustrare il funzionamento della logica complessa illustrata in precedenza.
Ecco uno scenario di esempio. Si tratta di un'unione piuttosto semplice di un file di testo (Contatti) con un database SQL (Dipendenti), in cui SQL Server è un parametro (DbServer).
Le tre query
Ecco il codice M per le tre query usate in questo esempio.
shared DbServer = "MySqlServer" meta [IsParameterQuery=true, Type="Text", IsParameterQueryRequired=true];
shared Contacts = let
Source = Csv.Document(File.Contents(
"C:\contacts.txt"),[Delimiter=" ", Columns=15, Encoding=1252, QuoteStyle=QuoteStyle.None]
),
#"Promoted Headers" = Table.PromoteHeaders(Source, [PromoteAllScalars=true]),
#"Changed Type" = Table.TransformColumnTypes(
#"Promoted Headers",
{
{"ContactID", Int64.Type},
{"NameStyle", type logical},
{"Title", type text},
{"FirstName", type text},
{"MiddleName", type text},
{"LastName", type text},
{"Suffix", type text},
{"EmailAddress", type text},
{"EmailPromotion", Int64.Type},
{"Phone", type text},
{"PasswordHash", type text},
{"PasswordSalt", type text},
{"AdditionalContactInfo", type text},
{"rowguid", type text},
{"ModifiedDate", type datetime}
}
)
in
#"Changed Type";
shared Employees = let
Source = Sql.Databases(DbServer),
AdventureWorks = Source{[Name="AdventureWorks"]}[Data],
HumanResources_Employee = AdventureWorks{[Schema="HumanResources",Item="Employee"]}[Data],
#"Removed Columns" = Table.RemoveColumns(
HumanResources_Employee,
{
"HumanResources.Employee(EmployeeID)",
"HumanResources.Employee(ManagerID)",
"HumanResources.EmployeeAddress",
"HumanResources.EmployeeDepartmentHistory",
"HumanResources.EmployeePayHistory",
"HumanResources.JobCandidate",
"Person.Contact",
"Purchasing.PurchaseOrderHeader",
"Sales.SalesPerson"
}
),
#"Merged Queries" = Table.NestedJoin(
#"Removed Columns",
{"ContactID"},
Contacts,
{"ContactID"},
"Contacts",
JoinKind.LeftOuter
),
#"Expanded Contacts" = Table.ExpandTableColumn(
#"Merged Queries",
"Contacts",
{"EmailAddress"},
{"EmailAddress"}
)
in
#"Expanded Contacts";
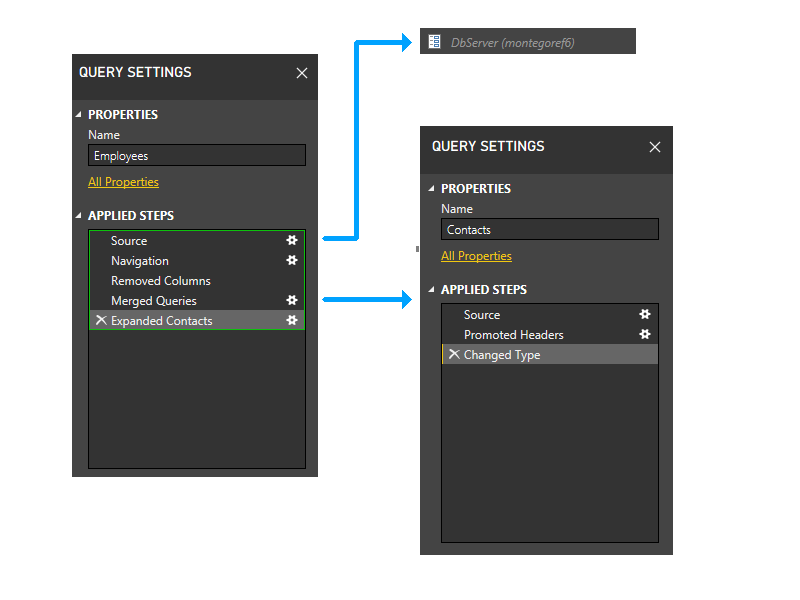
Ecco una visualizzazione di livello superiore, che mostra le dipendenze.
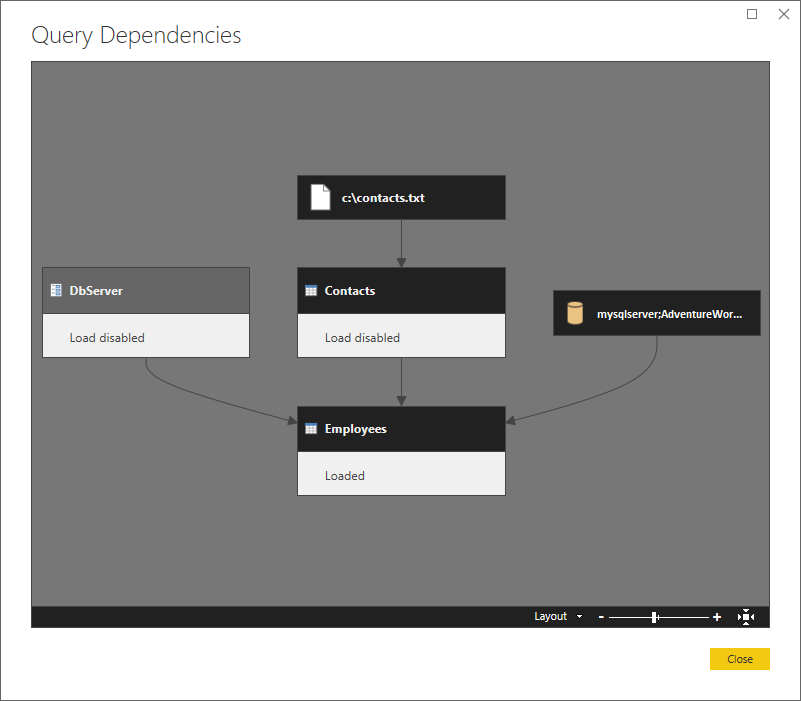
Facciamo la partizione
Ingrandisciamoci un po' e includiamo i passaggi nell'immagine e iniziamo a seguire la logica di partizionamento. Ecco un diagramma delle tre query, che mostra le partizioni del firewall iniziali in verde. Si noti che ogni passaggio inizia nella propria partizione.
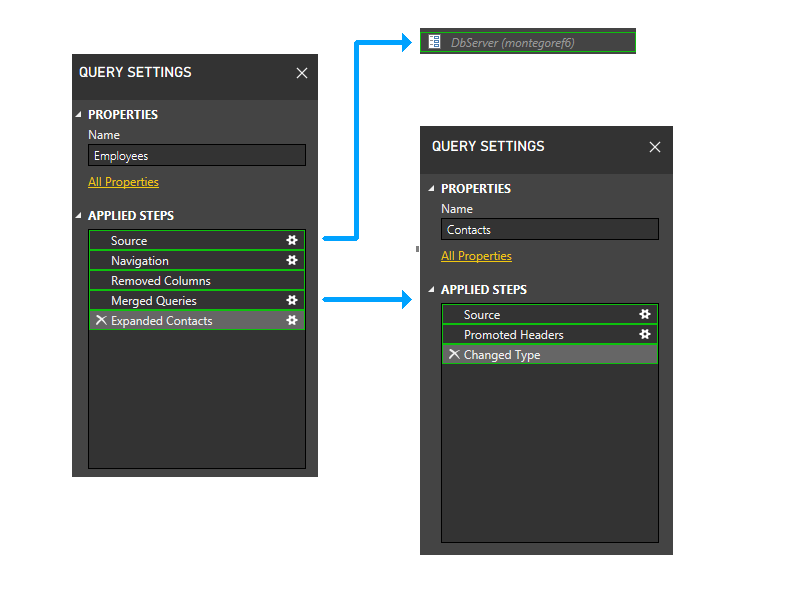
Successivamente, verranno tagliate le partizioni dei parametri. DbServer viene quindi incluso in modo implicito nella partizione di origine.
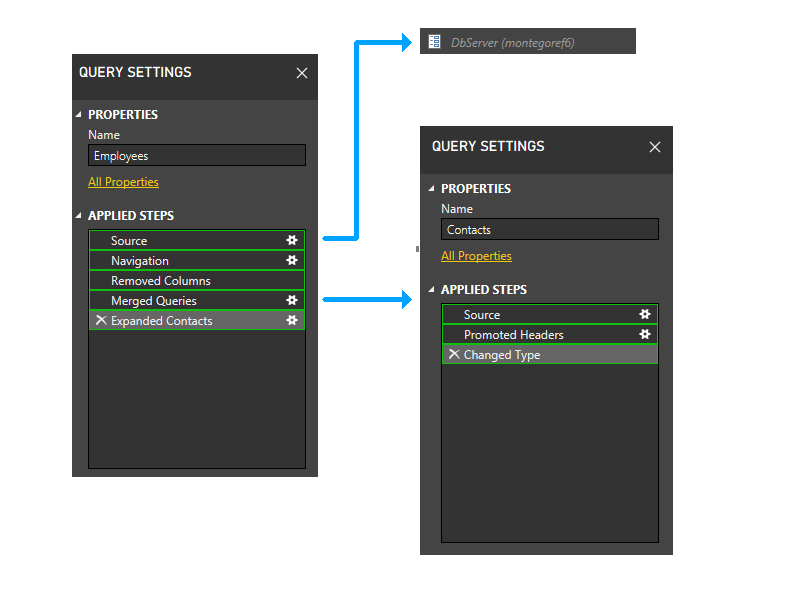
Ora si esegue il raggruppamento statico. Questo raggruppamento mantiene la separazione tra le partizioni in query separate (si noti, ad esempio, che gli ultimi due passaggi di Employees non vengono raggruppati con i passaggi di Contatti) e tra partizioni che fanno riferimento ad altre partizioni (ad esempio gli ultimi due passaggi di Dipendenti) e quelle che non lo fanno (ad esempio i primi tre passaggi dei dipendenti).
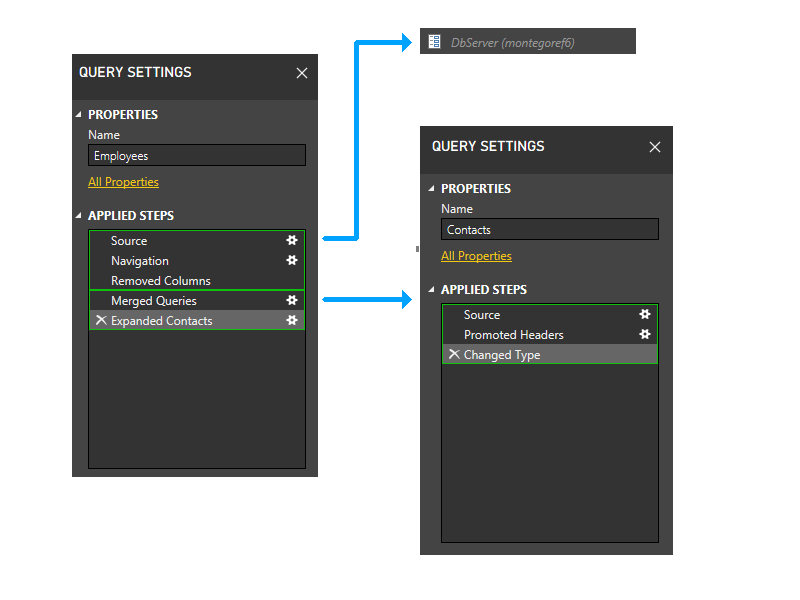
Ora si entra nella fase dinamica. In questa fase vengono valutate le partizioni statiche precedenti. Le partizioni che non accedono ad alcuna origine dati vengono tagliate. Le partizioni vengono quindi raggruppate per creare partizioni di origine il più grandi possibile. In questo scenario di esempio, tuttavia, tutte le partizioni rimanenti accedono alle origini dati e non è possibile eseguire ulteriori raggruppamenti. Le partizioni nell'esempio non cambiano quindi durante questa fase.
Facciamo finta
Per motivi di illustrazione, tuttavia, vediamo cosa accadrebbe se la query Contatti, invece di provenire da un file di testo, fosse hardcoded in M (ad esempio tramite la finestra di dialogo Immetti dati ).
In questo caso, la query Contatti non accede ad alcuna origine dati. Quindi, verrebbe tagliato durante la prima parte della fase dinamica.
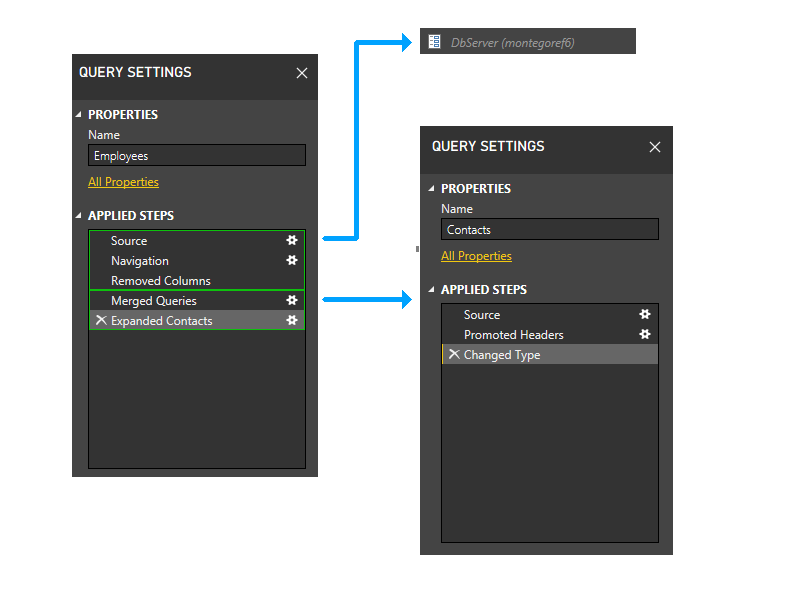
Con la partizione Contatti rimossa, gli ultimi due passaggi di Dipendenti non fanno più riferimento ad alcuna partizione, ad eccezione di quella contenente i primi tre passaggi di Dipendenti. Di conseguenza, le due partizioni verrebbero raggruppate.
La partizione risultante sarà simile alla seguente.
Esempio: Passaggio di dati da un'origine dati a un'altra
Va bene, basta con le spiegazioni astratte. Si esaminerà ora uno scenario comune in cui è probabile che si verifichi un errore del firewall e i passaggi per risolverlo.
Si supponga di voler cercare un nome di società dal servizio Northwind OData e quindi usare il nome della società per eseguire una ricerca Bing.
Creare prima di tutto una query company per recuperare il nome della società.
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName]
in
CHOPS
Successivamente, si crea una query di ricerca che fa riferimento a Company e la passa a Bing.
let
Source = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & Company))
in
Source
A questo punto, si verificano problemi. La valutazione della ricerca genera un errore del firewall.
Formula.Firewall: Query 'Search' (step 'Source') references other queries or steps, so it may not directly access a data source. Please rebuild this data combination.
Questo errore si verifica perché il passaggio Origine della Ricerca fa riferimento a un'origine dati (bing.com) e anche a un'altra query/partizione (Società). Viola la regola indicata in precedenza ("una partizione può accedere a origini dati compatibili o fare riferimento ad altre partizioni, ma non entrambe").
Cosa fare? Un'opzione consiste nel disabilitare completamente il firewall (tramite l'opzione Privacy etichettata Ignora i livelli di privacy e potenzialmente migliorare le prestazioni). Ma cosa succede se si vuole lasciare abilitato il firewall?
Per risolvere l'errore senza disabilitare il firewall, è possibile combinare Company e Search in una singola query, come illustrato di seguito:
let
Source = OData.Feed(
"https://services.odata.org/V4/Northwind/Northwind.svc/",
null,
[Implementation="2.0"]
),
Customers_table = Source{[Name="Customers",Signature="table"]}[Data],
CHOPS = Customers_table{[CustomerID="CHOPS"]}[CompanyName],
Search = Text.FromBinary(Web.Contents("https://www.bing.com/search?q=" & CHOPS))
in
Search
Tutto sta succedendo all'interno di una singola partizione. Supponendo che i livelli di privacy per le due origini dati siano compatibili, il firewall dovrebbe essere soddisfatto e non si riceve più un errore.
È finita
Anche se c'è molto di più che si potrebbe dire su questo argomento, questo articolo introduttivo è già abbastanza lungo. Si spera che venga fornita una migliore comprensione del firewall e consente di comprendere e correggere gli errori del firewall quando si verificano in futuro.