Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Sfondo
Nell'attuale momento, i modelli di intelligenza artificiale si stanno evolvendo per diventare più sostanziali, richiedendo una crescente domanda di hardware avanzato e un cluster di computer per un training efficiente dei modelli. HPC Pack consente di semplificare il lavoro di training del modello in modo efficace.
PyTorch Distributed Data Parallel (noto anche come DDP)
Per implementare il training dei modelli distribuiti, è necessario usare un framework di training distribuito. La scelta del framework dipende da quella usata per compilare il modello. In questo articolo ti guiderò su come procedere con PyTorch in HPC Pack.
PyTorch offre diversi metodi per il training distribuito. Tra questi, Distributed Data Parallel (DDP) è ampiamente preferibile a causa della sua semplicità e delle minime modifiche al codice necessarie per il modello di training a computer singolo corrente.
Configurare un cluster HPC Pack per il training del modello di intelligenza artificiale
È possibile configurare un cluster HPC Pack usando i computer locali o le macchine virtuali in Azure. Assicurati che questi computer siano dotati di GPU (in questo articolo useremo GPU Nvidia).
In genere, una GPU può avere un processo per un lavoro di training distribuito. Pertanto, se si dispone di due computer (ovvero nodi in un cluster di computer), ognuno dotato di quattro GPU, è possibile ottenere 2 * 4, che è uguale a 8, processi paralleli per un singolo training del modello. Questa configurazione può potenzialmente ridurre il tempo di training a circa 1/8 rispetto al training di un singolo processo, omettendo alcuni sovraccarichi di sincronizzazione dei dati tra i processi.
Creare un cluster HPC Pack nel modello di Resource Manager
Per semplicità, è possibile avviare un nuovo cluster HPC Pack in Azure, in modelli arm in GitHub.
Selezionare il modello "Cluster a nodo head singolo per carichi di lavoro Linux" e fare clic su "Distribuisci in Azure"
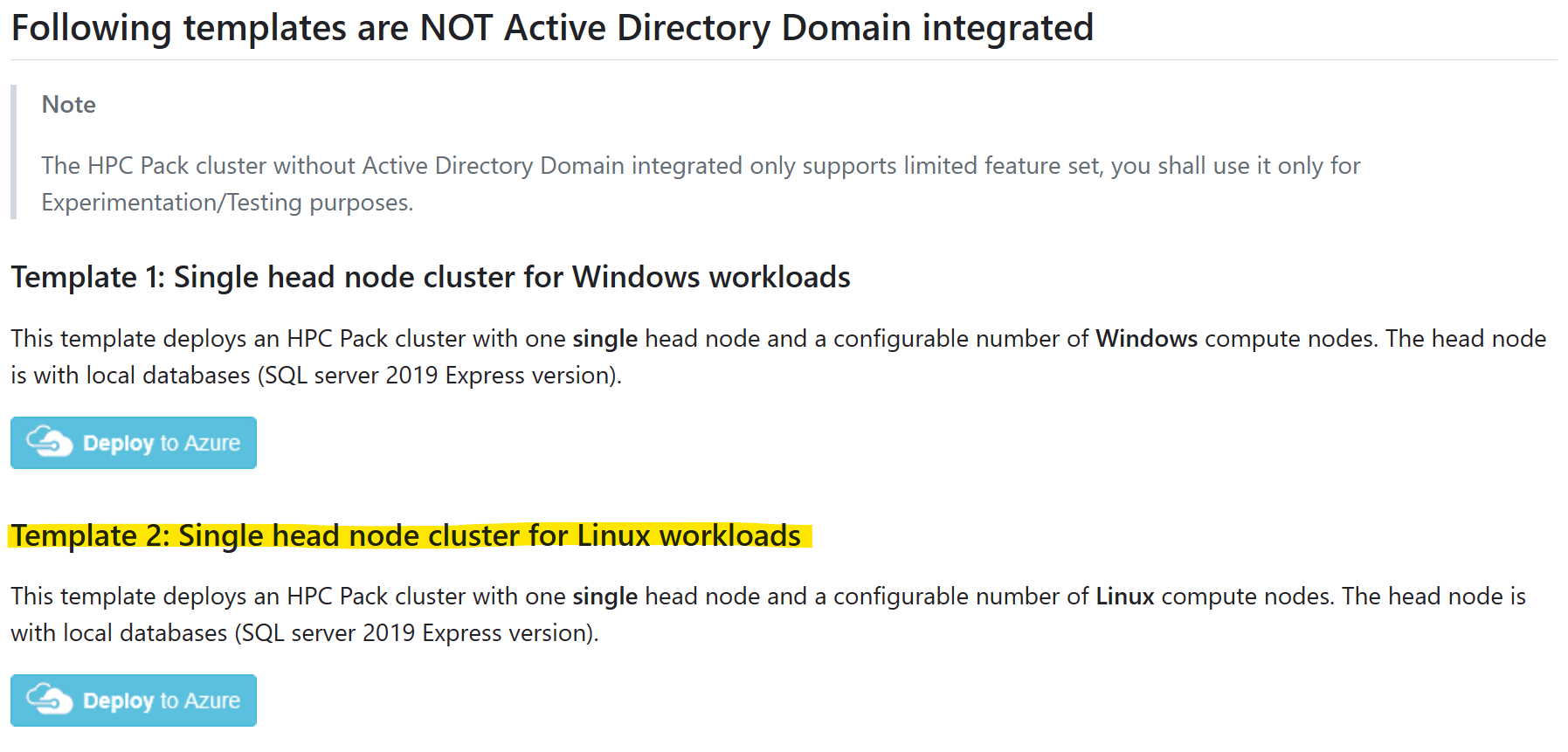
Per informazioni su come creare e caricare un certificato per l'uso di HPC Pack, vedere i prerequisiti
Si prega di notare:
Selezionare un'immagine del nodo di calcolo contrassegnata con "HPC". Ciò indica che i driver GPU sono preinstallati nell'immagine. In caso contrario, sarebbe necessaria l'installazione manuale del driver GPU in un nodo di calcolo in una fase successiva, che potrebbe rivelarsi un'attività complessa a causa della complessità dell'installazione del driver GPU. Altre informazioni sulle immagini HPC sono disponibili qui.
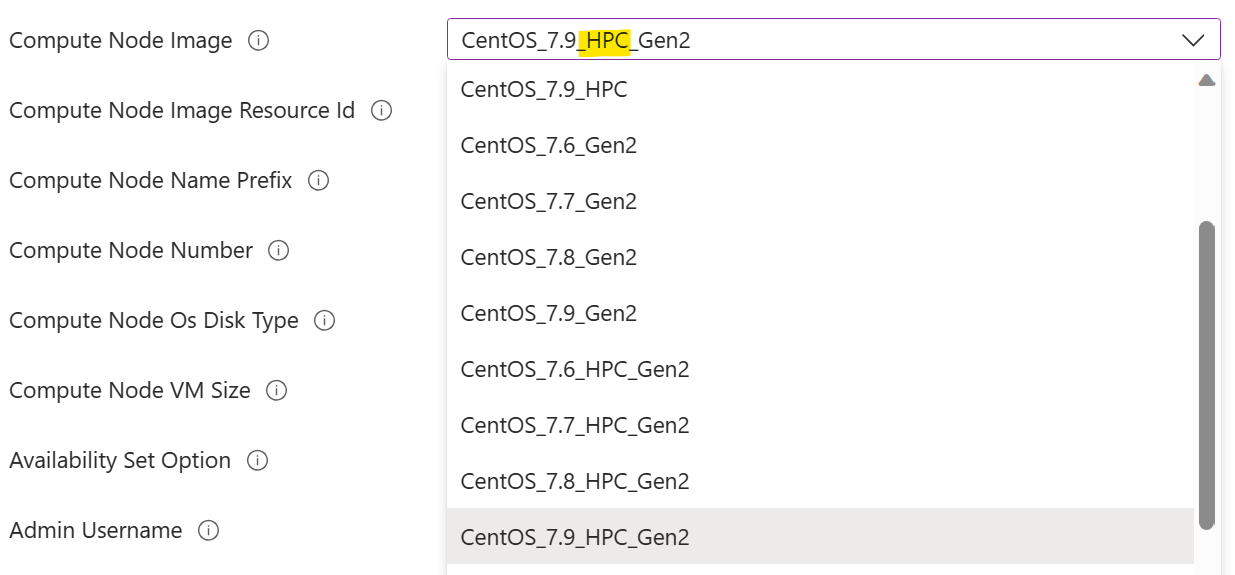
È consigliabile selezionare una dimensione di macchina virtuale del nodo di calcolo con GPU. Ovvero dimensioni della macchina virtuale serie N.
 GPU
GPU
Installare PyTorch nei nodi di calcolo
In ogni nodo di calcolo installare PyTorch con il comando
pip3 install torch torchvision torchaudio
Suggerimenti: è possibile sfruttare HPC Pack "Esegui comando" per eseguire un comando in un set di nodi del cluster in parallelo.
Configurare una directory condivisa
Prima di poter eseguire un processo di training, è necessaria una directory condivisa accessibile da tutti i nodi di calcolo. La directory viene usata per il codice di training e i dati (sia il set di dati di input che il modello sottoposto a training di output).
È possibile configurare una directory di condivisione SMB in un nodo head e quindi montarla in ogni nodo di calcolo con cifs, come illustrato di seguito:
In un nodo head creare una directory
appin%CCP_DATA%\SpoolDir, che è già condivisa comeCcpSpoolDirda HPC Pack per impostazione predefinita.In un nodo di calcolo montare la directory
app, ad esempiosudo mkdir /app sudo mount -t cifs //<your head node name>/CcpSpoolDir/app /app -o vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777NOTA:
- L'opzione
passwordpuò essere omessa in una shell interattiva. In tal caso, verrà richiesto di specificarlo. - Il
dir_modeefile_modeè impostato su 0777, in modo che qualsiasi utente Linux possa leggerlo/scriverlo. È possibile un'autorizzazione con restrizioni, ma più complessa da configurare.
- L'opzione
Facoltativamente, rendere il montaggio in modo permanente aggiungendo una linea in
/etc/fstabcome//<your head node name>/CcpSpoolDir/app cifs vers=2.1,domain=<hpc admin domain>,username=<hpc admin>,password=<your password>,dir_mode=0777,file_mode=0777 0 2Qui è necessario il
password.
Eseguire un processo di training
Si supponga di avere ora due nodi di calcolo Linux, ognuno con quattro GPU NVidia v100. Ed è stato installato PyTorch in ogni nodo. È stata configurata anche una directory condivisa "app". Ora possiamo iniziare il nostro lavoro di formazione.
Qui sto usando un semplice modello di toy basato su PyTorch DDP. È possibile ottenere il codice in GitHub.
Scaricare i file seguenti nella directory condivisa %CCP_DATA%\SpoolDir\app nel nodo head
- neural_network.py
- operations.py
- run_ddp.py
Creare quindi un processo con Node come unità di risorsa e due nodi per il processo, ad esempio

Specificare due nodi con GPU in modo esplicito, ad esempio
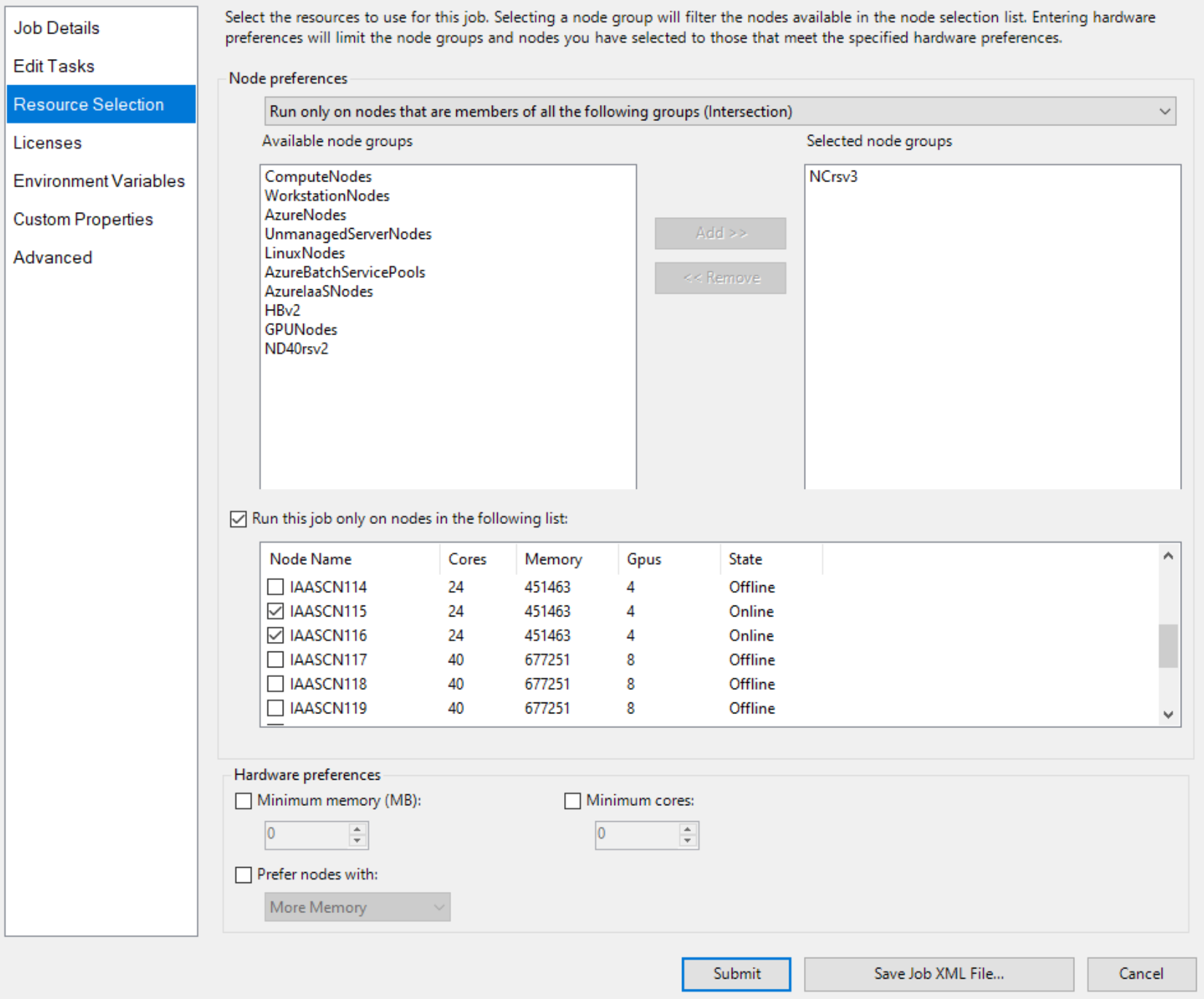
Aggiungere quindi attività di processo, ad esempio
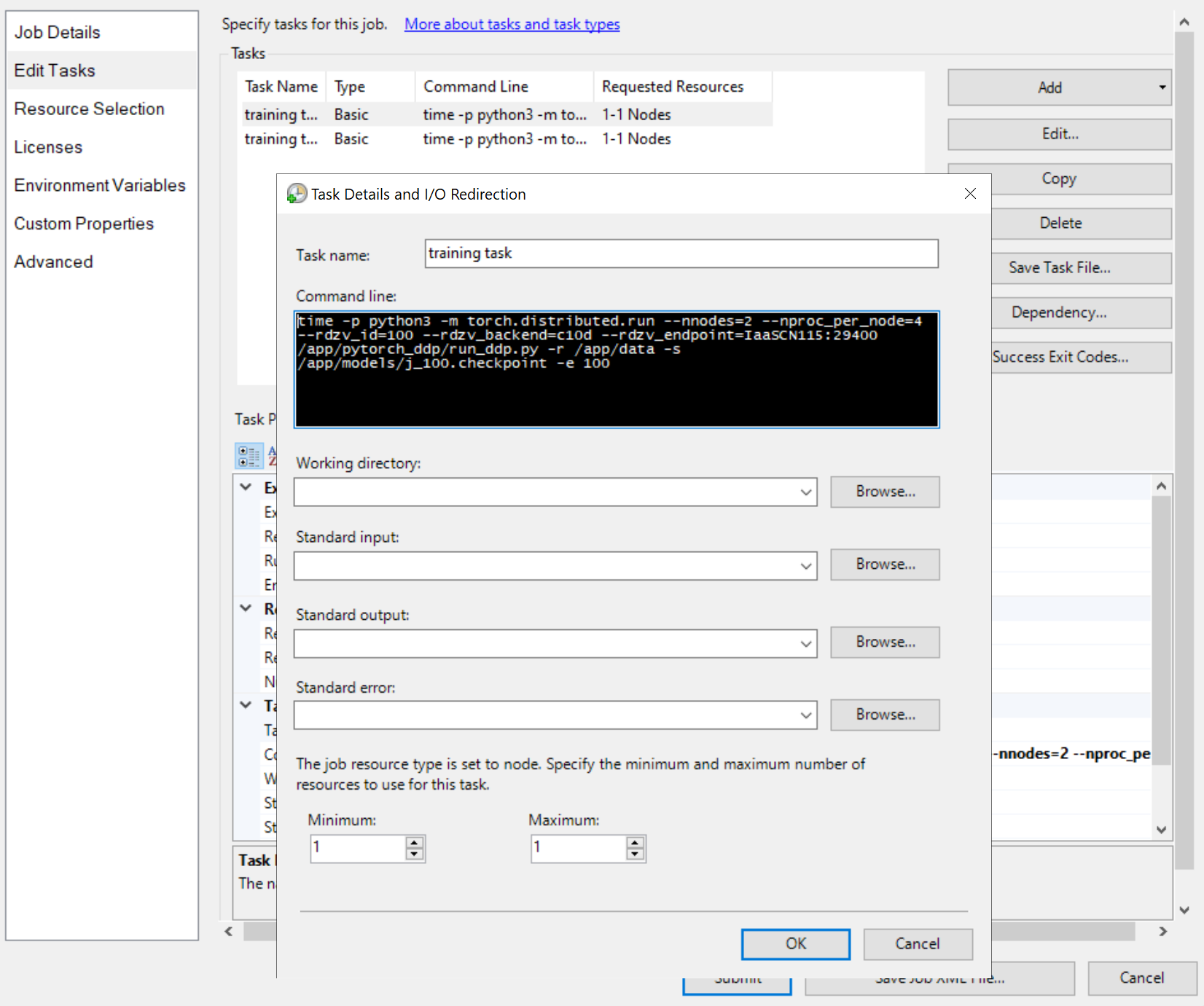
Le righe di comando delle attività sono tutte uguali, ad esempio
python3 -m torch.distributed.run --nnodes=<the number of compute nodes> --nproc_per_node=<the processes on each node> --rdzv_id=100 --rdzv_backend=c10d --rdzv_endpoint=<a node name>:29400 /app/run_ddp.py
-
nnodesspecifica il numero di nodi di calcolo per il processo di training. -
nproc_per_nodespecifica il numero di processi in ogni nodo di calcolo. Non può superare il numero di GPU in un nodo. Ovvero, una GPU può avere al massimo un processo. -
rdzv_endpointspecifica un nome e una porta di un nodo che funge da rendezvous. Qualsiasi nodo del processo di training può funzionare. - "/app/run_ddp.py" è il percorso del file di codice di training. Tenere presente che
/appè una directory condivisa nel nodo head.
Inviare il processo e attendere il risultato. È possibile visualizzare le attività in esecuzione, ad esempio
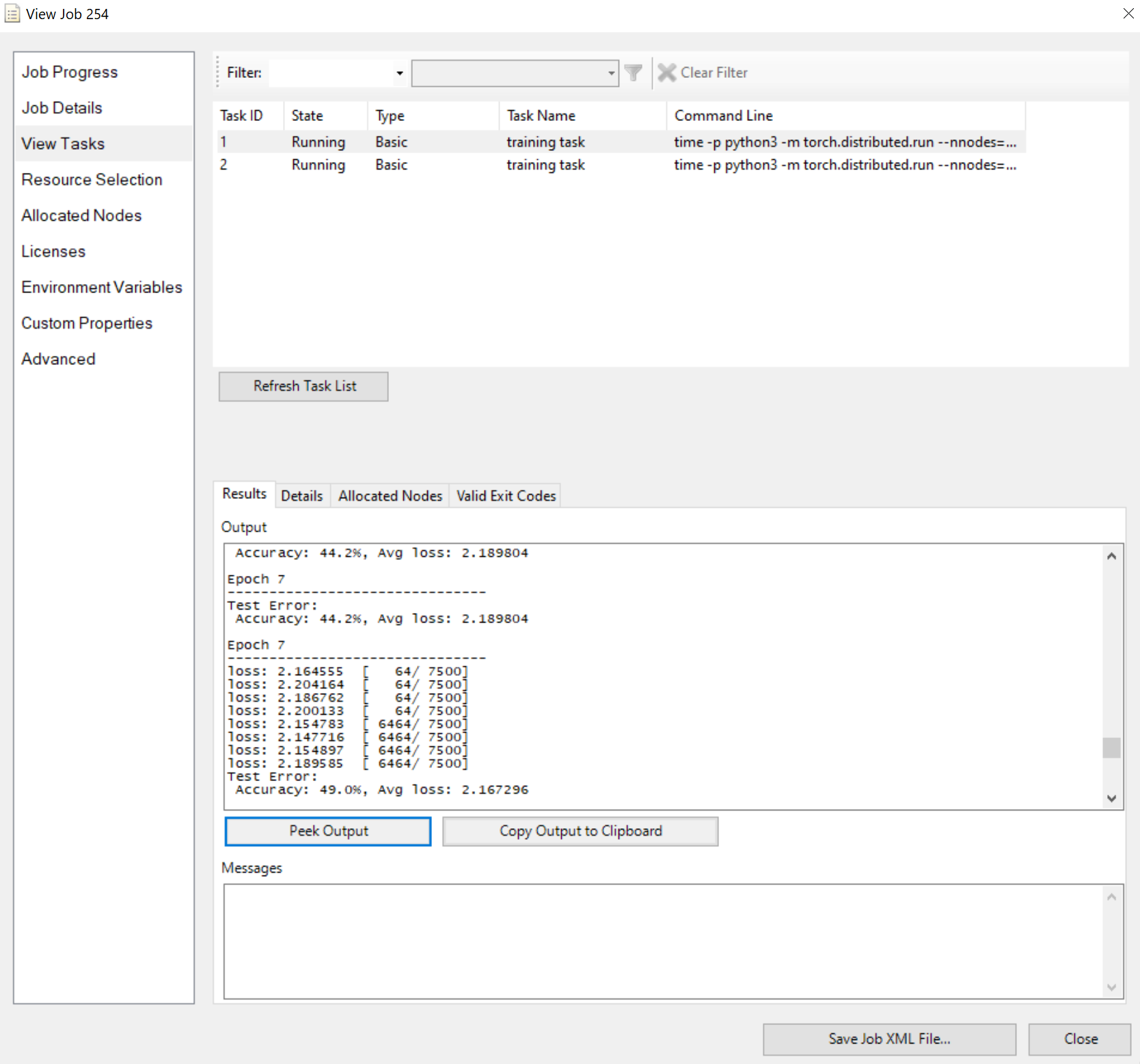
Si noti che il riquadro Risultati mostra l'output troncato se è troppo lungo.
È tutto per questo. Spero che tu ottenga i punti e HPC Pack possa velocizzare il tuo lavoro di formazione.