Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() IoT Edge 1.1
IoT Edge 1.1
Importante
IoT Edge 1.1 data di fine del supporto è stata il 13 dicembre 2022. Controlla il ciclo di vita dei prodotti Microsoft per ottenere informazioni sul modo in cui viene supportato questo prodotto, servizio, tecnologia o API. Per altre informazioni sull'aggiornamento alla versione più recente di IoT Edge, vedere Aggiornare IoT Edge.
In questo articolo vengono eseguite le attività seguenti:
- Usare Azure Machine Learning Studio per eseguire il training di un modello di Machine Learning.
- Impacchetta il modello addestrato come immagine del container.
- Distribuire l'immagine del contenitore come modulo Azure IoT Edge.
Machine Learning Studio è un blocco fondamentale usato per sperimentare, eseguire il training e distribuire modelli di Machine Learning.
I passaggi descritti in questo articolo potrebbero essere in genere eseguiti dai data scientist.
In questa sezione dell'esercitazione si apprenderà come:
- Creare notebook di Jupyter in un'area di lavoro di Azure Machine Learning per eseguire il training di un modello di Machine Learning.
- Containerizza il modello di machine learning addestrato.
- Creare un modulo IoT Edge dal modello di Machine Learning in contenitori.
Prerequisiti
Questo articolo fa parte di una serie di esercitazioni sull'uso di Machine Learning in IoT Edge. Ogni articolo della serie si basa sul lavoro dell'articolo precedente. Se sei arrivato direttamente a questo articolo, vedi il primo articolo della serie.
Configurare Azure Machine Learning
Si usa Machine Learning Studio per ospitare i due notebook jupyter e i file di supporto. In questo articolo viene creato e configurato un progetto di Machine Learning. Se Non è stato usato Jupyter o Machine Learning Studio, ecco due documenti introduttivi:
- Jupyter Notebook: Uso dei notebook di Jupyter in Visual Studio Code
- Azure Machine Learning: Inizia a lavorare con Azure Machine Learning nei notebook di Jupyter
Nota
Dopo aver configurato il servizio, è possibile accedere a Machine Learning da qualsiasi computer. Durante l'installazione, è necessario usare la macchina virtuale di sviluppo, che include tutti i file necessari.
Installare l'estensione Visual Studio Code di Azure Machine Learning
Visual Studio Code nella macchina virtuale di sviluppo deve avere questa estensione installata. Se si sta utilizzando un'istanza diversa, reinstallare l'estensione come descritto in Configurare l'estensione di Visual Studio Code.
Creare un account di Azure Machine Learning
Per effettuare il provisioning delle risorse ed eseguire carichi di lavoro in Azure, accedere con le credenziali dell'account Azure.
Apri la palette dei comandi in Visual Studio Code selezionando Visualizza>Palette dei comandi dalla barra dei menu.
Immettere il comando
Azure: Sign Innel riquadro comandi per avviare il processo di accesso. Seguire le istruzioni per completare l'accesso.Creare un'istanza di calcolo di Machine Learning per eseguire il carico di lavoro. Nel riquadro comandi immettere il comando
Azure ML: Create Compute.Seleziona la tua sottoscrizione di Azure.
Selezionare + Creare una nuova area di lavoro Azure MLe inserire il nome turbofandemo.
Selezionare il gruppo di risorse usato per questa demo.
Verrà visualizzato lo stato di avanzamento della creazione dell'area di lavoro nell'angolo in basso a destra della finestra di Visual Studio Code: Creazione dell'area di lavoro: turobofandemo. Questo passaggio può richiedere un minuto o due.
Attendere che l'area di lavoro venga creata correttamente. Dovrebbe dire area di lavoro di Azure ML turbofandemo creata.
Caricare i file di Jupyter Notebook
I file di notebook di esempio verranno caricati in una nuova area di lavoro di Machine Learning.
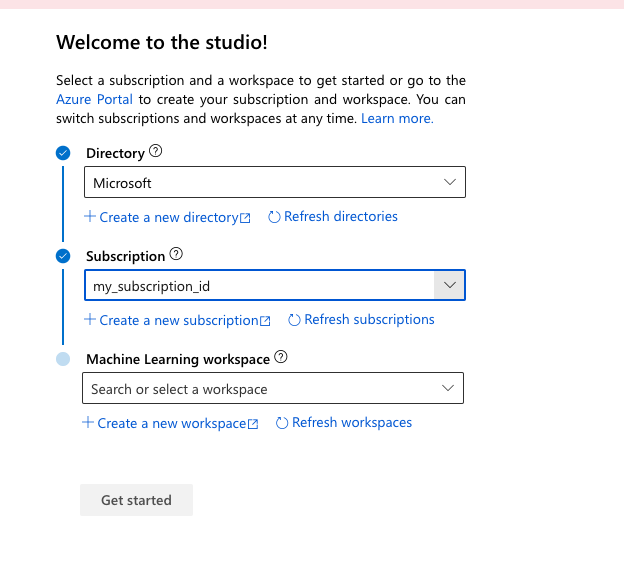
Passare a ml.azure.com e accedere.
Selezionare la directory Microsoft, la sottoscrizione di Azure e l'area di lavoro di Machine Learning appena creata.
Dopo aver eseguito l'accesso all'area di lavoro di Machine Learning, vai alla sezione Notebooks usando il menu a sinistra.
Selezionare la scheda File personali.
Selezionare Carica (icona freccia su).
Passare a C:\source\IoTEdgeAndMlSample\AzureNotebooks. Selezionare tutti i file nell'elenco e selezionare Apri.
Selezionare la casella di controllo mi fido del contenuto di questi file.
Selezionare Carica per iniziare il caricamento. Selezionare quindi Fine al termine del processo.
File di Jupyter Notebook
Esaminare i file caricati nell'area di lavoro di Machine Learning. Le attività in questa parte dell'esercitazione si estendono su due file di notebook, che usano alcuni file di supporto.
01-turbofan_regression.ipynb: questo notebook usa l'area di lavoro di Machine Learning per creare ed eseguire un esperimento di Machine Learning. In generale, il notebook esegue i passaggi seguenti:
- Scarica i dati dall'account di archiviazione di Azure generato dall'harness del dispositivo.
- Esplora e prepara i dati e quindi usa i dati per eseguire il training del modello di classificatore.
- Valuta il modello dall'esperimento usando un set di dati di test (Test_FD003.txt).
- Pubblica il modello di classificatore migliore nell'area di lavoro di Machine Learning.
02-turbofan_deploy_model.ipynb: Questo notebook prende il modello creato nel notebook precedente e lo usa per creare un'immagine di container pronta per essere distribuita su un dispositivo IoT Edge. Il notebook esegue i passaggi seguenti:
- Crea uno script di assegnazione dei punteggi per il modello.
- Produce un'immagine del contenitore usando il modello di classificatore salvato nell'area di lavoro di Machine Learning.
- Distribuisce l'immagine come servizio Web in Istanze di Azure Container.
- Usa il servizio Web per convalidare che il modello e l'immagine funzionino come previsto. L'immagine convalidata verrà distribuita nel nostro dispositivo IoT Edge nella sezione Creare e distribuire moduli IoT Edge personalizzati di questa esercitazione.
Test_FD003.txt: questo file contiene i dati che verranno usati come set di test quando si convalida il classificatore sottoposto a training. Abbiamo scelto di usare i dati di test, come fornito per il concorso originale, come set di test per la sua semplicità.
RUL_FD003.txt: questo file contiene la durata utile rimanente (URL) per l'ultimo ciclo di ogni dispositivo nel file Test_FD003.txt. Vedere i file readme.txt e Propagazione dei Danni Modeling.pdf in C:\source\IoTEdgeAndMlSample\data\Turbofan per una spiegazione dettagliata dei dati.
Utils.py: questo file contiene un set di funzioni di utilità Python per l'uso dei dati. Il primo notebook contiene una spiegazione dettagliata delle funzioni.
README.md: Il file README descrive l'uso dei notebook.
Esegui i notebook di Jupyter
Dopo aver creato l'area di lavoro, è possibile eseguire i notebook.
Nella tua pagina I miei file, seleziona 01-turbofan_regression.ipynb.
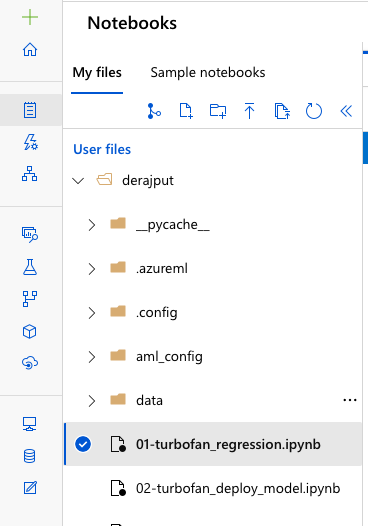
Se il notebook è elencato come Non attendibile, selezionare il widget Non attendibile nell'angolo superiore destro del notebook. Quando viene visualizzata la finestra di dialogo, selezionare Trust.
Per ottenere risultati ottimali, leggere la documentazione per ogni cella ed eseguirla singolarmente. Selezionare Esegui sulla barra degli strumenti. Più avanti, scoprirai che è opportuno eseguire più celle. È possibile ignorare gli avvisi di aggiornamento e obsolescenza.
Quando una cella è in esecuzione, viene visualizzato un asterisco tra le parentesi quadre ([*]). Una volta terminata l'operazione della cella, l'asterisco viene sostituito con un numero e potrebbe apparire l'output pertinente. Le celle di un notebook vengono compilate in sequenza e una sola cella può essere eseguita alla volta.
È anche possibile usare le opzioni di esecuzione dal menu cella. Selezionare CTRL+INVIO per eseguire una cella e selezionare MAIUSC+INVIO per eseguire una cella e passare alla cella successiva.
Suggerimento
Per un funzionamento coerente delle celle, evitare di eseguire lo stesso notebook da più schede del browser.
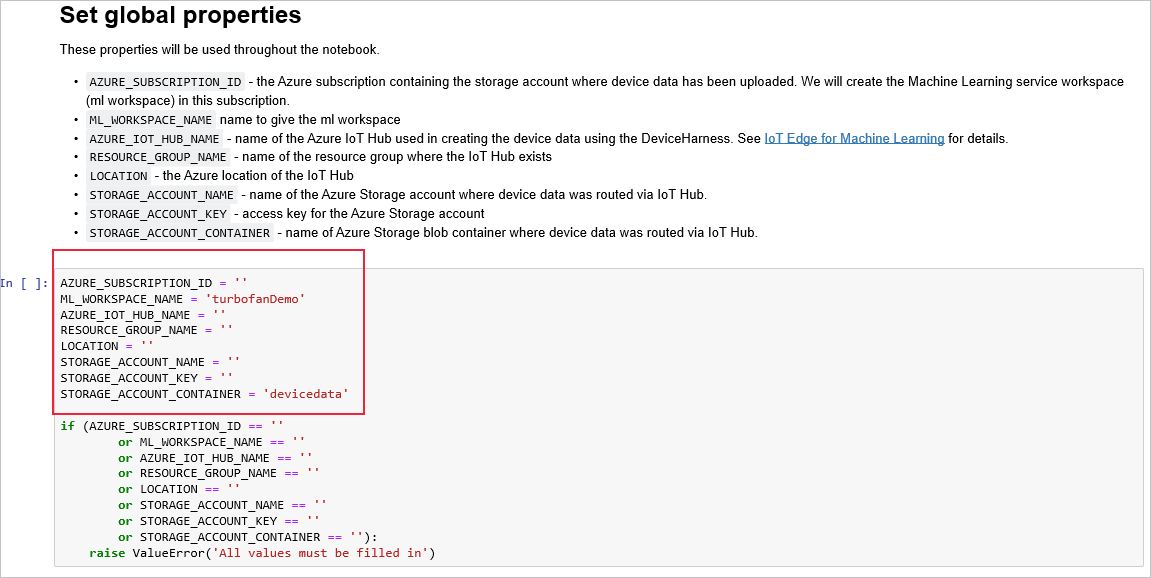
Nella cella che segue le istruzioni di Impostare le proprietà globali, immettere i valori per la sottoscrizione di Azure, le impostazioni e le risorse. Quindi eseguire la cella.
Nella cella precedente a "" dettagli dell'area di lavoro "", dopo che è stato eseguito, cercate il link che vi istruisce a effettuare l'accesso per l'autenticazione.

Aprire il collegamento e immettere il codice specificato. Questa procedura di accesso autentica il notebook di Jupyter per accedere alle risorse di Azure usando l'interfaccia della riga di comando multipiattaforma di Microsoft Azure.

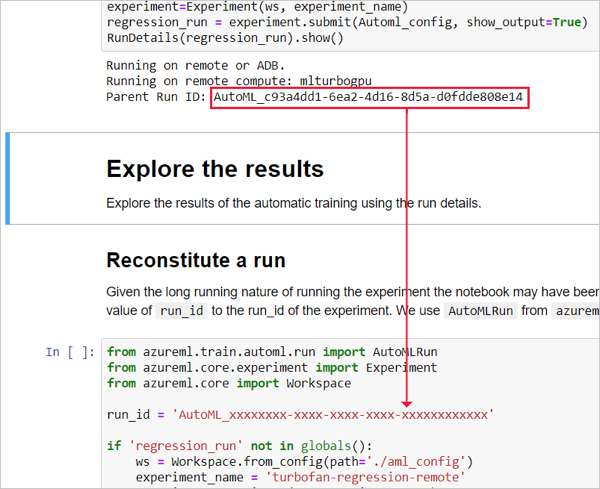
Nella cella che precede Esplorare i risultati, copia il valore dall'ID di esecuzione e incollalo nell'ID di esecuzione nella cella che segue Ricostituire un'esecuzione.
Esegui le restanti celle nel notebook.
Salvare il notebook e tornare alla pagina del progetto.
Apri 02-turbofan_deploy_model.ipynb ed esegui ogni cella. È necessario accedere per eseguire l'autenticazione nella cella che segue Configurare l'area di lavoro.
Salvare il notebook e tornare alla pagina del progetto.
Verificare l'esito positivo
Verificate che i notebook siano stati completati correttamente, controllando che siano stati creati alcuni elementi.
Nel notebook di Machine Learning scheda File personali selezionare aggiornare.
Verificare che i file seguenti siano stati creati.
Documento Descrizione ./aml_config/.azureml/config.json File di configurazione usato per creare l'area di lavoro di Machine Learning. ./aml_config/model_config.json File di configurazione che sarà necessario implementare il modello nella area di lavoro turbofanDemo Machine Learning in Azure. myenv.yml Fornisce informazioni sulle dipendenze per il modello di Machine Learning distribuito. Verificare che siano state create le risorse di Azure seguenti. Alcuni nomi di risorse vengono aggiunti con caratteri casuali.
Risorsa di Azure Nome Area di lavoro di Azure Machine Learning turborfanDemo Registro dei container di Azure turbofandemoxxxxxxxx Approfondimenti sulle Applicazioni turbofaninsightxxxxxxxx Azure Key Vault (Archivio chiavi di Azure) turbofankeyvaultbxxxxxxxx Archiviazione di Azure turbofanstoragexxxxxxxxx
Risoluzione errori
È possibile inserire istruzioni Python nel notebook per il debug, ad esempio il comando print() per visualizzare i valori. Nel caso in cui vengano visualizzate variabili o oggetti non definiti, eseguire le celle in cui vengono prima dichiarate o instanziate.
Potrebbe essere necessario eliminare i file creati in precedenza e le risorse di Azure se è necessario ripetere i notebook.
Pulire le risorse
Questa esercitazione fa parte di un set in cui ogni articolo si basa sul lavoro svolto nei precedenti. Attendere a pulire le risorse fino al completamento dell'esercitazione finale.
Passaggi successivi
In questo articolo, sono stati usati due Notebook Jupyter eseguiti in Machine Learning Studio per usare i dati dei dispositivi turbofan per:
- Allenare un classificatore RUL.
- Salvare il classificatore come modello.
- Creare un'immagine del contenitore.
- Distribuisci e testa l'immagine come servizio Web.
Continuare con l'articolo successivo per creare un dispositivo IoT Edge.