Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A:Si tratta Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  Azure Machine Learning
Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere le informazioni sullo spostamento di progetti di Machine Learning da ML Studio (versione classica) ad Azure Machine Learning.
- Altre informazioni su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
In questo articolo, crei un esperimento di machine learning in Machine Learning Studio (versione classica) che prevede il prezzo di un'auto in base a diverse variabili come la marca e le specifiche tecniche.
Se non si ha familiarità con l'apprendimento automatico, la serie di video Data Science for Beginners è un'ottima introduzione all'apprendimento automatico usando il linguaggio e i concetti quotidiani.
Questa guida introduttiva segue il flusso di lavoro predefinito di un esperimento:
- Creare un modello
- Addestrare il modello
- Assegnare punteggi e testare il modello
Ottieni i dati
Il primo elemento necessario nell'apprendimento automatico è rappresentato dai dati. In Studio (versione classica) sono disponibili numerosi set di dati di esempio da usare oppure è possibile importare dati da molte altre origini. Per questo esempio si userà il set di dati di esempio Automobile price data (Raw) incluso nell'area di lavoro. Questo set di dati include voci per diverse automobili e include informazioni su marca, modello, specifiche tecniche e prezzo.
Suggerimento
È possibile trovare una copia funzionante dell'esperimento seguente in Azure AI Gallery. Passare al primo esperimento di data science - Stima prezzo automobile e fare clic su Apri in Studio per scaricare una copia dell'esperimento nell'area di lavoro di Machine Learning Studio (versione classica).
Di seguito viene illustrato come ottenere il set di dati nell'esperimento.
Creare un nuovo esperimento facendo clic su +NUOVO nella parte inferiore della finestra di Machine Learning Studio (versione classica). Selezionare ESPERIMENTO>Esperimento vuoto.
All'esperimento viene assegnato un nome predefinito visualizzato nella parte superiore dell'area di disegno. Selezionare questo testo e rinominarlo in qualcosa di significativo, ad esempio Automobile price prediction. Il nome non deve essere univoco.
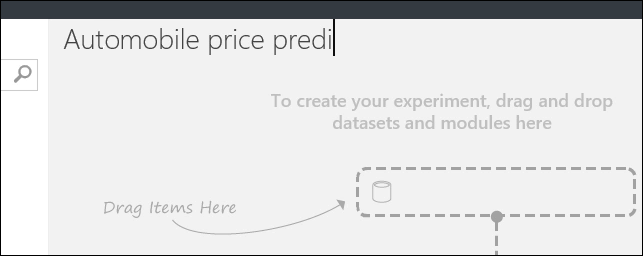
A sinistra dell'area di disegno dell'esperimento è presente una tavolozza di set di dati e moduli. Digitare automobile nella casella Cerca nella parte superiore di questa tavolozza per trovare il set di dati con etichetta Automobile price data (Raw). Trascinare il set di dati nell'area di disegno dell'esperimento.
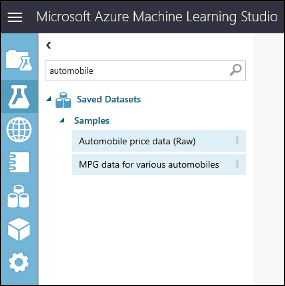
Per visualizzare l'aspetto di questi dati, fare clic sulla porta di output nella parte inferiore del set di dati delle automobili e quindi selezionare Visualizza.
Suggerimento
I set di dati e i moduli hanno porte di input e output rappresentate da piccoli cerchi: le porte di input nella parte superiore e le porte di output nella parte inferiore. Per creare un flusso di dati nell'esperimento, connettere una porta di output di un modulo a una porta di input di un altro. In qualsiasi momento, è possibile fare clic sulla porta di output di un set di dati o di un modulo per visualizzare l'aspetto dei dati in tale punto specifico del flusso di dati.
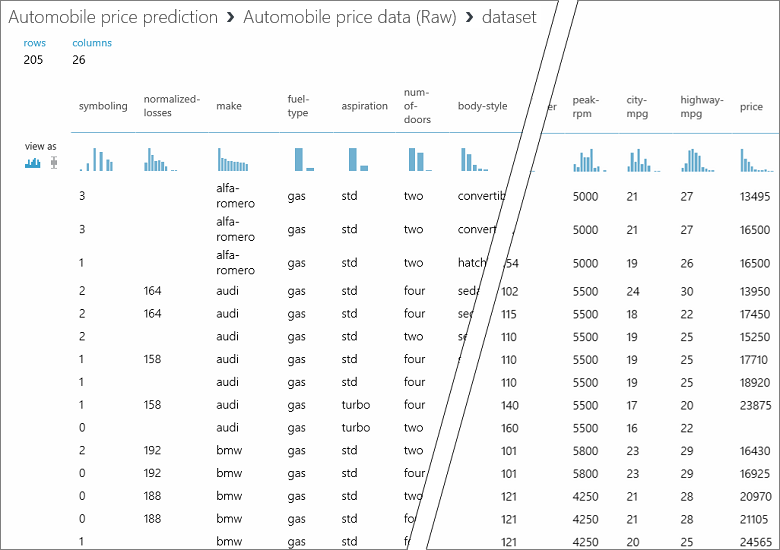
In questo set di dati ogni riga rappresenta un'automobile e le variabili associate a ogni automobile sono rappresentate da colonne. Il prezzo verrà stimato nella colonna all'estrema destra, ovvero la colonna 26 denominata "price" (prezzo) usando le variabili per un'automobile specifica.
Chiudere la finestra di visualizzazione facendo clic su "x" nell'angolo superiore destro.
Preparare i dati
Prima di poter analizzare un set di dati è in genere necessario pre-elaborarlo. È possibile che si sia notata l'assenza di valori nelle colonne di diverse righe. Per consentire al modello di analizzare correttamente i dati, è necessario eseguire la pulizia di questi valori mancanti. Verranno rimosse le righe con i valori mancanti. Inoltre, la colonna normalized-losses ha una percentuale elevata di valori mancanti, quindi la colonna verrà esclusa completamente dal modello.
Suggerimento
La pulizia dei valori mancanti dai dati di input è un prerequisito all'uso della maggior parte dei moduli.
Aggiungere prima di tutto un modulo che rimuove completamente la colonna normalized-losses . Si aggiunge quindi un altro modulo che rimuove tutte le righe con dati mancanti.
Digitare le colonne selezionate nella casella di ricerca nella parte superiore della tavolozza dei moduli per trovare il modulo Select Columns in Dataset (Seleziona colonne nel set di dati ). Trascina l'elemento nel canvas dell'esperimento. Questo modulo consente di selezionare le colonne di dati da includere o escludere nel modello.
Connettere la porta di output del dataset Automobile price data (Raw) alla porta di input di Select Columns in Dataset.
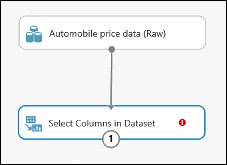
Fare clic sul modulo Select Columns in Dataset (Seleziona colonne nel set di dati ) e fare clic su Launch column selector (Avvia selettore di colonna ) nel riquadro Proprietà .
A sinistra fare clic su Con regole
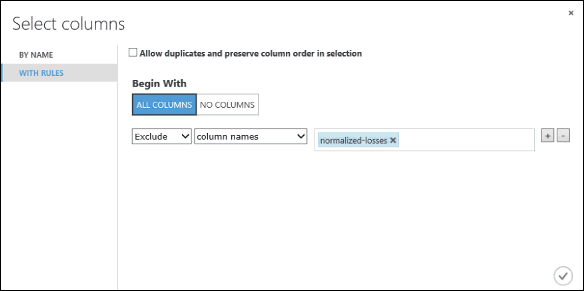
Sotto Inizia con, fare clic su Tutte le colonne. Queste regole indicano Seleziona colonne nel set di dati di consentire il passaggio di tutte le colonne, ad eccezione delle colonne che stiamo per escludere.
Nell'elenco a discesa selezionare Escludi e nomi di colonna e quindi fare clic all'interno della casella di testo. Verrà visualizzato un elenco di colonne. Selezionare normalized-losses e sarà aggiunto alla casella di testo.
Fare clic sul pulsante del segno di spunta (OK) per chiudere il selettore di colonne nella parte inferiore destra.
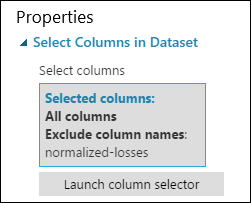
Il riquadro delle proprietà per Select Columns in Dataset (Seleziona colonne nel set di dati ) indica ora che passerà tutte le colonne del set di dati, ad eccezione delle perdite normalizzate.
Suggerimento
È possibile aggiungere un commento a un modulo facendo doppio clic sul modulo e immettendo del testo. In tal modo sarà possibile individuare subito l'operazione eseguita dal modulo nell'esperimento. In questo caso fare doppio clic sul modulo Seleziona colonne nel set di dati e digitare il commento "Escludi perdite normalizzate".
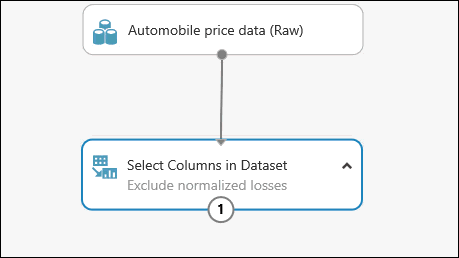
Trascinare il modulo Clean Missing Data (Pulisci dati mancanti ) nell'area di disegno dell'esperimento e connetterlo al modulo Select Columns in Dataset (Seleziona colonne nel set di dati ). Nel riquadro Proprietà selezionare Rimuovi l'intera riga in Modalità pulizia. Queste opzioni indirizzano Clean Missing Data (Pulisci dati mancanti ) per pulire i dati rimuovendo le righe con valori mancanti. Fare doppio clic sul modulo e digitare il commento "Rimuovi righe valori mancanti".
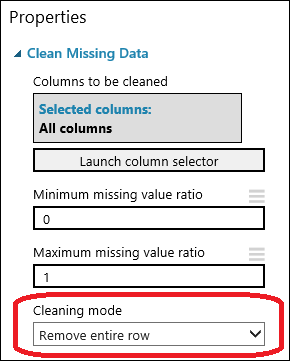
Eseguire l'esperimento facendo clic su ESEGUI nella parte inferiore della pagina.
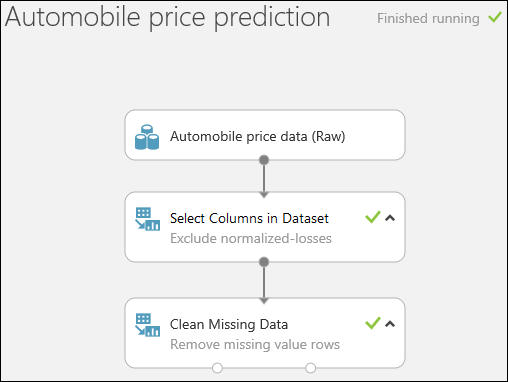
Al termine dell'esecuzione dell'esperimento, tutti i moduli saranno contraddistinti da un segno di spunta verde per indicarne il corretto completamento. Si noti anche lo stato Esecuzione completata nell'angolo superiore destro.
Suggerimento
Perché è stato eseguito l'esperimento ora? Eseguendo l'esperimento, le definizioni di colonna per i dati vengono passate dal set di dati, tramite il modulo Select Columns in Dataset (Seleziona colonne nel set di dati ) e tramite il modulo Clean Missing Data (Pulisci dati mancanti ). Ciò significa che tutti i moduli connessi a Clean Missing Data avranno anche queste stesse informazioni.
Ora sono disponibili dati puliti. Per visualizzare il set di dati pulito, fare clic sulla porta di output sinistra del modulo Clean Missing Data (Pulisci dati mancanti ) e selezionare Visualize (Visualizza). Si noti che la colonna normalized-losses non è più inclusa e non sono presenti valori mancanti.
A questo punto, una volta puliti i dati è possibile specificare le caratteristiche da usare nel modello predittivo.
Definire le caratteristiche
In Machine Learning , le funzionalità sono proprietà misurabili individuali di un elemento a cui si è interessati. Nel set di dati corrente ogni riga rappresenta un'automobile e ogni colonna è una caratteristica di tale automobile.
Per cercare un set di caratteristiche adeguato per creare un modello predittivo, è necessario sperimentare e conoscere approfonditamente il problema che si desidera risolvere. Alcune caratteristiche sono migliori di altre per predire l'obiettivo. Alcune caratteristiche sono strettamente correlate ad altre e possono essere rimosse. Ad esempio, city-mpg e highway-mpg sono strettamente correlate ed è possibile rimuoverne una senza influire in modo significativo sulla stima.
Verrà ora creato un modello che usa un sottoinsieme delle caratteristiche del set di dati. È possibile tornare più tardi e selezionare caratteristiche diverse, eseguire di nuovo l'esperimento e verificare se i risultati ottenuti sono migliori. Per iniziare verranno tuttavia provate le funzionalità seguenti:
marca, carrozzeria, interasse, cilindrata, cavalli, giri al minuto massimo, consumo autostrada, prezzo
Trascinare un altro modulo Select Columns in Dataset nell'area di disegno dell'esperimento. Connettere la porta di output sinistra del modulo Clean Missing Data (Pulisci dati mancanti ) all'input del modulo Select Columns in Dataset (Seleziona colonne nel set di dati ).
Fare doppio clic sul modulo e digitare "Selezionare le caratteristiche per la stima".
Fare clic su Avvia selettore di colonna nel riquadro Proprietà .
Fare clic su Con regole.
In Inizia con, cliccare su Nessuna colonna. Nella riga del filtro selezionare Includi e nomi di colonna e selezionare l'elenco di nomi di colonna nella casella di testo. Questo filtro indica al modulo di non analizzare le colonne (caratteristiche), a eccezione di quelle specificate.
Fare clic sul pulsante di segno di spunta (OK).
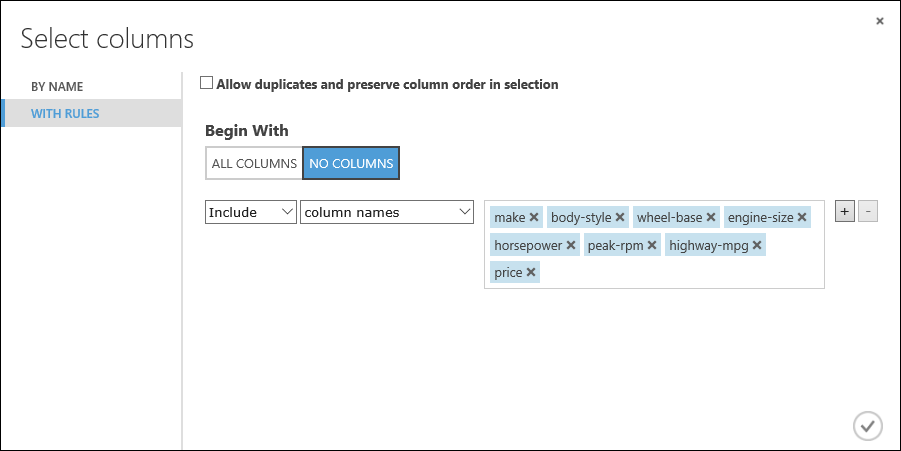
Questo modulo produce un set di dati filtrato contenente solo le caratteristiche da passare all'algoritmo di apprendimento che si userà nel passaggio successivo. In seguito, è possibile tornare indietro e provare a selezionare caratteristiche diverse.
Scegliere e applicare un algoritmo
I dati sono pronti, di conseguenza la creazione del modello predittivo implica la fase di training e test. Questi dati verranno usati per il training del modello e verrà testata la sua capacità di precisione per stimare i prezzi.
La classificazione e la regressione sono due tipi di algoritmi di Machine Learning supervisionati. La classificazione stima una risposta da un set di categorie definito, ad esempio un colore (rosso, blu o verde). La regressione viene usata per stimare un numero.
Poiché si vuole stimare il prezzo, ovvero un numero, si userà un algoritmo di regressione. Per questo esempio si userà un modello di regressione lineare .
Il training del modello viene eseguito tramite l'assegnazione di un set di dati che include i prezzi. Il modello analizza i dati e cerca le correlazioni tra le caratteristiche di un'automobile e il prezzo. Il modello viene quindi testato: viene assegnato un set di caratteristiche per le automobili di cui si ha familiarità e viene visualizzata la precisione con la quale il modello stima il prezzo noto.
Utilizzeremo i nostri dati sia per addestrare il modello che per testarlo, suddividendo i dati in set separati per l'addestramento e per il test.
Selezionare e trascinare il modulo Split Data nell'area di disegno dell'esperimento e connetterlo all'ultimo modulo Select Columns in Dataset (Seleziona colonne nel set di dati ).
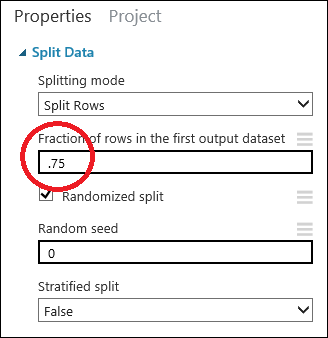
Fare clic sul modulo Split Data (Divisione dati ) per selezionarlo. Trovare la frazione di righe nel primo set di dati di output (nel riquadro Proprietà a destra dell'area di disegno) e impostarla su 0,75. In questo modo per il training del modello verrà usato il 75% dei dati, mentre il restante 25% verrà usato per il testing.
Suggerimento
Modificando il parametro Valore di inizializzazione casuale, è possibile produrre campioni casuali vari per l'addestramento e il test. Questo parametro controlla il seeding del generatore di numeri pseudocasuali.
Eseguire l'esperimento. Quando viene eseguito l'esperimento, i moduli Select Columns in Dataset e Split Data passano le definizioni di colonna ai moduli che verranno aggiunti successivamente.
Per selezionare l'algoritmo di apprendimento, espandere la categoria Machine Learning nella tavolozza dei moduli a sinistra dell'area di disegno e quindi espandere Inizializza modello. Verranno visualizzate diverse categorie di moduli che possono essere usate per inizializzare gli algoritmi di Machine Learning. Per questo esperimento, selezionare il modulo Regressione lineare nella categoria Regressione e trascinarlo nell'area di disegno dell'esperimento. È anche possibile trovare il modulo digitando "linear regression" nella casella di ricerca della tavolozza.
Trovare e trascinare il modulo Train Model nell'area di disegno dell'esperimento. Connettere l'output del modulo Linear Regression (Regressione lineare) all'input sinistro del modulo Train Model e connettere l'output dei dati di training (porta sinistra) del modulo Split Data all'input destro del modulo Train Model.
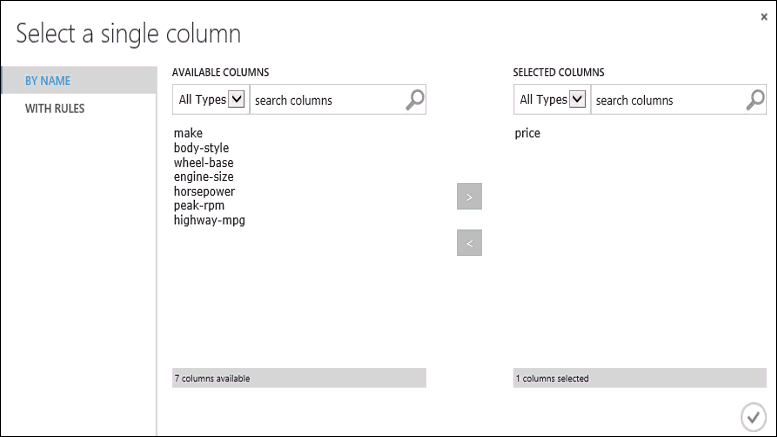
Fare clic sul modulo Train Model, fare clic su Avvia selettore di colonna nel riquadro Proprietà e quindi selezionare la colonna Prezzo. Il prezzo è il valore che verrà stimato dal modello.
Selezionare la colonna price nel selettore di colonna spostandola dall'elenco Colonne disponibili all'elenco Colonne selezionate .
Eseguire l'esperimento.
Abbiamo ora un modello di regressione addestrato che può essere utilizzato per assegnare un punteggio ai nuovi dati delle automobili per prevedere i prezzi.

Stimare i prezzi delle nuove automobili
Dopo aver eseguito il training del modello usando il 75% dei dati, è possibile usarlo per classificare il restante 25% e verificarne il funzionamento.
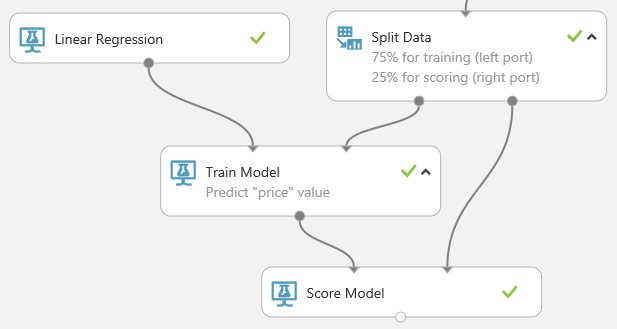
Trova e trascina il modulo Score Model nell'area di disegno dell'esperimento. Connettere l'output del modulo Train Model alla porta di input sinistra di Score Model. Connettere l'output dei dati di test (porta destra) del modulo Split Data alla porta di input destra del Score Model.
Eseguire l'esperimento e visualizzare l'output del modulo Score Model facendo clic sulla porta di output di Score Model e selezionare Visualizza. L'output mostra i valori stimati per il prezzo e i valori noti dai dati di test.
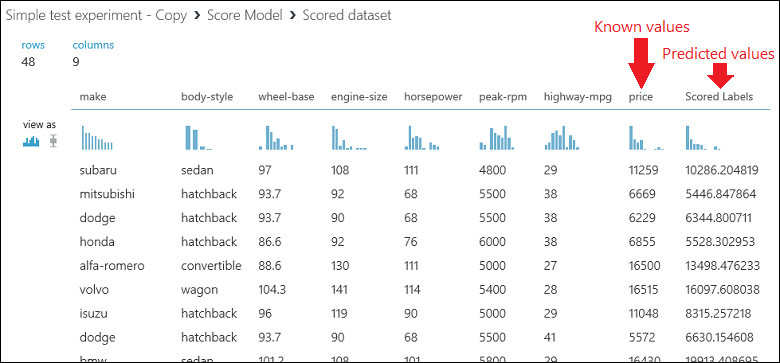
Alla fine viene testata la qualità dei risultati. Selezionare e trascinare il modulo Evaluate Model nell'area di disegno dell'esperimento e connettere l'output del modulo Score Model all'input sinistro di Evaluate Model. L'esperimento dovrebbe avere un aspetto simile al seguente:
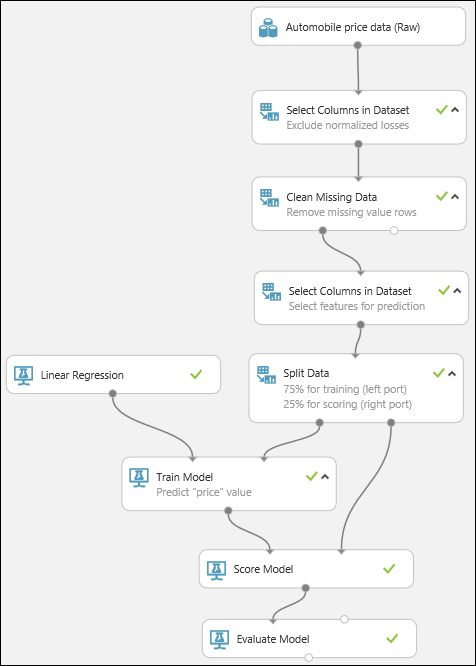
Eseguire l'esperimento.
Per visualizzare l'output del modulo Evaluate Model (Valuta modello ), fare clic sulla porta di output e quindi selezionare Visualize (Visualizza).
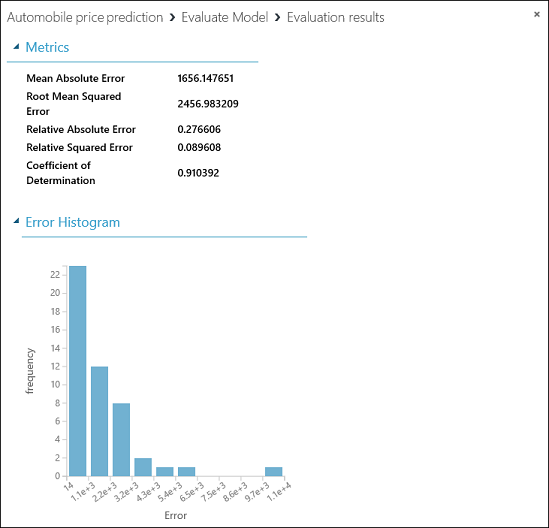
Per il modello vengono visualizzate le seguenti statistiche:
- Errore assoluto medio (MAE): media degli errori assoluti ( un errore è la differenza tra il valore stimato e il valore effettivo).
- Radice errore quadratico medio (RMSE): la radice quadrata della media degli errori quadrati delle predizioni effettuate sul set di dati di test.
- Errore assoluto relativo: media degli errori assoluti rispetto alla differenza assoluta tra i valori effettivi e la media di tutti i valori effettivi.
- Errore quadratino relativo: media degli errori quadrati rispetto alla differenza quadrata tra i valori effettivi e la media di tutti i valori effettivi.
- Coefficiente di determinazione: noto anche come valore quadrato R, si tratta di una metrica statistica che indica il modo in cui un modello soddisfa i dati.
Per ogni statistica di errore, sono preferibili i valori più piccoli. Un valore più piccolo indica che le stime sono più vicine ai valori effettivi. Per Coefficiente di determinazione, il valore più vicino è a uno (1,0), meglio sono le stime.
Pulire le risorse
Se le risorse create in questo articolo non sono più necessarie, eliminarle per evitare di incorrere in eventuali addebiti. Informazioni su come nell'articolo esportare ed eliminare i dati utente nel prodotto.
Passaggi successivi
In questa guida introduttiva, hai creato un semplice esperimento utilizzando un dataset di esempio. Per esplorare il processo di creazione e distribuzione di un modello in modo più approfondito, passare all'esercitazione sulla soluzione di analisi predittiva.