Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
SI APPLICA A: Machine Learning Studio (versione classica)
Machine Learning Studio (versione classica)  di Azure Machine Learning
di Azure Machine Learning
Importante
Il supporto dello studio di Azure Machine Learning (versione classica) terminerà il 31 agosto 2024. È consigliabile passare ad Azure Machine Learning entro tale data.
A partire dal 1° dicembre 2021 non sarà possibile creare nuove risorse dello studio di Azure Machine Learning (versione classica). Fino al 31 agosto 2024 sarà possibile continuare a usare le risorse dello studio di Azure Machine Learning (versione classica).
- Vedere le informazioni sullo spostamento di progetti di apprendimento automatico da ML Studio (versione classica) ad Azure Machine Learning.
- Scoprire di più su Azure Machine Learning
La documentazione relativa allo studio di Machine Learning (versione classica) è in fase di ritiro e potrebbe non essere aggiornata in futuro.
Per usare i propri dati in Machine Learning Studio (versione classica) per sviluppare ed eseguire il training di una soluzione di analisi predittiva, è possibile usare i dati da:
- File locale: caricare dati locali in anticipo dal disco rigido per creare un modulo di set di dati nell'area di lavoro
- Origini dati online: usare il modulo Import Data per accedere ai dati da una delle diverse origini dati online durante l'esecuzione dell'esperimento
- Esperimento di Machine Learning Studio (versione classica): usare i dati salvati come set di dati in Machine Learning Studio (versione classica)
- Database di SQL Server : usare i dati di un database di SQL Server senza dover copiare manualmente i dati
Nota
Esistono diversi set di dati di esempio disponibili in Machine Learning Studio (versione classica) che è possibile usare per i dati di training. Per informazioni su queste informazioni, vedere Usare i set di dati di esempio in Machine Learning Studio (versione classica).
Preparazione dei dati
Machine Learning Studio (versione classica) è progettato per lavorare con dati rettangolari o tabulari, ad esempio dati di testo delimitati o strutturati da un database, anche se in alcune circostanze è possibile usare dati non rettangolari.
È consigliabile se i dati sono relativamente puliti prima di importarli in Studio (versione classica). È opportuno risolvere eventuali problemi, ad esempio stringhe non racchiuse tra virgolette.
Tuttavia, in Studio (versione classica) sono disponibili moduli che consentono alcune modifiche dei dati all'interno dell'esperimento dopo l'importazione dei dati. A seconda degli algoritmi di Machine Learning usati, potrebbe essere necessario stabilire come gestire problemi strutturali di dati, ad esempio valori mancanti e dati di tipo sparse. A tale scopo, esistono moduli che possono rivelarsi utili. Vedere la sezione Trasformazione dei dati della tavolozza dei moduli per i moduli che eseguono queste funzioni.
In qualsiasi momento dell'esperimento è possibile visualizzare o scaricare i dati prodotti da un modulo facendo clic sulla porta di output. A seconda del modulo, potrebbero essere disponibili diverse opzioni di download oppure è possibile visualizzare i dati all'interno del Web browser in Studio (versione classica).
Tipi di dati e formati di dati supportati
È possibile importare diversi tipi di dati nell'esperimento, a seconda del meccanismo usato per importare dati e della relativa provenienza:
- Testo semplice (.txt)
- Valori separati da virgole (CSV) con intestazione (.csv) o senza (.nh.csv)
- Valori separati da tabulazioni (TSV) con un'intestazione (.tsv) o senza (.nh.tsv)
- File di Excel
- Tabella di Azure
- Tabella Hive
- Tabella di database SQL
- Valori OData
- Dati SVMLight (con estensione svmlight) (vedere la definizione di SVMLight per informazioni sul formato)
- Dati ARFF (Attribute Relation File Format) (con estensione arff) (vedere la definizione di ARFF per informazioni sul formato)
- File ZIP (con estensione zip)
- File dell’oggetto o dell'area di lavoro R (con estensione RData)
Se si importano dati in un formato come ARFF che include metadati, Studio (versione classica) usa questi metadati per definire l'intestazione e il tipo di dati di ogni colonna.
Se si importano dati come TSV o csv che non includono questi metadati, Studio (versione classica) deduce il tipo di dati per ogni colonna eseguendo il campionamento dei dati. Se i dati non hanno nemmeno intestazioni di colonna, Studio (versione classica) fornisce nomi predefiniti.
È possibile specificare in modo esplicito o modificare le intestazioni e i tipi di dati delle colonne tramite il modulo Edit Metadata (Modifica metadati).
I tipi di dati seguenti vengono riconosciuti da Studio (versione classica):
- String
- Intero
- Doppio
- Booleano
- Data e Ora
- TimeSpan
Studio usa un tipo di dati interno denominato tabella dati per passare i dati tra i moduli. È possibile convertire in modo esplicito i dati in formato tabella dati tramite il modulo Convert to Dataset.
I moduli che accettano formati diversi da tabella dati convertiranno i dati in tabella dati in modo automatico, prima di passare al modulo successivo.
Se necessario, è possibile convertire il formato tabella dati in CSV, TSV, ARFF o SVMLight usando altri moduli di conversione. Esaminare la sezione Conversioni di formati di dati della tavolozza dei moduli per i moduli che eseguono queste funzioni.
Capacità di dati
I moduli in Machine Learning Studio (versione classica) supportano set di dati fino a 10 GB di dati numerici densi per casi d'uso comuni. Se un modulo richiede più input, il valore di 10 GB rappresenta il totale delle dimensioni di tutti gli input. È possibile campionare set di dati di dimensioni maggiori con query di Hive o del database SQL di Azure oppure usare la pre-elaborazione di Learning by Counts prima di importare i dati.
I tipi di dati seguenti possono espandersi in set di dati di dimensioni maggiori durante la normalizzazione della funzionalità e sono limitati a meno di 10 GB:
- Sparse
- Categoriale
- Stringhe
- Dati binari
I moduli seguenti sono limitati a set di dati inferiori a 10 GB:
- Moduli di raccomandazione
- Modulo SMOTE (Synthetic Minority Oversampling Technique)
- Moduli di script: R, Python, SQL
- Moduli in cui la dimensione dei dati di output può essere maggiore della dimensione dei dati di input, come Join (Unione) o Feature Hashing.
- Convalida incrociata, ottimizzazione degli iperparametri del modello, regressione ordinale e multiclasse uno-tutti, quando il numero di iterazioni è molto elevato
Per i set di dati di dimensioni maggiori di alcuni GB, caricare i dati in Archiviazione di Azure o nel database SQL di Azure oppure usare Azure HDInsight, invece di eseguire il caricamento direttamente da un file locale.
È possibile trovare informazioni sui dati di immagine nelle informazioni di riferimento sul modulo di importazione di immagini.
Importare da un file locale
È possibile caricare un file di dati dal disco rigido da usare come dati di training in Studio (versione classica). Quando si importa il file di dati, si crea un modulo set di dati pronto per l'uso negli esperimenti nell'area di lavoro.
Per importare dati da un disco rigido locale effettuare le operazioni seguenti:
- Fare clic su +NUOVO nella parte inferiore della finestra Studio (versione classica).
- Seleziona DATASET (SET DI DATI) e DA FILE LOCALE.
- Nella finestra di dialogo Caricare un nuovo set di dati selezionare il file da caricare.
- Immettere un nome, identificare il tipo di dati e immettere facoltativamente una descrizione. Una descrizione è consigliabile perché consente di registrare tutte le caratteristiche relative ai dati da tenere presenti quando si useranno tali dati in futuro.
- La casella di controllo Questa è la nuova versione di un set di dati esistente consente di aggiornare un set di dati esistente con nuovi dati. A tale scopo, fare clic su questa casella di controllo e quindi immettere il nome di un set di dati esistente.
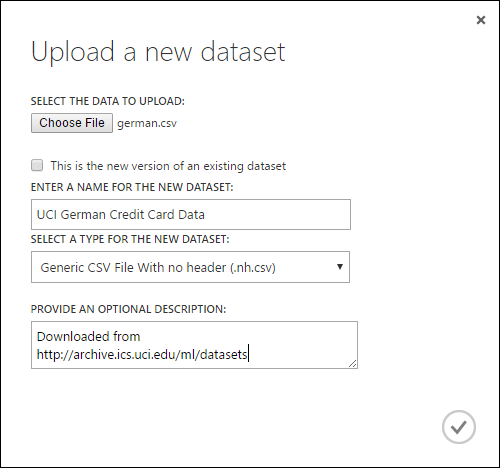
Il tempo di caricamento dipende dalle dimensioni dei dati e dalla velocità della connessione al servizio. Se si sa che il file richiederà molto tempo, è possibile eseguire altre operazioni all'interno di Studio (versione classica) durante l'attesa. In caso di chiusura del browser prima del completamento del caricamento dei dati, tuttavia, il caricamento dei dati avrà esito negativo.
Una volta caricati, i dati vengono archiviati in un modulo di set di dati e sono disponibili per eventuali esperimenti nell'area di lavoro.
Durante la modifica di un esperimento, è possibile individuare i set di dati caricati nell'elenco My Datasets (Set di dati personali) presente nell'elenco Saved Datasets (Set di dati salvati) nella tavolozza dei moduli. È possibile trascinare il set di dati nell'area di disegno dell'esperimento per usarlo per l'ulteriore analisi e l'apprendimento automatico.
Importare da origini dati online
Tramite il modulo Import Data l'esperimento può importare dati da diverse origini di dati online mentre l'esperimento viene eseguito.
Nota
Questo articolo fornisce informazioni generali sul modulo Import Data. Per altre informazioni sui tipi di dati a cui è possibile accedere, i formati, i parametri e le risposte alle domande comuni, vedere l'argomento di riferimento del modulo per il modulo Import Data.
Tramite il modulo Import Data è possibile accedere ai dati da una delle diverse origini dati online mentre l'esperimento viene eseguito:
- URL web con HTTP
- Hadoop tramite HiveQL
- Archiviazione BLOB di Azure
- Tabella di Azure
- Database SQL di Azure. Istanza gestita di SQL o SQL Server
- Provider di feed di dati, attualmente OData
- Azure Cosmos DB
Dal momento che si accede a questi dati di training durante l'esecuzione dell'esperimento, i dati sono disponibili solo durante l'esperimento. I dati archiviati in un modulo del set di dati sono invece disponibili per ogni esperimento nell'area di lavoro.
Per accedere alle origini dati online nel tuo esperimento in Studio (versione classica), aggiungi il modulo Importa Dati al tuo esperimento. In Properties (Proprietà) selezionare Launch Import Data Wizard (Avvia importazione dati guidata) per le istruzioni dettagliate per selezionare e configurare l'origine dati. In alternativa, è possibile selezionare manualmente Data source (Origine dati) in Properties (Proprietà) e specificare i parametri necessari per accedere ai dati.
Le origini dati online supportate vengono illustrate nella tabella seguente. Questa tabella riepiloga anche i formati di file supportati e i parametri usati per accedere ai dati.
Importante
Attualmente i moduli Import Data ed Export Data possono leggere e scrivere dati solo da un'istanza di Archiviazione di Azure creata con il modello di distribuzione classica. In altre parole, il nuovo tipo di account di archiviazione BLOB di Azure che offre un livello di accesso di archiviazione a caldo o un livello di accesso di archiviazione a freddo non è ancora supportato.
In genere gli account di archiviazione di Azure creati prima che fosse disponibile questa opzione non dovrebbero essere influenzati. Per creare un nuovo account, selezionare Classica come modello di distribuzione o usare Resource Manager e selezionare Utilizzo generico anziché Archivio BLOB come Tipologia account.
Per altre informazioni, vedere Archivio BLOB di Azure: livelli di archiviazione ad accesso frequente e sporadico.
Origini dati online supportate
Il modulo Importa dati di Machine Learning Studio (versione classica) supporta le origini dati seguenti:
| L'origine dei dati | Descrizione | Parametri |
|---|---|---|
| URL web tramite HTTP | Legge i dati nei formati CSV (Comma-Separated Values), TSV (Tab-Separated Values), ARFF (Attribute-Relation File Format) e SVM-light (Support Vector Machines), da qualsiasi URL Web che usa HTTP. |
URL: specifica il nome completo del file, inclusi l'URL del sito e il nome file, con qualsiasi estensione. Formato dati: specifica uno dei formati di dati supportati, ovvero CSV, TSV, ARFF o SVM-light. Se i dati includono una riga di intestazione, la riga verrà usata per assegnare i nomi di colonna. |
| Hadoop/HDFS | Legge i dati dall'archivio distribuito in Hadoop. Specificare i dati desiderati usando HiveQL, un linguaggio di query analogo a SQL. HiveQL può essere usato anche per aggregare i dati ed eseguire il filtro dei dati prima di aggiungere i dati a Studio (versione classica). |
Hive database query (Query di database Hive): specifica la query Hive usata per generare i dati. HCatalog server URI (URI del server HCatalog): specifica il nome del cluster usando il formato <nome del cluster>.azurehdinsight.net. Hadoop user account name (Nome dell'account utente Hadoop): specifica il nome dell'account utente Hadoop usato per il provisioning del cluster. Hadoop user account password (Password dell'account utente Hadoop): specifica le credenziali usate durante il provisioning del cluster. Per ulteriori informazioni, vedere Creare cluster Hadoop in HDInsight. Location of output data (Posizione dei dati di output): specifica se i dati vengono archiviati in Hadoop Distributed File System (HDFS) o in Azure.
Se si archiviano i dati di output in Azure, sarà necessario specificare il nome dell'account di archiviazione di Azure, la chiave di accesso alle risorse di archiviazione e il nome del contenitore di archiviazione. |
| Database SQL | Legge i dati archiviati in database SQL di Azure, Istanza gestita di SQL o in un database di SQL Server in esecuzione in una macchina virtuale di Azure. |
Nome server di database: specifica il nome del server in cui il database è in esecuzione.
Nel caso di un server SQL ospitato in una macchina virtuale di Azure, immettere tcp:<Virtual Machine DNS Name>, 1433 Nome database: specifica il nome del database nel server. Server user account name (Nome dell'account utente del server): specifica un nome utente per un account con autorizzazioni di accesso per il database. Server user account password (Password dell'account utente del server): specifica la password per l'account utente. Query database: immettere un'istruzione SQL che descriva i dati da leggere. |
| Database SQL in sede | Legge i dati archiviati in un database SQL. |
Gateway dati: specifica il nome del gateway di gestione dati installato su un computer dove è in grado di accedere al database SQL Server. Per informazioni sulla configurazione del gateway, vedere Eseguire analisi avanzate con Machine Learning Studio (versione classica) usando i dati di un server SQL. Nome server di database: specifica il nome del server in cui il database è in esecuzione. Nome database: specifica il nome del database nel server. Server user account name (Nome dell'account utente del server): specifica un nome utente per un account con autorizzazioni di accesso per il database. Nome utente password: fare clic su Enter values (Immettere i valori) per immettere le credenziali del database. È possibile usare l'autenticazione integrata di Windows o l'autenticazione di SQL Server a seconda della configurazione di SQL Server. Query database: immettere un'istruzione SQL che descriva i dati da leggere. |
| Tabella di Azure | Legge i dati dal servizio Table di Azure Storage. Se si leggono raramente quantità elevate di dati, usare il servizio tabelle di Azure. Offre una soluzione di archiviazione flessibile, non relazionale (NoSQL), a scalabilità elevata, poco costosa e a disponibilità elevata. |
Le opzioni disponibili nel modulo Import Data dipendono dal tipo di informazioni a cui si accede, ovvero informazioni pubbliche o un account di archiviazione privato che richiede credenziali di accesso. Questo aspetto è determinato da Authentication Type, che può avere un valore "PublicOrSAS" o "Account", ognuno dei quali ha un set di parametri specifico. URI pubblico o di firma di accesso condiviso. I parametri sono i seguenti:
Specifica le righe da analizzare per i nomi delle proprietà: i valori sono TopN (Prime N), per analizzare il numero di righe specificato, o ScanAll (Tutte) per ottenere tutte le righe nella tabella. Se i dati sono omogenei e prevedibili, è consigliabile selezionare TopN (Prime N) e immettere un numero per N. Per tabelle di grandi dimensioni, questo permette di ottenere tempi di lettura più rapidi. Se i dati sono strutturati con set di proprietà che variano in base alla profondità e alla posizione della tabella, scegliere l'opzione ScanAll (Tutte) per analizzare tutte le righe. Ciò garantisce l'integrità della conversione di proprietà e metadati risultante.
Chiave dell'account: specifica la chiave di archiviazione associata all'account. Nome tabella: specifica il nome della tabella che contiene i dati da leggere. Rows to scan for property names (Righe in cui cercare i nomi di proprietà): i valori sono TopN (Prime N), per analizzare il numero di righe specificato, o ScanAll (Tutte) per ottenere tutte le righe nella tabella. Se i dati sono omogenei e prevedibili, è consigliabile selezionare TopN (Prime N) e immettere un numero per N. Per tabelle di grandi dimensioni, questo permette di ottenere tempi di lettura più rapidi. Se i dati sono strutturati con set di proprietà che variano in base alla profondità e alla posizione della tabella, scegliere l'opzione ScanAll (Tutte) per analizzare tutte le righe. Ciò garantisce l'integrità della conversione delle proprietà e dei metadati risultanti. |
| Archiviazione BLOB di Azure | Legge i dati archiviati nel servizio BLOB dell'Archiviazione di Azure, incluse immagini, testo non strutturato o dati binari. È possibile usare il servizio BLOB per esporre pubblicamente i dati o per archiviare privatamente i dati dell'applicazione. È possibile accedere ai dati da qualsiasi posizione mediante connessioni HTTP o HTTPS. |
Le opzioni disponibili nel modulo Import Data dipendono dal tipo di informazioni a cui si accede, ovvero informazioni pubbliche o un account di archiviazione privato che richiede credenziali di accesso. Ciò è dovuto al tipo di autenticazione, che può avere valore "PublicOrSAS" o "Account". URI pubblico o di firma di accesso condiviso. I parametri sono i seguenti:
Formato file: specifica il formato dei dati nel servizio BLOB. I formati supportati sono CSV, TSV e ARFF.
Chiave dell'account: specifica la chiave di archiviazione associata all'account. Path to container, directory, or blob (Percorso del contenitore, della directory o del BLOB): specifica il nome del BLOB che contiene i dati da leggere. Formato del file BLOB: specifica il formato dei dati nel servizio BLOB. I formati di dati supportati sono CSV, TSV, ARFF, CSV con una codifica specificata, ed Excel.
È possibile usare l'opzione Excel per leggere dati dalle cartelle di lavoro di Excel. Nell'opzioneExcel data format indicare se i dati si trovano in un intervallo di foglio di lavoro di Excel o in una tabella di Excel. Nell'opzione Excel sheet or embedded table (Foglio di Excel o tabella incorporata) specificare il nome del foglio o della tabella da cui leggere i dati. |
| Provider di feed di dati | Legge dati da un provider di feed supportato. È attualmente supportato solo il formato OData (Open Data Protocol). |
Data content type (Tipo di contenuto dei dati): specifica il formato OData. URL di origine: specifica l'URL completo per il feed di dati. Ad esempio, il seguente URL legge dal database di esempio Northwind: https://services.odata.org/northwind/northwind.svc/ |
Importare da un altro esperimento
Talvolta si vuole ottenere un risultato intermedio da un esperimento e usare tale risultato come parte di un altro esperimento. A tale scopo, si salva il modulo come un set di dati:
- Fare clic sull'output del modulo da salvare come set di dati.
- Fare clic su Salva come set di dati.
- Quando richiesto, immettere un nome e una descrizione che consentiranno di identificare facilmente il set di dati.
- Fare clic sul segno di spunta OK .
Al termine del salvataggio, il set di dati sarà disponibile per l'uso in qualsiasi esperimento dell'area di lavoro. È possibile individuarlo nell’elenco Set di dati salvati nella tavolozza dei moduli.