Come configurare la replica dei dati in ingresso in Database di Azure per MySQL
SI APPLICA A:  Database di Azure per MySQL - Server singolo
Database di Azure per MySQL - Server singolo
Importante
Il server singolo del Database di Azure per MySQL è in fase di ritiro. È consigliabile eseguire l'aggiornamento al server flessibile del Database di Azure per MySQL. Per altre informazioni sulla migrazione al server flessibile del Database di Azure per MySQL, vedere Cosa succede al server singolo del Database di Azure per MySQL?
Questo articolo descrive come configurare Replica dei dati in ingresso in Database di Azure per MySQL configurando il server di origine e quello di replica. Per eseguire le procedure descritte in questo articolo è necessario avere già esperienza con i server e i database MySQL.
Nota
Questo articolo contiene riferimenti al termine slave, che Microsoft non usa più. Quando il termine verrà rimosso dal software, verrà rimosso anche dall'articolo.
Per creare una replica nel servizio Database di Azure per MySQL, Replica dei dati in ingresso sincronizza i dati da un server MySQL di origine in locale, in macchine virtuali (VM) o nei servizi di database cloud. Replica dei dati in ingresso si basa sulla posizione del file di log binario (binlog) o sulla replica basata su GTID nativa in MySQL. Per altre informazioni su questo tipo di replica, vedere MySQL binlog replication overview (Panoramica della replica basata su binlog di MySQL).
Prima di eseguire i passaggi descritti in questo articolo, rivedere le limitazioni e i requisiti della replica dei dati in ingresso.
Creare un'istanza del server singolo di Database di Azure per MySQL da usare come replica
Creare una nuova istanza del server singolo di Database di Azure per MySQL, ad esempio
replica.mysql.database.azure.com. Per istruzioni su come creare il server, vedere Creare un server di Database di Azure per MySQL usando il portale di Azure. Questo è il server di "replica" per Replica dei dati in ingresso.Importante
Il server di Database di Azure per MySQL deve essere creato nei piani tariffari Per utilizzo generico o Ottimizzata per la memoria perché la replica dei dati in ingresso è supportata solo in questi livelli. GTID è supportato nelle versioni 5.7 e 8.0 e solo nei server che supportano l'archiviazione fino a 16 TB (archiviazione per utilizzo generico v2).
Creare gli stessi account utente e i privilegi corrispondenti.
Gli account utente non vengono replicati dal server di origine a quello di replica. Se si prevede di specificare gli utenti con accesso al server di replica, è necessario creare manualmente tutti gli account e i privilegi corrispondenti sul nuovo server di Database di Azure per MySQL.
Aggiungere l'indirizzo IP del server di origine alle regole del firewall di quello di replica.
Aggiornare le regole firewall usando il portale di Azure o l'interfaccia della riga di comando di Azure.
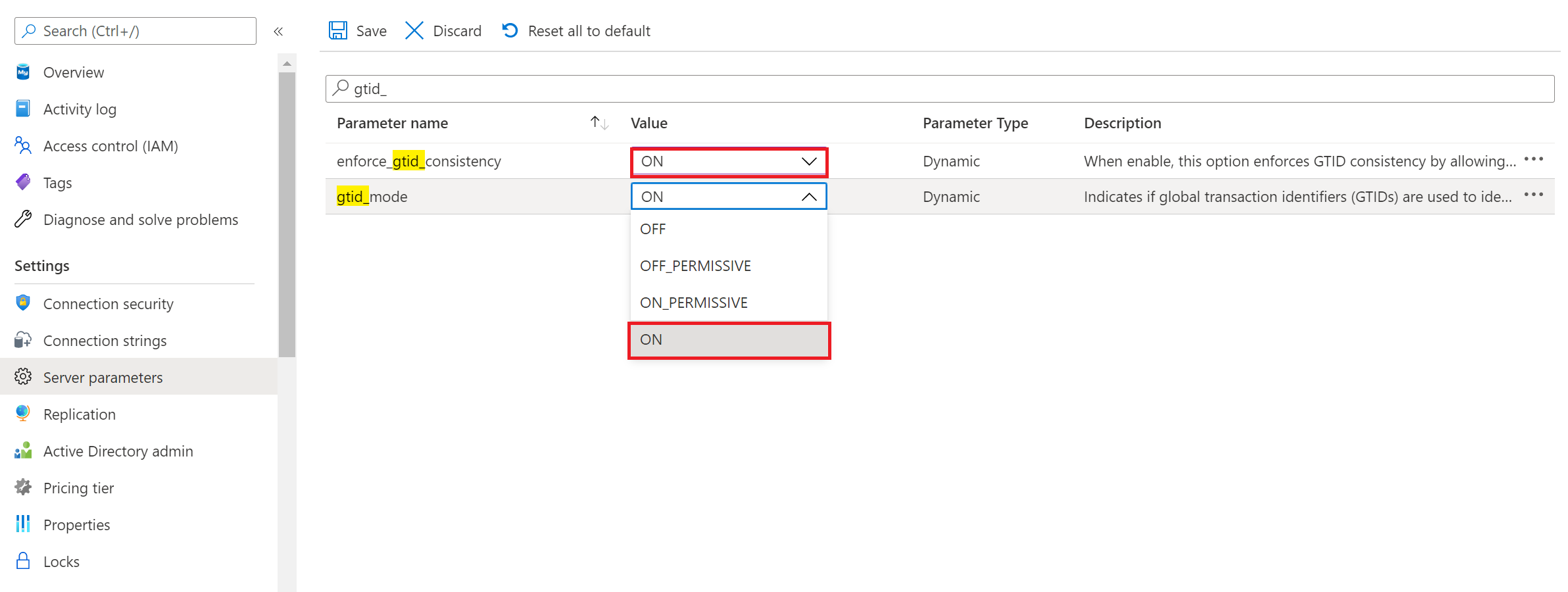
Facoltativo: se si desidera usare la replica basata su GTID dal server di origine al server di replica di Database di Azure per MySQL, è necessario abilitare i seguenti parametri del server nel server di Database di Azure per MySQL, come illustrato nell'immagine del portale seguente:
Configurare il server MySQL di origine
I passaggi seguenti consentono di preparare e configurare il server MySQL ospitato in locale, in una macchina virtuale o un servizio di database ospitato da altri provider di cloud per la replica dei dati in ingresso. Questo server è l'"origine" per Replica dei dati in ingresso.
Prima di procedere, rivedere i requisiti del server di origine.
Assicurarsi che il server di origine consenta il traffico in ingresso e in uscita sulla porta 3306 e che abbia un indirizzo IP pubblico, che il DNS sia accessibile pubblicamente o che abbia un nome di dominio completo (FQDN).
Testare la connettività al server di origine tentando di connettersi da uno strumento, ad esempio la riga di comando MySQL ospitata in un altro computer o da Azure Cloud Shell, disponibile nel portale di Azure.
Se l'organizzazione ha criteri di sicurezza rigorosi e non consente a tutti gli indirizzi IP nel server di origine di abilitare la comunicazione da Azure al server di origine, usare il comando seguente per determinare l'indirizzo IP del server MySQL.
Accedere al server di Database di Azure per MySQL usando uno strumento quale la riga di comando di MySQL.
Eseguire la query seguente.
mysql> SELECT @@global.redirect_server_host;Di seguito è riportato un output di esempio:
+-----------------------------------------------------------+ | @@global.redirect_server_host | +-----------------------------------------------------------+ | e299ae56f000.tr1830.westus1-a.worker.database.windows.net | +-----------------------------------------------------------+Uscire dalla riga di comando di MySQL.
Per ottenere l'indirizzo IP, eseguire il comando seguente nell'utilità ping:
ping <output of step 2b>Ad esempio:
C:\Users\testuser> ping e299ae56f000.tr1830.westus1-a.worker.database.windows.net Pinging tr1830.westus1-a.worker.database.windows.net (**11.11.111.111**) 56(84) bytes of data.Configurare le regole del firewall del server di origine per includere l'indirizzo IP restituito del passaggio precedente sulla porta 3306.
Nota
Questo indirizzo IP potrebbe cambiare a causa di operazioni di manutenzione/distribuzione. Questo metodo di connettività è destinato solo ai clienti che non possono permettersi di consentire tutti gli indirizzi IP sulla porta 3306.
Attivare la registrazione binaria.
Verificare se la registrazione binaria è stata abilitata sul server di origine eseguendo questo comando:
SHOW VARIABLES LIKE 'log_bin';Se la variabile
log_binviene restituita con il valore "ON", la registrazione binaria è abilitata sul server.Se è restituito
log_bincon il valore "OFF" e il server di origine è in esecuzione in locale o in macchine virtuali in cui è possibile accedere al file di configurazione (my.cnf), è possibile seguire questa procedura:Individuare il file di configurazione MySQL (my.cnf) nel server di origine. Ad esempio: /etc/my.cnf
Aprire il file di configurazione per modificarlo e individuare la sezione mysqld nel file.
Nella sezione mysqld aggiungere la riga seguente:
log-bin=mysql-bin.logRiavviare il server di origine MySQL per rendere effettive le modifiche.
Dopo il riavvio del server, verificare che la registrazione binaria sia abilitata. A tal fine eseguire la stessa query:
SHOW VARIABLES LIKE 'log_bin';
Configurare le impostazioni del server di origine.
Per Replica dei dati in ingresso è necessario che il parametro
lower_case_table_namessia coerente tra il server di origine e quello di replica. Per impostazione predefinita, in Database di Azure per MySQL questo parametro è impostato su 1.SET GLOBAL lower_case_table_names = 1;Facoltativo: se si desidera usare la replica basata su GTID, è necessario verificare che GTID sia abilitato nel server di origine. È possibile eseguire il comando seguente sul server MySQL di origine per verificare se gtid_mode sia ON.
show variables like 'gtid_mode';Importante
Tutti i server hanno gtid_mode impostato sul valore predefinito OFF. Non è necessario abilitare GTID nel server MySQL di origine per configurare Replica dei dati in ingresso. Se GTID è già abilitato nel server di origine, è possibile usare facoltativamente la replica basata su GTID per configurare anche Replica dei dati in ingresso con il server singolo di Database di Azure per MySQL. È possibile usare la replica basata su file per configurare la replica dei dati in tutti i server, indipendentemente dalla configurazione gitd_mode nel server di origine.
Creare un nuovo ruolo di replica e configurare le autorizzazioni.
Sul server di origine creare un account utente configurato con i privilegi di replica. Questa operazione può essere eseguita tramite i comandi SQL o uno strumento come MySQL Workbench. Valutare se si prevede di eseguire la replica con SSL, poiché è necessario specificare questa impostazione quando si crea l'utente. Per istruzioni su come aggiungere account utente sul server di origine, vedere la documentazione di MySQL.
Nei comandi seguenti il nuovo ruolo di replica creato può accedere all'origine da qualsiasi computer, non solo da quello che ospita l'origine stessa. Questa operazione viene eseguita specificando "syncuser@'%'" nel comando per la creazione dell'utente. Per altre informazioni su come specificare i nomi degli account, vedere la documentazione di MySQL.
Comando SQL
Replica con SSL
Se SSL deve essere obbligatorio per tutte le connessioni utente, quando si crea un utente usare il comando seguente:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO 'syncuser'@'%' REQUIRE SSL;Replica senza SSL
Se SSL non è obbligatorio per tutte le connessioni, quando si crea un utente usare il comando seguente:
CREATE USER 'syncuser'@'%' IDENTIFIED BY 'yourpassword'; GRANT REPLICATION SLAVE ON *.* TO 'syncuser'@'%';MySQL Workbench
Per creare il ruolo di replica in MySQL Workbench, aprire il pannello Utenti e privilegi nel pannello Gestione e quindi selezionare Aggiungi account.
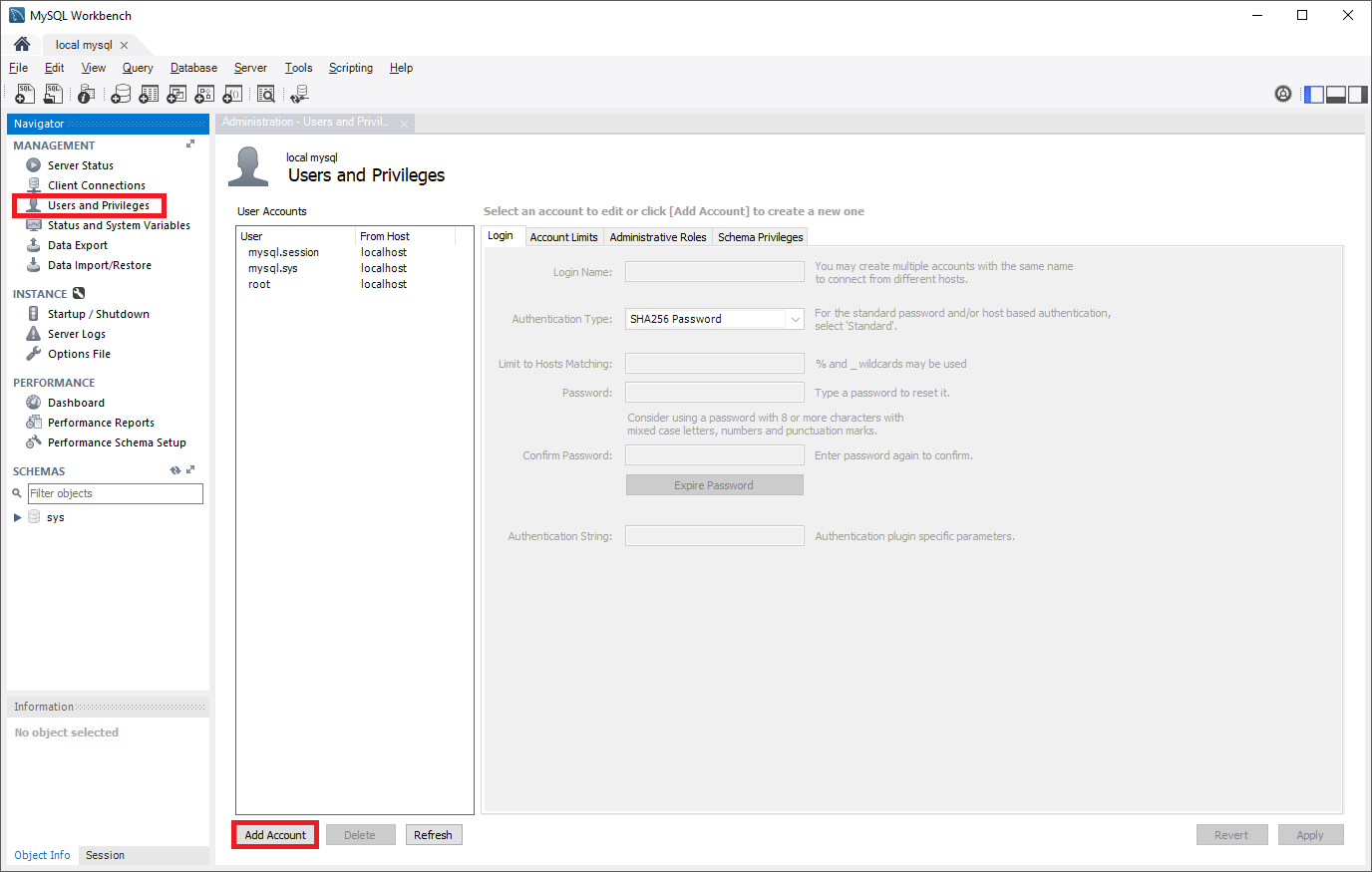
Digitare il nome utente nel campo Login Name (ID di accesso).
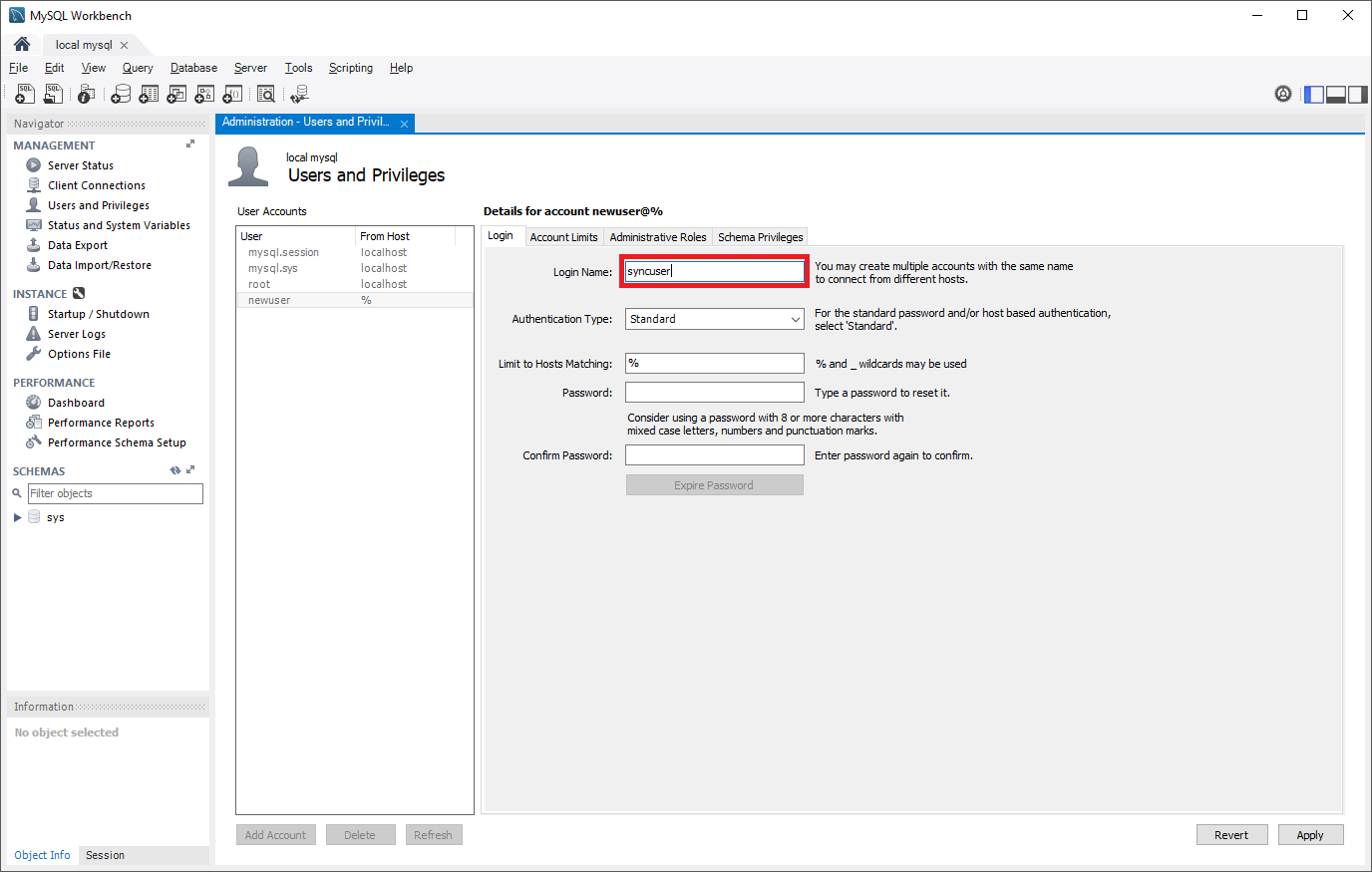
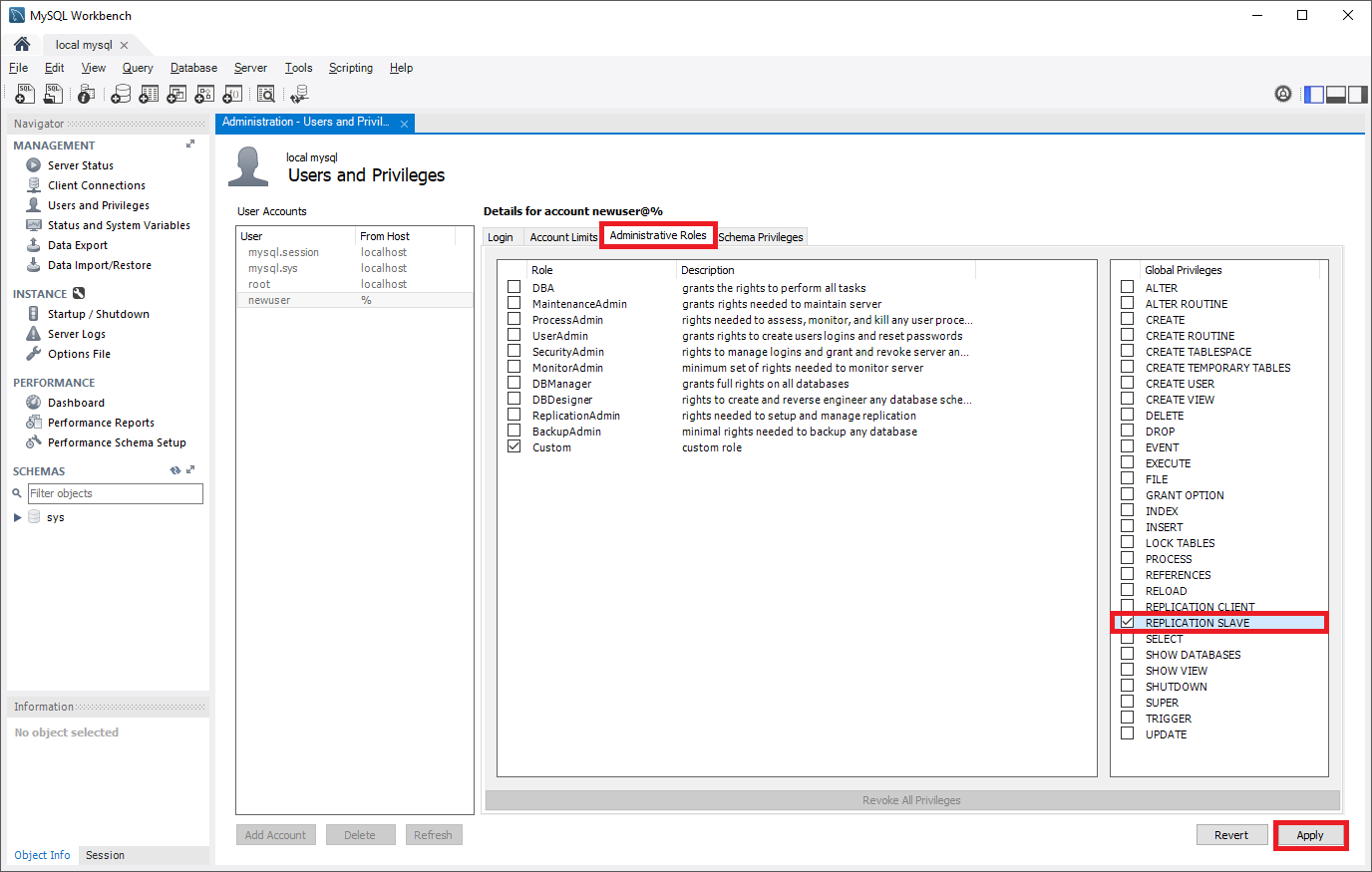
Selezionare il pannello Ruoli amministrativi e quindi selezionare Slave della replica dall'elenco Privilegi globali. Quindi selezionare Applica per creare il ruolo di replica.
Impostare il server di origine sulla modalità in sola lettura.
Prima di avviare il dump del database, il server deve essere impostato in modalità di sola lettura. In questa modalità di sola lettura, il server di origine non sarà in grado di elaborare alcuna transazione di scrittura. Valutare l'impatto che questa impostazione può avere sulle attività aziendali e pianificare l'intervallo di impostazione in sola lettura in un orario di minore attività, se necessario.
FLUSH TABLES WITH READ LOCK; SET GLOBAL read_only = ON;Ottenere l'offset e il nome del file di log binario.
Eseguire il comando
show master statusper determinare l'offset e il nome del file di log binario corrente.show master status;I risultati dovrebbero essere simili ai seguenti: Assicurarsi di annotare il nome del file binario da usare nei passaggi successivi.

Eseguire il dump e ripristinare il server di origine
Determinare i database e le tabelle da replicare in Database di Azure per MySQL ed eseguire il dump dal server di origine.
Per eseguire il dump dei database dal server primario è possibile usare mysqldump. Per informazioni dettagliate, vedere Dump e ripristino. Non è necessario eseguire il dump della libreria MySQL e della libreria di test.
Facoltativo: se si desidera usare la replica basata su GTID, sarà necessario identificare il GTID dell'ultima transazione eseguita nel database primario. Per prendere nota del GTID dell'ultima transazione eseguita nel server master, è possibile usare il comando seguente.
show global variables like 'gtid_executed';Impostare il server di origine sulla modalità in lettura/scrittura.
Dopo avere eseguito il dump del database, ripristinare la modalità di lettura/scrittura sul server MySQL di origine.
SET GLOBAL read_only = OFF; UNLOCK TABLES;Ripristinare il file di dump nel nuovo server.
Ripristinare il file di dump nel server creato nel servizio Database di Azure per MySQL. Per informazioni su come ripristinare un file di dump in un server MySQL, vedere Dump e ripristino. Se il file di dump ha grandi dimensioni, caricarlo in una macchina virtuale in Azure nella stessa area del server di replica. Ripristinare quindi il file nel server di Database di Azure per MySQL dalla macchina virtuale.
Facoltativo: prendere nota del GTID del server ripristinato in Database di Azure per MySQL per accertare che corrisponda al server primario. È possibile usare il comando di seguito per prendere nota del GTID del valore GTID eliminato nel server di replica di Database di Azure per MySQL. Perché la replica basata su GTID funzioni, il valore di gtid_purged deve essere uguale a quello di gtid_executed nel master indicato nel passaggio 2.
show global variables like 'gtid_purged';
Collegare il server di origine e quello di replica per avviare la Replica dei dati in ingresso
Impostare il server di origine.
Tutte le funzioni di replica dei dati in ingresso vengono eseguite tramite stored procedure. Per informazioni su tali procedure, vedere Stored procedure per la replica dei dati in ingresso. Le stored procedure possono essere eseguite nella shell di MySQL o in MySQL Workbench.
Per collegare due server e avviare la replica, accedere al server di replica di destinazione nel servizio Database di Azure per MySQL e impostare l'istanza esterna come server di origine. Questa operazione viene eseguita tramite la stored procedure
mysql.az_replication_change_masternel server di Database di Azure per MySQL.CALL mysql.az_replication_change_master('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_log_file>', <master_log_pos>, '<master_ssl_ca>');Facoltativo: se si desidera usare la replica basata su GTID, è necessario usare il comando seguente per collegare i due server
call mysql.az_replication_change_master_with_gtid('<master_host>', '<master_user>', '<master_password>', <master_port>, '<master_ssl_ca>');master_host: nome host del server di origine
master_user: nome utente per il server di origine
master_password: password per il server di origine
master_port: numero di porta in cui il server di origine è in ascolto delle connessioni (3306 è la porta predefinita in cui MySQL è In ascolto).
master_log_file: nome del file di log binario da
show master statusin esecuzionemaster_log_pos: posizione del file di log binario da
show master statusin esecuzionemaster_ssl_ca: contesto del certificato della CA. Se non si usa SSL, passare una stringa vuota.
È consigliabile passare questo parametro sotto forma di variabile. Per altre informazioni, vedere gli esempi seguenti.
Nota
Se il server di origine è ospitato in una macchina virtuale di Azure, impostare "Consenti l'accesso ai servizi di Azure" su "ON" per consentire ai server di origine e di replica di comunicare tra loro. Questa impostazione può essere modificata dalle opzioni di sicurezza delle connessioni. Per altre informazioni, vedere Gestire le regole del firewall tramite il portale.
Esempi
Replica con SSL
La variabile
@certviene creata eseguendo i comandi MySQL seguenti:SET @cert = '-----BEGIN CERTIFICATE----- PLACE YOUR PUBLIC KEY CERTIFICATE'`S CONTEXT HERE -----END CERTIFICATE-----'La replica con SSL viene configurata tra un server di origine ospitato nel dominio "companya.com" e un server di replica ospitato in Database di Azure per MySQL. Sulla replica viene eseguita questa stored procedure.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, @cert);Replica senza SSL
La replica senza SSL viene configurata tra un server di origine ospitato nel dominio "companya.com" e un server di replica ospitato in Database di Azure per MySQL. Sulla replica viene eseguita questa stored procedure.
CALL mysql.az_replication_change_master('master.companya.com', 'syncuser', 'P@ssword!', 3306, 'mysql-bin.000002', 120, '');Configurare il filtro.
Se si desidera ignorare la replica di alcune tabelle dal server master, aggiornare il parametro del server
replicate_wild_ignore_tablenel server di replica. È possibile fornire più modelli di tabella. A tal fine usare un elenco delimitato da virgole.Per altre informazioni su questo parametro, esaminare la documentazione di MySQL.
Per aggiornarlo è possibile usare il portale di Azure o l'interfaccia della riga di comando di Azure.
Avviare la replica.
Chiamare la stored procedure
mysql.az_replication_startper avviare la replica.CALL mysql.az_replication_start;Verificare lo stato della replica.
Chiamare il comando
show slave statussul server di replica per visualizzare lo stato della replica.show slave status;Se lo stato di
Slave_IO_RunningeSlave_SQL_Runningè "sì" e il valore diSeconds_Behind_Masterè "0", la replica funziona correttamente.Seconds_Behind_Masterindica il ritardo della replica. Se il valore non è "0", significa che la replica sta elaborando gli aggiornamenti.
Altre stored procedure utili per le operazioni di Replica dei dati in ingresso
Arrestare la replica
Per arrestare la replica tra il server di origine e quello di replica, usare la stored procedure seguente:
CALL mysql.az_replication_stop;
Rimuovere la relazione di replica
Per rimuovere la relazione tra il server di origine e quello di replica, usare la stored procedure seguente:
CALL mysql.az_replication_remove_master;
Ignorare un errore di replica
Per ignorare un errore di replica e consentire alla replica di proseguire, usare la stored procedure seguente:
CALL mysql.az_replication_skip_counter;
Facoltativo: se si desidera usare la replica basata su GTID, usare la stored procedure seguente per ignorare una transazione
call mysql. az_replication_skip_gtid_transaction(‘<transaction_gtid>’)
La procedura può ignorare la transazione per il GTID specificato. Se il formato GTID non è corretto o se la transazione GTID è già stata eseguita, la procedura non verrà eseguita. Il GTID per una transazione può essere determinato analizzando il log binario per controllare gli eventi delle transazioni. MySQL offre un'utilità mysqlbinlog per analizzare i log binari e visualizzare il relativo contenuto in formato testo, utile per identificare GTID della transazione.
Importante
Questa procedura può essere usata solo per ignorare una transazione. Non è possibile usarla per ignorare il set GTID o per impostare gtid_purged.
Per ignorare la transazione successiva dopo la posizione di replica corrente, identificare il GTID della transazione successiva usando il comando seguente, come illustrato di seguito.
SHOW BINLOG EVENTS [IN 'log_name'] [FROM pos][LIMIT [offset,] row_count]

Passaggi successivi
- Altre informazioni sulla replica dei dati in ingresso in Database di Azure per MySQL.