Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
È possibile eseguire la migrazione di dati, carichi di lavoro e applicazioni da Azure Data Lake Storage Gen1 ad Azure Data Lake Storage Gen2. Questo articolo illustra l'approccio di migrazione consigliato e illustra i diversi modelli di migrazione e quando usarli. Per una lettura più semplice, questo articolo usa il termine Gen1 per fare riferimento ad Azure Data Lake Storage Gen1 e il termine Gen2 per fare riferimento ad Azure Data Lake Storage Gen2.
Nota
Azure Data Lake Storage Gen1 è ora ritirato. Vedere l'annuncio di ritiro qui. Le risorse di Data Lake Storage Gen1 non sono più accessibili.
Azure Data Lake Storage Gen2 è basato sull'archiviazione BLOB di Azure e offre un set di funzionalità dedicate all'analisi dei Big Data. Data Lake Storage Gen2 combina funzionalità di Azure Data Lake Storage Gen1, ad esempio semantica del file system, sicurezza a livello di directory e file e scalabilità con funzionalità di archiviazione a basso costo, archiviazione a livelli, disponibilità elevata/ripristino di emergenza da Archiviazione BLOB di Azure.
Nota
Poiché Gen1 e Gen2 sono servizi diversi, non esiste un'esperienza di aggiornamento sul posto. Per semplificare la migrazione a Gen2 usando il portale di Azure, vedere Eseguire la migrazione di Azure Data Lake Storage da Gen1 a Gen2 usando il portale di Azure.
Approccio consigliato
Per eseguire la migrazione da Gen1 a Gen2, è consigliabile adottare l'approccio seguente.
Passaggio 1: valutare l'idoneità
Passaggio 2: preparare la migrazione
Passaggio 3: eseguire la migrazione di carichi di lavoro di dati e applicazioni
Passaggio 4: Eseguire il cutover da Gen1 a Gen2
Passaggio 1: valutare l'idoneità
Informazioni sull'offerta Data Lake Storage Gen2, sui vantaggi, sui costi e sull'architettura generale.
Confrontare le funzionalità di Gen1 con quelle di Gen2.
Esaminare un elenco di problemi noti per valutare eventuali lacune nelle funzionalità.
Gen2 supporta funzionalità di archiviazione BLOB, ad esempio la registrazione diagnostica, i livelli di accesso e i criteri di gestione del ciclo di vita dell'archiviazione BLOB. Se si è interessanti nell'uso di una di queste funzionalità, esaminare il livello di supporto corrente.
Esaminare lo stato corrente del supporto dell'ecosistema di Azure per assicurarsi che Gen2 supporti tutti i servizi da cui dipendono le soluzioni.
Passaggio 2: preparare la migrazione
Identificare i set di dati di cui desiderate eseguire la migrazione.
Sfruttare questa opportunità per pulire i set di dati che non si usano più. A meno che non si intenda eseguire la migrazione di tutti i dati contemporaneamente, approfitta di questo tempo per identificare gruppi logici di dati che possono essere migrati in fasi.
Eseguire un'analisi dell'invecchiamento (o simile) sul tuo account Gen1 per identificare quali file o cartelle rimangono nell'inventario per molto tempo o potrebbero diventare obsoleti.
Determinare l'impatto della migrazione sull'azienda.
Si consideri, ad esempio, se è possibile permettersi tempi di inattività durante la migrazione. Queste considerazioni consentono di identificare un modello di migrazione appropriato e di scegliere gli strumenti più appropriati.
Creare un piano di migrazione.
È consigliabile usare questi modelli di migrazione. È possibile scegliere uno di questi modelli, combinarli insieme o progettare un modello personalizzato personalizzato.
Passaggio 3: Eseguire la migrazione di dati, carichi di lavoro e applicazioni
Eseguire la migrazione di dati, carichi di lavoro e applicazioni usando il modello preferito. È consigliabile convalidare gli scenari in modo incrementale.
Creare un account di archiviazione e abilitare la funzionalità dello spazio dei nomi gerarchico.
Eseguire la migrazione dei dati.
Configura i servizi nei tuoi carichi di lavoro affinché puntino al tuo endpoint Gen2.
Per i cluster HDInsight, è possibile aggiungere le impostazioni di configurazione dell'account di archiviazione al file %HADOOP_HOME%/conf/core-site.xml. Se si prevede di eseguire la migrazione di tabelle Hive esterne da Gen1 a Gen2, assicurarsi di aggiungere anche le impostazioni dell'account di archiviazione al file %HIVE_CONF_DIR%/hive-site.xml.
È possibile modificare le impostazioni di ogni file usando Apache Ambari. Per trovare le impostazioni dell'account di archiviazione, vedere Supporto di Hadoop azure: ABFS - Azure Data Lake Storage Gen2. In questo esempio viene usata l'impostazione per abilitare l'autorizzazione
fs.azure.account.keycon chiave condivisa:<property> <name>fs.azure.account.key.abfswales1.dfs.core.windows.net</name> <value>your-key-goes-here</value> </property>Per collegamenti ad articoli che consentono di configurare HDInsight, Azure Databricks e altri servizi di Azure per l'uso di Gen2, vedere Servizi di Azure che supportano Azure Data Lake Storage Gen2.
Aggiornare le applicazioni per l'uso delle API Gen2. Vedere queste guide:
Aggiornare gli script per utilizzare i cmdlet di PowerShell di Data Lake Storage Gen2 e i comandi Azure CLI.
Cercare riferimenti URI che contengono la stringa
adl://nei file di codice o nei notebook di Databricks, file HQL Apache Hive o qualsiasi altro file usato come parte dei carichi di lavoro. Sostituire questi riferimenti con l'URI Gen2 formattato del nuovo account di archiviazione. Ad esempio, l'URI gen1:adl://mydatalakestore.azuredatalakestore.net/mydirectory/myfilepotrebbe diventareabfss://myfilesystem@mydatalakestore.dfs.core.windows.net/mydirectory/myfile.Configurare la sicurezza dell'account per includere ruoli di Azure, sicurezza a livello di file e cartelle e firewall di Archiviazione di Azure e reti virtuali.
Passaggio 4: Eseguire il cutover da Gen1 a Gen2
Dopo aver certi che le applicazioni e i carichi di lavoro siano stabili in Gen2, è possibile iniziare a usare Gen2 per soddisfare gli scenari aziendali. Disattivare tutte le pipeline rimanenti in esecuzione su Gen1 e chiudere il proprio account Gen1.
Funzionalità di Gen1 e Gen2
Questa tabella confronta le funzionalità di Gen1 con quella di Gen2.
Modelli da Gen1 a Gen2
Scegliere un modello di migrazione e quindi modificarlo in base alle esigenze.
| Modello di migrazione | Dettagli |
|---|---|
| Trasferimento in modalità lift-and-shift | Modello più semplice. Ideale se le pipeline di dati possono permettersi tempi di inattività. |
| Copia incrementale | Simile al lift-and-shift, ma con meno tempi di inattività. Ideale per grandi quantità di dati che richiedono più tempo per la copia. |
| Pipeline doppia | Ideale per le pipeline che non possono permettersi tempi di inattività. |
| Sincronizzazione bidirezionale | Analogamente alla doppia pipeline, ma con un approccio per fasi, più adatto a pipeline più complesse. |
Esaminiamo più da vicino ogni modello.
Modello di trasferimento e migrazione diretta
Questo è il modello più semplice.
Bloccare tutte le scritture su Gen1.
Spostare i dati da Gen1 a Gen2. È consigliabile usare Azure Data Factory o il portale di Azure. Gli ACL vengono copiati insieme ai dati.
Orientare le operazioni di inserimento e i flussi di lavoro verso Gen2.
Disattivare Gen1.
Scopri il codice di esempio per il pattern lift and shift nel nostro esempio di migrazione Lift and Shift.
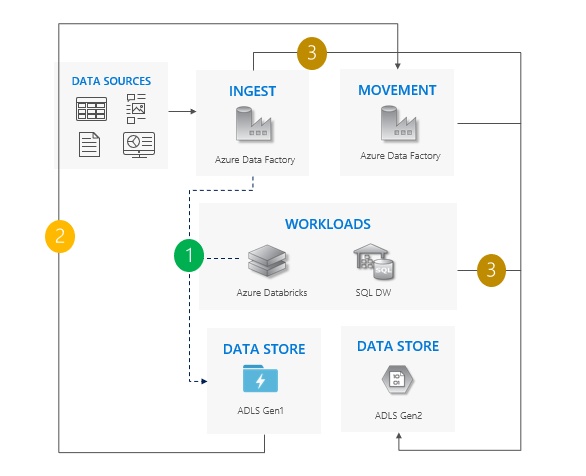
Considerazioni sull'uso del modello di sollevamento e spostamento
Passaggio simultaneo da Gen1 a Gen2 per tutti i carichi di lavoro.
Attendere tempi di inattività durante la migrazione e il periodo di transizione.
Ideale per le pipeline che possono consentire tempi di inattività e che tutte le app possono essere aggiornate contemporaneamente.
Suggerimento
Prendere in considerazione l'uso del portale di Azure per ridurre il tempo di inattività e ridurre il numero di passaggi necessari per completare la migrazione.
Modello di copia incrementale
Iniziare a spostare i dati da Gen1 a Gen2. È consigliabile usare Azure Data Factory. Gli ACL vengono copiati insieme ai dati.
Copiare in modo incrementale nuovi dati da Gen1.
Dopo aver copiato tutti i dati, interrompere tutte le scritture su Gen1 e reindirizzare i carichi di lavoro su Gen2.
Disattivare Gen1.
Consulta il nostro codice di esempio per il modello di copia incrementale nel nostro Incremental copy migration sample.
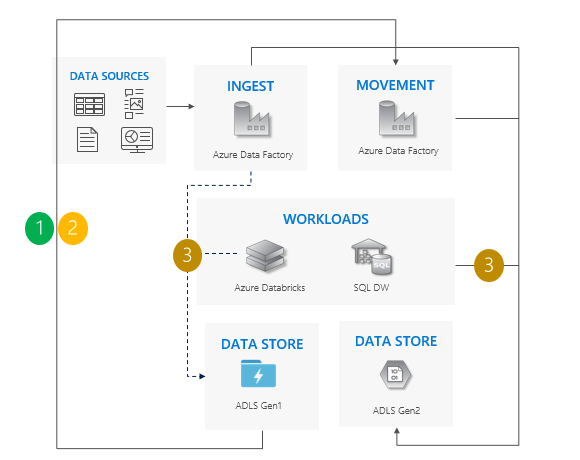
Considerazioni sull'uso del modello di copia incrementale:
Passaggio da Gen1 a Gen2 per tutti i carichi di lavoro simultaneamente.
Si prevede un periodo di inattività solo durante la fase di transizione.
Ideale per le pipeline in cui tutte le app sono aggiornate contemporaneamente, ma la copia dei dati richiede più tempo.
Modello di pipeline doppia
Spostare i dati da Gen1 a Gen2. È consigliabile usare Azure Data Factory. Gli ACL vengono copiati con i dati.
Inserire nuovi dati sia in Gen1 che in Gen2.
Indirizzare i carichi di lavoro verso Gen2.
Arrestare tutte le scritture in Gen1 e quindi disattivare Gen1.
Scopri il nostro codice di esempio per il modello di doppia pipeline nell' esempio di migrazione Doppia Pipeline.
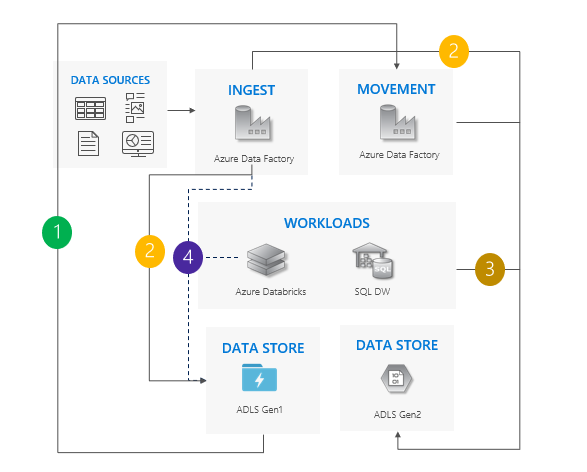
Considerazioni sull'uso del modello di doppia pipeline:
Le pipeline Gen1 e Gen2 vengono eseguite affiancate.
Supporta un tempo di inattività pari a zero.
Ideale in situazioni in cui i carichi di lavoro e le applicazioni non possono permettersi tempi di inattività ed è possibile inserire in entrambi gli account di archiviazione.
Modello di sincronizzazione bidirezionale
Configurare la replica bidirezionale tra Gen1 e Gen2. È consigliabile usare WanDisco. Offre una funzionalità di ripristino per i dati esistenti.
Al termine di tutti gli spostamenti, arrestare tutte le scritture in Gen1 e disattivare la replica bidirezionale.
Disattivare Gen1.
Scopri il nostro codice di esempio per il modello di sincronizzazione bidirezionale nel nostro esempio di migrazione della sincronizzazione bidirezionale.
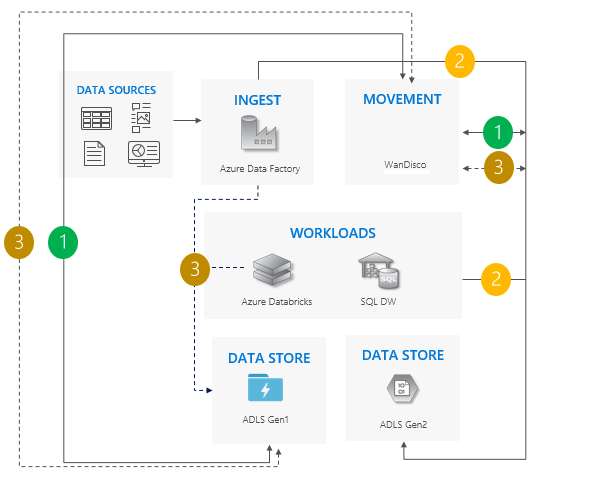
Considerazioni sull'uso del modello di sincronizzazione bidirezionale:
Ideale per scenari complessi che coinvolgono un numero elevato di pipeline e dipendenze in cui un approccio in più fasi potrebbe avere più senso.
Il lavoro di migrazione è elevato, ma offre supporto in parallelo per Gen1 e Gen2.
Passaggi successivi
- Informazioni sulle varie parti della configurazione della sicurezza per un account di archiviazione. Per altre informazioni, vedere la Guida alla sicurezza di Archiviazione di Azure.
- Ottimizzare le prestazioni per Data Lake Store. Per le prestazioni, vedere Ottimizzare Azure Data Lake Storage Gen2
- Esaminare le procedure consigliate per la gestione di Data Lake Store. Vedere Procedure consigliate per l'uso di Azure Data Lake Storage Gen2