Ricerca full-text
In SQL Server e nel database SQL di Azure la ricerca full-text consente ad applicazioni e utenti di eseguire query full-text su dati di tipo carattere in tabelle di SQL Server. Affinché le query full-text possano essere eseguite in una determinata tabella, l'amministratore del database deve prima creare un indice full-text nella tabella in questione. L'indice full-text include una o più colonne basate su caratteri nella tabella. In queste colonne possono essere presenti i seguenti tipi di dati: char, varchar, nchar, nvarchar, text, ntext, image, xml, o varbinary(max) e FILESTREAM. Ogni indice full-text consente di indicizzare una o più colonne della tabella e ciascuna colonna può essere utilizzata con una lingua specifica.
Attraverso le query full-text è possibile eseguire ricerche linguistiche rispetto ai dati di testo contenuti negli indici full-text, utilizzando parole e frasi in base alle regole di una determinata lingua, come ad esempio l'inglese o il giapponese. Le query full-text possono contenere semplici parole e frasi oppure più forme di una parola o frase. Una query full-text restituisce qualsiasi documento contenente almeno una corrispondenza, nota anche come riscontro. Si ottiene una corrispondenza quando un documento di destinazione contiene tutti i termini specificati nella query full-text e soddisfa qualsiasi altra condizione di ricerca, come ad esempio la distanza entro i termini corrispondenti.
Nota
La ricerca full-text è un componente facoltativo del motore di database SQL Server. Per altre informazioni, vedere Installare SQL Server 2014.
Funzionalità della ricerca full-text
La ricerca full-text è applicabile a un'ampia gamma di scenari aziendali, ad esempio la ricerca di elementi in un sito Web; studio legale che cerca le storie dei casi in un repository di dati legali; o le descrizioni dei processi corrispondenti ai reparti di risorse umane con riprendi archiviati. Le attività di sviluppo e amministrazione di base della ricerca full-text sono equivalenti indipendentemente dagli scenari aziendali. In uno scenario aziendale, tuttavia, l'indice e le query full-text possono essere modificati in base agli obiettivi aziendali da raggiungere. È ad esempio probabile che per un'attività di commercio elettronico l'ottimizzazione delle prestazioni sia ritenuta più importante della classificazione dei risultati, dell'accuratezza delle chiamate (quante delle corrispondenze esistenti vengono effettivamente restituite da una query full-text) o del supporto di più lingue. Per un ufficio legale, invece, l'aspetto più importante potrebbe essere la restituzione di ogni possibile occorrenza (richiamo totale delle informazioni).
Query della ricerca full-text
Dopo l'aggiunta delle colonne a un indice full-text, gli utenti e le applicazioni possono eseguire query full-text sul testo contenuto all'interno delle colonne. Queste query possono consentire la ricerca degli elementi seguenti:
Una o più parole o frasi specifiche (termine semplice)
Parola o frase in cui le parole iniziano con il testo specificato (termine di prefisso)
Forme flessive di una parola specifica (termine di generazione)
Una parola o frase vicina a un'altra parola o frase (termine di prossimità)
Sinonimi di una parola specifica (thesaurus)
Parole o frasi che usano valori ponderati (termine ponderato)
Per le query di ricerca full-text non viene fatta distinzione tra maiuscole e minuscole. Ad esempio, dalla ricerca di "Alluminio" o "alluminio" vengono restituiti gli stessi risultati.
Le query full-text usano un piccolo set di predicati Transact-SQL (CONTAINS e FREETEXT) e funzioni (CONTAINSTABLE e FREETEXTTABLE). Tuttavia, gli obiettivi di ricerca di un determinato scenario aziendale influiscono sulla struttura delle query full-text. Ad esempio:
Commercio elettronico: ricerca di un prodotto in un sito Web
SELECT product_id FROM products WHERE CONTAINS(product_description, "Snap Happy 100EZ" OR FORMSOF(THESAURUS,'Snap Happy') OR '100EZ') AND product_cost < 200 ;Ricerca di scenari di assunzione per i candidati al lavoro che hanno esperienza con SQL Server:
SELECT candidate_name,SSN FROM candidates WHERE CONTAINS(candidate_resume,"SQL Server") AND candidate_division = 'DBA';
Per altre informazioni, vedere Esecuzione della query con ricerca Full-Text.
Confronto tra LIKE e la ricerca full-text
Contrariamente alla ricerca full-text, il predicato LIKE di Transact-SQL funziona unicamente con modelli di caratteri. Non è inoltre possibile utilizzare il predicato LIKE per eseguire query su dati binari formattati. Inoltre, l'esecuzione di una query LIKE su una grande quantità di dati di testo non strutturati è molto più lenta dell'esecuzione di una query full-text equivalente sugli stessi dati. Una query LIKE eseguita su milioni di righe di dati di testo può richiedere diversi minuti, mentre per una query full-text sugli stessi dati possono essere necessari al massimo pochi secondi, a seconda del numero di righe restituite.
Componenti e architettura della ricerca full-text
L'architettura della ricerca full-text è costituita dai processi seguenti:
Processo di SQL Server (sqlservr.exe).
Processo host del daemon di filtri (fdhost.exe).
Ai fini della sicurezza, i filtri vengono caricati da processi separati definiti host del daemon di filtri. I processi fdhost.exe vengono creati da un servizio dell'utilità di avvio di FDHOST (MSSQLFDLauncher) e vengono eseguiti con le credenziali di sicurezza dell'account del servizio dell'utilità di avvio di FDHOST. Il funzionamento delle query e dell'indicizzazione full-text dipende quindi dall'esecuzione del servizio dell'utilità di avvio di FDHOST. Per informazioni sulla configurazione dell'account del servizio per questo servizio, vedere Impostazione dell'account del servizio dell'Utilità di avvio del daemon di filtri full-text.
In questi due processi sono inclusi i componenti dell'architettura della ricerca full-text, riepilogati con le relative relazioni nell'illustrazione seguente. I componenti vengono descritti dopo l'illustrazione.
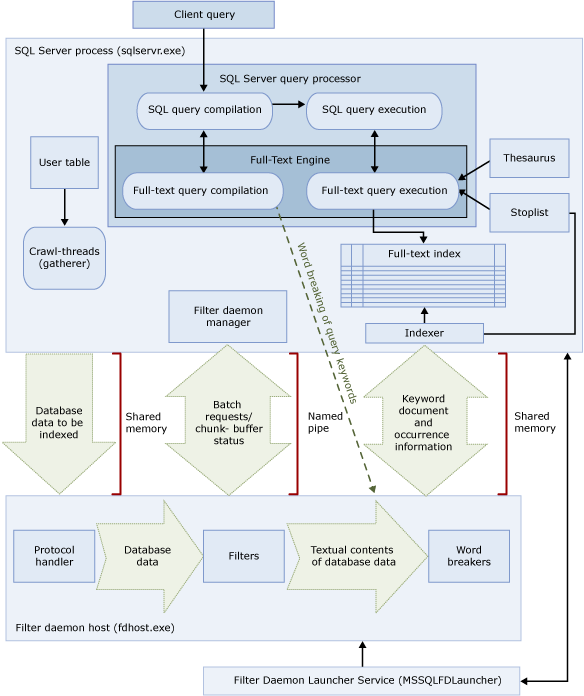
Processo di SQL Server
Il processo di SQL Server usa i componenti seguenti per la ricerca full-text:
Tabelle utente. In queste tabelle sono contenuti i dati da inserire nell'indice full-text.
Gatherer full-text. Il gatherer full-text funziona con i thread della ricerca per indicizzazione full-text e consente di pianificare e gestire il popolamento degli indici full-text, nonché di monitorare i cataloghi full-text.
File del thesaurus. In questi file sono contenuti i sinonimi dei termini da cercare. Per altre informazioni, vedere Configurare e gestire i file del thesaurus per la ricerca full-text.
Oggetti dell'elenco di parole non significative. Negli oggetti dell'elenco di parole non significative sono inclusi un insieme di parole comuni che non risultano utili per la ricerca. Per altre informazioni, vedere Configurare e gestire parole non significative ed elenchi di parole non significative per la ricerca full-text.
SQL Server processore di query. Query Processor consente di compilare ed eseguire query SQL. Se in una query SQL è inclusa una query di ricerca full-text, la query viene inviata al motore di ricerca full-text sia durante la compilazione sia durante l'esecuzione. Il risultato della query viene messo a confronto con l'indice full-text.
Motore di ricerca full-text. Il motore di Full-Text in SQL Server è completamente integrato con il processore di query. Il motore di ricerca full-text compila ed esegue query full-text. Come parte dell'esecuzione di query, il motore di ricerca full-text può ricevere input dal thesaurus e dall'elenco di parole non significative.
Writer di indici (indicizzatore). Il writer di indici consente di compilare la struttura utilizzata per archiviare i token indicizzati.
Strumento di gestione del daemon di filtri. Lo strumento di gestione del daemon di filtri consente di monitorare lo stato dell'host del daemon di filtri per il motore di ricerca full-text.
Processo host del daemon di filtri
L'host del daemon di filtri è un processo avviato dal motore di ricerca full-text e consente l'esecuzione dei componenti della ricerca full-text seguenti, responsabili dell'accesso, del filtraggio e del word breaking di dati dalle tabelle, nonché del word breaking e dello stemming dell'input della query.
I componenti dell'host del daemon di filtri sono i seguenti:
Protocol handler. Questo componente consente di effettuare il pull dei dati dalla memoria per un'ulteriore elaborazione e di accedere ai dati da una tabella utente in un database specificato. È inoltre responsabile della raccolta dei dati dalle colonne oggetto dell'indicizzazione full-text e del loro passaggio all'host del daemon di filtri tramite il quale verrà applicato il filtro e il word breaker in base alle specifiche esigenze.
Filtri. Per alcuni tipi di dati è richiesta l'applicazione di un filtro prima che i dati di un documento possano essere sottoposti all'indicizzazione full-text, inclusi i dati nelle colonne
varbinary,varbinary(max),imageoxml. Il filtro utilizzato per un documento dipende dal relativo tipo. Vengono infatti utilizzati filtri diversi per documenti di Microsoft Word (doc), documenti di Microsoft Excel (xls) e documenti XML (xml). Il filtro estrae blocchi di testo dal documento, rimuovendo la formattazione incorporata e mantenendo il testo e, potenzialmente, le informazioni sulla posizione del testo. Il risultato è un flusso di informazioni testuali. Per altre informazioni, vedere Configurazione e gestione di filtri per la ricerca.Word breaker e stemmer. Un word breaker è un componente specifico della lingua che consente di trovare i delimitatori di parola in base alle regole lessicali di una determinata lingua (word breaking). Ogni word breaker è associato a uno stemmer specifico della lingua che coniuga i verbi ed esegue le espansioni flessionali. In fase di indicizzazione, l'host del daemon di filtri utilizza un word breaker e uno stemmer per eseguire l'analisi linguistica sui dati testuali di una colonna di tabella specificata. Il word breaker e lo stemmer utilizzati per l'indicizzazione della colonna sono determinati dalla lingua associata a una colonna di tabella nell'indice full-text. Per altre informazioni, vedere Configurare e gestire word breaker e stemmer per la ricerca.
Elaborazione della ricerca full-text
La ricerca full-text è supportata dal motore di ricerca full-text che svolge due ruoli, vale a dire il supporto per l'indicizzazione e quello per l'esecuzione di query.
Processo di indicizzazione full-text
Quando viene iniziato un popolamento full-text, noto anche come ricerca per indicizzazione, tramite il motore di ricerca full-text viene eseguito il push di batch di grandi dimensioni di dati in memoria e viene inviata una notifica all'host del daemon di filtri. L'host filtra ed esegue il word breaking dei dati ed esegue inoltre la conversione dei dati convertiti in elenchi di parole invertiti. La ricerca full-text effettua quindi il pull dei dati convertiti dagli elenchi di parole, elabora i dati per rimuovere le parole non significative e salva in modo permanente gli elenchi di parole per un batch in uno o più indici invertiti.
Quando si indicizzano i dati archiviati in una varbinary(max) colonna oimage, il filtro, che implementa l'interfaccia IFilter, estrae il testo in base al formato di file specificato per tali dati, ad esempio Microsoft Word. In alcuni casi, i componenti del filtro richiedono che i varbinary(max)dati o image vengano scritti nella cartella filterdata anziché essere inseriti nella memoria.
Nell'ambito dell'elaborazione, i dati di testo raccolti vengono sottoposti a un word breaker per separare il testo in singoli token o parole chiave. La lingua utilizzata per la suddivisione in token viene specificata a livello di colonna o può essere identificata all'interno dei dati varbinary(max), image o xml dal componente filtro.
È possibile eseguire un'ulteriore elaborazione per rimuovere le parole non significative e normalizzare i token prima di archiviarli nell'indice full-text o in un frammento di indice.
Al termine di un popolamento, viene attivato un processo di unione conclusivo che associa i frammenti di indice in un singolo indice full-text master. Ciò consente prestazioni di query superiori poiché è necessario eseguire query solo sull'indice master anziché su alcuni frammenti di indice ed è possibile utilizzare statistiche di punteggio migliori per la classificazione della pertinenza.
Processo di esecuzione di query full-text
Query Processor consente di passare le parti full-text di una query al motore di ricerca full-text affinché vengano elaborate. Il motore di ricerca full-text esegue il word breaking e, facoltativamente, le espansioni del thesaurus, lo stemming e l'elaborazione delle parole non significative. Le parti full-text della query vengono rappresentate come operatori SQL, principalmente come funzioni di flusso con valori di tabella. Durante l'esecuzione della query, queste funzioni accedono all'indice invertito per recuperare i risultati corretti. I risultati vengono restituiti al client immediatamente oppure dopo essere stati ulteriormente elaborati.
Componenti linguistici e Supporto per la lingua nella ricerca full-text
La ricerca full-text supporta quasi 50 lingue, tra cui inglese, spagnolo, cinese, giapponese, arabo, bengalese e hindi. Per un elenco completo dei linguaggi full-text supportati, vedere sys.fulltext_languages (Transact-SQL). A ognuna delle colonne contenute nell'indice full-text è associato un identificatore delle impostazioni locali (LCID) di Microsoft Windows che corrisponde a una lingua supportata dalla ricerca full-text. L'identificatore LCID 1033, ad esempio, corrisponde all'inglese americano, mentre l'identificatore LCID 2057 corrisponde all'inglese britannico. Per ogni lingua full-text supportata, SQL Server fornisce componenti linguistici che supportano l'indicizzazione e l'esecuzione di query su dati full-text archiviati in tale lingua.
Tra i componenti specifici della lingua sono inclusi gli elementi seguenti:
Word breaker e stemmer. Un word breaker consente di trovare i delimitatori di parola in base alle regole lessicali di una determinata lingua (word breaking). A ogni word breaker è associato uno stemmer tramite cui vengono coniugati i verbi per la stessa lingua. Per altre informazioni, vedere Configurare e gestire word breaker e stemmer per la ricerca.
Elenchi di parole non significative. Viene inoltre fornito un elenco di parole non significative di sistema. Per parola non significativa si intende una parola inutile ai fini della ricerca e quindi ignorata dalle query full-text. Ad esempio, nelle impostazioni locali della lingua italiana parole quali "circa", "con", "devo" e "cui" sono considerate non significative. In genere, è necessario configurare uno o più file del thesaurus ed elenchi di parole non significative. Per altre informazioni, vedere Configurare e gestire parole non significative ed elenchi di parole non significative per la ricerca full-text.
File del thesaurus. SQL Server installa anche un file thesaurus per ogni lingua full-text, nonché un file thesaurus globale. I file del thesaurus installati sono praticamente vuoti, ma è possibile modificarli per definire sinonimi per una lingua o uno scenario aziendale specifico. Sviluppando un thesaurus basato sui dati full-text in uso, è possibile ampliare in modo efficace l'ambito delle query full-text su tali dati. Per altre informazioni, vedere Configurare e gestire i file del thesaurus per la ricerca full-text.
Filtri (iFilters). L'indicizzazione di un documento in una colonna con tipo di dati
varbinary(max),imageoxmlrichiede l'applicazione di un filtro per eseguire ulteriori operazioni di elaborazione. Il filtro deve essere specifico del tipo di documento (doc, pdf, xls, xml e così via). Per altre informazioni, vedere Configurazione e gestione di filtri per la ricerca.
I word breaker, gli stemmer e i filtri vengono eseguiti nel processo host del daemon di filtri (fdhost.exe).
Attività correlate
Scrittura di query full-text
Gestione di cataloghi e indici
Gestione dei componenti linguistici
Configurazione e gestione di word breaker e stemmer per la ricerca
Visualizzazione o modifica di word breaker e filtri registrati
Ripristinare i word breaker utilizzati dalla ricerca alla versione precedente
Modifica del word breaker utilizzato per le lingue Inglese (Stati Uniti) e Inglese (Regno Unito)
Personalizzare Comportamento di word breaker con un dizionario personalizzato
Configurare e gestire i file del thesaurus per la ricerca full-text
Gestione della ricerca full-text