Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Important
I cluster Big Data di Microsoft SQL Server 2019 sono stati ritirati. Il supporto per i cluster Big Data di SQL Server 2019 è terminato a partire dal 28 febbraio 2025. Per altre informazioni, vedere il post di blog sull'annuncio e le opzioni per Big Data nella piattaforma Microsoft SQL Server.
I cluster Big Data di SQL Server possono virtualizzare i dati da file CSV in HDFS. Questo processo consente ai dati di rimanere nella posizione originale, ma può essere eseguita una query da un'istanza di SQL Server come qualsiasi altra tabella. Questa funzionalità usa connettori PolyBase e riduce al minimo la necessità di processi ETL. Per altre informazioni sulla virtualizzazione dei dati, vedere Introduzione alla virtualizzazione dei dati con PolyBase
Prerequisites
Selezionare o caricare un file CSV per la virtualizzazione dei dati
In Azure Data Studio (ADS) connettiti all'istanza master di SQL Server del cluster Big Data. Dopo la connessione, espandere gli elementi HDFS in Esplora oggetti per individuare i file CSV da virtualizzare.
Ai fini di questa esercitazione, creare una nuova directory denominata Data.
- Fare clic con il pulsante destro del mouse sulla directory radice HDFS per aprire il menu di scelta rapida.
- Selezionare Nuova directory.
- Assegnare un nome alla nuova directory Data.
Caricare dati di esempio. Per una semplice procedura dettagliata, è possibile usare un file di dati CSV di esempio. Questo articolo usa i dati relativi al ritardo delle compagnie aeree provenienti dal Dipartimento dei trasporti degli Stati Uniti. Scaricare i dati non elaborati ed estrarre i dati nel computer. Denominare il file airline_delay_causes.csv.
Per caricare il file di esempio dopo averlo estratto:
- In Azure Data Studio fare clic con il pulsante destro del mouse sulla nuova directory creata.
- Selezionare Carica file.
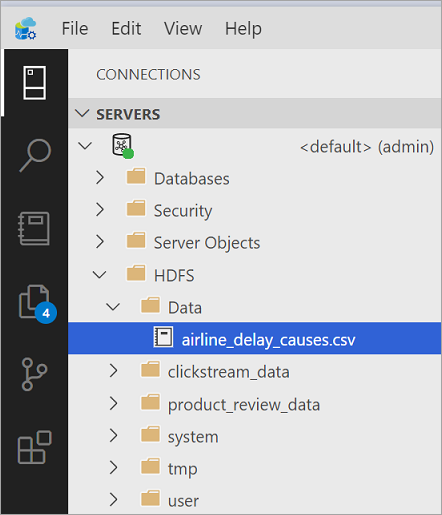
Azure Data Studio carica i file in HDFS nel cluster Big Data.
Creare l'origine dati esterna del pool di archiviazione nel database di destinazione
L'origine dati esterna del pool di archiviazione non viene, per impostazione predefinita, creata in un database nel cluster Big Data. Prima di creare la tabella esterna, creare l'origine dati esterna SqlStoragePool predefinita nel database di destinazione con la query Transact-SQL seguente. Assicurarsi di modificare prima il contesto della query nel database di destinazione.
-- Create the default storage pool source for SQL Big Data Cluster
IF NOT EXISTS(SELECT * FROM sys.external_data_sources WHERE name = 'SqlStoragePool')
CREATE EXTERNAL DATA SOURCE SqlStoragePool
WITH (LOCATION = 'sqlhdfs://controller-svc/default');
Creare la tabella esterna
In ADS fare clic con il pulsante destro del mouse sul file CSV e scegliere Crea tabella esterna da file CSV dal menu di scelta rapida. È anche possibile creare tabelle esterne da file CSV da una directory in HDFS se i file nella directory seguono lo stesso schema. Ciò consentirebbe la virtualizzazione dei dati a livello di directory senza la necessità di elaborare singoli file e ottenere un set di risultati unito sui dati combinati. Azure Data Studio illustra i passaggi per creare la tabella esterna.
Specificare il database, l'origine dati, un nome di tabella, lo schema e il nome per il formato di file esterno della tabella.
Select Next.
Preview Data
Azure Data Studio offre un'anteprima dei dati importati.
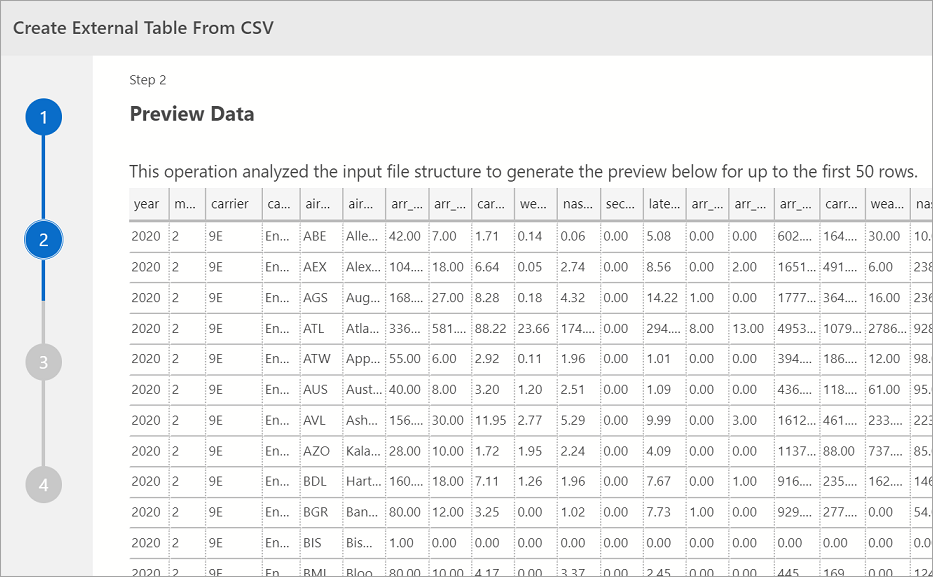
Al termine della visualizzazione dell'anteprima, selezionare Avanti per continuare
Modify Columns
Nella finestra successiva è possibile modificare le colonne della tabella esterna che si intende creare. È possibile modificare il nome della colonna, modificare il tipo di dati e consentire le righe nullable.
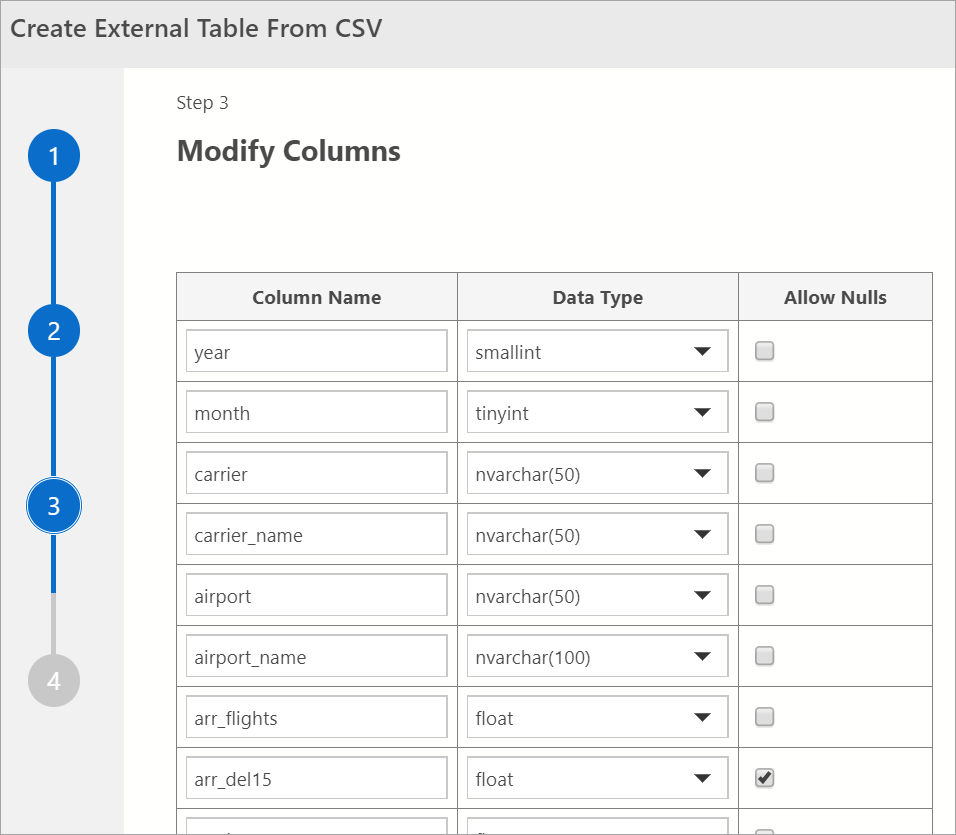
Dopo aver verificato le colonne di destinazione, selezionare Avanti.
Summary
Questo passaggio fornisce un riepilogo delle selezioni. Fornisce informazioni sul nome, il nome del database, il nome della tabella, lo schema della tabella e le informazioni sulla tabella esterna di SQL Server. In questo passaggio è possibile generare uno script o creare una tabella. Genera Script compila uno script in T-SQL per la creazione dell'origine dati esterna. Crea tabella definisce l'origine dati esterna.
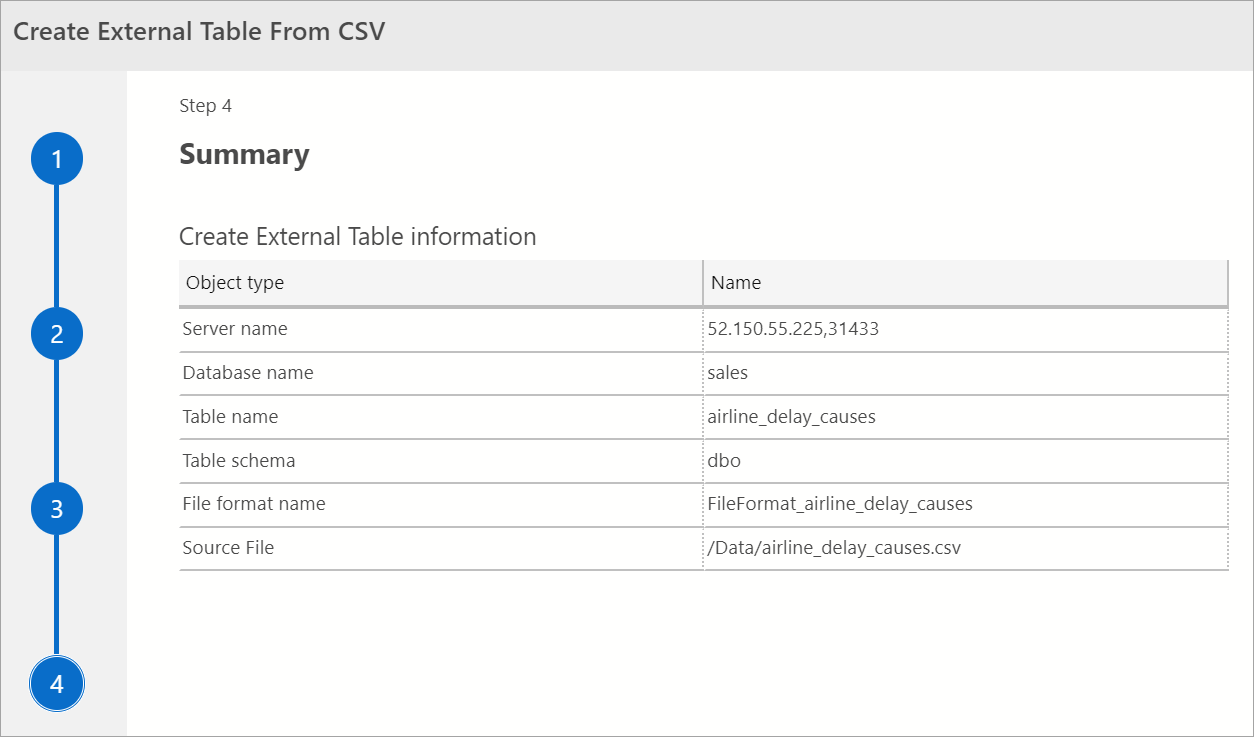
Se si seleziona Crea tabella, SQL Server crea la tabella esterna nel database di destinazione.
Se si seleziona Genera script, Azure Data Studio crea la query T-SQL per la creazione della tabella esterna.
Dopo aver creato la tabella, è ora possibile eseguire query direttamente usando T-SQL dall'istanza di SQL Server.
Next steps
Per altre informazioni sul cluster Big Data di SQL Server e sugli scenari correlati, vedere Introduzione ai cluster Big Data di SQL Server.