Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
I cluster Big Data di Microsoft SQL Server 2019 sono stati ritirati. Il supporto per i cluster Big Data di SQL Server 2019 è terminato a partire dal 28 febbraio 2025. Per altre informazioni, vedere il post di blog sull'annuncio e le opzioni per Big Data nella piattaforma Microsoft SQL Server.
Questo articolo fornisce un esempio di come usare kubeadm per configurare Kubernetes in più computer per le distribuzioni di cluster Big Data di SQL Server. In questo esempio, più computer Ubuntu 16.04 o 18.04 LTS (fisici o virtuali) sono la destinazione. Se si esegue la distribuzione in una piattaforma Linux diversa, è necessario modificare alcuni dei comandi in modo che corrispondano al sistema.
Tip
Per gli script di esempio che configurano Kubernetes, vedere Creare un cluster Kubernetes usando Kubeadm in Ubuntu 20.04 LTS.
Per uno script di esempio che automatizza una distribuzione di una distribuzione kubeadm a nodo singolo in una macchina virtuale e quindi distribuisce una configurazione predefinita del cluster Big Data, vedere Distribuire un cluster kubeadm a nodo singolo.
Prerequisites
- Almeno tre macchine fisiche Linux o macchine virtuali
- Configurazione consigliata per computer:
- 8 CPUs
- 64 GB di memoria
- 100 GB di spazio di archiviazione
Important
Prima di avviare la distribuzione del cluster Big Data, assicurarsi che gli orologi siano sincronizzati in tutti i nodi Kubernetes di destinazione della distribuzione. Il cluster Big Data ha proprietà di integrità predefinite per vari servizi che fanno distinzione tra l'ora e l'asimmetria dell'orologio può comportare uno stato non corretto.
Preparare le macchine
In ogni computer sono necessari diversi prerequisiti. In un terminale bash eseguire i comandi seguenti in ogni computer:
Aggiungere il computer corrente al
/etc/hostsfile:echo $(hostname -i) $(hostname) | sudo tee -a /etc/hostsDisabilitare lo scambio in tutti i dispositivi.
sudo sed -i "/ swap / s/^/#/" /etc/fstab sudo swapoff -aImportare le chiavi e registrare il repository per Kubernetes.
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo sudo tee /etc/apt/trusted.gpg.d/apt-key.asc echo 'deb http://apt.kubernetes.io/ kubernetes-xenial main' | sudo tee -a /etc/apt/sources.list.d/kubernetes.listConfigurare i prerequisiti di Docker e Kubernetes nel computer.
KUBE_DPKG_VERSION=1.15.0-00 #or your other target K8s version, which should be at least 1.13. sudo apt-get update && \ sudo apt-get install -y ebtables ethtool && \ sudo apt-get install -y docker.io && \ sudo apt-get install -y apt-transport-https && \ sudo apt-get install -y kubelet=$KUBE_DPKG_VERSION kubeadm=$KUBE_DPKG_VERSION kubectl=$KUBE_DPKG_VERSION && \ curl https://raw.githubusercontent.com/kubernetes/helm/master/scripts/get | bashImposta
net.bridge.bridge-nf-call-iptables=1. Su Ubuntu 18.04, i comandi seguenti abilitano primabr_netfilter.. /etc/os-release if [ "$VERSION_CODENAME" == "bionic" ]; then sudo modprobe br_netfilter; fi sudo sysctl net.bridge.bridge-nf-call-iptables=1
Configurare il master Kubernetes
Dopo aver eseguito i comandi precedenti su ogni macchina, scegli una delle macchine come master Kubernetes. Eseguire quindi i comandi seguenti nel computer.
Creare prima di tutto un file rbac.yaml nella directory corrente con il comando seguente.
cat <<EOF > rbac.yaml apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: default-rbac subjects: - kind: ServiceAccount name: default namespace: default roleRef: kind: ClusterRole name: cluster-admin apiGroup: rbac.authorization.k8s.io EOFInizializza il Kubernetes master su questa macchina. Lo script di esempio seguente specifica la versione
1.15.0di Kubernetes. La versione usata dipende dal cluster Kubernetes.KUBE_VERSION=1.15.0 sudo kubeadm init --pod-network-cidr=10.244.0.0/16 --kubernetes-version=$KUBE_VERSIONDovresti vedere il risultato che il master di Kubernetes è stato inizializzato con successo.
Si noti il
kubeadm joincomando che è necessario usare negli altri server per aggiungere il cluster Kubernetes. Copiarlo per usarlo in un secondo momento.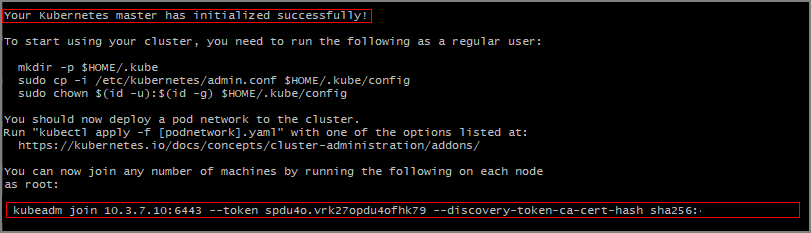
Configurare un file di configurazione kubernetes nella home directory.
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configConfigurare il cluster e il dashboard Kubernetes.
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml helm init kubectl apply -f rbac.yaml kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v1.10.1/src/deploy/recommended/kubernetes-dashboard.yaml kubectl create clusterrolebinding kubernetes-dashboard --clusterrole=cluster-admin --serviceaccount=kube-system:kubernetes-dashboard
Configurare gli agenti Kubernetes
Gli altri computer fungeranno da agenti Kubernetes nel cluster.
In ognuno degli altri computer eseguire il kubeadm join comando copiato nella sezione precedente.

Visualizzare lo stato del cluster
Per verificare la connessione al cluster, usare il comando kubectl get per restituire un elenco di nodi del cluster.
kubectl get nodes
Next steps
I passaggi descritti in questo articolo hanno configurato un cluster Kubernetes in più computer Ubuntu. Il passaggio successivo consiste nel distribuire il cluster Big Data di SQL Server 2019. Per istruzioni, vedere l'articolo seguente: