Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Questo articolo presenta la nuova API Voce e illustra come implementarla in un'app Xamarin.iOS per supportare il riconoscimento vocale continuo e trascrivere il riconoscimento vocale (da flussi audio live o registrati) in testo.
Novità di iOS 10, Apple ha rilasciato l'API Riconoscimento vocale che consente a un'app iOS di supportare il riconoscimento vocale continuo e trascrivere il riconoscimento vocale (da flussi audio live o registrati) in testo.
In base ad Apple, l'API Riconoscimento vocale offre le funzionalità e i vantaggi seguenti:
- Alta precisione
- Stato dell'arte
- Facile da usare
- Veloce
- Supporta più lingue
- Rispetta la privacy dell'utente
Funzionamento del riconoscimento vocale
Il riconoscimento vocale viene implementato in un'app iOS acquisendo audio live o preregistrato (in una delle lingue parlate supportate dall'API) e passandolo a un riconoscimento vocale che restituisce una trascrizione in testo normale delle parole pronunciate.

Dettatura della tastiera
Quando la maggior parte degli utenti pensa al riconoscimento vocale in un dispositivo iOS, pensa all'assistente vocale Siri predefinito, che è stato rilasciato insieme alla dettatura della tastiera in iOS 5 con iPhone 4S.
La dettatura della tastiera è supportata da qualsiasi elemento dell'interfaccia che supporta TextKit (ad esempio UITextField o UITextArea) e viene attivata dall'utente facendo clic sul pulsante di dettatura (direttamente a sinistra della barra spaziatrice) nella tastiera virtuale iOS.
Apple ha rilasciato le seguenti statistiche di dettatura della tastiera (raccolte dal 2011):
- La dettatura della tastiera è stata ampiamente usata da quando è stata rilasciata in iOS 5.
- Circa 65.000 app lo usano al giorno.
- Circa un terzo di tutte le dettatura iOS viene eseguito in un'app di terze parti.
La dettatura della tastiera è estremamente facile da usare perché non richiede alcun impegno per la parte dello sviluppatore, ad eccezione dell'uso di un elemento di interfaccia TextKit nella progettazione dell'interfaccia utente dell'app. La dettatura della tastiera ha anche il vantaggio di non richiedere richieste di privilegi speciali dall'app prima che possa essere usata.
Le app che usano le nuove API riconoscimento vocale richiederanno autorizzazioni speciali da concedere all'utente, poiché il riconoscimento vocale richiede la trasmissione e l'archiviazione temporanea dei dati nei server Apple. Per informazioni dettagliate, vedere la documentazione relativa ai miglioramenti alla sicurezza e alla privacy.
Anche se la dettatura della tastiera è facile da implementare, presenta diverse limitazioni e svantaggi:
- Richiede l'uso di un campo di input di testo e della visualizzazione di una tastiera.
- Funziona solo con l'input audio live e l'app non ha alcun controllo sul processo di registrazione audio.
- Non fornisce alcun controllo sulla lingua usata per interpretare il parlato dell'utente.
- Non c'è modo per l'app di sapere se il pulsante Dettatura è anche disponibile per l'utente.
- L'app non può personalizzare il processo di registrazione audio.
- Fornisce un set molto superficiale di risultati che non dispone di informazioni quali tempi e confidenza.
API Riconoscimento vocale
Novità di iOS 10, Apple ha rilasciato l'API Riconoscimento vocale che offre un modo più potente per un'app iOS di implementare il riconoscimento vocale. Questa API è la stessa usata da Apple per alimentare sia la dettatura siri che la tastiera ed è in grado di fornire una trascrizione rapida con lo stato dell'accuratezza dell'arte.
I risultati forniti dall'API Riconoscimento vocale sono personalizzati in modo trasparente per i singoli utenti, senza che l'app deve raccogliere o accedere a dati utente privati.
L'API Riconoscimento vocale fornisce risultati all'app chiamante quasi in tempo reale, perché l'utente sta parlando e fornisce altre informazioni sui risultati della traduzione rispetto al solo testo. tra cui:
- Più interpretazioni di ciò che l'utente ha detto.
- Livelli di confidenza per le singole traduzioni.
- Informazioni sulla tempistica.
Come indicato in precedenza, l'audio per la traduzione può essere fornito da un feed live o da origini preregistrate e in una delle oltre 50 lingue e dialetti supportati da iOS 10.
L'API Riconoscimento vocale può essere usata in qualsiasi dispositivo iOS che esegue iOS 10 e nella maggior parte dei casi richiede una connessione Internet dinamica perché la maggior parte delle traduzioni avviene nei server Apple. Detto questo, alcuni dispositivi iOS più recenti supportano la traduzione sempre attiva e on-device di lingue specifiche.
Apple ha incluso un'API di disponibilità per determinare se una determinata lingua è disponibile per la traduzione al momento corrente. L'app deve usare questa API invece di testare direttamente la connettività Internet.
Come indicato in precedenza nella sezione Dettatura della tastiera, il riconoscimento vocale richiede la trasmissione e l'archiviazione temporanea dei dati nei server Apple su Internet e, di conseguenza, l'app deve richiedere l'autorizzazione dell'utente per eseguire il riconoscimento includendo la NSSpeechRecognitionUsageDescription chiave nel file Info.plist e chiamando il SFSpeechRecognizer.RequestAuthorization metodo .
In base all'origine dell'audio usato per il riconoscimento vocale, potrebbero essere necessarie altre modifiche al file dell'app Info.plist . Per informazioni dettagliate, vedere la documentazione relativa ai miglioramenti alla sicurezza e alla privacy.
Adozione del riconoscimento vocale in un'app
Esistono quattro passaggi principali che lo sviluppatore deve eseguire per adottare il riconoscimento vocale in un'app iOS:
- Specificare una descrizione dell'utilizzo nel file dell'app
Info.plistusando laNSSpeechRecognitionUsageDescriptionchiave . Ad esempio, un'app per la fotocamera potrebbe includere la descrizione seguente: "Ciò consente di scattare una foto solo dicendo la parola "cheese". - Richiedere l'autorizzazione chiamando il
SFSpeechRecognizer.RequestAuthorizationmetodo per presentare una spiegazione (fornita nellaNSSpeechRecognitionUsageDescriptionchiave precedente) del motivo per cui l'app vuole l'accesso al riconoscimento vocale all'utente in una finestra di dialogo e consentire loro di accettare o rifiutare. - Creare una richiesta di riconoscimento vocale:
- Per l'audio preregistrato su disco, usare la
SFSpeechURLRecognitionRequestclasse . - Per l'audio live (o audio dalla memoria), usare la
SFSPeechAudioBufferRecognitionRequestclasse .
- Per l'audio preregistrato su disco, usare la
- Passare la richiesta di riconoscimento vocale a un riconoscimento vocale (
SFSpeechRecognizer) per iniziare il riconoscimento. L'app può facoltativamente mantenere l'oggetto restituitoSFSpeechRecognitionTaskper monitorare e tenere traccia dei risultati del riconoscimento.
Questi passaggi verranno illustrati in dettaglio di seguito.
Specifica di una descrizione dell'utilizzo
Per specificare la chiave richiesta NSSpeechRecognitionUsageDescription nel Info.plist file, eseguire le operazioni seguenti:
Fare doppio clic sul
Info.plistfile per aprirlo per la modifica.Passare alla visualizzazione Origine:
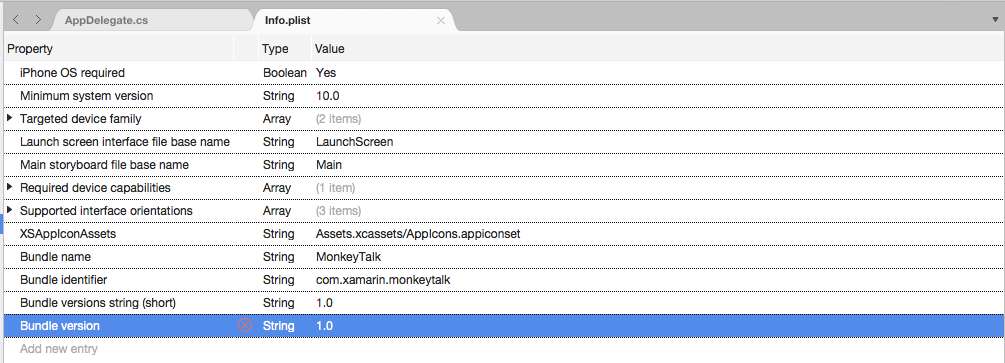
Fare clic su Add New Entry (Aggiungi nuova voce), immettere
NSSpeechRecognitionUsageDescriptionper Property (ProprietàString) per Type (Tipo) e Una Descrizione utilizzo come valore. Ad esempio: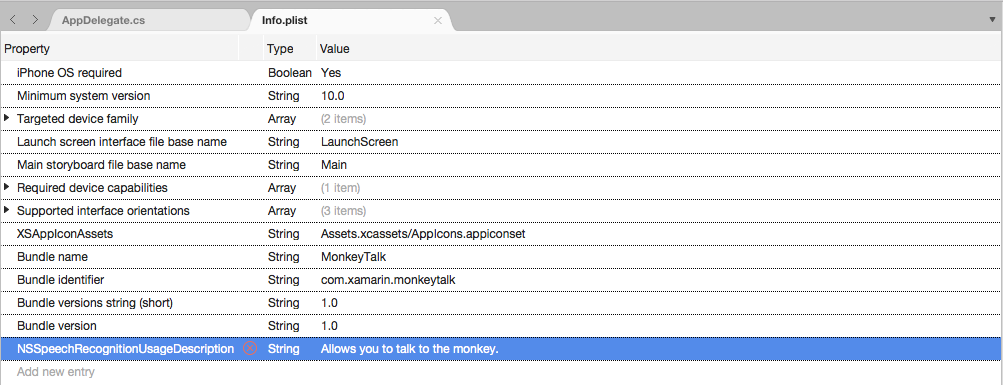
Se l'app gestirà la trascrizione audio live, richiederà anche una descrizione dell'utilizzo del microfono. Fare clic su Add New Entry (Aggiungi nuova voce), immettere
NSMicrophoneUsageDescriptionper Property (ProprietàString) per Type (Tipo) e Una Descrizione utilizzo come valore. Ad esempio: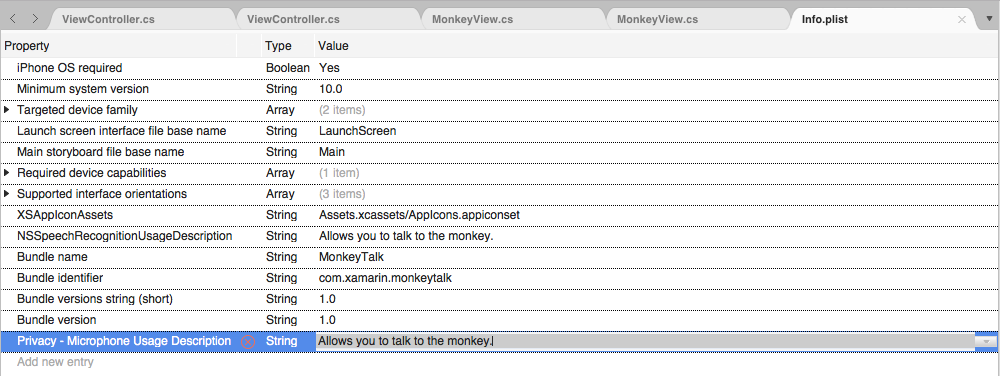
Salvare le modifiche apportate al file.





Importante
Se non si specifica una delle chiavi precedenti Info.plist (NSSpeechRecognitionUsageDescription o NSMicrophoneUsageDescription) l'app non riesce senza alcun avviso quando si tenta di accedere al riconoscimento vocale o al microfono per l'audio live.
Richiesta di autorizzazione
Per richiedere l'autorizzazione utente necessaria che consente all'app di accedere al riconoscimento vocale, modificare la classe principale View Controller e aggiungere il codice seguente:
using System;
using UIKit;
using Speech;
namespace MonkeyTalk
{
public partial class ViewController : UIViewController
{
protected ViewController (IntPtr handle) : base (handle)
{
// Note: this .ctor should not contain any initialization logic.
}
public override void ViewDidLoad ()
{
base.ViewDidLoad ();
// Request user authorization
SFSpeechRecognizer.RequestAuthorization ((SFSpeechRecognizerAuthorizationStatus status) => {
// Take action based on status
switch (status) {
case SFSpeechRecognizerAuthorizationStatus.Authorized:
// User has approved speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.Denied:
// User has declined speech recognition
...
break;
case SFSpeechRecognizerAuthorizationStatus.NotDetermined:
// Waiting on approval
...
break;
case SFSpeechRecognizerAuthorizationStatus.Restricted:
// The device is not permitted
...
break;
}
});
}
}
}
Il RequestAuthorization metodo della SFSpeechRecognizer classe richiederà all'utente l'autorizzazione per accedere al riconoscimento vocale usando il motivo per cui lo sviluppatore ha fornito nella NSSpeechRecognitionUsageDescription chiave del Info.plist file.
Un SFSpeechRecognizerAuthorizationStatus risultato viene restituito alla RequestAuthorization routine di callback del metodo che può essere usata per intervenire in base all'autorizzazione dell'utente.
Importante
Apple suggerisce di attendere fino a quando l'utente non ha avviato un'azione nell'app che richiede il riconoscimento vocale prima di richiedere questa autorizzazione.
Riconoscimento vocale preregistrato
Se l'app vuole riconoscere il riconoscimento vocale da un file WAV o MP3 preregistrato, può usare il codice seguente:
using System;
using UIKit;
using Speech;
using Foundation;
...
public void RecognizeFile (NSUrl url)
{
// Access new recognizer
var recognizer = new SFSpeechRecognizer ();
// Is the default language supported?
if (recognizer == null) {
// No, return to caller
return;
}
// Is recognition available?
if (!recognizer.Available) {
// No, return to caller
return;
}
// Create recognition task and start recognition
var request = new SFSpeechUrlRecognitionRequest (url);
recognizer.GetRecognitionTask (request, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said, \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
Esaminando prima di tutto questo codice, tenta di creare un riconoscimento vocale (SFSpeechRecognizer). Se la lingua predefinita non è supportata per il riconoscimento vocale, null viene restituita e le funzioni vengono chiusa.
Se riconoscimento vocale è disponibile per la lingua predefinita, l'app verifica se è attualmente disponibile per il riconoscimento usando la Available proprietà . Ad esempio, il riconoscimento potrebbe non essere disponibile se il dispositivo non dispone di una connessione Internet attiva.
Un SFSpeechUrlRecognitionRequest oggetto viene creato dal NSUrl percorso del file preregistrato nel dispositivo iOS e viene passato al Riconoscimento vocale per elaborare con una routine di callback.
Quando viene chiamato il callback, se NSError non null è presente un errore che deve essere gestito. Poiché il riconoscimento vocale viene eseguito in modo incrementale, la routine di callback può essere chiamata più volte in modo che la SFSpeechRecognitionResult.Final proprietà venga testata per verificare se la traduzione è completa e la versione migliore della traduzione viene scritta (BestTranscription).
Riconoscimento vocale in tempo reale
Se l'app vuole riconoscere il riconoscimento vocale live, il processo è molto simile al riconoscimento vocale preregistrato. Ad esempio:
using System;
using UIKit;
using Speech;
using Foundation;
using AVFoundation;
...
#region Private Variables
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
#endregion
...
public void StartRecording ()
{
// Setup audio session
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
// Start recording
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
// Start recognition
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
// Was there an error?
if (err != null) {
// Handle error
...
} else {
// Is this the final translation?
if (result.Final) {
Console.WriteLine ("You said \"{0}\".", result.BestTranscription.FormattedString);
}
}
});
}
public void StopRecording ()
{
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
}
public void CancelRecording ()
{
AudioEngine.Stop ();
RecognitionTask.Cancel ();
}
Esaminando in dettaglio questo codice, vengono create diverse variabili private per gestire il processo di riconoscimento:
private AVAudioEngine AudioEngine = new AVAudioEngine ();
private SFSpeechRecognizer SpeechRecognizer = new SFSpeechRecognizer ();
private SFSpeechAudioBufferRecognitionRequest LiveSpeechRequest = new SFSpeechAudioBufferRecognitionRequest ();
private SFSpeechRecognitionTask RecognitionTask;
Usa AV Foundation per registrare l'audio che verrà passato a un SFSpeechAudioBufferRecognitionRequest per gestire la richiesta di riconoscimento:
var node = AudioEngine.InputNode;
var recordingFormat = node.GetBusOutputFormat (0);
node.InstallTapOnBus (0, 1024, recordingFormat, (AVAudioPcmBuffer buffer, AVAudioTime when) => {
// Append buffer to recognition request
LiveSpeechRequest.Append (buffer);
});
L'app tenta di avviare la registrazione ed eventuali errori vengono gestiti se la registrazione non può essere avviata:
AudioEngine.Prepare ();
NSError error;
AudioEngine.StartAndReturnError (out error);
// Did recording start?
if (error != null) {
// Handle error and return
...
return;
}
L'attività di riconoscimento viene avviata e un handle viene mantenuto nell'attività di riconoscimento (SFSpeechRecognitionTask):
RecognitionTask = SpeechRecognizer.GetRecognitionTask (LiveSpeechRequest, (SFSpeechRecognitionResult result, NSError err) => {
...
});
Il callback viene usato in modo simile a quello usato in precedenza per il riconoscimento vocale preregistrato.
Se la registrazione viene arrestata dall'utente, vengono informati sia il motore audio che la richiesta di riconoscimento vocale:
AudioEngine.Stop ();
LiveSpeechRequest.EndAudio ();
Se l'utente annulla il riconoscimento, l'attività Motore audio e riconoscimento viene informata:
AudioEngine.Stop ();
RecognitionTask.Cancel ();
È importante chiamare RecognitionTask.Cancel se l'utente annulla la traduzione per liberare memoria e processore del dispositivo.
Importante
Se non si specificano i NSSpeechRecognitionUsageDescription tasti o NSMicrophoneUsageDescription Info.plist , l'app non riesce senza alcun avviso quando si tenta di accedere al riconoscimento vocale o al microfono per l'audio live (var node = AudioEngine.InputNode;). Per altre informazioni, vedere la sezione Descrizione utilizzo riportata sopra.
Limiti di riconoscimento vocale
Apple impone le limitazioni seguenti quando si usa il riconoscimento vocale in un'app iOS:
- Il riconoscimento vocale è gratuito per tutte le app, ma l'utilizzo non è illimitato:
- I singoli dispositivi iOS hanno un numero limitato di riconoscimenti che possono essere eseguiti al giorno.
- Le app verranno limitate a livello globale su base giornaliera.
- L'app deve essere preparata per gestire gli errori di connessione di rete per il riconoscimento vocale e i limiti di frequenza di utilizzo.
- Il riconoscimento vocale può avere un costo elevato sia per lo scaricamento della batteria che per il traffico di rete elevato sul dispositivo iOS dell'utente, a causa di questo, Apple impone un rigido limite di durata audio di circa un minuto di riconoscimento vocale massimo.
Se un'app raggiunge regolarmente i limiti di limitazione della velocità, Apple chiede che lo sviluppatore li contatti.
Considerazioni sulla privacy e sull'usabilità
Apple ha il suggerimento seguente per essere trasparente e rispettare la privacy dell'utente quando si include il riconoscimento vocale in un'app iOS:
- Quando si registra il parlato dell'utente, assicurarsi di indicare chiaramente che la registrazione avviene nell'interfaccia utente dell'app. Ad esempio, l'app potrebbe riprodurre un suono di "registrazione" e visualizzare un indicatore di registrazione.
- Non usare il riconoscimento vocale per informazioni riservate sugli utenti, ad esempio password, dati sull'integrità o informazioni finanziarie.
- Mostra i risultati del riconoscimento prima di agire su di essi. Questo non solo fornisce commenti e suggerimenti sulle operazioni eseguite dall'app, ma consente all'utente di gestire gli errori di riconoscimento man mano che vengono effettuati.
Riepilogo
Questo articolo ha presentato la nuova API Voce e ha illustrato come implementarla in un'app Xamarin.iOS per supportare il riconoscimento vocale continuo e trascrivere il riconoscimento vocale (da flussi audio live o registrati) in testo.