Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Nota
Questo eBook è stato pubblicato nella primavera del 2017 e non è stato aggiornato da allora. C'è molto nel libro che rimane prezioso, ma alcuni dei materiali sono obsoleti.
Lo sviluppo di applicazioni client-server ha portato alla creazione di applicazioni a livelli che usano tecnologie specifiche in ogni livello. Tali applicazioni vengono spesso definite applicazioni monolitiche e vengono incluse nell'hardware pre-ridimensionato per i carichi di picco. I principali svantaggi di questo approccio di sviluppo sono lo stretto accoppiamento tra i componenti all'interno di ciascun livello, l'impossibilità di scalare facilmente i singoli componenti e il costo dei test. Un semplice aggiornamento può avere effetti imprevisti sul resto del livello e quindi una modifica a un componente dell'applicazione richiede che l'intero livello venga ridiscato e ridistribuibile.
In particolare per quanto riguarda l'età del cloud, è che i singoli componenti non possono essere facilmente ridimensionati. Un'applicazione monolitica contiene funzionalità specifiche del dominio ed è in genere divisa per livelli funzionali, ad esempio front-end, logica di business e archiviazione dei dati. Un'applicazione monolitica viene ridimensionata clonando l'intera applicazione in più computer, come illustrato nella figura 8-1.
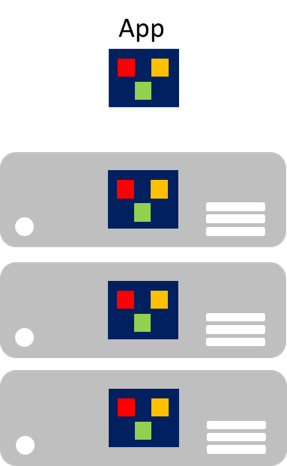
Figura 8-1: Approccio alla scalabilità di applicazioni monolitiche
Microservizi
I microservizi offrono un approccio diverso allo sviluppo e alla distribuzione di applicazioni, un approccio adatto ai requisiti di agilità, scalabilità e affidabilità delle applicazioni cloud moderne. Un'applicazione di microservizi viene scomposta in componenti indipendenti che interagiscono per offrire la funzionalità complessiva dell'applicazione. Il termine microservizio sottolinea che le applicazioni devono essere costituite da servizi sufficientemente piccoli da riflettere preoccupazioni indipendenti, in modo che ogni microservizio implementi una singola funzione. Inoltre, ogni microservizio dispone di contratti ben definiti in modo che altri microservizi possano comunicare e condividere dati con essi. Esempi tipici di microservizi includono i carrello acquisti, l'elaborazione dell'inventario, i sottosistemi di acquisto e l'elaborazione dei pagamenti.
I microservizi possono aumentare il numero di istanze in modo indipendente, rispetto alle applicazioni monolitiche giganti che si adattano insieme. Ciò significa che un'area funzionale specifica, che richiede una maggiore potenza di elaborazione o larghezza di banda di rete per supportare la domanda, può essere ridimensionata anziché aumentare inutilmente altre aree dell'applicazione. La figura 8-2 illustra questo approccio, in cui i microservizi vengono distribuiti e ridimensionati in modo indipendente, creando istanze di servizi tra computer.
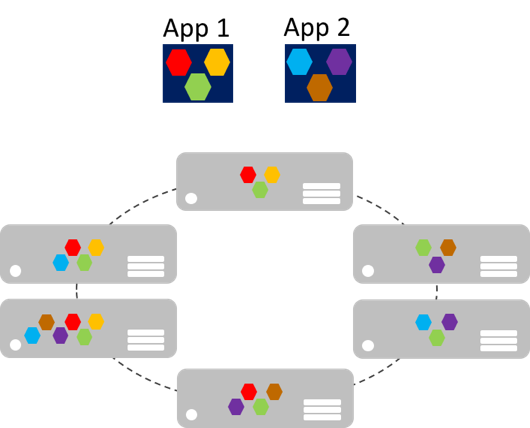
Figura 8-2: Approccio di ridimensionamento delle applicazioni di microservizi
La scalabilità orizzontale dei microservizi può essere quasi istantanea, consentendo a un'applicazione di adattarsi ai carichi modificati. Ad esempio, un singolo microservizio nella funzionalità web di un'applicazione potrebbe essere l'unico microservizio nell'applicazione che deve aumentare il numero di istanze per gestire traffico in ingresso aggiuntivo.
Il modello classico per la scalabilità delle applicazioni prevede un livello con carico bilanciato e senza stato con un archivio dati esterno condiviso per archiviare dati persistenti. I microservizi con stato gestiscono i propri dati persistenti, in genere archiviandoli localmente nei server in cui sono posizionati, per evitare il sovraccarico dell'accesso alla rete e della complessità delle operazioni tra servizi. Ciò consente l'elaborazione più rapida possibile dei dati e può eliminare la necessità di sistemi di memorizzazione nella cache. Inoltre, i microservizi con stato scalabile in genere partizionano i dati tra le istanze, per gestire le dimensioni dei dati e trasferire la velocità effettiva oltre la quale un singolo server può supportare.
I microservizi supportano anche aggiornamenti indipendenti. Questo accoppiamento libero tra microservizi offre un'evoluzione rapida e affidabile dell'applicazione. La natura indipendente e distribuita supporta gli aggiornamenti in sequenza, in cui solo un subset di istanze di un singolo microservizio verrà aggiornato in qualsiasi momento. Pertanto, se viene rilevato un problema, è possibile eseguire il rollback di un aggiornamento buggy prima che tutte le istanze vengano aggiornate con il codice o la configurazione difettosi. Analogamente, i microservizi usano in genere il controllo delle versioni dello schema, in modo che i client visualizzino una versione coerente quando vengono applicati gli aggiornamenti, indipendentemente da quale istanza del microservizio viene comunicata.
Pertanto, le applicazioni di microservizi hanno molti vantaggi rispetto alle applicazioni monolitiche:
- Ogni microservizio è relativamente piccolo, facile da gestire ed evolvere.
- Ogni microservizio può essere sviluppato e distribuito indipendentemente da altri servizi.
- Ogni microservizio può essere ridimensionato in modo indipendente. Ad esempio, potrebbe essere necessario aumentare il numero di istanze di un servizio catalogo o un servizio carrello acquisti rispetto a un servizio di ordinamento. Pertanto, l'infrastruttura risultante utilizzerà in modo più efficiente le risorse quando si aumenta il numero di istanze.
- Ogni microservizio isola eventuali problemi. Ad esempio, se si verifica un problema in un servizio, influisce solo su tale servizio. Gli altri servizi possono continuare a gestire le richieste.
- Ogni microservizio può usare le tecnologie più recenti. Poiché i microservizi sono autonomi ed eseguiti side-by-side, è possibile usare le tecnologie e i framework più recenti, anziché essere costretti a usare un framework precedente che potrebbe essere usato da un'applicazione monolitica.
Tuttavia, una soluzione basata su microservizi presenta anche potenziali svantaggi:
- La scelta di come partizionare un'applicazione in microservizi può risultare complessa, poiché ogni microservizio deve essere completamente autonomo, end-to-end, inclusa la responsabilità per le origini dati.
- Gli sviluppatori devono implementare la comunicazione tra servizi, che aggiunge complessità e latenza all'applicazione.
- Le transazioni atomiche tra più microservizi in genere non sono possibili. Pertanto, i requisiti aziendali devono adottare la coerenza finale tra microservizi.
- Nell'ambiente di produzione c'è una complessità operativa nella distribuzione e nella gestione di un sistema compromesso di molti servizi indipendenti.
- La comunicazione diretta da client a microservizio può rendere difficile effettuare il refactoring dei contratti di microservizi. Ad esempio, nel corso del tempo, il modo in cui il sistema viene partizionato nei servizi potrebbe dover cambiare. Un singolo servizio può essere suddiviso in due o più servizi, e due servizi potrebbero essere uniti. Quando i client comunicano direttamente con i microservizi, questo lavoro di refactoring può interrompere la compatibilità con le app client.
Containerizzazione
La containerizzazione è un approccio allo sviluppo software in cui un'applicazione e il relativo set di dipendenze con controllo delle versioni, oltre alla configurazione dell'ambiente astratta come file manifesto della distribuzione, vengono inseriti insieme come immagine del contenitore, testati come unità e distribuiti in un sistema operativo host.
Un contenitore è un ambiente operativo isolato, controllato dalle risorse e portabile, in cui un'applicazione può essere eseguita senza toccare le risorse di altri contenitori o l'host. Pertanto, un contenitore sembra e agisce come un computer fisico appena installato o una macchina virtuale.
Esistono molte analogie tra contenitori e macchine virtuali, come illustrato nella figura 8-3.
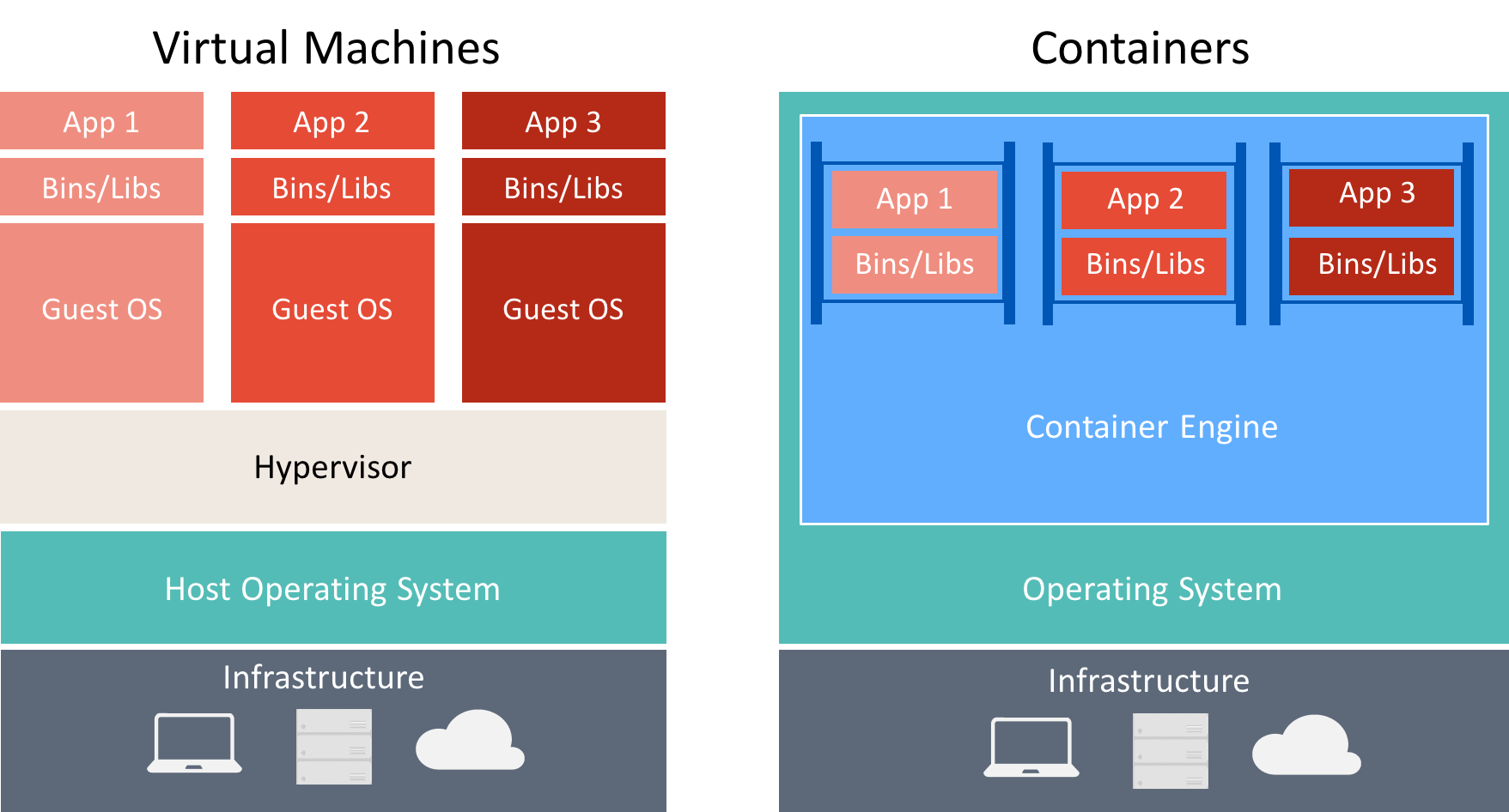
Figura 8-3: Confronto tra macchine virtuali e contenitori
Un contenitore esegue un sistema operativo, ha un file system e può essere accessibile tramite una rete come se fosse una macchina fisica o virtuale. Tuttavia, la tecnologia e i concetti usati dai contenitori sono molto diversi dalle macchine virtuali. Le macchine virtuali includono le applicazioni, le dipendenze necessarie e un sistema operativo guest completo. I contenitori includono l'applicazione e le relative dipendenze, ma condividono il sistema operativo con altri contenitori, in esecuzione come processi isolati nel sistema operativo host (a parte i contenitori Hyper-V eseguiti all'interno di una macchina virtuale speciale per ogni contenitore). Di conseguenza, i contenitori condividono le risorse e in genere richiedono meno risorse rispetto alle macchine virtuali.
Il vantaggio di un approccio di sviluppo e distribuzione orientato ai contenitori è che elimina la maggior parte dei problemi che derivano da configurazioni di ambiente incoerenti e i problemi che si presentano con essi. Inoltre, i contenitori consentono di aumentare rapidamente le funzionalità di scalabilità delle applicazioni creando istanze di nuovi contenitori secondo necessità.
I concetti chiave durante la creazione e l'uso dei contenitori sono i seguenti:
- Host contenitore: la macchina virtuale o fisica configurata per ospitare contenitori. L'host contenitore eseguirà uno o più contenitori.
- Immagine contenitore: un'immagine è costituita da un'unione di file system a più livelli sovrapposti tra loro e è la base di un contenitore. Un'immagine non ha stato e non cambia mai quando viene distribuita in ambienti diversi.
- Contenitore: un contenitore è un'istanza di runtime di un'immagine.
- Immagine del sistema operativo del contenitore: i contenitori vengono distribuiti dalle immagini. L'immagine del sistema operativo del contenitore è il primo livello in potenzialmente molti livelli di immagine che costituiscono un contenitore. Un sistema operativo contenitore non è modificabile e non può essere modificato.
- Repository contenitori: ogni volta che viene creata un'immagine del contenitore, l'immagine e le relative dipendenze vengono archiviate in un repository locale. Queste immagini possono essere riutilizzate più volte nell'host contenitore. Le immagini del contenitore possono anche essere archiviate in un registro pubblico o privato, ad esempio l'hub Docker, in modo che possano essere usate in host contenitore diversi.
Le aziende adottano sempre più contenitori quando implementano applicazioni basate su microservizi e Docker è diventata l'implementazione standard del contenitore adottata dalla maggior parte delle piattaforme software e dai fornitori di servizi cloud.
L'applicazione di riferimento eShopOnContainers usa Docker per ospitare quattro microservizi back-end in contenitori, come illustrato nella figura 8-4.
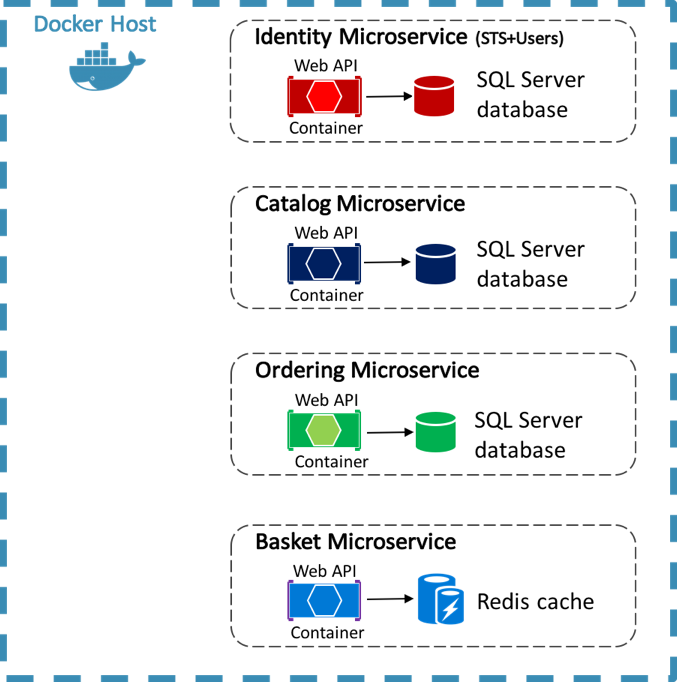
Figura 8-4: Microservizi back-end dell'applicazione di riferimento eShopOnContainers
L'architettura dei servizi back-end nell'applicazione di riferimento viene scomposta in più sub-sistemi autonomi sotto forma di collaborazione di microservizi e contenitori. Ogni microservizio offre una singola area di funzionalità: un servizio di gestione delle identità, un servizio di catalogo, un servizio di ordinamento e un servizio carrello.
Ogni microservizio ha un proprio database, consentendone la separazione completa dagli altri microservizi. Se necessario, la coerenza tra database di diversi microservizi viene ottenuta usando gli eventi a livello di applicazione. Per altre informazioni, vedere Comunicazione tra microservizi.
Per altre informazioni sull'applicazione di riferimento, vedere Microservizi .NET: Architettura per applicazioni .NET in contenitori.
Comunicazione tra client e microservizi
L'app per dispositivi mobili eShopOnContainers comunica con i microservizi back-end in contenitori usando la comunicazione diretta da client a microservizio , illustrata nella figura 8-5.
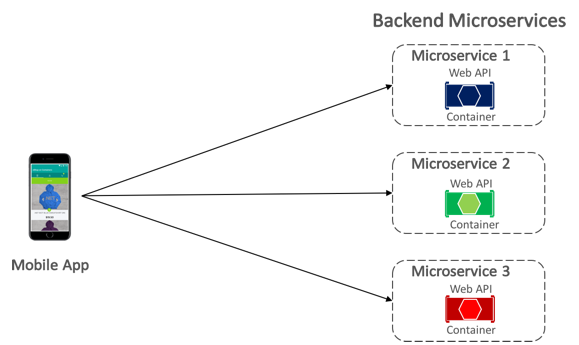
Figura 8-5: Comunicazione da client a microservizio diretto
Con la comunicazione diretta da client a microservizio, l'app per dispositivi mobili invia richieste a ogni microservizio direttamente tramite l'endpoint pubblico, con una porta TCP diversa per ogni microservizio. Nell'ambiente di produzione, l'endpoint viene in genere mappato al servizio di bilanciamento del carico del microservizio, che distribuisce le richieste tra le istanze disponibili.
Suggerimento
Prendere in considerazione l'uso della comunicazione del gateway API. Le comunicazioni da client a microservizio diretto possono avere svantaggi durante la compilazione di un'applicazione basata su microservizi di grandi dimensioni e complessa, ma è più che adeguata per un'applicazione di piccole dimensioni. Quando si progetta un'applicazione basata su microservizi di grandi dimensioni con decine di microservizi, è consigliabile usare la comunicazione del gateway API. Per altre informazioni, vedere Microservizi .NET: Architettura per applicazioni .NET in contenitori.
Comunicazione tra microservizi
Un'applicazione basata su microservizi è un sistema distribuito, potenzialmente in esecuzione in più computer. Ogni istanza del servizio è in genere un processo. Pertanto, i servizi devono interagire usando un protocollo di comunicazione tra processi, ad esempio HTTP, TCP, Advanced Message Queuing Protocol (AMQP) o protocolli binari, a seconda della natura di ogni servizio.
I due approcci comuni per la comunicazione da microservizi a microservizio sono la comunicazione REST basata su HTTP durante l'esecuzione di query per i dati e la messaggistica asincrona leggera durante la comunicazione degli aggiornamenti tra più microservizi.
La comunicazione basata su eventi basata sulla messaggistica asincrona è fondamentale quando si propagano modifiche tra più microservizi. Con questo approccio, un microservizio pubblica un evento quando si verifica un evento rilevante, ad esempio quando aggiorna un'entità business. Altri microservizi sottoscrivono questi eventi. Quindi, quando un microservizio riceve un evento, aggiorna le proprie entità aziendali, che a sua volta potrebbero causare la pubblicazione di più eventi. Questa funzionalità di pubblicazione-sottoscrizione viene in genere ottenuta con un bus di eventi.
Un bus di eventi consente la comunicazione di pubblicazione-sottoscrizione tra microservizi, senza che i componenti siano consapevoli in modo esplicito tra loro, come illustrato nella figura 8-6.
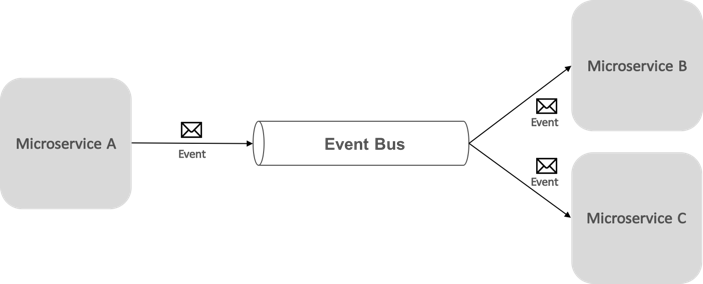
Figura 8-6: Pubblicazione-sottoscrizione con un bus di eventi
Dal punto di vista dell'applicazione, il bus di eventi è semplicemente un canale publish-subscribe esposto tramite un'interfaccia. Tuttavia, il modo in cui viene implementato il bus di eventi può variare. Ad esempio, un'implementazione del bus di eventi può usare RabbitMQ, il bus di servizio di Azure o altri bus di servizio, ad esempio NServiceBus e MassTransit. La figura 8-7 mostra come viene usato un bus di eventi nell'applicazione di riferimento eShopOnContainers.
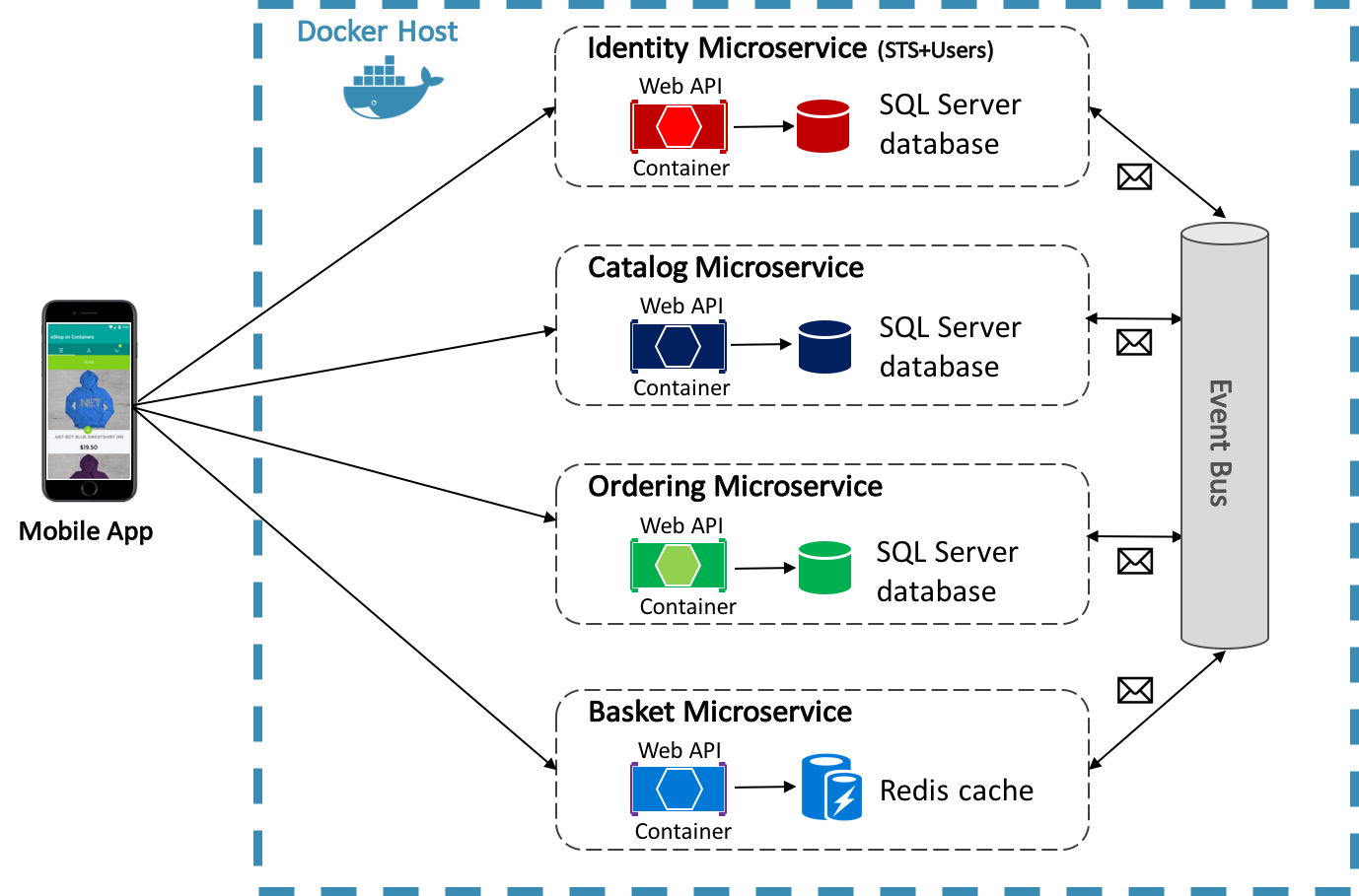
Figura 8-7: Comunicazione asincrona basata su eventi nell'applicazione di riferimento
Il bus di eventi eShopOnContainers, implementato tramite RabbitMQ, offre funzionalità di pubblicazione-sottoscrizione asincrona uno-a-molti. Ciò significa che, dopo la pubblicazione di un evento, possono essere presenti più sottoscrittori in ascolto dello stesso evento. La figura 8-9 illustra questa relazione.
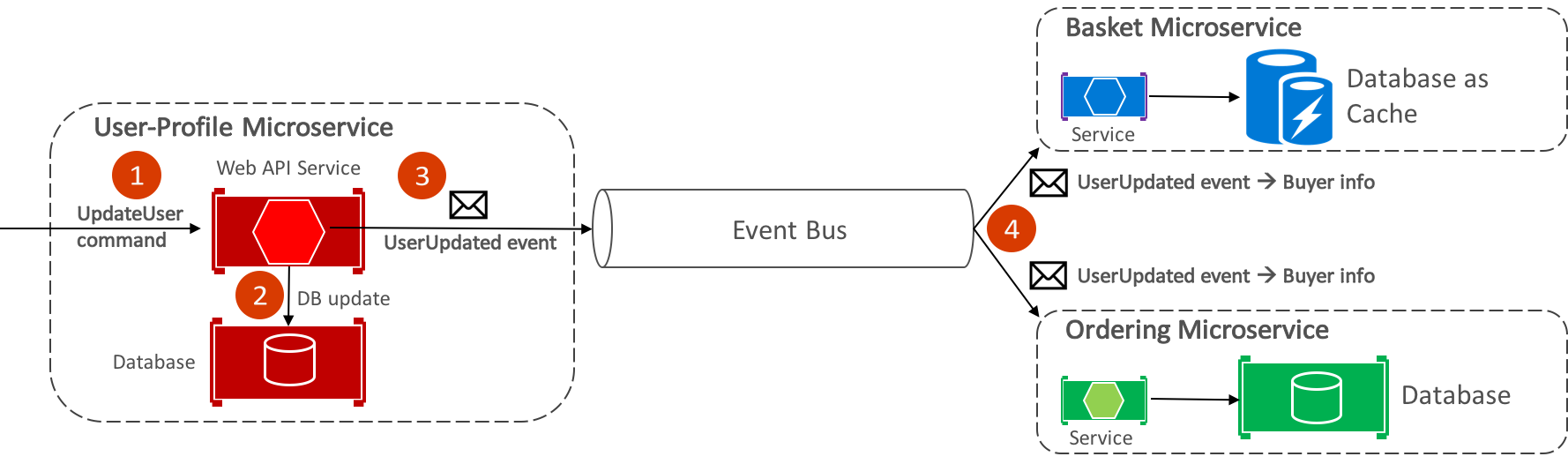
Figura 8-9: Comunicazione uno-a-molti
Questo approccio di comunicazione uno-a-molti usa gli eventi per implementare transazioni aziendali che si estendono su più servizi, garantendo una coerenza finale tra i servizi. Una transazione coerente finale è costituita da una serie di passaggi distribuiti. Pertanto, quando il microservizio del profilo utente riceve il comando UpdateUser, aggiorna i dettagli dell'utente nel database e pubblica l'evento UserUpdated nel bus di eventi. Sia il microservizio basket che il microservizio di ordinamento hanno sottoscritto per ricevere questo evento e in risposta aggiornano le informazioni sull'acquirente nei rispettivi database.
Nota
Il bus di eventi eShopOnContainers, implementato con RabbitMQ, deve essere usato solo come modello di verifica. Per i sistemi di produzione, è consigliabile considerare implementazioni alternative del bus di eventi.
Per informazioni sull'implementazione del bus di eventi, vedere Microservizi .NET: Architettura per applicazioni .NET in contenitori.
Riepilogo
I microservizi offrono un approccio allo sviluppo e alla distribuzione di applicazioni adatte ai requisiti di agilità, scalabilità e affidabilità delle applicazioni cloud moderne. Uno dei principali vantaggi dei microservizi è che possono essere ridimensionati in modo indipendente, il che significa che un'area funzionale specifica può essere ridimensionata che richiede una maggiore potenza di elaborazione o larghezza di banda di rete per supportare la domanda, senza dover ridimensionare inutilmente aree dell'applicazione che non riscontrano un aumento della domanda.
Un contenitore è un ambiente operativo isolato, controllato dalle risorse e portabile, in cui un'applicazione può essere eseguita senza toccare le risorse di altri contenitori o l'host. Le aziende adottano sempre più contenitori quando implementano applicazioni basate su microservizi e Docker è diventata l'implementazione standard del contenitore adottata dalla maggior parte delle piattaforme software e dai fornitori di servizi cloud.