Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Un'espressione regolare, comunemente definita regex, è una sequenza di caratteri che definisce un modello di ricerca. Le espressioni regolari vengono usate principalmente per la corrispondenza di criteri con stringhe e in corrispondenza di stringhe; ad esempio, nelle operazioni "trova e sostituisci". È possibile usare un regex in Prevenzione della perdita dei dati Microsoft Purview (DLP) per definire modelli che consentono di identificare e classificare i dati sensibili o per rilevare i modelli nel contenuto. Gli usi regex più comuni in Microsoft Purview DLP sono:
- Definizione di tipi di informazioni sensibili personalizzati.
- Utilizzo della condizione in una regola di prevenzione della
SubjectOrBodyMatchesPatternsperdita dei dati (vedere altre informazioni qui)
Questo articolo descrive i problemi comuni che si verificano quando si usano espressioni regolari e come è possibile risolverli.
Potenziale problema di convalida quando si usa un regex con DLP
- Le unità di base del modello, ad esempio caratteri letterali, cifre, spazi vuoti e segni di punteggiatura, possono essere rappresentate da se stessi o da simboli speciali denominati metacaratteri, ad
\desempio per qualsiasi cifra,\sper qualsiasi spazio vuoto o\.per un punto letterale. - Le unità di base, se combinate con i quantificatori, specificano quante volte possono o devono verificarsi in una corrispondenza. Ad esempio,
*significa zero o più,+significa uno o più,?significa zero o uno e{n,m}significa tranemvolte. Ad esempio,\d+indica una o più cifre,\s?indica spazi vuoti facoltativi ea{3,5}indica tra tre e cinque istanze del carattere letterale a. - Un regex usa un lookbehind positivo o un lookbehind negativo. Un lookbehind viene usato per verificare se esiste una corrispondenza prima di una determinata posizione nella stringa di input, senza includere i caratteri effettivi nella corrispondenza. Un lookbehind positivo viene usato per corrispondere quando è presente il modello lookbehind, mentre un lookbehind negativo viene usato per trovare la corrispondenza quando il modello lookbehind non è presente.
- Si consideri questo esempio:
(?<=^|\s|_). Questo esempio mostra un lookbehind che include tre possibilità:-
^asserisce la posizione. In questo caso, è necessario che la corrispondenza dei criteri inizi all'inizio della riga. -
\srileva eventuali spazi vuoti come corrispondenza. -
_corrisponde al carattere di sottolineatura letterale ( _ ).
-
- Nell'esempio precedente, le possibilità 2 e 3 corrisponderanno a un singolo carattere. Tuttavia, la possibilità n. 1 indica solo dove deve iniziare la corrispondenza. Non produrrà risultati rispetto ad alcuna corrispondenza di caratteri.
- Si prenda un secondo esempio,
^\d+$. Questa espressione regolare rileverà solo una stringa composta interamente da cifre, dall'inizio alla fine. - Le convalide del modello Regex in condizioni non fanno distinzione tra maiuscole e minuscole per impostazione predefinita. Per rispettare la distinzione tra maiuscole e minuscole, aggiungere (?-i) al modello
Come ottenere il testo estratto
Un regex viene confrontato sul testo estratto del contenuto, anziché sul contenuto stesso. Quindi, anche quando il modello sembra essere presente nel contenuto, potrebbe non corrispondere durante la valutazione di un criterio DLP.
Per assicurarsi di acquisire le corrispondenze appropriate, seguire questa procedura:
- Usare il cmdlet Test-TextExtraction per ottenere il testo estratto, che sarà costituito da un flusso di stringhe.
- Usare quindi il testo estratto per la corrispondenza con l'espressione regolare.
Ad esempio:
$data = ([System.IO.File]::ReadAllBytes('<FilePath>'))
$tr = Test-TextExtraction -FileData $data
$tr.ExtractedResults.ExtractedStreamText | Format-List
Come verificare il rilevamento dei tipi di informazioni riservate
Per verificare il rilevamento del tipo di informazioni sensibili (SIT), è necessario prendere il testo appena estratto e quindi eseguire il cmdlet Test-DataClassification su di esso per verificare il rilevamento. I risultati dell'esecuzione del cmdlet indicheranno se sono presenti corrispondenze SIT per il regex.
Ad esempio:
$textStream = $tr.ExtractedResults.ExtractedStreamText | Out-String
$result = Test-DataClassification -TextToClassify $textStream
$result.ClassificationResults | Format-List
Esempio di uso di un regex in una regola dei criteri DLP
In questo esempio si bloccherà il messaggio di posta elettronica che contiene stringhe che iniziano con ABC seguito da un numero.
Regex usato:^ABC\d
Esempio di regola DLP:New-DlpComplianceRule -Name "Rule_00" -Policy "Policy_00" -SubjectOrBodyMatchesPatterns "^ABC\d" - BlockAccess $True
Messaggio di posta elettronica di esempio
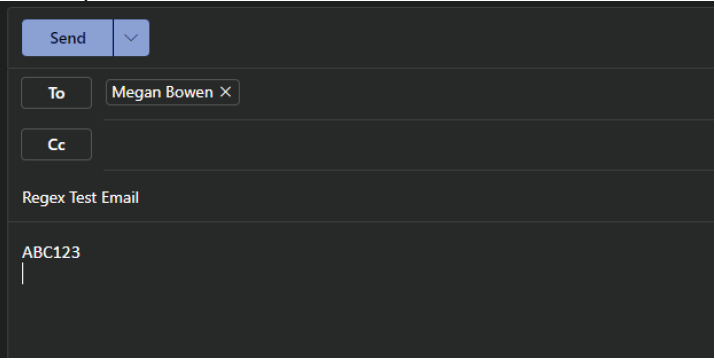
Anche se sembra che il regex rileverà una corrispondenza con questo elemento di posta elettronica, il testo estratto sarà simile al seguente:
Regex Test Email ABC123
Come si può vedere, il testo estratto inizia con il contenuto nella riga dell'oggetto del messaggio di posta elettronica, anziché con il contenuto nel corpo del messaggio di posta elettronica. Tuttavia, l'inclusione del carattere di asserzione, ^, all'inizio del regex richiede che la stringa ABC... sia all'inizio del testo estratto affinché venga rilevata una corrispondenza.
Per risolvere questo problema, è possibile modificare regex in ABC\d.