Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
| Mayana Pereira | Scott Christiansen |
|---|---|
| CELA Data Science | Sicurezza e attendibilità dei clienti |
| Microsoft | Microsoft |
Abstract — L'identificazione di report sui bug di sicurezza (SBR) è un passaggio fondamentale del ciclo di vita dello sviluppo software. Negli approcci basati su Machine Learning supervisionato, è normale presupporre che siano disponibili interi report di bug per il training e che le relative etichette siano prive di rumore. Al meglio della nostra conoscenza, questo è il primo studio a dimostrare che la previsione accurata delle etichette è possibile per gli SBR anche quando è disponibile solo il titolo e in presenza di rumore.
Termini d'indice - Machine Learning, Etichettatura Errata, Rumore, Bug Report di Sicurezza, Bug Repository
Io. INTRODUZIONE
L'identificazione dei problemi relativi alla sicurezza tra i bug segnalati è un'esigenza urgente tra i team di sviluppo software, come tali problemi richiedono correzioni più rapide per soddisfare i requisiti di conformità e garantire l'integrità del software e dei dati dei clienti.
Gli strumenti di Machine Learning e intelligenza artificiale promettono di rendere lo sviluppo del software più veloce, agile e corretto. Diversi ricercatori hanno applicato l'apprendimento automatico al problema di identificare i bug di sicurezza [2], [7], [8], [18]. Gli studi pubblicati precedenti hanno presupposto che l'intero report sui bug sia disponibile per il training e l'assegnazione di punteggi a un modello di Machine Learning. Questo non è necessariamente il caso. In alcune situazioni non è possibile rendere disponibile l'intero report sui bug. Ad esempio, il rapporto sui bug potrebbe contenere password, informazioni personali (PII) o altri tipi di dati sensibili, un caso che stiamo attualmente affrontando in Microsoft. È quindi importante stabilire in che modo sia possibile eseguire l'identificazione dei bug di sicurezza usando meno informazioni, ad esempio quando è disponibile solo il titolo del report sui bug.
Inoltre, i repository di bug contengono spesso voci con etichetta errata [7]: report di bug non di sicurezza classificati come correlati alla sicurezza e viceversa. Esistono diversi motivi per l'occorrenza di etichettatura errata, che vanno dalla mancanza di competenza del team di sviluppo in materia di sicurezza, alla confusione di determinati problemi, ad esempio è possibile che i bug non di sicurezza vengano sfruttati indirettamente per avere conseguenze sulla sicurezza. Si tratta di un problema grave, poiché l'errata etichettatura dei report sui bug di sicurezza comporta la necessità di esaminare manualmente il database dei bug in uno sforzo costoso e dispendioso in termini di tempo. Comprendere in che modo il disturbo influisce sui diversi classificatori e su quanto siano affidabili (o fragili) diverse tecniche di Machine Learning in presenza di set di dati contaminati con diversi tipi di rumore è un problema che deve essere risolto per portare la classificazione automatica alla pratica dell'ingegneria software.
Il lavoro preliminare sostiene che i repository di bug sono intrinsecamente rumorosi e che il rumore potrebbe avere un effetto negativo sui classificatori di Machine Learning sulle prestazioni [7]. Manca tuttavia qualsiasi studio sistematico e quantitativo sul modo in cui livelli e tipi di disturbo diversi influiscono sulle prestazioni di diversi algoritmi di Machine Learning supervisionato per il problema di identificare i report sui bug di sicurezza (SRB).
In questo studio viene illustrato che la classificazione dei report sui bug può essere eseguita anche quando il titolo è disponibile esclusivamente per il training e l'assegnazione dei punteggi. Per quanto ne sappiamo questo è il primo lavoro a farlo. Inoltre, viene fornito il primo studio sistematico dell'effetto del rumore nella classificazione dei report sui bug. Facciamo uno studio comparativo dell'affidabilità di tre tecniche di Machine Learning (regressione logistica, Bayes naïve e AdaBoost) contro il rumore indipendente dalla classe.
Anche se esistono alcuni modelli analitici che acquisiscono l'influenza generale del rumore per alcuni semplici classificatori [5], [6], questi risultati non forniscono limiti stretti sull'effetto del rumore sulla precisione e sono validi solo per una determinata tecnica di Machine Learning. Un'analisi accurata dell'effetto del rumore nei modelli di Machine Learning viene in genere eseguita eseguendo esperimenti di calcolo. Tali analisi sono state eseguite per diversi scenari, dai dati di misurazione software [4], alla classificazione delle immagini satellite [13] e ai dati medici [12]. Tuttavia, questi risultati non possono essere convertiti nel problema specifico, a causa della sua elevata dipendenza dalla natura dei set di dati e dal problema di classificazione sottostante. Al meglio delle nostre conoscenze, non ci sono risultati pubblicati sul problema dell'effetto dei set di dati rumorosi sulla classificazione dei report sui bug di sicurezza in particolare.
I NOSTRI CONTRIBUTI DI RICERCA:
I classificatori vengono sottoposti a training per l'identificazione dei report sui bug di sicurezza (SBR) esclusivamente in base al titolo dei report. Per quanto ne sappiamo, questo è il primo studio a farlo. Le operazioni precedenti usano il report di bug completo o hanno migliorato il report sui bug con funzionalità complementari aggiuntive. La classificazione dei bug basata esclusivamente sul riquadro è particolarmente rilevante quando non è possibile rendere disponibili i report di bug completi a causa di problemi di privacy. Ad esempio, è noto il caso di report sui bug che contengono password e altri dati sensibili.
Viene inoltre fornito il primo studio sistematico sulla tolleranza al rumore delle etichette di diversi modelli e tecniche di apprendimento automatico usati per la classificazione automatica delle SBRs. Facciamo uno studio comparativo dell'affidabilità di tre tecniche distinte di Machine Learning (regressione logistica, Bayes naïve e AdaBoost) contro il rumore dipendente dalla classe e indipendente dalla classe.
Il resto del documento è presentato come segue: nella sezione II sono presenti alcune delle opere precedenti della letteratura. Nella sezione III viene descritto il set di dati e il modo in cui i dati vengono pre-elaborati. La metodologia è descritta nella sezione IV e i risultati degli esperimenti analizzati nella sezione V. Infine, le nostre conclusioni e le nostre opere future sono presentate in VI.
II. LAVORI PRECEDENTI
APPLICAZIONI DI MACHINE LEARNING NEI REPOSITORY DI BUG.
Esiste una vasta letteratura nell'applicazione di text mining, elaborazione del linguaggio naturale e Machine Learning nei repository di bug in un tentativo di automatizzare attività laboriose, ad esempio il rilevamento di bug di sicurezza [2], [7], [8], [18], identificazione dei duplicati di bug [3], valutazione dei bug [1], [11], per denominare alcune applicazioni. Idealmente, il matrimonio tra Machine Learning (ML) ed elaborazione del linguaggio naturale riduce potenzialmente il lavoro manuale necessario per curare i database di bug, ridurre il tempo necessario per eseguire queste attività e aumentare l'affidabilità dei risultati.
In [7] gli autori propongono un modello linguistico naturale per automatizzare la classificazione delle richieste di archiviazione in base alla descrizione del bug. Gli autori estraggono un vocabolario da tutte le descrizioni dei bug nel set di dati di training e lo curano manualmente in tre elenchi di parole: parole rilevanti, parole non significative (parole comuni che sembrano irrilevanti per la classificazione) e sinonimi. Essi confrontano le prestazioni del classificatore di bug di sicurezza addestrato sui dati che vengono tutti valutati dai tecnici della sicurezza e di un classificatore addestrato sui dati etichettati generalmente dai reporter di bug. Anche se il modello è chiaramente più efficace quando viene addestrato su dati esaminati da ingegneri della sicurezza, il modello proposto si basa su un vocabolario derivato manualmente, rendendolo dipendente dalla curazione umana. Inoltre, non esiste alcuna analisi del modo in cui diversi livelli di rumore influiscono sul modello, sul modo in cui i diversi classificatori rispondono al rumore e se il rumore in entrambe le classi influisce in modo diverso sulle prestazioni.
Zou et. al [18] utilizza più tipi di informazioni contenute in un report di bug che coinvolgono i campi non testuali di un report di bug (funzionalità meta, ad esempio tempo, gravità e priorità) e il contenuto testuale di un report di bug (funzionalità testuali, ovvero il testo nei campi di riepilogo). In base a queste funzionalità, creano un modello per identificare automaticamente gli SDR tramite l'elaborazione del linguaggio naturale e le tecniche di Machine Learning. In [8] gli autori eseguono un'analisi simile, ma confrontano anche le prestazioni delle tecniche di Machine Learning supervisionate e non supervisionate e studiano la quantità di dati necessari per eseguire il training dei modelli.
In [2] gli autori esplorano anche diverse tecniche di Machine Learning per classificare i bug come SBC o NSBR (Non-Security Bug Report) in base alle descrizioni. Propongono una pipeline per l'elaborazione dei dati e il training del modello basati su TFIDF. Confrontano la pipeline proposta con un modello basato su bag-of-words e Naïve Bayes. Wijayasekara et al. [16] usava anche tecniche di text mining per generare il vettore di funzionalità di ogni report di bug basato su parole frequenti per identificare i bug di impatto nascosto (HIB). Yang et al. [17] hanno affermato di identificare report di bug ad alto impatto (ad esempio, SBR) con l'aiuto di Frequenza Termine (TF) e Naive Bayes. In [9] gli autori propongono un modello per stimare la gravità di un bug.
RUMORE DI ETICHETTATURA
Il problema della gestione dei set di dati con rumore nelle etichette è stato ampiamente studiato. Frenay e Verleysen propongono una tassonomia di rumore di etichetta in [6], al fine di distinguere diversi tipi di etichetta rumorosa. Gli autori propongono tre diversi tipi di disturbo: rumore dell'etichetta che si verifica indipendentemente dalla vera classe e dei valori delle caratteristiche dell'istanza; rumore dell'etichetta che dipende solo dall'etichetta vera; e disturbo dell'etichetta in cui la probabilità di etichettatura errata dipende anche dai valori delle caratteristiche. Nel nostro lavoro studiamo i primi due tipi di rumore. Dal punto di vista teorico, il rumore delle etichette riduce in genere le prestazioni di un modello [10], tranne in alcuni casi specifici [14]. In generale, i metodi affidabili si basano sull'evitare l'overfitting per gestire il rumore delle etichette [15]. Lo studio degli effetti del rumore nella classificazione è stato fatto prima in molte aree come la classificazione delle immagini satellitari [13], la classificazione della qualità del software [4] e la classificazione del dominio medico [12]. Al meglio della nostra conoscenza, non ci sono lavori pubblicati che studiano la quantificazione precisa degli effetti delle etichette rumorose nel problema della classificazione SBR. In questo scenario non è stata stabilita la relazione precisa tra livelli di rumore, tipi di rumore e riduzione delle prestazioni. Inoltre, vale la pena comprendere come si comportano diversi classificatori in presenza di rumore. Più in generale, non siamo a conoscenza di qualsiasi lavoro che studia sistematicamente l'effetto di set di dati rumorosi sulle prestazioni di diversi algoritmi di Machine Learning nel contesto dei report sui bug software.
III. DESCRIZIONE DELL'INSIEME DI DATI
Il set di dati è costituito da 1.073.149 titoli di bug, 552.073 di cui corrispondono a SBR e 521.076 a NSBR. I dati sono stati raccolti da vari team di Microsoft negli anni 2015, 2016, 2017 e 2018. Tutte le etichette sono state ottenute dai sistemi di verifica dei bug basati sulla firma o dall'etichetta umana. I titoli di bug nel set di dati sono testi molto brevi, contenenti circa 10 parole, con una panoramica del problema.
Un. Pre-elaborazione dei dati Viene analizzato ogni titolo di bug in base agli spazi vuoti, generando un elenco di token. Ogni elenco di token viene elaborato come segue:
Rimuovere tutti i token che sono percorsi di file
Token di divisione in cui sono presenti i simboli seguenti: { , (, ), -, }, {, [, ], }
Rimuovere parole non significative, token composti solo da caratteri numerici e token visualizzati meno di 5 volte nell'intero corpus.
IV. METODOLOGIA
Il processo di training dei modelli di Machine Learning è costituito da due passaggi principali: codificare i dati in vettori di funzionalità e formare classificatori di Machine Learning supervisionati.
Un. Vettori di funzionalità e tecniche di Machine Learning
La prima parte prevede la codifica dei dati in vettori di funzionalità usando l'algoritmo frequenza termine-inverso della frequenza documentale (TF-IDF), come utilizzato in [2]. TF-IDF è una tecnica di recupero delle informazioni che pesa la frequenza dei termini (TF) e la relativa frequenza inversa dei documenti (IDF). Ogni parola o termine ha il rispettivo punteggio TF e IDF. L'algoritmo TF-IDF assegna l'importanza a tale parola in base al numero di volte in cui viene visualizzato nel documento e, più importante, controlla la rilevanza della parola chiave nell'insieme di titoli nel set di dati. Abbiamo addestrato e confrontato tre tecniche di classificazione: naive Bayes (NB), alberi decisionali potenziati (AdaBoost) e la regressione logistica (LR). Queste tecniche sono state scelte perché sono state illustrate per ottenere prestazioni ottimali per l'attività correlata di identificare i report sui bug di sicurezza in base all'intero report nella documentazione. Questi risultati sono stati confermati in un'analisi preliminare in cui questi tre classificatori hanno superato le macchine vettoriali di supporto e le foreste casuali. Negli esperimenti viene usata la libreria scikit-learn per la codifica e il training del modello.
B. Tipi di rumore
Il rumore studiato in questo lavoro si riferisce al rumore nell'etichetta della classe nei dati di addestramento. In presenza di tale rumore, di conseguenza, il processo di apprendimento e il modello risultante sono compromessi da esempi non etichettati. Analizziamo l'impatto dei diversi livelli di rumore applicati alle informazioni sulla classe. I tipi di rumore dell'etichetta sono stati trattati in precedenza nella letteratura usando varie terminologie. Nel nostro lavoro, analizziamo gli effetti di due diversi tipi di rumore di etichetta nei nostri classificatori: rumore di etichetta indipendente dalla classe, introdotto selezionando istanze in modo casuale e cambiando la loro etichetta; e rumore dipendente dalla classe, dove le classi hanno diverse probabilità di essere rumorose.
a) rumore indipendente dalla classe: il rumore indipendente dalla classe fa riferimento al rumore che si verifica indipendentemente dalla classe vera delle istanze. In questo tipo di rumore, la probabilità di etichettatura errata pbr è la stessa per tutte le istanze del set di dati. Introduciamo un rumore indipendente dalla classe nei nostri set di dati invertendo casualmente ogni etichetta con probabilità pbr.
b) rumore dipendente dalla classe: il rumore dipendente dalla classe fa riferimento al rumore che dipende dalla classe vera delle istanze. In questo tipo di rumore, la probabilità di mislabellare nella classe SBR è psbr e la probabilità di mislabellare nella classe NSBR è pnsbr. Si introduce un disturbo dipendente dalla classe nel set di dati capovolgendo ogni voce nel set di dati per cui l'etichetta true è SBR con probabilità psbr. Analogamente, invertiamo l'etichetta di classe delle istanze NSBR con probabilità pnsbr.
c) rumore a classe singola: il rumore a classe singola è un caso speciale di rumore dipendente dalla classe, dove pnsbr = 0 e psbr> 0. Si noti che per il rumore indipendente dalla classe abbiamo psbr = pnsbr = pbr.
C. Generazione rumore
I nostri esperimenti esaminano l'impatto di diversi tipi e livelli di rumore nel processo di addestramento dei classificatori SBR. Abbiamo impostato 25% del set di dati come dati di test, 10% come dati di convalida e 65% come dati di addestramento.
Si aggiunge rumore agli insiemi di dati di training e convalida per livelli diversi di pbr, psbr e pnsbr . Non vengono apportate modifiche al set di dati di test. I diversi livelli di rumore usati sono P = {0,05 × i|0 < i < 10}.
Negli esperimenti di disturbo indipendenti dalla classe, per pbr ∈ P eseguire le operazioni seguenti:
Generare rumore per set di dati di addestramento e convalida.
Addestrare i modelli di regressione logistica, Naïve Bayes e AdaBoost usando il set di dati di allenamento (con disturbo); ottimizzare i modelli usando il set di dati di convalida (con disturbo).
Testare i modelli usando il set di dati di test (senza rumore).
Negli esperimenti di disturbo dipendente dalla classe, per psbr ∈ P e pnsbr ∈ P procediamo come segue per tutte le combinazioni di psbr e pnsbr:
Generare rumore per set di dati di addestramento e convalida.
Eseguire il training dei modelli di regressione logistica, Naïve Bayes e AdaBoost usando il dataset di addestramento (con rumore);
Affinare i modelli usando il set di dati di convalida (con disturbo);
Testare i modelli usando il set di dati di test (senza rumore).
V. RISULTATI SPERIMENTALI
In questa sezione vengono analizzati i risultati degli esperimenti condotti in base alla metodologia descritta nella sezione IV.
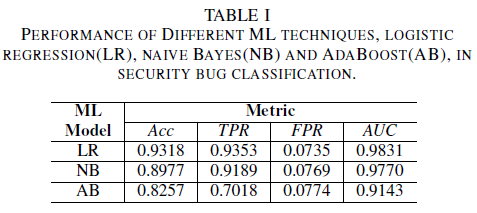
a) Prestazioni del modello senza rumore nel set di dati di training: uno dei contributi di questo documento è la proposta di un modello di Machine Learning per identificare i bug di sicurezza usando solo il titolo del bug come dati per il processo decisionale. In questo modo è possibile eseguire il training dei modelli di Machine Learning anche quando i team di sviluppo non vogliono condividere report di bug completi a causa della presenza di dati sensibili. Vengono confrontate le prestazioni di tre modelli di Machine Learning quando viene eseguito il training usando solo i titoli di bug.
Il modello di regressione logistica è il classificatore con prestazioni migliori. È il classificatore con il valore AUC più alto, pari a 0,9826, richiamo di 0,9353 per un valore FPR pari a 0,0735. Il classificatore Naïve Bayes presenta prestazioni leggermente inferiori rispetto al classificatore di regressione logistica, con un AUC pari a 0,9779 e un richiamo pari a 0,9189 per un FPR pari a 0,0769. Il classificatore AdaBoost presenta prestazioni inferiori rispetto ai due classificatori menzionati in precedenza. Ottiene un valore AUC pari a 0,9143 e un richiamo pari a 0,7018 per un FPR 0,0774. L'area sotto la curva ROC (AUC) è una buona metrica per confrontare le prestazioni di diversi modelli, come riepiloga in un singolo valore della relazione TPR e FPR. Nell'analisi successiva restringeremo la nostra analisi comparativa ai valori AUC.
Un. Rumore di classe: classe singola
Si può immaginare uno scenario in cui tutti i bug vengono assegnati alla classe NSBR per impostazione predefinita e un bug verrà assegnato alla classe SBR solo se è presente un esperto di sicurezza che esamina il repository di bug. Questo scenario è rappresentato nell'impostazione sperimentale a classe singola, in cui si presuppone che pnsbr = 0 e 0 < psbr< 0,5.
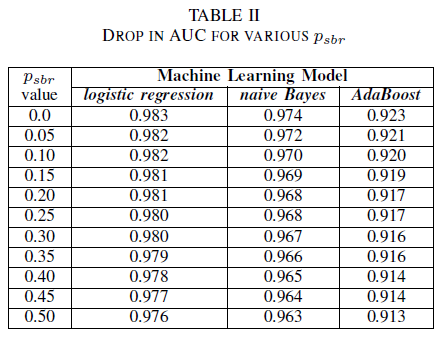
Dalla tabella II si osserva un impatto molto ridotto nell'AUC per tutti e tre i classificatori.From table II we observe a very small impact in the AUC for all three classifiers. Il AUC-ROC di un modello addestrato su psbr = 0 rispetto a un AUC-ROC di un modello in cui psbr = 0,25 differisce di 0,003 per la regressione logistica, 0,006 per Bayes naïve e 0,006 per AdaBoost. Nel caso di psbr = 0,50, l'AUC misurata per ognuno dei modelli differisce dal modello sottoposto a training con psbr = 0 per 0,007 per la regressione logistica, 0,011 per Bayes naïve e 0,010 per AdaBoost. il classificatore di regressione logistica sottoposto a training in presenza di rumore a classe singola presenta la variazione più piccola nella metrica AUC, ovvero un comportamento più affidabile, rispetto ai classificatori Naïve Bayes e AdaBoost.
B. Rumore di classe: indipendente dalla classe
Vengono confrontate le prestazioni dei nostri tre classificatori per il caso in cui il set di addestramento sia danneggiato da un rumore indipendente dalla classe. Viene misurata l'AUC per ogni modello addestrato con livelli diversi di pbr nei dati di addestramento.
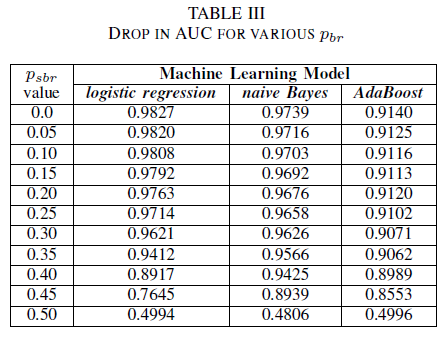
Nella tabella III si osserva una diminuzione del AUC-ROC per ogni incremento del rumore nell'esperimento. Il AUC-ROC misurato da un modello addestrato su dati senza rumore rispetto a un AUC-ROC di un modello addestrato con rumore indipendente dalla classe con pbr = 0,25 si differenzia di 0,011 per la regressione logistica, 0,008 per Bayes ingenuo e 0,0038 per AdaBoost. Si osserva che il rumore dell'etichetta non influisce sull'AUC dei classificatori Naïve Bayes e AdaBoost in modo significativo quando i livelli di rumore sono inferiori a 40%. D'altra parte, il classificatore di regressione logistica subisce un impatto sulla misurazione AUC per i livelli di rumore delle etichette superiori a 30%.
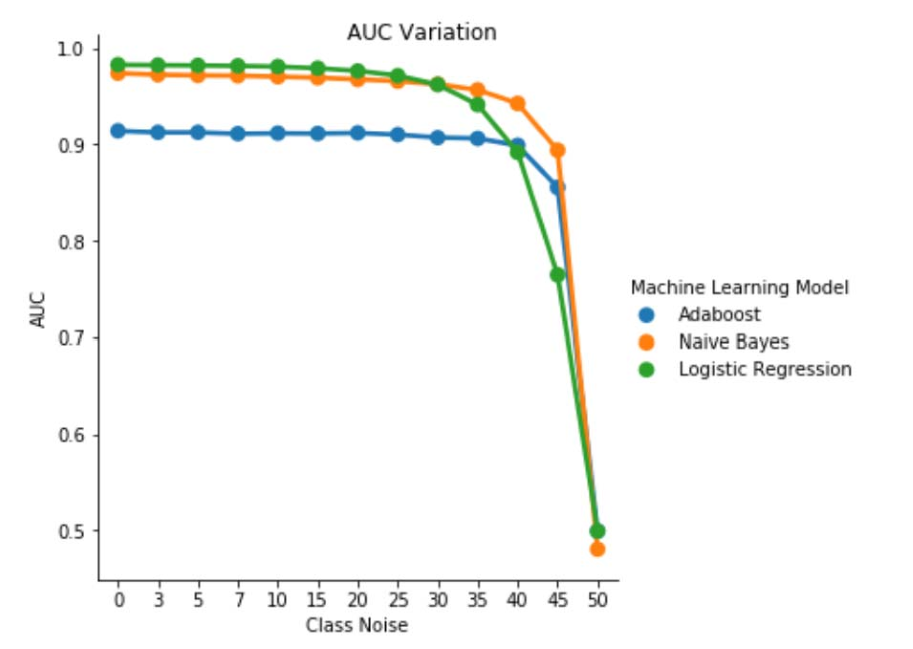
Fig. 1. Variazione di AUC-ROC nel rumore indipendente dalla classe. Per un livello di rumore pbr =0,5 il classificatore agisce come un classificatore casuale, ad esempio AUC≈0.5. Tuttavia, è possibile osservare che per i livelli di rumore inferiori (pbr ≤0,30), lo strumento di apprendimento della regressione logistica presenta prestazioni migliori rispetto agli altri due modelli. Tuttavia, per 0,35≤ pbr ≤0,45 naïve Bayes learner presenta metriche AUCROC migliori.
C. Rumore della classe: dipendente dalla classe
Nel set finale di esperimenti viene considerato uno scenario in cui classi diverse contengono livelli di rumore diversi, ad esempio psbr ≠ pnsbr. Incrementiamo sistematicamente psbr e pnsbr di 0,05 indipendentemente nei dati di addestramento e osserviamo il cambiamento del comportamento dei tre classificatori.
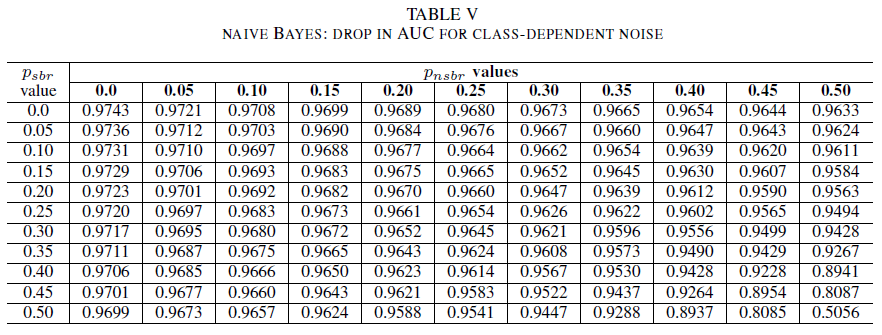
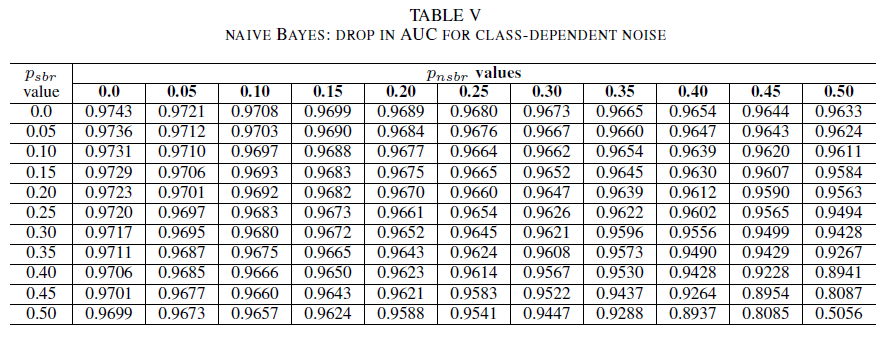
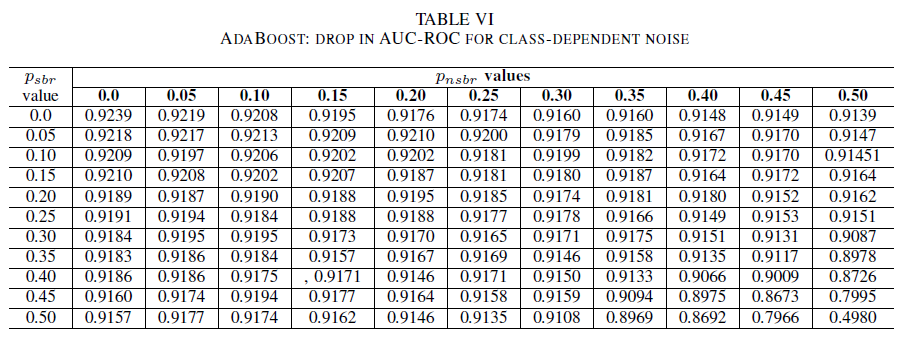
Le Tabelle IV, V, VI mostrano la variazione dell'AUC man mano che il rumore è aumentato in livelli diversi in ogni classe per la regressione logistica nella Tabella IV, per Naive Bayes nella Tabella V e per AdaBoost nella Tabella VI. Per tutti i classificatori, si nota un impatto sulla metrica AUC quando entrambe le classi presentano un livello di rumore superiore a 30%. Naïve Bayes si comporta in modo più robusto. L'impatto sull'AUC è molto ridotto anche se vengono invertiti i 50% dell'etichetta nella classe positiva, a patto che la classe negativa contenga 30% di etichette rumorose o meno. In questo caso, il calo dell'AUC è di 0,03. AdaBoost ha presentato il comportamento più affidabile di tutti e tre i classificatori. Un cambiamento significativo nell'AUC avverrà solo per i livelli di rumore superiori a 45% in entrambe le classi. In tal caso, si inizia a osservare un decadimento dell'AUC maggiore di 0,02.
D. Sulla presenza di rumore residuo nel set di dati originale
Il set di dati è stato etichettato da sistemi automatizzati basati sulla firma e da esperti umani. Inoltre, tutte le segnalazioni di bug sono state ulteriormente esaminate e chiuse da esperti umani. Anche se ci aspettiamo che la quantità di rumore nel set di dati sia minima e non statisticamente significativa, la presenza di rumore residuo non invalida le nostre conclusioni. In effetti, a titolo illustrativo, si supponga che il set di dati originale sia danneggiato da un rumore indipendente dalla classe uguale a 0 < p < 1/2 indipendente e identicamente distribuito (i.i.d) per ogni elemento.
Se noi, sopra il rumore originale, aggiungessimo un rumore indipendente dalla classe con probabilità pbr i.i.d, il rumore risultante per ogni voce sarà p∗ = p(1 − pbr )+(1 − p)pbr. Per 0 < p,pbr< 1/2, è necessario che il rumore effettivo per etichetta p∗ sia strettamente maggiore del rumore aggiunto artificialmente al set di dati pbr . Di conseguenza, le prestazioni dei classificatori sarebbero ancora migliori se fossero state addestrati con un set di dati completamente privo di rumore (p = 0) in primo luogo. In sintesi, l'esistenza di rumore residuo nel set di dati effettivo significa che la resilienza contro il rumore dei classificatori è migliore dei risultati qui presentati. Inoltre, se il rumore residuo nel set di dati fosse statisticamente rilevante, l'AUC dei classificatori diventerà 0,5 (una ipotesi casuale) per un livello di rumore rigorosamente inferiore a 0,5. Questo comportamento non viene osservato nei risultati.
VI. CONCLUSIONI E LAVORI FUTURI
Il nostro contributo in questo documento è duplice.
In primo luogo, è stata illustrata la fattibilità della classificazione dei report sui bug di sicurezza basata esclusivamente sul titolo del report sui bug. Ciò è particolarmente rilevante negli scenari in cui l'intero report sui bug non è disponibile a causa di vincoli di privacy. Ad esempio, in questo caso, i report sui bug contengono informazioni private come password e chiavi crittografiche e non erano disponibili per il training dei classificatori. Il risultato mostra che l'identificazione SBR può essere eseguita ad alta precisione anche quando sono disponibili solo i titoli dei report. Il nostro modello di classificazione che utilizza una combinazione di TF-IDF e regressione logistica raggiunge un'AUC di 0.9831.
In secondo luogo, è stato analizzato l'effetto dei dati di addestramento e validazione con etichetta errata. Sono state confrontate tre tecniche di classificazione di Machine Learning note (Bayes naïve, regressione logistica e AdaBoost) in termini di robustezza rispetto a diversi tipi di rumore e livelli di rumore. Tutti e tre i classificatori sono affidabili per il rumore a classe singola. Il rumore nei dati di addestramento non ha alcun effetto significativo sul classificatore risultante. La diminuzione dell'AUC è molto piccola ( 0,01) per un livello di rumore pari a 50%. Per il rumore presente in entrambe le classi ed è indipendente dalla classe, i modelli Bayes e AdaBoost presentano variazioni significative nell'AUC solo quando viene eseguito il training con un set di dati con livelli di rumore superiori a 40%.
Infine, il rumore dipendente dalla classe influisce significativamente sull'AUC solo quando ci sono più di 35% di rumore in entrambe le classi. AdaBoost ha mostrato la massima robustezza. L'impatto nell'AUC è molto piccolo anche quando la classe positiva ha 50% delle etichette rumorose, a condizione che la classe negativa contenga 45% di etichette rumorose o meno. In questo caso, la diminuzione dell'AUC è minore di 0,03. Al meglio delle nostre conoscenze, questo è il primo studio sistematico sull'effetto di set di dati rumorosi per l'identificazione dei report sui bug di sicurezza.
LAVORI FUTURI
In questo documento è stato avviato lo studio sistematico degli effetti del rumore nelle prestazioni dei classificatori di Machine Learning per l'identificazione dei bug di sicurezza. Ci sono diversi sequel interessanti di questo lavoro, tra cui: esaminare l'effetto di set di dati rumorosi per determinare il livello di gravità di un bug di sicurezza; comprendere l'effetto dello squilibrio della classe sulla resilienza dei modelli sottoposti a training contro il rumore; comprendere l'effetto del rumore che viene introdotto in modo antagonista nel set di dati.
REFERENZE
[1] John Anvik, Lyndon Hiew e Gail C Murphy. Chi dovrebbe correggere questo bug? Nei Proceedings della 28a conferenza internazionale di ingegneria del software, pagine 361-370. ACM, 2006.
[2] Diksha Behl, Sahil Handa e Anuja Arora. Uno strumento di mining di bug per identificare e analizzare i bug di sicurezza usando Naive Bayes e tf-idf. In Optimization, Reliability e Tecnologia dell'Informazione (ICROIT), Conferenza Internazionale 2014, pagine 294–299. IEEE, 2014.
Nicolas Bettenburg, Rahul Premraj, Thomas Zimmermann e Sunghun Kim. Report di bug duplicati considerati dannosi, davvero? In Manutenzione software, 2008. ICSM 2008. Conferenza internazionale IEEE su, pagine 337–345. IEEE, 2008.
[4] Andres Folleco, Taghi M Khoshgoftaar, Jason Van Hulse e Lofton Bullard. Identificazione degli studenti affidabili per i dati di bassa qualità. In Riutilizzo e integrazione delle informazioni, 2008. IRI 2008. IEEE International Conference su, pagine 190–195. IEEE, 2008.
[5] Benoˆıt Frenay.' Incertezza e rumore delle etichette nell'apprendimento automatico. Tesi di dottorato, Università cattolica di Louvain, Louvain-la-Neuve, Belgio, 2013.
Benoˆıt Frenay e Michel Verleysen. Classificazione in presenza del rumore dell'etichetta: un sondaggio. transazioni IEEE su reti neurali e sistemi di apprendimento, 25(5):845-869, 2014.
Michael Gegick, Pete Rotella e Tao Xie. Identificazione dei report sui bug di sicurezza tramite text mining: case study industriale. In i repository del software di estrazione (MSR), 2010 7th IEEE working conference on, pagine 11-20. IEEE, 2010.
Katerina Goseva-Popstojanova e Jacob Tyo. Identificazione dei report sui bug correlati alla sicurezza tramite text mining usando la classificazione supervisionata e non supervisionata. In 2018 IEEE International Conference on Software Quality, Reliability and Security (QRS), pagine 344-355, 2018.
Ahmed Lamkanfi, Serge Demeyer, Vittorio Giger e Bart Goethals. Stima della gravità di un bug segnalato. In Mining Software Repositories (MSR), 2010 7th IEEE Working Conference on, pagine 1–10. IEEE, 2010.
[10] Naresh Manwani e PS Sastry. Tolleranza al rumore in caso di riduzione al minimo dei rischi. transazioni IEEE su cibernetica, 43(3):1146-1151, 2013.
[11] G Murphy e D Cubranic. Valutazione automatica dei bug con la categorizzazione del testo. In La sedicesima conferenza internazionale sull'ingegneria del software & knowledge engineering. Citeseer, 2004.
[12] Mykola Pechenizkiy, Alexey Tsymbal, Seppo Puuronen e Oleksandr Pechenizkiy. Rumore di classe e apprendimento supervisionato nei domini medici: l'effetto dell'estrazione delle caratteristiche. In null, pagine da 708 a 713. IEEE, 2006.
[13] Charlotte Pelletier, Silvia Valero, Jordi Inglada, Nicolas Champion, Claire Marais Sicre e Gerard Dedieu. Effetto del rumore delle etichette di classe di training sulle prestazioni di classificazione per la mappatura della copertura terrestre con serie temporali di immagini satellitari. Remote Sensing, 9(2):173, 2017.
[14] PS Sastry, GD Nagendra e Naresh Manwani. Un team di automati d'apprendimento a azione continua per l'apprendimento tollerante al rumore di semispazi. Transazioni IEEE di Sistemi, Uomo e Cibernetica, Parte B (Cibernetica), 40(1):19–28, 2010.
[15] Choh-Man Teng. Confronto tra tecniche di gestione del rumore. In FLAIRS Conference, pagine 269-273, 2001.
[16] Dumidu Wijayasenya, Milos Manic e Miles McQueen. Identificazione e classificazione delle vulnerabilità tramite database di bug di data mining di testo. In Industrial Electronics Society, IECON 2014-40th Annual Conference of the IEEE, pagine 3612–3618. IEEE, 2014.
[17] Xinli Yang, David Lo, Qiao Huang, Xin Xia e Jianling Sun. Identificazione automatica dei report sui bug ad alto impatto sfruttando strategie di apprendimento sbilanciate. In Computer Software and Applications Conference (COMPSAC), 2016 IEEE 40th Annual, volume 1, pagine 227–232. IEEE, 2016.
[18] Deqing Zou, Zhijun Deng, Zhen Li e Hai Jin. Identificazione automatica dei report sui bug di sicurezza tramite l'analisi delle funzionalità multitipo. In Conferenza sull'Australasia sulla Sicurezza e Privacy delle Informazioni, Pagine 619-633. Springer, 2018.