Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Di Andrew Marshall, Jugal Parikh, Emre Kiciman e Ram Shankar Siva Kumar
Ringraziamento speciale a Raul Rojas e all'AETHER Security Engineering Workstream
Novembre 2019
Questo documento è un risultato finale di AETHER Engineering Practices for AI Working Group e integra le procedure di modellazione delle minacce SDL esistenti fornendo nuove indicazioni sull'enumerazione delle minacce e sulla mitigazione specifiche per l'intelligenza artificiale e lo spazio di Machine Learning. È progettato per essere usato come riferimento durante le revisioni della progettazione della sicurezza degli elementi seguenti:
Prodotti/servizi che interagiscono con o assumono dipendenze dai servizi basati su intelligenza artificiale/Machine Learning
Prodotti/servizi creati con intelligenza artificiale/Machine Learning al loro centro
La mitigazione tradizionale delle minacce per la sicurezza è più importante che mai. I requisiti stabiliti dal ciclo di vita dello sviluppo della sicurezza sono essenziali per stabilire una base di sicurezza del prodotto basata su queste linee guida. L'impossibilità di affrontare le minacce di sicurezza tradizionali consente di abilitare gli attacchi specifici di intelligenza artificiale/Machine Learning trattati in questo documento sia nei domini software che fisici, oltre a rendere la compromissione semplice ridurre lo stack di software. Per un'introduzione alle completamente nuove minacce alla sicurezza in questo spazio, vedere Protezione del futuro dell'Intelligenza Artificiale e ML in Microsoft.
I set di competenze dei tecnici della sicurezza e dei data scientist in genere non si sovrappongono. Queste linee guida consentono a entrambe le discipline di avere conversazioni strutturate su queste minacce/mitigazioni net-new senza richiedere ai tecnici della sicurezza di diventare data scientist o viceversa.
Questo documento è suddiviso in due sezioni:
- "Principali nuove considerazioni nella modellazione delle minacce" è incentrato su nuovi modi di pensare e nuove domande da porre quando si modellano i sistemi di intelligenza artificiale/Machine Learning. Sia i data scientist che i tecnici della sicurezza devono esaminarlo perché sarà il loro playbook per le discussioni sulla modellazione delle minacce e la definizione delle priorità di mitigazione.
- "Minacce specifiche per intelligenza artificiale/MACHINE e le relative mitigazioni" fornisce informazioni dettagliate su attacchi specifici e procedure di mitigazione specifiche attualmente in uso per proteggere i prodotti e i servizi Microsoft da queste minacce. Questa sezione è destinata principalmente ai data scientist che potrebbero dover implementare mitigazioni specifiche delle minacce come output del processo di modellazione/revisione della sicurezza delle minacce.
Queste linee guida sono organizzate intorno a una tassonomia delle minacce di Machine Learning antagonista creata da Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen e Jeffrey Snover intitolato "Modalità di errore in Machine Learning". Per indicazioni sulla gestione degli incidenti nel triage delle minacce alla sicurezza descritte in questo documento, fare riferimento alla SDL Bug Bar per le minacce di intelligenza artificiale/apprendimento automatico. Tutti questi documenti sono in evoluzione e si adatteranno nel tempo al panorama delle minacce.
Nuove considerazioni chiave nella modellazione delle minacce: modifica del modo in cui si visualizzano i limiti di attendibilità
Si supponga di compromettere o avvelenare i dati di cui si esegue il training, nonché il provider di dati. Informazioni su come rilevare voci di dati anomale e dannose, oltre a essere in grado di distinguere e recuperare da essi
Riassunto
Gli archivi dati di training e i sistemi che li ospitano fanno parte dell'ambito di modellazione delle minacce. La più grande minaccia per la sicurezza nell'apprendimento automatico oggi è l'avvelenamento dei dati a causa della mancanza di rilevamenti e mitigazioni standard in questo spazio, combinati con la dipendenza da set di dati pubblici non attendibili/noncurati come origini di dati di training. Tenere traccia della provenienza e della derivazione dei dati è essenziale per garantire la sua attendibilità ed evitare un ciclo di training "Garbage in, Garbage Out".
Domande da porre in una verifica della sicurezza
Se i dati sono avvelenati o manomessi, come si sa?
- Quali dati di telemetria avete per rilevare un'anomalia nella qualità dei vostri dati di addestramento?
Stai facendo training dagli input forniti dall'utente?
-Che tipo di convalida/purificazione dell'input stai facendo su quel contenuto?
-La struttura di questi dati è documentata in modo simile ai fogli dati per i set di dati?
Se si esegue il training su archivi dati online, quali passaggi eseguire per garantire la sicurezza della connessione tra il modello e i dati?
-Hanno un modo per segnalare compromessi ai consumatori dei loro feed?
- Sono anche in grado di farlo?
Qual è la sensibilità dei dati da cui si esegue il training?
-È possibile catalogarlo o controllare l'aggiunta,l'aggiornamento o l'eliminazione delle voci di dati?
Il modello può restituire dati sensibili?
-Questi dati sono stati ottenuti con l'autorizzazione dall'origine?
Il modello restituisce solo i risultati necessari per raggiungere l'obiettivo?
Il modello restituisce punteggi di attendibilità non elaborati o qualsiasi altro output diretto che potrebbe essere registrato e duplicato?
Qual è l'impatto dei dati di training recuperati attaccando o invertendo il modello?
Se i livelli di attendibilità dell'output del modello diminuiscno improvvisamente, è possibile scoprire come/perché, nonché i dati che lo hanno causato?
È stato definito un input ben formato per il modello? Cosa si sta facendo per garantire che gli input soddisfino questo formato e cosa fare se non lo fanno?
Se gli output non sono corretti ma non causano errori da segnalare, come è possibile sapere?
Si sa se gli algoritmi di training sono resilienti agli input antagonisti a livello matematico?
Come si recupera dalla contaminazione antagonista dei dati di training?
-È possibile isolare/mettere in quarantena il contenuto antagonista e ripetere il training dei modelli interessati?
-È possibile eseguire il rollback o il ripristino in un modello di una versione precedente per il nuovo training?
Si usa l'apprendimento per rinforzo su contenuti pubblici non valutati?
Inizia a pensare all'origine dei tuoi dati: se trovassi un problema, potresti tracciarlo fino alla sua introduzione nel set di dati? In caso contrario, è un problema?
Sapere da dove provengono i dati di training e identificare le norme statistiche per iniziare a comprendere l'aspetto delle anomalie
-Quali elementi dei dati di training sono vulnerabili all'influenza esterna?
-Chi può contribuire ai set di dati da cui si trae formazione?
-Come attaccheresti le fonti dei dati di formazione per danneggiare un concorrente?
Minacce e mitigazioni correlate in questo documento
Perturbazione antagonista (tutte le varianti)
Avvelenamento dei dati (tutte le varianti)
Esempi di attacchi
Forzare i messaggi di posta elettronica non dannosi a essere classificati come posta indesiderata o causare un esempio dannoso non rilevato
Input creati da utenti malintenzionati che riducono il livello di attendibilità della classificazione corretta, in particolare in scenari con conseguenze elevate
Un utente malintenzionato inserisce il rumore in modo casuale nei dati di origine che vengono classificati per ridurre la probabilità che la classificazione corretta venga usata in futuro, rendendo di fatto il modello meno efficace.
Contaminazione dei dati di training per forzare la classificazione errata dei punti dati selezionati, causando azioni specifiche eseguite o omesse da un sistema
Identificare le azioni che il modello o il prodotto/servizio può eseguire che può causare danni al cliente online o nel dominio fisico
Riassunto
Gli attacchi non mitigati ai sistemi IA/ML possono trasferirsi nel mondo fisico. Qualsiasi scenario che può essere manipolato per arrecare danno psicologico o fisico agli utenti è un rischio catastrofico per il tuo prodotto/servizio. Ciò si estende a tutti i dati sensibili sui clienti usati per le scelte di formazione e progettazione che possono rivelare tali dati personali.
Domande da porre in una verifica della sicurezza
Si effettua l'addestramento con esempi avversari? Quale impatto ha sull'output del modello nel dominio fisico?
Come si manifesta il trolling per il tuo prodotto/servizio? Come è possibile rilevare e rispondere?
Cosa serve perché il tuo modello restituisca un risultato che inganni il servizio nel negare l'accesso a utenti legittimi?
Qual è l'impatto della copia/furto del modello?
Il modello può essere usato per dedurre l'appartenenza di una singola persona in un determinato gruppo o semplicemente nei dati di training?
Un utente malintenzionato può causare danni alla reputazione o ripercussioni negative di pubbliche relazioni al prodotto forzandolo ad eseguire azioni specifiche?
Come si gestiscono i dati formattati correttamente ma eccessivamente distorti, ad esempio dai troll?
È possibile, per ogni modo di interagire con o eseguire query sul modello, interrogare tale metodo per divulgare i dati di addestramento o la funzionalità del modello?
Minacce e mitigazioni correlate in questo documento
Inferenza dell'appartenenza
Inversione del modello
Furto di modelli
Esempi di attacchi
Ricostruzione ed estrazione dei dati di training eseguendo ripetutamente query sul modello per ottenere risultati di attendibilità massima
Duplicazione del modello stesso mediante una corrispondenza esaustiva di query/risposta
L'esecuzione di query sul modello in modo da rivelare un elemento specifico di dati privati è stato incluso nel set di training
Auto a guida autonoma ingannata ad ignorare i segnali di stop/semafori
Bot conversazionali manipolati per trollare utenti benigni
Identificare tutte le origini delle dipendenze di Intelligenza artificiale/Machine Learning, nonché i livelli di presentazione front-end nella supply chain di dati/modelli
Riassunto
Molti attacchi in intelligenza artificiale e Machine Learning iniziano con l'accesso legittimo alle API che vengono visualizzate per fornire l'accesso alle query a un modello. A causa delle ricche fonti di dati e delle esperienze utente ricche coinvolte qui, l'accesso autenticato ma "inappropriato" (qui c'è un'area grigia) di terze parti ai modelli è un rischio a causa della possibilità di agire come livello di presentazione sopra un servizio fornito da Microsoft.
Domande da porre in una verifica della sicurezza
Quali clienti/partner vengono autenticati per accedere alle API del modello o del servizio?
-Possono fungere da livello di presentazione per il tuo servizio?
-È possibile revocare tempestivamente l'accesso in caso di compromissione?
-Qual è la strategia di ripristino in caso di uso dannoso del servizio o delle dipendenze?
Una terza parte può costruire una facciata attorno al tuo modello per riutilizzarlo e danneggiare Microsoft o la sua clientela?
I clienti forniscono direttamente i dati di addestramento?
-Come si proteggono i dati?
- Cosa fare se è dannoso e il servizio è il bersaglio?
Che aspetto ha un falso positivo qui? Qual è l'impatto di un falso negativo?
È possibile tenere traccia e misurare la deviazione dei tassi vero positivo e falso positivo tra più modelli?
Di quali tipi di dati di telemetria hai bisogno per dimostrare l'affidabilità dell'output del tuo modello ai clienti?
Identificare tutte le dipendenze di terze parti nella catena di fornitura di dati ML/formazione, non solo software "open source", ma anche provider di dati
-Perché si usano e come si verifica la loro attendibilità?
Stai usando modelli preconfigurati da terze parti o inviando dati di addestramento a fornitori MLaaS di terze parti?
Notizie di inventario sugli attacchi su prodotti/servizi simili. Comprendere che molte minacce di intelligenza artificiale/Machine Learning trasferiscono tra tipi di modello, quale impatto potrebbero avere questi attacchi sui propri prodotti?
Minacce e mitigazioni correlate in questo documento
Riprogrammazione reti neurali
Esempi antagonisti nel dominio fisico
Provider di Machine Learning dannosi che recuperano i dati di formazione
Attacco alla catena di approvvigionamento ML
Modello compromesso
Dipendenze specifiche di ML compromesse
Esempi di attacchi
Il provider dannoso di MLaaS infetta il tuo modello con un bypass specifico
Il cliente avversario rileva una vulnerabilità in una dipendenza comune OSS che usi e carica un payload creato di dati di addestramento per compromettere il tuo servizio.
Un partner senza scrupoli usa le API di riconoscimento facciale e crea un livello di presentazione sul servizio per produrre Deep Fakes.
Minacce specifiche dell'intelligenza artificiale e delle relative mitigazioni
Numero 1: Perturbazione avversaria
Descrizione
Negli attacchi in stile di perturbazione, l'utente malintenzionato modifica in modo furtivo la query per ottenere una risposta desiderata da un modello distribuito in produzione[1]. Si tratta di una violazione dell'integrità dell'input del modello che causa attacchi di tipo fuzzing in cui il risultato finale non è necessariamente una violazione di accesso o EOP, ma compromette invece le prestazioni di classificazione del modello. Questo può anche essere manifesto da troll che usano determinate parole di destinazione in modo che l'IA li proibirà, negando efficacemente il servizio a utenti legittimi con un nome corrispondente a una parola "vietata".
 [24]
[24]
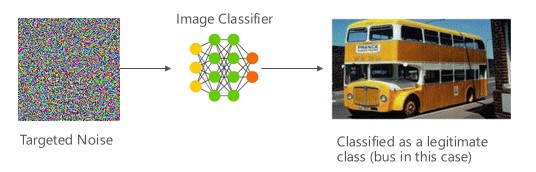
Variante #1a: classificazione errata mirata
In questo caso, gli utenti malintenzionati generano un esempio che non è nella classe di input del classificatore di destinazione, ma viene classificato dal modello come tale classe di input specifica. Il campione antagonista può apparire come rumore casuale agli occhi umani, ma gli attaccanti hanno una certa conoscenza del sistema di Machine Learning di destinazione per generare un rumore bianco che non è casuale, bensì sfrutta aspetti specifici del modello di destinazione. L'avversario fornisce un campione di input che non è un campione legittimo, ma il sistema di riferimento lo classifica come una classe legittima.
Esempi
 [6]
[6]
Soluzioni di prevenzione
Rinforzare la robustezza avversaria utilizzando la fiducia del modello indotta dall'addestramento avversario [19]: gli autori propongono HCNN (Highly Confident Near Neighbor), un framework che combina informazioni di fiducia e ricerca del vicino più vicino, per rafforzare la robustezza avversaria di un modello base. Questo può aiutare a distinguere tra previsioni del modello corrette e errate in una vicinanza di un punto campionato dalla distribuzione di training sottostante.
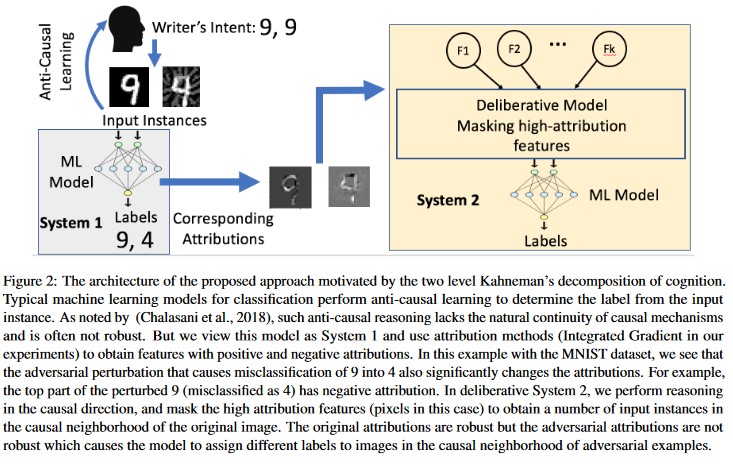
Analisi causale guidata dall'attribuzione [20]: gli autori studiano la connessione tra la resilienza alle perturbazioni antagoniste e la spiegazione basata sull'attribuzione delle singole decisioni generate dai modelli di Machine Learning. Segnalano che gli input antagonisti non sono affidabili nello spazio di attribuzione, ovvero la maschera di alcune funzionalità con un'attribuzione elevata porta a modificare l'indecisione del modello di Machine Learning negli esempi antagonisti. Al contrario, gli input naturali sono affidabili nello spazio di attribuzione.
 [20]
[20]
Questi approcci possono rendere i modelli di Machine Learning più resilienti agli attacchi antagonisti perché ingannare questo sistema di riconoscimento a due livelli richiede non solo attaccare il modello originale, ma anche garantire che l'attribuzione generata per l'esempio antagonista sia simile agli esempi originali. Entrambi i sistemi devono essere compromessi simultaneamente per un attacco antagonista riuscito.
Parallels tradizionali
Elevazione remota dei privilegi dato che l'attaccante ha ora il controllo completo del vostro modello
Severità
Critico
Variant #1b: classificazione errata di origine/destinazione
Questo è caratterizzato da un tentativo da parte di un utente malintenzionato di ottenere un modello per restituire l'etichetta desiderata per un determinato input. Questo di solito costringe un modello a restituire un falso positivo o un falso negativo. Il risultato finale è un sottile controllo dell'accuratezza della classificazione del modello, in cui un attaccante può indurre bypass specifici a volontà.
Anche se questo attacco ha un impatto negativo significativo sull'accuratezza della classificazione, può anche essere più intensivo in termini di tempo, dato che un antagonista non deve solo modificare i dati di origine in modo che non sia più etichettata correttamente, ma anche etichettata in modo specifico con l'etichetta fraudolenta desiderata. Questi attacchi spesso comportano più passaggi/tentativi di forzare la classificazione errata [3]. Se il modello è suscettibile ad attacchi basati su apprendimento trasferibile che forzano la classificazione mirata errata, potrebbe non esserci un footprint di traffico di attaccante rilevabile poiché gli attacchi di esplorazione possono essere eseguiti offline.
Esempi
Costringere i messaggi di posta elettronica innocui a essere classificati come spam o far sì che un esempio dannoso passi inosservato. Questi sono noti anche come attacchi di evasione del modello o attacchi di imitazione.
Soluzioni di prevenzione
Azioni di rilevamento reattive/difensive
- Implementare una soglia di tempo minima tra le chiamate all'API fornendo risultati di classificazione. Questo rallenta i test di attacco in più passaggi aumentando la quantità complessiva di tempo necessaria per trovare una perturbazione riuscita.
Azioni proattive/protettive
Funzionalità di riduzione del rumore per migliorare la robustezza avversaria [22]: gli autori sviluppano una nuova architettura di rete che aumenta la robustezza avversaria eseguendo la riduzione del rumore delle caratteristiche. In particolare, le reti contengono blocchi che densono le funzionalità usando mezzi non locali o altri filtri; l'intera rete viene sottoposta a training end-to-end. In combinazione con l'addestramento antagonista, la funzionalità che denota le reti migliora notevolmente lo stato dell'arte nella robustezza antagonista nelle impostazioni di attacco white box e black-box.
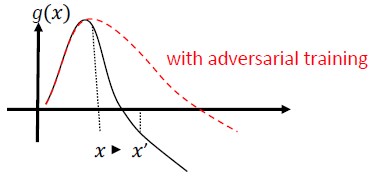
Allenamento e regolarizzazione avversaria: eseguire l'allenamento con esempi avversari noti per creare resilienza e robustezza contro gli input dannosi. Ciò può anche essere considerato come una forma di regolarizzazione, che penalizza la norma delle sfumature di input e rende la funzione di stima del classificatore più uniforme (aumentando il margine di input). Sono incluse le classificazioni corrette con tassi di attendibilità inferiori.
Investire nello sviluppo di una classificazione monotonica con la selezione di caratteristiche monotoniche. In questo modo, l'avversario non sarà in grado di eludere il classificatore semplicemente riempiendo le funzionalità dalla classe negativa [13].
Il feature squeezing [18] può essere usato per rafforzare i modelli DNN rilevando esempi avversari. Riduce lo spazio di ricerca disponibile per un avversario mediante l'unione di campioni che corrispondono a molti vettori di funzionalità diversi nello spazio originale in un singolo campione. Confrontando la stima di un modello DNN sull'input originale con quella sull'input compresso, lo squeing delle funzionalità consente di rilevare esempi antagonisti. Se gli esempi originali e compressi producono output sostanzialmente diversi dal modello, è probabile che l'input sia antagonista. Misurando il disaccordo tra le stime e selezionando un valore soglia, il sistema può restituire la stima corretta per esempi legittimi e rifiuta input antagonisti.

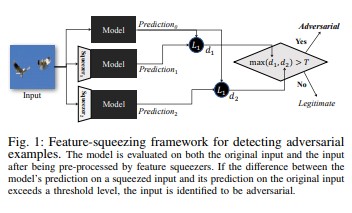 [18]
[18]Difese certificate contro esempi avversari [22]: gli autori propongono un metodo basato su un rilassamento semi-definito che restituisce un certificato che, per una determinata rete e input di test, nessun attacco può forzare l'errore a superare un determinato valore. In secondo luogo, poiché questo certificato è differenziabile, gli autori lo ottimizzano congiuntamente con i parametri di rete, fornendo un regolarizzatore adattivo che incoraggia l'affidabilità contro tutti gli attacchi.
Azioni di risposta
- Genera avvisi sui risultati della classificazione con varianza elevata tra classificatori, soprattutto se da un singolo utente o da un piccolo gruppo di utenti.
Parallels tradizionali
Elevazione remota dei privilegi
Severità
Critico
Variant #1c: errata classificazione casuale
Si tratta di una variante speciale in cui la classificazione dell'obiettivo dell'attaccante può essere qualsiasi cosa tranne la classificazione legittima della fonte. L'attacco comporta in genere l'inserimento casuale di rumore nei dati di origine classificati per ridurre la probabilità che la classificazione corretta venga usata in futuro [3].
Esempi
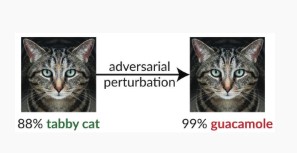
Soluzioni di prevenzione
Uguale a Variant 1a.
Parallels tradizionali
Interruzione del servizio non persistente
Severità
Importante
Variant #1d: Riduzione della confidenza
Un utente malintenzionato può creare input per ridurre il livello di attendibilità della classificazione corretta, in particolare negli scenari con conseguenze elevate. Ciò può anche assumere la forma di un numero elevato di falsi positivi destinati a sovraccaricare gli amministratori o i sistemi di monitoraggio con avvisi fraudolenti indistinguabili da avvisi legittimi [3].
Esempi

Soluzioni di prevenzione
- Oltre alle azioni descritte in Variant #1a, è possibile usare la limitazione degli eventi per ridurre il volume di avvisi da una singola origine.
Parallels tradizionali
Interruzione del servizio non persistente
Severità
Importante
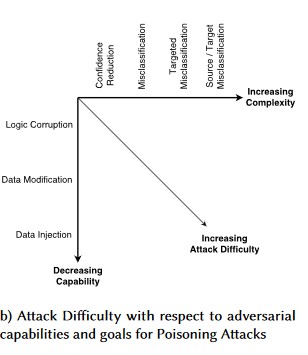
#2a Avvelenamento mirato dei dati
Descrizione
L'obiettivo dell'utente malintenzionato è quello di contaminare il modello di computer generato nella fase di training, in modo che le stime sui nuovi dati vengano modificate nella fase di test[1]. Negli attacchi di avvelenamento mirato, l'utente malintenzionato vuole assegnare erroneamente esempi specifici per eseguire o omettere azioni specifiche.
Esempi
Invio di software AV come malware per forzare la sua errata classificazione come dannoso ed eliminare l'uso di software AV mirato nei sistemi client.
Soluzioni di prevenzione
Definire sensori di anomalia per esaminare la distribuzione dei dati su base giornaliera e avvisare le variazioni
-Misurare la variazione dei dati di training su base giornaliera, telemetria per sbilanciamento/deriva
Convalida dell'input, pulizia e controllo dell'integrità
L'avvelenamento inserisce campioni di training anomali. Due strategie principali per contrastare questa minaccia:
-Sanificazione/validazione dei dati: rimuovere campioni di avvelenamento dai dati di training -Bagging per combattere gli attacchi di avvelenamento [14]
-Rifiuto-attivato-Negative-Impact (RONI) difesa [15]
-Robust Learning: scegliere algoritmi di apprendimento affidabili in presenza di campioni di avvelenamento.
-Uno di questi approcci è descritto in [21] in cui gli autori affrontano il problema dell'avvelenamento dei dati in due passaggi: 1) introducendo un nuovo metodo di factorizzazione della matrice affidabile per recuperare il vero spazio secondario e 2) la regressione affidabile dei principi per eliminare le istanze antagoniste in base alla base recuperata nel passaggio (1). Caratterizzano le condizioni necessarie e sufficienti per ripristinare correttamente il sottospazio reale e presentare un limite alla perdita di previsione prevista rispetto alla verità del terreno.
Parallels tradizionali
Host infettato da trojan in cui l'attaccante si annida nella rete. I dati di addestramento o di configurazione sono compromessi e vengono ingeriti/falsamente considerati affidabili per la creazione del modello.
Severità
Critico
#2b Avvelenamento Indiscriminato dei Dati
Descrizione
L'obiettivo è rovinare la qualità/integrità del set di dati attaccato. Molti set di dati sono pubblici/non affidabili/non curati, quindi ciò crea ulteriori preoccupazioni riguardo alla capacità di individuare tali violazioni dell'integrità dei dati fin dall'inizio. La formazione sui dati inconsapevolmente compromessi rappresenta una situazione di spazzatura dentro/spazzatura fuori. Una volta rilevata, la valutazione deve determinare l'entità dei dati che sono stati violati e la quarantena/ripetizione del training.
Esempi
Un'azienda raschia un sito Web noto e attendibile per i dati dei futures petroliferi per eseguire il training dei propri modelli. Il sito Web del provider di dati viene successivamente compromesso tramite attacchi SQL Injection. L'utente malintenzionato può avvelenare il set di dati a volontà e il modello sottoposto a training non ha alcuna nozione che i dati siano intasati.
Soluzioni di prevenzione
Uguale alla variante 2a.
Parallels tradizionali
Denial of Service autenticato rispetto a un asset di valore elevato
Severità
Importante
#3 Attacchi di inversione del modello
Descrizione
Le funzionalità private usate nei modelli di Machine Learning possono essere recuperate [1]. Ciò include la ricostruzione dei dati di addestramento privati a cui l'utente malintenzionato non ha accesso. Noto anche come attacchi di arrampicata collinare nella community biometrica [16, 17] Questo risultato viene eseguito trovando l'input che ottimizza il livello di attendibilità restituito, soggetto alla classificazione corrispondente alla destinazione [4].
Esempi
 [4]
[4]
Soluzioni di prevenzione
Le interfacce ai modelli addestrati con dati sensibili richiedono un forte controllo d'accesso.
Query con limite di frequenza consentite dal modello
Implementare controlli tra utenti/chiamanti e il modello effettivo eseguendo la convalida di input su tutte le query proposte, rifiutando qualsiasi elemento che non soddisfa la definizione di correttezza dell'input del modello e restituendo solo la quantità minima di informazioni necessarie per essere utili.
Parallels tradizionali
Divulgazione di informazioni mirate e coperte
Severità
Questa impostazione predefinita è importante in base alla barra dei bug SDL standard, ma i dati sensibili o personali estratti generano questo valore come critico.
#4 Attacco di inferenza di appartenenza
Descrizione
L'utente malintenzionato può determinare se un determinato record di dati faceva parte del set di dati di training del modello o meno[1]. I ricercatori sono stati in grado di stimare la procedura principale di un paziente (ad esempio: chirurgia che il paziente ha attraversato) in base agli attributi (ad esempio, età, sesso, ospedale) [1].
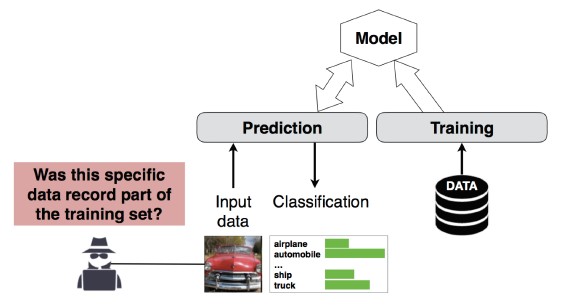 [12]
[12]
Soluzioni di prevenzione
I documenti di ricerca che dimostrano la validità di questo attacco indicano che la privacy differenziale [4, 9] sarebbe una mitigazione efficace. Questo è ancora un campo nascente presso Microsoft e AETHER Security Engineering consiglia di sviluppare competenze con gli investimenti di ricerca in questo spazio. Questa ricerca dovrebbe enumerare le funzionalità di privacy differenziale e valutarne l'efficacia pratica come mitigazioni, quindi progettare modi per queste difese da ereditare in modo trasparente sulle piattaforme dei servizi online, analogamente a come la compilazione del codice in Visual Studio offre on-byprotezioni di sicurezza predefinite trasparenti per gli sviluppatori e gli utenti.
L'uso del dropout dei neuroni e della sovrapposizione di modelli può essere efficace fino a un certo punto. L'uso dell'eliminazione dei neuroni non solo aumenta la resilienza di una rete neurale a questo attacco, ma aumenta anche le prestazioni del modello [4].
Parallels tradizionali
Privacy dei dati. Le inferenze vengono effettuate sull'inclusione di un punto dati nel set di training, ma i dati di training stessi non vengono divulgati
Severità
Si tratta di un problema di privacy, non di un problema di sicurezza. Viene risolto nel materiale sussidiario sulla modellazione delle minacce perché i domini si sovrappongono, ma qualsiasi risposta qui verrebbe guidata dalla privacy, non dalla sicurezza.
#5 Furto di modelli
Descrizione
Gli utenti malintenzionati ricreano il modello sottostante eseguendo query legittime sul modello. La funzionalità del nuovo modello è uguale a quella del modello sottostante[1]. Dopo aver ricreato il modello, può essere invertito per ripristinare le informazioni sulle funzionalità o fare inferenze sui dati di training.
Risoluzione delle equazioni: per un modello che restituisce le probabilità di classe tramite l'output dell'API, un utente malintenzionato può creare query per determinare variabili sconosciute in un modello.
Ricerca di percorsi: un attacco che sfrutta le particolarità dell'API per estrarre le "decisioni" prese da un albero durante la classificazione di un input [7].
Attacco di trasferibilità: un avversario può eseguire il training di un modello locale, possibilmente effettuando query di previsione al modello di destinazione, e usarlo per creare esempi antagonisti che si trasferiscono al modello di destinazione [8]. Se il modello viene estratto e rilevato vulnerabile a un tipo di input antagonista, i nuovi attacchi contro il modello distribuito in produzione possono essere sviluppati completamente offline dall'utente malintenzionato che ha estratto una copia del modello.
Esempi
Nelle impostazioni in cui un modello di Machine Learning serve a rilevare il comportamento antagonista, ad esempio l'identificazione della posta indesiderata, la classificazione malware e il rilevamento anomalie di rete, l'estrazione del modello può facilitare gli attacchi di evasione [7].
Soluzioni di prevenzione
Azioni proattive/protettive
Ridurre o offuscare i dettagli restituiti nelle API di stima mantenendo comunque la loro utilità per le applicazioni "oneste" [7].
Definire una query ben formata per gli input del modello e restituire solo i risultati in risposta a input completati e ben formati corrispondenti a tale formato.
Restituisce valori di confidenza arrotondati. La maggior parte dei chiamanti legittimi non necessita di più posizioni decimali di precisione.
Parallels tradizionali
Manomissione non autenticata e di sola lettura dei dati di sistema, divulgazione di informazioni di alto valore mirate?
Severità
Importante nei modelli sensibili alla sicurezza, moderato altrimenti
N. 6 Riprogrammazione rete neurale
Descrizione
Tramite una query appositamente creata da un avversario, i sistemi di Machine Learning possono essere riprogrammati in un'attività che devia dalla finalità originale dell'autore [1].
Esempi
Controlli di accesso deboli su un'API di riconoscimento facciale che consentono a parti terze di integrarla in app progettate per danneggiare i clienti Microsoft, come un generatore di deep fake.
Soluzioni di prevenzione
Autenticazione reciproca client-server<> avanzata e controllo di accesso alle interfacce del modello
Rimozione degli account offensivi.
Identificare e applicare un contratto di servizio per le API. Determinare il tempo di correzione accettabile per un problema una volta segnalato e assicurarsi che il problema non venga più restituito dopo la scadenza del contratto di servizio.
Parallels tradizionali
Questo è uno scenario di abuso. È meno probabile che si apra un evento di sicurezza che si disabiliti semplicemente l'account dell'autore del reato.
Severità
Da Importante a Critico
Esempio avversario nel dominio fisico (da bit a atomi)
Descrizione
Un esempio antagonista è un input/query da un'entità dannosa inviata con l'unico scopo di ingannare il sistema di Machine Learning [1]
Esempi
Questi esempi possono manifestarsi nel dominio fisico, ad esempio un'auto a guida autonoma che viene ingannata a superare un segnale di stop a causa di un determinato colore di luce (l'input antagonista) che viene proiettato sul segnale di stop, forzando il sistema di riconoscimento delle immagini a non vedere più il segnale di stop come segnale di stop.
Parallels tradizionali
Elevazione dei privilegi, esecuzione di codice remoto
Soluzioni di prevenzione
Questi attacchi si manifestano perché i problemi nel livello di Machine Learning (il livello dell'algoritmo e dei dati al di sotto del processo decisionale basato sull'intelligenza artificiale) non sono stati mitigati. Come per qualsiasi altro sistema fisico *o* software, il livello al di sotto della destinazione può sempre essere attaccato tramite vettori tradizionali. Per questo motivo, le procedure di sicurezza tradizionali sono più importanti che mai, soprattutto con il livello di vulnerabilità non rilevate (il livello dati/algo) usato tra l'IA e il software tradizionale.
Severità
Critico
#8 Provider di Machine Learning dannosi che possono recuperare i dati di addestramento
Descrizione
Un provider malintenzionato presenta un algoritmo con una backdoor, che consente di recuperare i dati di addestramento privati. Sono stati in grado di ricostruire visi e testi, partendo solo dal modello.
Parallels tradizionali
Divulgazione di informazioni mirate
Soluzioni di prevenzione
I documenti di ricerca che dimostrano la validità di questo attacco indicano che la crittografia omomorfica sarebbe una mitigazione efficace. Si tratta di un'area con poco investimento attuale in Microsoft e AETHER Security Engineering consiglia di sviluppare competenze con investimenti di ricerca in questo spazio. Questa ricerca dovrebbe enumerare i principi della Crittografia Omomorfica e valutarne l'efficacia pratica come mitigazioni nei confronti di provider ML-as-a-Service dannosi.
Severità
Importante se i dati sono informazioni personali identificabili, Moderato in caso contrario
#9 Attacco alla supply chain di ML
Descrizione
A causa di risorse di grandi dimensioni (dati e calcolo) necessari per eseguire il training degli algoritmi, la procedura corrente consiste nel riutilizzare i modelli sottoposti a training da grandi aziende e modificarli leggermente per le attività a portata di mano (ad esempio ResNet è un modello di riconoscimento delle immagini diffuso di Microsoft). Questi modelli sono curati in un "Model Zoo" (Caffe ospita modelli di riconoscimento delle immagini più popolari). In questo attacco, l'avversario attacca i modelli ospitati in Caffe, avvelenando così il pozzo per chiunque altro. [1]
Parallels tradizionali
Compromissione delle dipendenze di terze parti non relative alla sicurezza
Lo store di app ospita malware inconsapevolmente
Soluzioni di prevenzione
Ridurre al minimo le dipendenze di terze parti per i modelli e i dati laddove possibile.
Incorporare queste dipendenze nel processo di modellazione delle minacce.
Utilizzare l'autenticazione avanzata, il controllo di accesso e la crittografia tra sistemi di prima/terza parte.
Severità
Critico
Machine Learning backdoor numero 10
Descrizione
Il processo di training viene esternalizzato a una terza parte malintenzionata che manomette i dati di training e ha fornito un modello trojaned che forza le classificazioni errate mirate, ad esempio classificando un determinato virus come non dannoso[1]. Si tratta di un rischio negli scenari di generazione di modelli ML-as-a-Service.
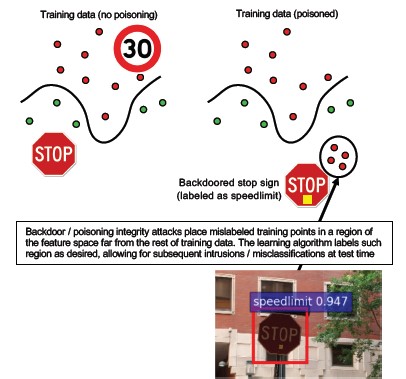 [12]
[12]
Parallels tradizionali
Compromissione delle dipendenze di sicurezza di terze parti
Meccanismo di aggiornamento software compromesso
Compromissione dell'autorità di certificazione
Soluzioni di prevenzione
Azioni di rilevamento reattive/difensive
- Il danno è già stato fatto dopo che questa minaccia è stata individuata, quindi il modello e tutti i dati di training forniti dal provider dannoso non possono essere considerati attendibili.
Azioni proattive/protettive
Eseguire il training di tutti i modelli sensibili internamente
Catalogare i dati di training o assicurarsi che provenga da terze parti attendibili con procedure di sicurezza avanzate
Modella la minaccia nell'interazione tra il provider MLaaS e i tuoi sistemi
Azioni di risposta
- Come nel caso di compromissione della dipendenza esterna
Severità
Critico
#11 Sfruttare le dipendenze software del sistema di Machine Learning
Descrizione
In questo attacco, l'utente malintenzionato non modifica gli algoritmi. Sfrutta invece vulnerabilità software come overflow del buffer o scripting tra siti[1]. È ancora più facile compromettere i livelli software sotto L'intelligenza artificiale/Machine Learning rispetto all'attacco diretto del livello di apprendimento, quindi le tradizionali procedure di mitigazione delle minacce per la sicurezza descritte in dettaglio nel ciclo di vita dello sviluppo della sicurezza sono essenziali.
Parallels tradizionali
Dipendenza da software open source compromessa
Vulnerabilità del server Web (XSS, CSRF, errore di convalida dell'input API)
Soluzioni di prevenzione
Collaborare con il team di sicurezza per seguire le procedure consigliate applicabili per il ciclo di vita dello sviluppo della sicurezza/sicurezza operativa.
Severità
Variabile; Fino a critico a seconda del tipo di vulnerabilità del software tradizionale.
Bibliografia
[1] Modalità di errore in Machine Learning, Ram Shankar Siva Kumar, David O'Brien, Kendra Albert, Salome Viljoen e Jeffrey Snover, https://learn.microsoft.com/security/failure-modes-in-machine-learning
[2] AETHER Security Engineering Workstream, Data Provenance/Derivazione v-team
[3] Esempi avversari nel Deep Learning: Caratterizzazione e Divergenza, Wei, et al, https://arxiv.org/pdf/1807.00051.pdf
[4] ML-Leaks: attacchi e difese di inferenza di appartenenza indipendenti dai modelli e dai dati di Machine Learning, Salem, et al, https://arxiv.org/pdf/1806.01246v2.pdf
[5] M. Fredrikson, S. Jha e T. Ristenpart, "Attacchi di inversione del modello che sfruttano informazioni di fiducia e contromisure di base", nei Atti della conferenza ACM SIGSAC 2015 sulla sicurezza informatica e delle comunicazioni (CCS).
[6] Nicolas Papernot e Patrick McDaniel - Esempi avversari nel Machine Learning AIWTB 2017
[7] Furto di modelli di Machine Learning tramite le API di previsione, Florian Tramèr, École Polytechnique Fédérale de Lausanne (EPFL); Fan Zhang, Cornell University; Ari Juels, Cornell Tech; Michael K. Reiter, Università della Carolina del Nord a Chapel Hill; Thomas Ristenpart, Cornell Tech
[8] Lo spazio degli esempi antagonisti trasferibili, Florian Tramèr, Nicolas Papernot, Ian Goodfellow, Dan Boneh e Patrick McDaniel
[9] Comprensione delle inferenze di appartenenza nei modelli di apprendimento Well-Generalized Yunhui Long1 , Vincent Bindschaedler1 , Lei Wang2 , Diyue Bu2 , Xiaofeng Wang2 , Haixu Tang2 , Carl A. Gunter1 e Kai Chen3,4
[10] Simon-Gabriel et al., la vulnerabilità antagonista delle reti neurali aumenta con la dimensione di input, ArXiv 2018;
[11] Lyu et al., Famiglia di regolarizzazione gradiente unificata per esempi adversariali, ICDM 2015
[12] Wild Patterns: Ten Years After the Rise of Adversarial Machine Learning - NeCS 2019 Battista Biggioa, Fabio Roli
[13] Rilevamento malware robusto contro attacchi adversariali utilizzando la classificazione monotona Inigo Incer et al.
[14] Battista Biggio, Igino Corona, Giorgio Fumera, Giorgio Giacinto e Fabio Roli. Classificatori di bagging per combattere gli attacchi di avvelenamento nelle attività di classificazione antagonista
[15] Un miglioramento nel rifiuto per la difesa contro impatti negativi Hongjiang Li e Patrick P.K. Chan
[16] Adler. Vulnerabilità nei sistemi di crittografia biometrica. 5° Conferenza Internazionale AVBPA, 2005
[17] Galbally, McCool, Fierrez, Marcel, Garcia-Garcia. Sulla vulnerabilità dei sistemi di verifica dei volti agli attacchi in salita. Patt. Rec., 2010
Weilin Xu, David Evans, Yanjun Qi. Squeezing delle funzionalità: rilevamento di esempi antagonisti nelle reti neurali profonde. 2018 Network and Distributed System Security Symposium. 18-21 febbraio.
[19] Rinforzo della robustezza avversaria con la fiducia del modello indotta dall'addestramento avversario - Xi Wu, Uyeong Jang, Jiefeng Chen, Lingjiao Chen, Somesh Jha
[20] Analisi causale guidata dall'attribuzione per il rilevamento di esempi avversari, Susmit Jha, Sunny Raj, Steven Fernandes, Sumit Kumar Jha, Somesh Jha, Gunjan Verma, Brian Jalaian, Ananthram Swami
[21] Regressione lineare robusta contro l'avvelenamento dei dati di addestramento – Chang Liu et al.
[22] Distorzione delle caratteristiche per migliorare la robustezza avversaria, Cihang Xie, Yuxin Wu, Laurens van der Maaten, Alan Yuille, Kaiming He
[23] Difese certificate contro esempi antagonisti - Aditi Raghunathan, Jacob Steinhardt, Percy Liang