Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Il kernel semantico fornisce molti componenti diversi, che possono essere usati singolarmente o insieme. Questo articolo offre una panoramica dei diversi componenti e illustra la relazione tra di esse.
Connettori per servizi di intelligenza artificiale
I connettori del kernel di intelligenza artificiale semantica forniscono un livello di astrazione che espone più tipi di servizi di intelligenza artificiale da provider diversi tramite un'interfaccia comune. I servizi supportati includono completamento chat, generazione di testo, generazione di embedding, conversione da testo a immagine, conversione da immagine a testo, conversione da testo ad audio e da audio a testo.
Quando un'implementazione è registrata nel Kernel, i servizi di completamento chat o generazione di testo vengono usati per impostazione predefinita da qualsiasi chiamata di metodo al kernel. Nessuno degli altri servizi supportati verrà usato automaticamente.
Consiglio
Per altre informazioni sull'uso dei servizi di intelligenza artificiale, vedere Aggiunta di servizi di intelligenza artificiale al kernel semantico.
Connettori di archiviazione vettoriale (memoria)
I connettori del Kernel Semantico per gli archivi vettoriali forniscono un livello di astrazione che espone archivi vettoriali da diversi provider tramite un'interfaccia comune. Il kernel non utilizza automaticamente alcun archivio vettoriale registrato, ma la Ricerca Vettoriale può essere facilmente esposta come plug-in al kernel, nel qual caso il plug-in viene reso disponibile per i modelli di invito e per il modello di intelligenza artificiale per il completamento della chat.
Consiglio
Per ulteriori informazioni sull'uso dei connettori di memoria, consultare Aggiunta dei servizi di intelligenza artificiale al kernel semantico.
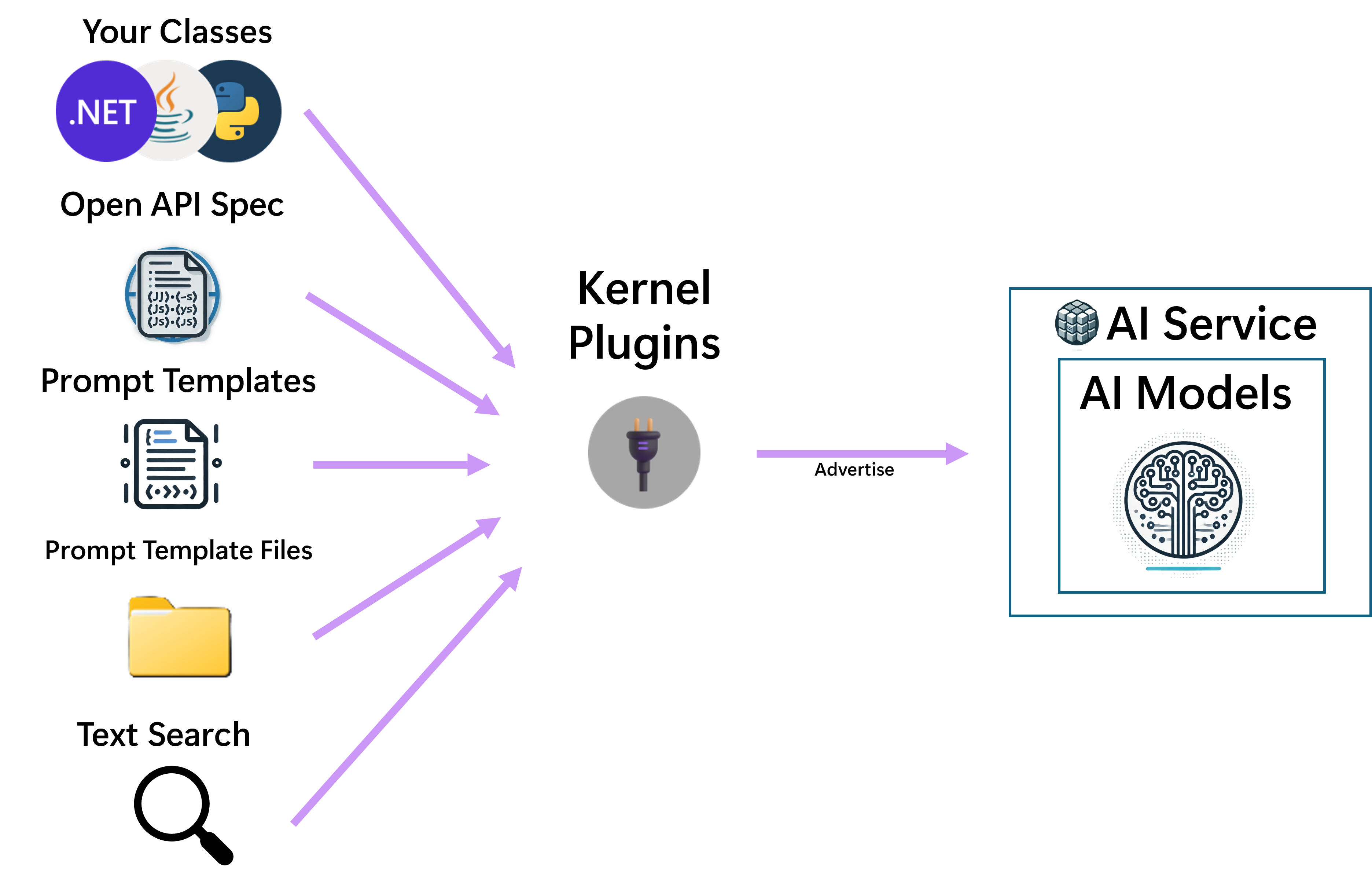
Funzioni e plugin
I plugin sono contenitori di funzioni nominati. Ognuno può contenere una o più funzioni. I plug-in possono essere registrati con il kernel, che consente al kernel di usarli in due modi:
- Comunicarli all'intelligenza artificiale di completamento della chat, in modo che l'intelligenza artificiale possa sceglierli per l'invocazione.
- Renderli disponibili per essere chiamati da un modello durante il rendering del modello.
Le funzioni possono essere create facilmente da molte origini, tra cui codice nativo, specifiche OpenAPI, implementazioni ITextSearch per gli scenari RAG, ma anche dai modelli di richiesta.
Mancia
Per altre informazioni sulle diverse origini di plug-in, vedere Che cos'è un plug-in?.
Suggerimento
Per altre informazioni sui plug-in pubblicitari per l'intelligenza artificiale di completamento della chat, vedere Chiamata di funzione con completamento della chat.
Modelli di prompt
I modelli di prompt consentono a uno sviluppatore o a un tecnico del prompt di creare un modello che combina il contesto e le istruzioni per l'intelligenza artificiale con l'input utente e l'output della funzione. Ad esempio, il template può contenere istruzioni per il modello di intelligenza artificiale di completamento chat, segnaposti per l'input degli utenti e chiamate codificate in modo fisso ai plug-in, che devono sempre essere eseguite prima di richiamare il modello di intelligenza artificiale di completamento chat.
I modelli di prompt possono essere usati in due modi:
- Come punto di partenza di un flusso di completamento della chat chiedendo al kernel di eseguire il rendering del template e di invocare il modello di intelligenza artificiale per il completamento della chat con il risultato reso.
- Come funzione plug-in, in modo che possa essere richiamato nello stesso modo in cui può essere richiamata qualsiasi altra funzione.
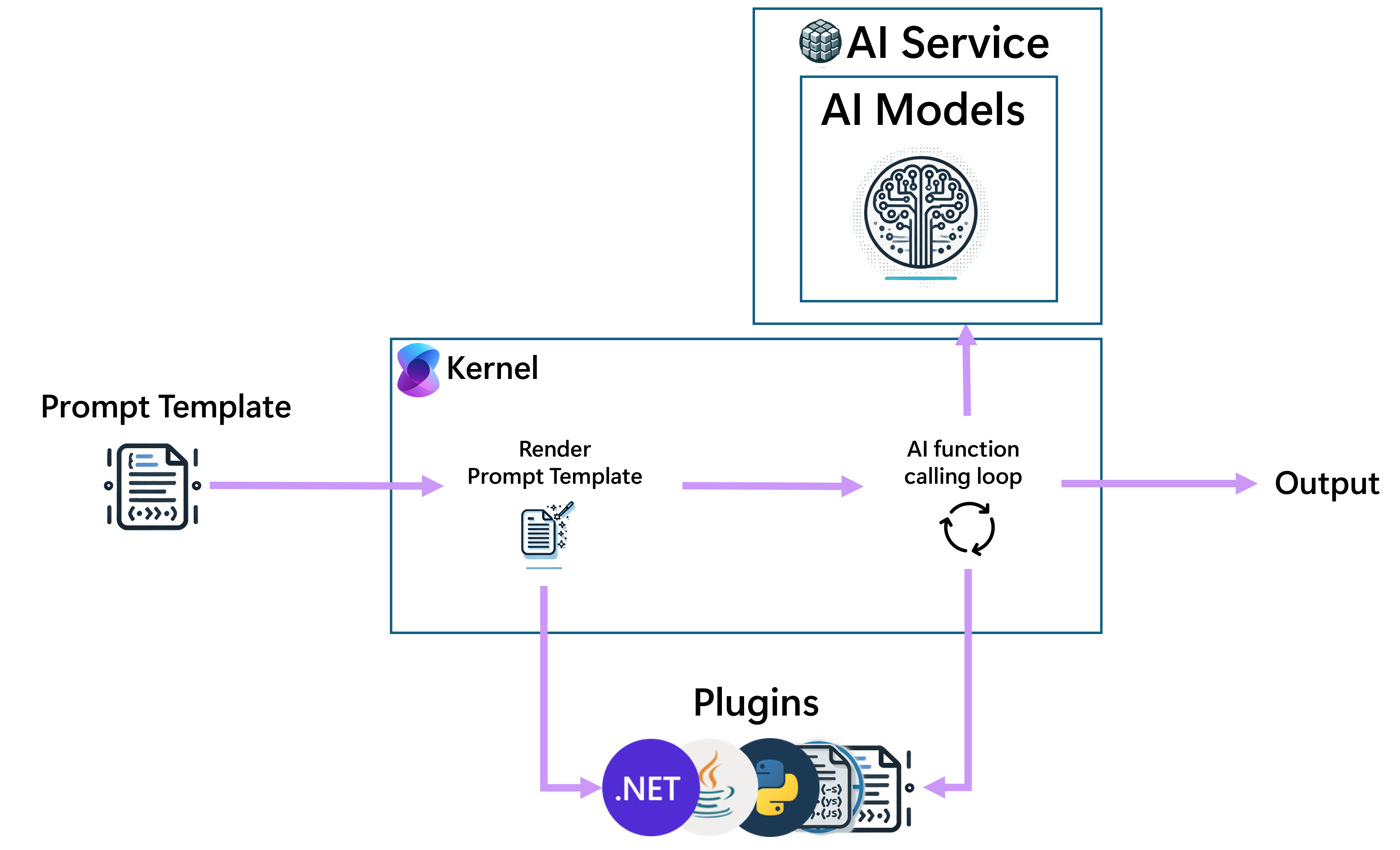
Quando viene utilizzato un modello di richiesta, verrà innanzitutto eseguito il rendering, ed eventuali riferimenti a funzioni hardcoded che contiene saranno eseguiti. Il prompt reso verrà quindi passato al modello di intelligenza artificiale di completamento della chat. Il risultato generato dall'intelligenza artificiale verrà restituito al chiamante. Se il modello di prompt era stato registrato come funzione plugin, la funzione potrebbe essere stata scelta per l'esecuzione dal modello AI di Chat Completion e, in questo caso, il chiamante è Semantic Kernel per conto del modello di AI.
L'uso di modelli di prompt come funzioni plug-in in questo modo può comportare flussi piuttosto complessi. Si consideri ad esempio lo scenario in cui un template di prompt A viene registrato come plugin.
Allo stesso tempo, un modello di prompt diverso B può essere passato al kernel per avviare il processo di completamento della chat.
B potrebbe avere una chiamata codificata fissa a A.
Di conseguenza, i passaggi seguenti sono i seguenti:
- Quando inizia il rendering di
B, l'esecuzione del prompt trova un riferimento aA. - Il rendering di
Aviene eseguito. - Il risultato reso di
Aviene passato al modello di intelligenza artificiale di completamento della chat. - Il risultato del modello di intelligenza artificiale di completamento della chat viene restituito a
B. - Rendering del
Bcompletato. - L'output renderizzato di
Bviene passato al modello di intelligenza artificiale di completamento-chat. - Il risultato del modello di intelligenza artificiale Completamento chat viene restituito al chiamante.
Considera anche lo scenario in cui non è presente alcuna chiamata codificata da B a A.
Se la chiamata di funzione è abilitata, il modello di intelligenza artificiale di completamento chat può comunque decidere che A deve essere richiamato perché richiede dati o funzionalità che A può fornire.
La registrazione dei modelli di richiesta come funzioni plug-in consente di creare funzionalità descritte usando il linguaggio umano anziché il codice effettivo. La separazione delle funzionalità in un plug-in come questo consente al modello di intelligenza artificiale di ragionare separatamente rispetto al flusso di esecuzione principale, e può portare a tassi di successo più elevati per il modello di intelligenza artificiale, poiché può concentrarsi su un singolo problema alla volta.
Guarda il diagramma seguente per un flusso semplice avviato da un modello di avvio.
Mancia
Per altre informazioni sui modelli di suggerimenti, vedere Quali sono le richieste?.
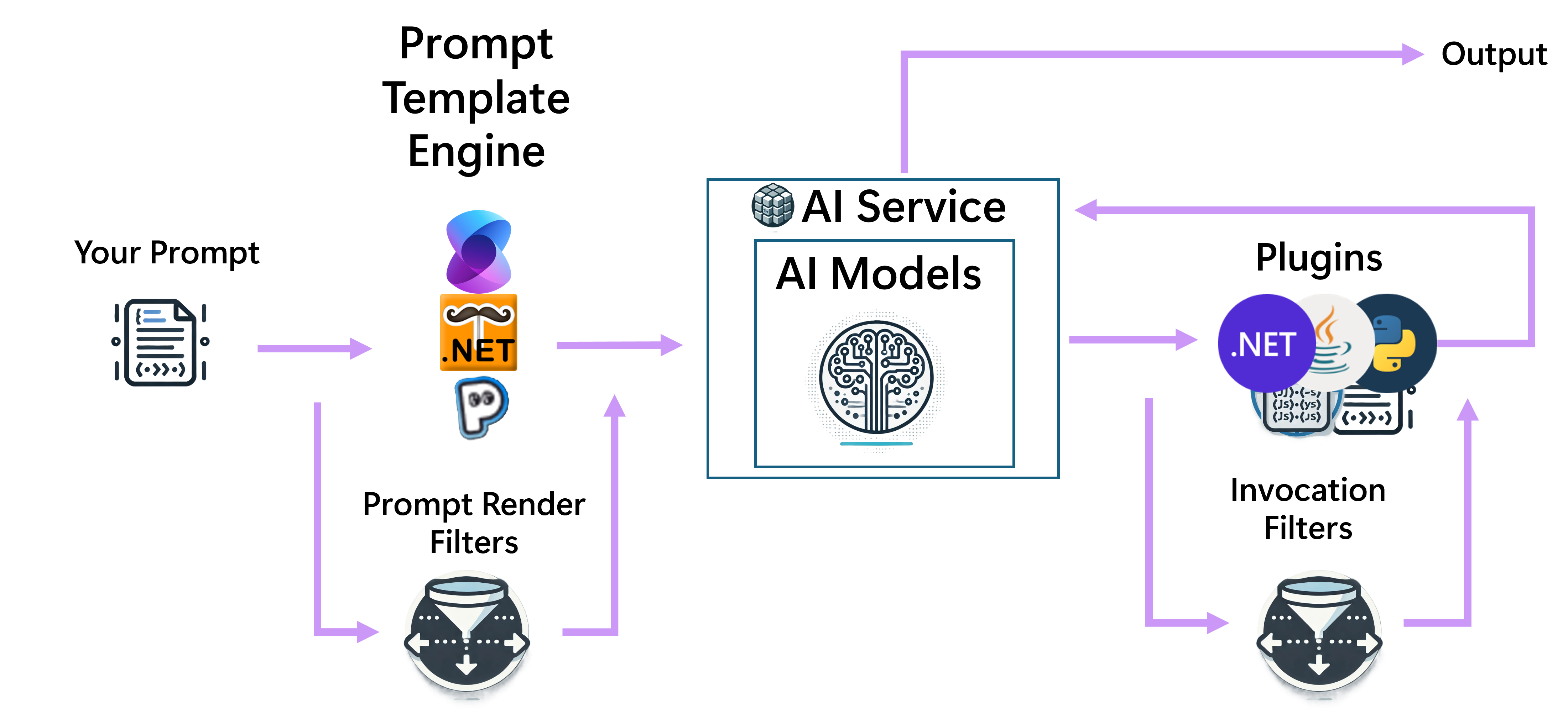
Filtri
I filtri consentono di eseguire azioni personalizzate prima e dopo eventi specifici durante il flusso di completamento della chat. Questi eventi includono:
- Prima e dopo la chiamata di funzione.
- Prima e dopo il rendering del prompt.
I filtri devono essere registrati con il kernel per essere richiamati durante il flusso di completamento della chat.
Si noti che, poiché i modelli di prompt vengono sempre convertiti in KernelFunctions prima dell'esecuzione, sia i filtri di funzione che quelli di prompt verranno richiamati per un modello di prompt. Poiché i filtri sono annidati quando sono disponibili più filtri, i filtri di funzione sono i filtri esterni e i filtri prompt sono i filtri interni.
Suggerimento
Per altre informazioni sui filtri, vedere Che cosa sono i filtri?.