Funzionamento e linee guida per i timeout lease, cluster e controllo integrità per i gruppi di disponibilità Always On
Le differenze nell'hardware, nel software e nelle configurazioni cluster, nonché le diverse esigenze di disponibilità e prestazioni delle applicazioni richiedono una configurazione specifica per i timeout controllo integrità, cluster e lease. Alcune applicazioni e carichi di lavoro richiedono un monitoraggio più aggressivo per limitare il tempo di inattività dopo gli errori hardware. Altre situazioni registrano una maggior tolleranza per i problemi di rete temporanei e le attese dovute all'uso intensivo delle risorse e possono accettare failover più lenti.
Vari servizi rilevano attivamente gli errori su ogni nodo. Il servizio cluster può rilevare la perdita di quorum, la DLL della risorsa può rilevare un problema associato al rilevamento integrità Always On oppure il failover manuale potrebbe essere avviato direttamente sull'istanza principale. Il servizio cluster, l'host di risorse e l'istanza di SQL Server si sincronizzano tra loro tramite RPC, memoria condivisa e T-SQL. Nella maggior parte degli scenari questi servizi comunicano correttamente. Tuttavia questa comunicazione non è del tutto affidabile anche tra servizi nello stesso computer. Il gruppo di disponibilità (AG) deve anche essere in grado di risolvere eventi che hanno effetto sull'intero sistema, ad esempio errori di rete e disco, che potrebbero impedire la comunicazione o compromettere la funzionalità. Con molti casi di errore e senza una comunicazione completamente affidabile tra i servizi, il gruppo di disponibilità dipende da vari meccanismi di rilevamento di failover per rilevare e rispondere ai singoli errori in modo indipendente, perché lo stato del cluster sia sempre coerente per tutti i nodi.
Nodo cluster e rilevamento delle risorse
Ogni nodo del cluster esegue un singolo servizio cluster, che gestisce il cluster di failover e controlla tutte le risorse del cluster. L'host di risorse funziona come processo separato ed è l'interfaccia tra il servizio cluster e le risorse del cluster. L'host di risorse esegue operazioni sulle risorse del cluster quando viene chiamato dal servizio cluster. Le applicazioni che supportano i cluster, come SQL Server, rendono disponibili interfacce personalizzate al monitoraggio risorse tramite le DLL della risorsa. La DLL della risorsa implementa operazioni online e offline e il monitoraggio dello stato per le risorse personalizzate. L'host di risorse è un processo figlio del servizio cluster e viene terminato ogni volta che viene terminato il servizio cluster.
Per SQL Server la DLL della risorsa del gruppo di disponibilità determina l'integrità del gruppo sulla base del meccanismo di lease del gruppo di disponibilità e del rilevamento di integrità Always On. La DLL della risorsa del gruppo di disponibilità espone lo stato di integrità della risorsa tramite l'operazione IsAlive. Il monitoraggio risorse esegue il polling di IsAlive all'intervallo di heartbeat del cluster, impostato dai valori CrossSubnetDelay e SameSubnetDelay validi nell'intero cluster. Su un nodo primario il servizio cluster avvia i failover ogni volta che la chiamata IsAlive alla DLL della risorsa indica che il gruppo di disponibilità non è integro.
Il servizio cluster invia heartbeat ad altri nodi del cluster e riconosce gli heartbeat che riceve da tali nodi. Quando un nodo rileva un errore di comunicazione per una serie di heartbeat non riconosciuti, trasmette un messaggio in seguito al quale tutti i nodi raggiungibili riconciliano le loro visualizzazioni dell'integrità del nodo cluster. Questo evento, detto evento regroup, mantiene la coerenza dello stato del cluster nei nodi. Se in seguito a un evento regroup si verifica la perdita del quorum, tutte le risorse del cluster in questa partizione vengono disconnesse, inclusi i gruppi di disponibilità. Tutti i nodi della partizione vengono trasferiti a uno stato di risoluzione in corso. Se è presente una partizione che contiene un quorum, il gruppo di disponibilità viene assegnato a un nodo nella partizione e diventa la replica primaria, mentre tutti gli altri nodi diventano repliche secondarie.
Rilevamento dell'integrità Always On
La DLL della risorsa Always On esegue il monitoraggio dello stato dei componenti interni di SQL Server. sp_server_diagnostics segnala l'integrità SQL Server di questi componenti in un intervallo controllato da HealthCheckTimeout. sp_server_diagnostics segnala lo stato di integrità di cinque componenti di livello istanza: sistema, risorsa, elaborazione query, sottosistema I/O ed eventi. Segnala anche l'integrità di ogni gruppo di disponibilità. A ogni aggiornamento, la DLL della risorsa aggiorna lo stato di integrità della risorsa gruppo di disponibilità in base al livello di errore del gruppo di disponibilità. Quando i dati vengono restituiti da sp_server_diagnostics, ogni componente viene visualizzato con stato normale, avviso, errore o sconosciuto e con dati XML che descrivono lo stato del componente. Per il rilevamento dell'integrità, la DLL della risorsa si attiva solo se un componente restituisce uno stato di errore.
Se il rilevamento dell'integrità non segnala un aggiornamento alla DLL della risorsa per vari intervalli, il gruppo di disponibilità viene considerato come non integro e restituisce errori nelle chiamate IsAlive.
Meccanismo lease
A differenza di quanto accade in altri meccanismi di failover, nel meccanismo lease l'istanza di SQL Server svolge un ruolo attivo. Il meccanismo lease viene usato come convalida "Looks Alive" tra l'host risorse cluster e il processo di SQL Server. Con il meccanismo ci si assicura che i due lati, cioè il servizio cluster e il servizio SQL Server, abbiano contatti frequenti e che si controllino a vicenda lo stato per impedire, in definitiva, uno scenario split brain. Quando si porta online il gruppo di disponibilità online come replica primaria, l'istanza di SQL Server genera un thread di lavoro lease dedicato per il gruppo di disponibilità. Il ruolo di lavoro lease condivide una piccola area della memoria con l'host di risorse contenente eventi lease di arresto e rinnovo. Il ruolo di lavoro lease e l'host di risorse funzionano in modo circolare, segnalando il rispettivo evento di rinnovo lease e quindi diventando inattivi in attesa che l'altro elemento segnali il proprio evento di rinnovo lease o di arresto. Sia l'host di risorse che il thread lease di SQL Server gestiscono un valore time-to-live, che viene aggiornato ogni volta che il thread si attiva con la segnalazione dell'altro thread. Se il time-to-live viene raggiunto durante l'attesa del segnale, il lease scade e la replica esegue la transizione allo stato di risoluzione per il gruppo di disponibilità specifico. Se viene segnalato l'evento di arresto lease, la replica esegue la transizione a un ruolo di risoluzione.
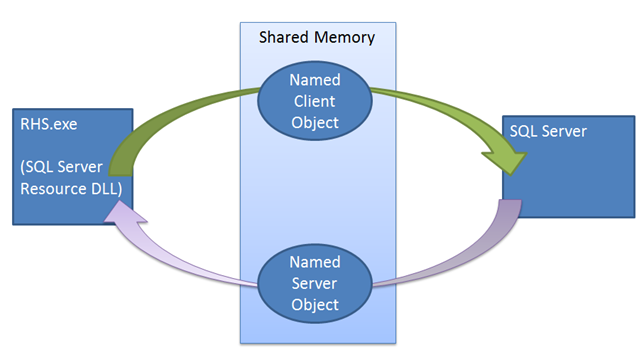
Il meccanismo lease applica la sincronizzazione tra SQL Server e il cluster di failover di Windows Server. Quando viene eseguito un comando di failover, il servizio cluster esegue una chiamata Offline alla DLL della risorsa della replica primaria corrente. Prima la risorsa DLL prova a portare offline il gruppo di disponibilità tramite una stored procedure. Se la stored procedure ha esito negativo o registra un timeout, l'errore viene segnalato al servizio cluster, che esegue un comando di interruzione. Anche tale comando prova a eseguire la stessa stored procedure, ma questa volta il cluster non attende che la DLL della risorsa segnali la riuscita o l'errore prima di portare online il gruppo di disponibilità su una nuova replica. Se questa seconda chiamata di procedura ha esito negativo, l'host di risorse deve fare affidamento sul meccanismo lease per portare offline l'istanza. Quando la DLL della risorsa viene chiamata per portare offline il gruppo di disponibilità la DLL della risorsa segnala l'evento di arresto lease, attivando il thread di lavoro lease di SQL Server per portare offline il gruppo di disponibilità. Anche se questo evento di arresto non viene segnalato, il lease scade e la replica passa allo stato di risoluzione.
Il lease è principalmente un meccanismo di sincronizzazione tra l'istanza primaria e il cluster, ma può anche creare condizioni di errore in casi per cui non sarebbe stato necessario eseguire il failover. Ad esempio, utilizzo della CPU elevato, condizioni di memoria insufficiente (scarsa memoria virtuale, paging dei processi), mancata risposta da parte del processo SQL durante la generazione di un dump della memoria, mancata risposta del sistema, cluster (WSFC) offline a causa della perdita del quorum possono impedire il rinnovo del lease da parte dell'istanza SQL Server e causare un riavvio o un failover.
Linee guida per i valori di timeout cluster
Considerare con cura i vantaggi, gli svantaggi e le conseguenze dell'uso di un monitoraggio meno rigido del cluster di SQL Server. Se si incrementano i valori di timeout cluster, aumenta la tolleranza per i problemi di rete temporanei, ma la reazione agli errori hardware richiede più tempo. Anche l'incremento dei timeout per gestire la pressione sulle risorse o la latenza geografica estesa determina un aumento del tempo necessario per il recupero dagli errori hardware o irreversibili. Questo è accettabile per molte applicazioni, ma non è ideale in tutti i casi.
Le impostazioni predefinite sono ottimizzate per una reazione rapida ai sintomi di errori hardware e per la limitazione dei tempi di inattività, ma queste impostazioni possono rivelarsi eccessivamente aggressive per determinati carichi di lavoro e configurazioni. Non è consigliabile ridurre le impostazioni di LeaseTimeout, CrossSubnetDelay, CrossSubnetThreshold, SameSubnetDelay, SameSubnetThreshold o HealthCheckTimeout al di sotto dei valori predefiniti. Le impostazioni corrette per ogni distribuzione variano e la loro definizione può richiedere un periodo di messa a punto prolungato. Quando si apportano modifiche a uno di questi valori è necessario apportarle gradualmente, tenendo in considerazione le relazioni e le dipendenze tra i valori.
Relazione tra timeout cluster e timeout lease
La funzione primaria del meccanismo lease è di portare offline la risorsa di SQL Server quando il servizio cluster non può comunicare con l'istanza durante l'esecuzione di un failover a un altro nodo. Quando il cluster esegue l'operazione offline sulla risorsa cluster del gruppo di disponibilità, il servizio cluster esegue una chiamata RPC a rhs.exe per portare offline la risorsa. La DLL della risorsa usa le stored procedure per indicare a SQL Server di portare offline il gruppo di disponibilità, ma questa stored procedure potrebbe non riuscire o registrare un timeout. L'host della risorsa interrompe anche il proprio thread di rinnovo del lease durante la chiamata offline. Nel peggiore dei casi, SQL Server causa la scadenza del lease entro ½ * LeaseTimeout ed esegue la transizione dell'istanza a uno stato di risoluzione. I failover possono essere avviati da entità diverse, ma è importante che la visualizzazione dello stato del cluster sia coerente nelle diverse istanze cluster e nelle istanze di SQL Server. Considerare ad esempio uno scenario in cui l'istanza primaria perde la connessione al resto del cluster. Ogni nodo del cluster determina un errore in orari simili a causa dei valori di timeout cluster, ma solo il nodo primario può interagire con l'istanza di SQL Server primaria per imporre la rinuncia al ruolo primario.
Dal punto di vista del nodo primario, il servizio cluster ha perso il quorum e il servizio inizia la procedura di chiusura. Il servizio cluster rilascia una chiamata RPC all'host di risorse per terminare il processo. Questa chiamata di terminazione è quella che porta offline il gruppo di disponibilità nell'istanza di SQL Server. Questa chiamata offline viene eseguita tramite T-SQL, ma non può garantire che verrà stabilita una connessione tra SQL e la DLL della risorsa.
Dal punto di vista del resto del cluster, al momento non è presente alcuna replica primaria e il cluster vota e stabilisce una nuova replica primaria singola per i nodi restanti nel cluster. Se la stored procedure che è stata chiamata dalla DLL della risorsa ha esito negativo o registra un timeout, il cluster potrebbe essere vulnerabile a uno scenario split brain.
Il timeout lease evita gli scenari di tipo split brain a fronte di errori di comunicazione. Anche se tutte le comunicazioni hanno esito negativo, il processo della DLL della risorsa termina e non è in grado di aggiornare il lease. Dopo la scadenza del lease, il processo porta offline autonomamente il gruppo di disponibilità. L'istanza di SQL Server deve rilevare che non ospita più la replica primaria prima che il cluster ne stabilisca una nuova. Poiché il resto del cluster, responsabile della scelta di una nuova replica primaria, non è in grado di coordinare con la replica primaria corrente, i valori di timeout garantiscono che non venga impostata una nuova replica primaria fino a quando la replica primaria corrente non assume lo stato offline.
Quando il cluster esegue il failover, l'istanza di SQL Server che ospita la replica primaria precedente deve eseguire la transizione a uno stato di risoluzione prima che la nuova replica primaria assuma lo stato online. Il thread di lease di SQL Server ha in qualsiasi momento un time-to-live pari a ½ * LeaseTimeout, perché ogni volta che il lease viene rinnovato il nuovo time-to-live viene aggiornato a LeaseInterval o a ½ * LeaseTimeout. Se il servizio cluster o l'host di risorse si blocca o termina senza segnalare l'evento di arresto del lease, il cluster dichiara il nodo primario inattivo dopo SameSubnetThreshold\ SameSubnetDelay millisecondi. Entro questo intervallo il lease deve scadere, per garantire che la replica primaria sia offline. Poiché il time-to-live massimo per il timeout lease è ½ * LeaseTimeout, ½ * LeaseTimeout deve essere minore di SameSubnetThreshold * SameSubnetDelay.
SameSubnetThreshold \<= CrossSubnetThreshold e SameSubnetDelay \<= CrossSubnetDelay devono essere true per tutti i cluster SQL Server.
Operazione d timeout controllo integrità
Il timeout controllo integrità è più flessibile perché nessun altro meccanismo di failover dipende direttamente da tale impostazione. Il valore predefinito di 30 secondi imposta l'intervallo sp_server_diagnostics su 10 secondi, con un valore minimo di 15 secondi per il timeout e un intervallo di 5 secondi. Più in generale, l'intervallo di aggiornamento di sp_server_diagnostics è sempre 1/3 * HealthCheckTimeout. Quando la DLL della risorsa non riceve un nuovo set di dati di integrità in corrispondenza di un intervallo, continua a usare i dati di integrità dell'intervallo precedente per determinare l'integrità del gruppo di disponibilità e dell'istanza corrente. Se si incrementa il valore di timeout controllo integrità, la replica primaria tollera un uso più intenso della CPU. Ciò può evitare che sp_server_diagnostics trasmetta nuovi dati a ogni intervallo, ma implica l'uso di dati di verifica integrità obsoleti per un periodo più lungo. Indipendentemente dal valore di timeout, quando si ricevono dati indicanti che la replica non è integra, la successiva chiamata IsAlive segnala che l'istanza non è integra e il servizio cluster avvia un failover.
Il livello condizione di errore del gruppo di disponibilità modifica le condizioni di errore per la verifica di integrità. Per qualsiasi livello di errore, se l'elemento gruppo di disponibilità è segnalato come non integro da sp_server_diagnostics, il controllo di integrità ha esito negativo. Ogni livello eredita tutte le condizioni di errore dai livelli inferiori.
| Level | Condizione in cui l'istanza viene considerata inattiva |
|---|---|
| 1: OnServerDown | La verifica integrità non esegue nessuna azione se una qualsiasi risorsa diversa dal gruppo di disponibilità registra un errore. Se i dati del gruppo di disponibilità non vengono ricevuti entro 5 intervalli o 5/3 * HealthCheckTimeout |
| 2: OnServerUnresponsive | Se non viene ricevuto alcun dato da sp_server_diagnostics per HealthCheckTimeout |
| 3: OnCriticalServerError | (Impostazione predefinita) Se il componente di sistema segnala un errore |
| 4: OnModerateServerError | Se il componente risorsa segnala un errore |
| 5: OnAnyQualifiedFailureConitions | Se il componente di elaborazione query segnala un errore |
Aggiornamento dei valori di timeout cluster e Always On
Valori cluster
La configurazione di WSFC include quattro valori che determinano i valori di timeout cluster:
- SameSubnetDelay
- SameSubnetThreshold
- CrossSubnetDelay
- CrossSubnetThreshold
I valori di ritardo (delay) determinano il tempo tra gli heartbeat del servizio cluster, mentre i valori soglia (threshold) impostano il numero di heartbeat ignorabili dal nodo o dalla risorsa di destinazione prima che il cluster dichiari l'oggetto inattivo. Se non è presente nessun heartbeat con esito positivo tra nodi nella stessa subnet per oltre SameSubnetDelay \* SameSubnetThreshold millisecondi, il nodo viene considerato inattivo. Lo stesso vale per le comunicazioni tra subnet che usano i valori tra le subnet.
Per elencare tutti i valori cluster correnti, in qualsiasi nodo del cluster di destinazione aprire un terminale PowerShell con privilegi elevati. Esegui questo comando:
Get-Cluster | fl *
Per aggiornare uno di questi valori, eseguire il comando seguente in un terminale PowerShell con privilegi elevati:
(Get-Cluster).<ValueName> = <NewValue>
Se si incrementa il prodotto di Delay * Threshold per rendere più tollerante il timeout cluster, è consigliabile incrementare prima il valore delay (ritardo) e quindi il valore threshold (soglia). Se si aumenta il ritardo, aumenta il tempo tra gli heartbeat. Più tempo tra gli heartbeat significa più tempo per la risoluzione dei problemi di rete temporanei e la riduzione della congestione della rete prodotta dall'invio di più heartbeat nello stesso periodo.
Timeout lease
Il meccanismo lease è controllato da un valore singolo specifico per ogni gruppo di disponibilità in un cluster WSFC. Un timeout lease potrebbe causare gli errori seguenti:
Error 35201:
A connection timeout has occurred while attempting to establish a connection to availability replica 'replicaname'
Error 35206:
A connection timeout has occurred on a previously established connection to availability replica 'replicaname'
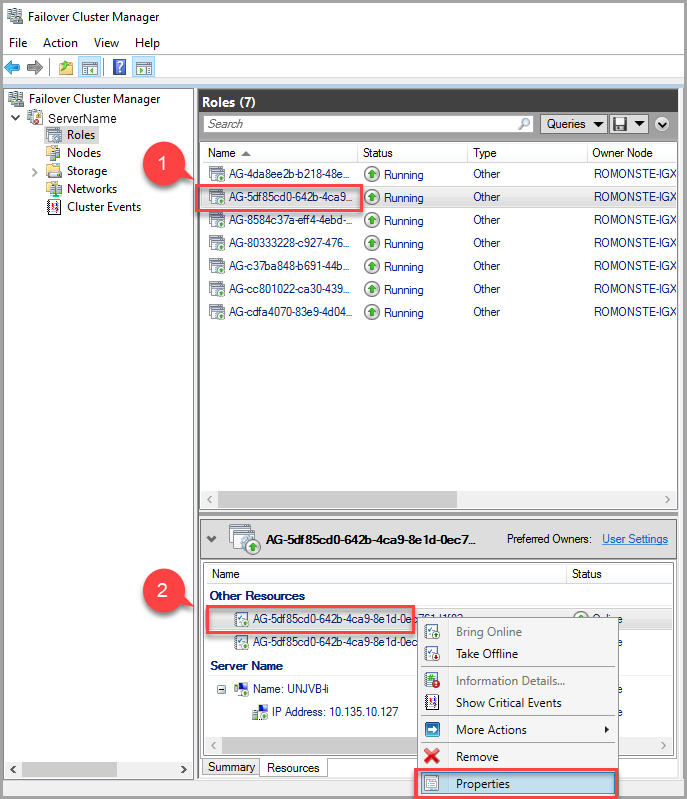
Per modificare il valore del timeout lease, usare Gestione cluster di failover e seguire questa procedura:
Nella scheda dei ruoli trovare il ruolo del gruppo di disponibilità di destinazione. Selezionare il ruolo del gruppo di disponibilità di destinazione.
Fare clic con il pulsante destro del mouse sulla risorsa del gruppo di disponibilità nella parte inferiore della finestra e selezionare Proprietà.
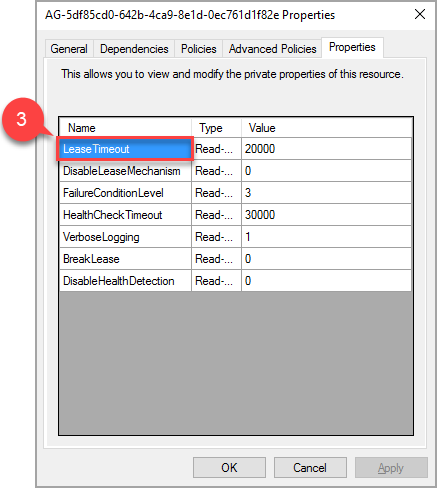
Nella finestra popup passare alla scheda delle proprietà per visualizzare un elenco di valori specifici per il gruppo di disponibilità corrente. Selezionare il valore LeaseTimeout per modificarlo.
A seconda della configurazione del gruppo di disponibilità, potrebbero essere disponibili risorse aggiuntive per listener, dischi condivisi, condivisioni di file e così via. Queste risorse non richiedono alcuna configurazione aggiuntiva.
Nota
Per rendere effettivo il nuovo valore della proprietà 'LeaseTimeout', è necessario portare offline e quindi di nuovo online la risorsa.
Valori del controllo integrità
Il controllo integrità Always On è gestito da due valori: FailureConditionLevel e HealthCheckTimeout. FailureConditionLevel indica il livello di tolleranza a condizioni di errore specifiche segnalate da sp_server_diagnostics, mentre HealthCheckTimeout consente di configurare il tempo per il quale la DLL della risorsa può funzionare senza ricevere un aggiornamento da sp_server_diagnostics. L'intervallo di aggiornamento per sp_server_diagnostics è sempre HealthCheckTimeout/3.
Per configurare il livello della condizione di failover, usare l'opzione FAILURE_CONDITION_LEVEL = <n> dell'istruzione CREATE o ALTERAVAILABILITY GROUP, dove <n> è un numero intero incluso tra 1 e 5. Il comando seguente imposta il livello della condizione di errore su 1 per il gruppo di disponibilità "AG1":
ALTER AVAILABILITY GROUP AG1 SET (FAILURE_CONDITION_LEVEL = 1);
Per configurare il timeout controllo integrità usare l'opzione HEALTH_CHECK_TIMEOUT delle istruzioni CREATE o ALTERAVAILABILITY GROUP. Il comando seguente imposta il timeout controllo integrità su 60.000 millisecondi per il gruppo di disponibilità AG1:
ALTER AVAILABILITY GROUP AG1 SET (HEALTH_CHECK_TIMEOUT =60000);
Riepilogo delle linee guida per i timeout
Non è consigliabile ridurre i valori di timeout al di sotto dei valori predefiniti.
L'intervallo lease (½ * LeaseTimeout) deve essere inferiore al prodotto di SameSubnetThreshold * SameSubnetDelay
SameSubnetThreshold <= CrossSubnetThreshold
SameSubnetDelay <= CrossSubnetDelay
| Impostazione di timeout | Scopo | tra le | Usi | IsAlive e LooksAlive | Cause | Risultato |
|---|---|---|---|---|---|---|
| Timeout lease Impostazione predefinita: 20000 |
Previene lo "split brain". | Da primaria a cluster (HADR) |
Oggetti evento di Windows | Usati in entrambi | Mancata risposta del sistema operativo, memoria virtuale insufficiente, paging del working set, generazione di dump, massimo utilizzo della CPU, WSFC inattivo (perdita di quorum) | Risorsa del gruppo di disponibilità offline-online, failover |
| Timeout sessione Impostazione predefinita: 10000 |
Informare del problema di comunicazione tra replica primaria e secondaria | Da secondaria a primaria (HADR) |
Socket TCP (messaggi inviati tramite l'endpoint di mirroring del database) | Usati in nessuna delle due | Comunicazione di rete, Problemi nella replica secondaria - inattiva, mancata risposta del sistema operativo, contesa di risorse |
Secondaria - DISCONNESSA |
| Timeout controllo integrità Impostazione predefinita 30000 |
Indicare il timeout durante il tentativo di determinare l'integrità della replica primaria | Da cluster a primaria (FCI e HADR) |
sp_server_diagnostics di T-SQL | Usati in entrambi | Condizioni di errore soddisfatte, mancata risposta del sistema operativo, memoria virtuale insufficiente, taglio del working set, generazione di dump, WSFC (perdita di quorum), problemi dell'utilità di pianificazione (utilità di pianificazione con deadlock) | Risorsa del gruppo di disponibilità offline-online o failover, riavvio/failover FCI |
Contenuto correlato
Commenti e suggerimenti
Presto disponibile: Nel corso del 2024 verranno gradualmente disattivati i problemi di GitHub come meccanismo di feedback per il contenuto e ciò verrà sostituito con un nuovo sistema di feedback. Per altre informazioni, vedere https://aka.ms/ContentUserFeedback.
Invia e visualizza il feedback per