Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server
Per creare un gruppo di disponibilità distribuito, è necessario creare due gruppi di disponibilità ognuno con il proprio listener. È quindi possibile combinare questi gruppi di disponibilità in un gruppo di disponibilità distribuito. La procedura seguente illustra un esempio di base in Transact-SQL. Questo esempio non descrive in dettaglio la creazione di gruppi di disponibilità e listener, ma mette in rilievo i requisiti principali.
Per una panoramica tecnica dei gruppi di disponibilità distribuiti, vedere Gruppi di disponibilità distribuiti.
Prerequisiti
Per configurare un gruppo di disponibilità distribuito, è necessario disporre di quanto segue:
- Versione supportata di SQL Server.
Nota
Se il listener è stato configurato per il gruppo di disponibilità in SQL Server in una macchina virtuale di Azure usando un nome di rete distribuito (DNN), la configurazione di un gruppo di disponibilità distribuito al di sopra del gruppo di disponibilità non è supportata. Per altre informazioni, vedere Interoperabilità di SQL Server sulla macchina virtuale Azure con il gruppo di disponibilità e listener DNN.
Autorizzazioni
È richiesta l'autorizzazione CREATE AVAILABILITY GROUP per il server per creare un gruppo di disponibilità e sysadmin per eseguire il failover di un gruppo di disponibilità distribuito.
Impostare gli endpoint di mirroring del database per l'ascolto su tutti gli indirizzi IP
Assicurarsi che gli endpoint del mirroring del database possano comunicare tra i diversi gruppi di disponibilità nel gruppo di disponibilità distribuito. Se un gruppo di disponibilità è impostato su una rete specifica nell'endpoint del mirroring del database, il gruppo di disponibilità distribuito non funziona correttamente. In ogni server che ospita una replica nel gruppo di disponibilità distribuito, impostare l'endpoint del mirroring del database in modo che ascolti su tutti gli indirizzi IP (LISTENER_IP = ALL).
Creare un endpoint del mirroring del database per l'ascolto su tutti gli indirizzi IP
Ad esempio, lo script seguente crea un nuovo endpoint per il mirroring del database sulla porta TCP 5022, che ascolta su tutti gli indirizzi IP.
CREATE ENDPOINT [aodns-hadr]
STATE = STARTED
AS TCP
(
LISTENER_PORT = 5022,
LISTENER_IP = ALL
)
FOR DATABASE_MIRRORING
(
ROLE = ALL,
AUTHENTICATION = WINDOWS NEGOTIATE,
ENCRYPTION = REQUIRED ALGORITHM AES
);
GO
Modificare un endpoint del mirroring del database esistente per l'ascolto su tutti gli indirizzi IP
Lo script seguente, ad esempio, modifica un endpoint di mirroring del database esistente in modo che sia in ascolto su tutti gli indirizzi IP.
ALTER ENDPOINT [aodns-hadr]
AS TCP
(
LISTENER_IP = ALL
);
GO
Creare un primo gruppo di disponibilità
Creare il gruppo di disponibilità primario nel primo cluster
Creare un gruppo di disponibilità nel primo cluster di failover di Windows Server (WSFC). In questo esempio il gruppo di disponibilità è denominato ag1 per il database db1. La replica primaria del gruppo di disponibilità primario è nota come server primario globale in un gruppo di disponibilità distribuito. Server1 è il server primario globale in questo esempio.
CREATE AVAILABILITY GROUP [ag1]
FOR DATABASE db1
REPLICA ON N'server1' WITH (ENDPOINT_URL = N'TCP://server1.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server2' WITH (ENDPOINT_URL = N'TCP://server2.contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Nota
L'esempio precedente usa il seeding automatico, dove SEEDING_MODE è impostato su AUTOMATIC per le repliche e il gruppo di disponibilità distribuito. Questa configurazione imposta le repliche secondarie e il gruppo di disponibilità secondario in modo che vengano popolati automaticamente senza richiedere alcun backup e ripristino manuale del database primario.
Creare un join delle repliche secondarie al gruppo di disponibilità primario
È necessario creare un join tra tutte le repliche secondarie al gruppo di disponibilità tramite ALTER AVAILABILITY GROUP con l'opzione JOIN. Dal momento che in questo esempio viene usato il seeding automatico, è necessario chiamare anche ALTER AVAILABILITY GROUP con l'opzione GRANT CREATE ANY DATABASE. Questa impostazione consente al gruppo di disponibilità di creare il database e avviare il seeding automatico dalla replica primaria.
In questo esempio i seguenti comandi vengono eseguiti sulla replica secondaria, server2, per creare un join del gruppo di disponibilità ag1. Il gruppo di disponibilità può quindi creare database sulla replica secondaria.
ALTER AVAILABILITY GROUP [ag1] JOIN
ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE
GO
Nota
Quando il gruppo di disponibilità crea un database in una replica secondaria, imposta il proprietario del database come l'account che ha eseguito l'istruzione ALTER AVAILABILITY GROUP per concedere l'autorizzazione per la creazione di qualsiasi database. Per informazioni complete, vedere Concedere le autorizzazioni di creazione di database sulla replica secondaria al gruppo di disponibilità.
Creare un listener per il gruppo di disponibilità primario
Successivamente aggiungere un listener per il gruppo di disponibilità primario sul primo WSFC. In questo esempio il listener viene denominato ag1-listener. Per istruzioni dettagliate sulla creazione di un listener, vedere Creare o configurare un listener del gruppo di disponibilità (SQL Server).
ALTER AVAILABILITY GROUP [ag1]
ADD LISTENER 'ag1-listener' (
WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) ,
PORT = 60173);
GO
Creare un secondo gruppo di disponibilità
Creare quindi un secondo gruppo di disponibilità, ag2, nel secondo WSFC. In questo caso, il database non viene specificato, perché viene eseguito automaticamente il seeding dal gruppo di disponibilità primario. La replica primaria del gruppo di disponibilità secondario è nota come server di inoltro in un gruppo di disponibilità distribuito. In questo esempio server3 è il server d'inoltro.
CREATE AVAILABILITY GROUP [ag2]
FOR
REPLICA ON N'server3' WITH (ENDPOINT_URL = N'TCP://server3.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC),
N'server4' WITH (ENDPOINT_URL = N'TCP://server4.contoso.com:5022',
FAILOVER_MODE = MANUAL,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,
BACKUP_PRIORITY = 50,
SECONDARY_ROLE(ALLOW_CONNECTIONS = NO),
SEEDING_MODE = AUTOMATIC);
GO
Nota
- Il gruppo di disponibilità secondario deve usare lo stesso endpoint del mirroring del database (in questo esempio la porta 5022). In caso contrario, la replica verrà interrotta dopo un failover locale.
- I gruppi di disponibilità sottostanti devono trovarsi nella stessa modalità di disponibilità. Entrambi i gruppi di disponibilità devono trovarsi in modalità commit sincrono oppure entrambi devono essere in modalità commit asincrono. Se non si è certi di quale usare, impostare entrambi sulla modalità di commit asincrona fino a quando non si è pronti a eseguire il failover.
Creare un join delle repliche secondarie al gruppo di disponibilità secondario
In questo esempio i seguenti comandi vengono eseguiti sulla replica secondaria, server4, per creare un join del gruppo di disponibilità ag2. Il gruppo di disponibilità può quindi creare database sulla replica secondaria per supportare il seeding automatico.
ALTER AVAILABILITY GROUP [ag2] JOIN
ALTER AVAILABILITY GROUP [ag2] GRANT CREATE ANY DATABASE
GO
Creare un listener per il gruppo di disponibilità secondario
Successivamente aggiungere un listener per il gruppo di disponibilità secondario sul secondo WSFC. In questo esempio il listener viene denominato ag2-listener. Per istruzioni dettagliate sulla creazione di un listener, vedere Creare o configurare un listener del gruppo di disponibilità (SQL Server).
ALTER AVAILABILITY GROUP [ag2]
ADD LISTENER 'ag2-listener' ( WITH IP ( ('2001:db88:f0:f00f::cf3c'),('2001:4898:e0:f213::4ce2') ) , PORT = 60173);
GO
Creare un gruppo di disponibilità distribuito nel primo cluster
Creare un gruppo di disponibilità distribuito nel primo WSFC (in questo esempio denominato distributedAG ). Usare il comando CREATE AVAILABILITY GROUP con l'opzione DISTRIBUTED. Il parametro AVAILABILITY GROUP ON specifica i gruppi di disponibilità membri, ag1 e ag2.
Per creare il gruppo di disponibilità distribuito usando il seeding automatico, usare il seguente codice Transact-SQL:
CREATE AVAILABILITY GROUP [distributedAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Nota
Il parametro LISTENER_URL specifica il listener per ogni gruppo di disponibilità insieme all'endpoint del mirroring del database del gruppo di disponibilità. Questo esempio riguarda la porta 5022 (non la porta 60173 usata per creare il listener). Se si usa un servizio di bilanciamento del carico, ad esempio in Azure, aggiungere una regola di bilanciamento del carico per la porta del gruppo di disponibilità distribuita. Aggiungere la regola per la porta del listener, oltre che alla porta dell'istanza di SQL Server.
Annullare il seeding automatico al server d'inoltro
Se per qualsiasi motivo è necessario annullare l'inizializzazione del server d'inoltro prima che i due gruppi di disponibilità siano sincronizzati, modificare (ALTER) il gruppo di disponibilità distribuito impostando il parametro SEEDING_MODE del server di inoltro su MANUAL e annullare immediatamente il seeding. Eseguire il comando nel database primario globale:
-- Cancel automatic seeding. Connect to global primary but specify DAG AG2
ALTER AVAILABILITY GROUP [distributedAG]
MODIFY
AVAILABILITY GROUP ON
'ag2' WITH
( SEEDING_MODE = MANUAL );
Aggiungere un gruppo di disponibilità distribuito nel secondo cluster
Creare quindi un join del gruppo di disponibilità distribuito nel secondo WSFC.
Per creare un join con il gruppo di disponibilità distribuito usando il seeding automatico, usare il seguente codice Transact-SQL:
ALTER AVAILABILITY GROUP [distributedAG]
JOIN
AVAILABILITY GROUP ON
'ag1' WITH
(
LISTENER_URL = 'tcp://ag1-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'ag2' WITH
(
LISTENER_URL = 'tcp://ag2-listener.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
GO
Creare un join del database alla replica secondaria del secondo gruppo di disponibilità
Se il secondo gruppo di disponibilità è stato configurato per l'uso del seeding automatico, andare al passaggio 2.
Se il secondo gruppo di disponibilità usa il seeding manuale, ripristinare il backup eseguito sul database primario globale nel database secondario del secondo gruppo di disponibilità:
RESTORE DATABASE [db1] FROM DISK = '<full backup location>' WITH NORECOVERY; RESTORE LOG [db1] FROM DISK = '<log backup location>' WITH NORECOVERY;Quando il database nella replica secondaria del secondo gruppo di disponibilità è in uno stato di ripristino, è necessario aggiungerlo manualmente al gruppo di disponibilità.
ALTER DATABASE [db1] SET HADR AVAILABILITY GROUP = [ag2];
Eseguire il failover di un gruppo di disponibilità distribuito
Poiché SQL Server 2022 (16.x) ha introdotto il supporto del gruppo di disponibilità distribuito per l'impostazione REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, le istruzioni per il failover di una disponibilità distribuita sono diverse per SQL Server 2022 e versioni successive rispetto a sql Server 2019 e versioni precedenti.
Per un gruppo di disponibilità distribuito, l'unico tipo di failover supportato è un manuale avviato dall'utente FORCE_FAILOVER_ALLOW_DATA_LOSS. Pertanto, per evitare la perdita di dati, è necessario eseguire passaggi aggiuntivi (descritti in dettaglio in questa sezione) per assicurarsi che i dati vengano sincronizzati tra le due repliche prima di avviare il failover.
In caso di emergenza in cui la perdita di dati è accettabile, è possibile avviare un failover senza garantire la sincronizzazione dei dati eseguendo:
ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;
È possibile usare lo stesso comando per eseguire il failover al server d'inoltro, nonché eseguire il failback nel database primario globale.
In SQL Server 2022 (16.x) e versioni successive è possibile configurare l'impostazione REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT per un gruppo di disponibilità distribuito, progettato per garantire nessuna perdita di dati quando viene eseguito il failover di un gruppo di disponibilità distribuito. Se questa impostazione è configurata, seguire la procedura descritta in questa sezione per eseguire il failover del gruppo di disponibilità distribuito. Se non si vuole usare l'impostazione REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT, seguire le istruzioni per eseguire il failover di un gruppo di disponibilità distribuito in SQL Server 2019 e versioni precedenti.
Nota
L'impostazione di REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT su 1 indica che la replica primaria attende il commit delle transazioni nella replica secondaria prima del commit nella replica primaria, il che può compromettere le prestazioni. Anche se la limitazione o l'arresto delle transazioni nel database primario globale non è necessaria per la sincronizzazione del gruppo di disponibilità distribuito in SQL Server 2022 (16.x), in questo modo è possibile migliorare le prestazioni per le transazioni utente e la sincronizzazione del gruppo di disponibilità distribuito con REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT impostato su 1.
Passaggi per assicurarsi che non si verifichi alcuna perdita di dati
Per assicurarsi che non si verifichi alcuna perdita di dati, è prima necessario configurare il gruppo di disponibilità distribuito per non supportare alcuna perdita di dati seguendo questa procedura:
- Per prepararsi al failover, verificare che il server primario globale e il server d'inoltro siano in
SYNCHRONOUS_COMMITmodalità. In caso contrario, impostarli suSYNCHRONOUS_COMMITa utilizzando ALTER AVAILABILITY GROUP. - Impostare il gruppo di disponibilità distribuito su commit sincrono in sia il server primario globale che il server d'inoltro.
- Attendere che il gruppo di disponibilità distribuito sia sincronizzato.
- Nel primario globale, impostare l'impostazione
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITdel gruppo di disponibilità distribuito su 1 utilizzando il comando ALTER AVAILABILITY GROUP. - Verificare che tutte le repliche nei gruppi di disponibilità locali e nel gruppo di disponibilità distribuito siano in buono stato e che il gruppo di disponibilità distribuito sia SINCRONIZZATO.
- Nella replica primaria globale, impostare il ruolo del gruppo di disponibilità distribuito su
SECONDARY, che rende il gruppo di disponibilità distribuito non disponibile. - Nel server d'inoltro (il nuovo server primario previsto), eseguire il failover del gruppo di disponibilità distribuita usando ALTER AVAILABILITY GROUP con
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Nella nuova replica secondaria (la replica primaria globale precedente) impostare il gruppo di disponibilità distribuito
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITsu 0. - Facoltativo: se i gruppi di disponibilità si trovano in una distanza geografica che causa la latenza, impostare la modalità di disponibilità su
ASYNCHRONOUS_COMMIT. Questa operazione ripristina la modifica dal primo passaggio, se necessario.
Esempio di T-SQL
Questa sezione illustra la procedura descritta in un esempio dettagliato per eseguire il failover del gruppo di disponibilità distribuito denominato distributedAG tramite Transact-SQL. L'ambiente di esempio ha un totale di 4 nodi per il gruppo di disponibilità distribuito. Gruppo globale primario di disponibilità host N1 e N2ag1, mentre il gruppo di disponibilità host dell'inoltro N3 e N4ag2. Il gruppo di disponibilità distribuito distributedAG esegue il push delle modifiche da ag1 a ag2.
Eseguire una query per verificare
SYNCHRONOUS_COMMITnelle primarie dei gruppi di disponibilità locali che formano il gruppo di disponibilità distribuito. Eseguire il codice T-SQL seguente direttamente sul server d'inoltro e sul database primario globale.SELECT DISTINCT ag.name AS [Availability Group], ar.replica_server_name AS [Replica], ar.availability_mode_desc AS [Availability Mode] FROM sys.availability_replicas AS ar INNER JOIN sys.availability_groups AS ag ON ar.group_id = ag.group_id INNER JOIN sys.dm_hadr_database_replica_states AS rs ON ar.group_id = rs.group_id AND ar.replica_id = rs.replica_id WHERE ag.name IN ('ag1', 'ag2') AND rs.is_primary_replica = 1 ORDER BY [Availability Group]; --if needed, to set a given replica to SYNCHRONOUS for node N1, default instance. If named, change from N1 to something like N1\SQL22 ALTER AVAILABILITY GROUP [testag] MODIFY REPLICA ON N'N1\SQL22' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Impostare il gruppo di disponibilità distribuito su commit sincrono eseguendo il codice seguente in sia il server primario globale che il server d'inoltro:
-- sets the distributed availability group to synchronous commit ALTER AVAILABILITY GROUP [distributedAG] MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Nota
In un gruppo di disponibilità distribuito, lo stato di sincronizzazione tra i due gruppi di disponibilità dipende dalla modalità di disponibilità di entrambe le repliche. Per la modalità con commit sincrono, il gruppo di disponibilità primario corrente e quello secondario corrente devono essere entrambi configurati con la modalità di disponibilità
SYNCHRONOUS_COMMIT. Per questo motivo, è necessario eseguire questo script sia nella replica primaria globale che nel server d'inoltro.Attendere che lo stato del gruppo di disponibilità distribuito venga modificato in
SYNCHRONIZED. Eseguire la query seguente sul database primario globale:-- Run this query on the Global Primary -- Check the results to see if synchronization_state_desc is SYNCHRONIZED SELECT ag.name, drs.database_id AS [Availability Group], db_name(drs.database_id) AS database_name, drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id WHERE ag.name = 'distributedAG' ORDER BY [Availability Group];Procedere dopo che la synchronization_state_desc del gruppo di disponibilità è
SYNCHRONIZED.Per SQL Server 2022 (16.x) e versioni successive, nel global primary, impostare
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITsu 1 utilizzando il seguente T-SQL:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Verificare che i gruppi di disponibilità siano integri in tutte le repliche eseguendo una query sul primario globale e sul server d'inoltro:
SELECT ag.name AS [AG Name], db_name(drs.database_id) AS database_name, ar.replica_server_name AS [replica], drs.synchronization_state_desc, drs.last_hardened_lsn FROM sys.dm_hadr_database_replica_states AS drs INNER JOIN sys.availability_groups AS ag ON drs.group_id = ag.group_id INNER JOIN sys.availability_replicas AS ar ON drs.replica_id = ar.replica_id AND drs.replica_id = ar.replica_id WHERE ag.name IN ('ag1', 'ag2', 'distributedAG');Nel server primario globale impostare il ruolo del gruppo di disponibilità distribuito su
SECONDARY. A questo punto, il gruppo di disponibilità distribuito non è disponibile. Al termine di questo passaggio, non è possibile eseguire il failback finché non vengono completati i passaggi restanti.ALTER AVAILABILITY GROUP distributedAG SET (ROLE = SECONDARY);Eseguire il failover dal database primario globale eseguendo la query seguente sul server d'inoltro per eseguire la transizione dei gruppi di disponibilità e riportare online il gruppo di disponibilità distribuito:
-- Run the following command on the forwarder, the SQL Server instance that hosts the primary replica of the secondary availability group. ALTER AVAILABILITY GROUP distributedAG FORCE_FAILOVER_ALLOW_DATA_LOSS;Dopo questo passaggio:
- Il cambiamento primario globale passa da
N1aN3. - Il server d'inoltro passa da
N3aN1. - Il gruppo di disponibilità distribuito è disponibile.
- Il cambiamento primario globale passa da
Nel nuovo server d'inoltro (primario globale precedente,
N1), deselezionare la proprietà del gruppo di disponibilità distribuitoREQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITimpostandola su 0:ALTER AVAILABILITY GROUP distributedAG SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 0);FACOLTATIVO: se i gruppi di disponibilità si trovano in una distanza geografica che causa la latenza, prendere in considerazione la possibilità di tornare alla modalità di disponibilità in
ASYNCHRONOUS_COMMITsu sia primario globale che sul server d'inoltro. Questa operazione ripristina la modifica apportata nel primo passaggio, se necessario.-- If applicable: sets the distributed availability group to asynchronous commit: ALTER AVAILABILITY GROUP distributedAG MODIFY AVAILABILITY GROUP ON 'ag1' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT), 'ag2' WITH (AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT);
Rimuovere un gruppo di disponibilità distribuito
L'istruzione Transact-SQL seguente rimuove un gruppo di disponibilità distribuito denominato distributedAG:
DROP AVAILABILITY GROUP distributedAG;
Creare un gruppo di disponibilità distribuito in istanze del cluster di failover
È possibile creare un gruppo di disponibilità distribuito usando un gruppo di disponibilità in un'istanza del cluster di failover. In questo caso, non è necessario un listener del gruppo di disponibilità. Usare il nome di rete virtuale (VNN) per la replica primaria dell'istanza FCI. L'esempio seguente illustra un gruppo di disponibilità distribuito denominato SQLFCIDAG. Un gruppo di disponibilità è SQLFCIAG. SQLFCIAG ha due repliche FCI. Il nome di rete virtuale per la replica primaria FCI è SQLFCIAG-1 e il nome di rete virtuale per la replica FCI secondaria è SQLFCIAG-2. Il gruppo di disponibilità distribuito include anche SQLAG-DR, per il ripristino di emergenza.
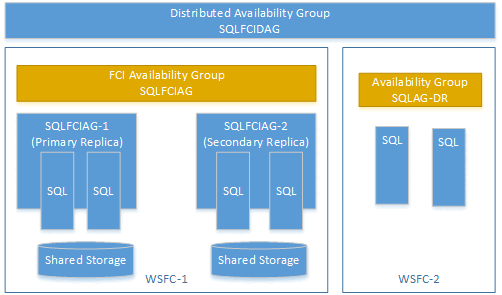
Il DDL seguente crea questo gruppo di disponibilità distribuito:
CREATE AVAILABILITY GROUP [SQLFCIDAG]
WITH (DISTRIBUTED)
AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-1.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
),
'SQLAG-DR' WITH
(
LISTENER_URL = 'tcp://SQLAG-DR.contoso.com:5022',
AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT,
FAILOVER_MODE = MANUAL,
SEEDING_MODE = AUTOMATIC
);
L'URL del listener è il nome di rete virtuale dell'istanza FCI primaria.
Eseguire il failover manuale di FCI in un gruppo di disponibilità distribuito
Per eseguire manualmente il failover del gruppo di disponibilità FCI, aggiornare il gruppo di disponibilità distribuito in modo da riflettere la modifica dell'URL del listener. Ad esempio, eseguire il DDL seguente sia nel gruppo primario globale del gruppo di disponibilità distribuito sia nel server di inoltro del gruppo di disponibilità distribuito di SQLFCIDAG:
ALTER AVAILABILITY GROUP [SQLFCIDAG]
MODIFY AVAILABILITY GROUP ON
'SQLFCIAG' WITH
(
LISTENER_URL = 'tcp://SQLFCIAG-2.contoso.com:5022'
)