Nota
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare ad accedere o modificare le directory.
L'accesso a questa pagina richiede l'autorizzazione. È possibile provare a modificare le directory.
Si applica a:![]() SQL Server
SQL Server
Un gruppo di disponibilità distribuito è un tipo particolare di gruppo di disponibilità che comprende due gruppi di disponibilità distinti. I gruppi di disponibilità distribuiti sono disponibili a partire da SQL Server 2016.
Questo articolo descrive la funzionalità dei gruppi di disponibilità distribuiti. Per configurare un gruppo di disponibilità distribuito, vedere Configurare gruppi di disponibilità distribuiti.
Panoramica
Un gruppo di disponibilità distribuito è un tipo particolare di gruppo di disponibilità che comprende due gruppi di disponibilità distinti. I gruppi di disponibilità che fanno parte di un gruppo di disponibilità distribuito non devono necessariamente trovarsi nella stessa posizione. Possono essere fisici, virtuali, in locale, nel cloud pubblico o in qualsiasi posizione supporti la distribuzione di un gruppo di disponibilità. Sono inclusi i gruppi multidominio e persino multipiattaforma, ad esempio, nel caso di un gruppo di disponibilità ospitato in Linux e uno ospitato in Windows. Se due gruppi di disponibilità possono comunicare, è possibile usarli per configurare un gruppo di disponibilità distribuito.
Un gruppo di disponibilità tradizionale ha risorse configurate in un cluster di failover di Windows Server (WSFC) o, se su Linux, Pacemaker. Per un gruppo di disponibilità distribuito, non si configura nulla nel cluster sottostante (WSFC o Pacemaker). Tutti gli elementi che lo riguardano vengono mantenuti all'interno di SQL Server. Per sapere come visualizzare le informazioni relative a un gruppo di disponibilità distribuito, vedere Visualizzare informazioni su un gruppo di disponibilità distribuito.
Un gruppo di disponibilità distribuito richiede la presenza di un listener per i gruppi di disponibilità sottostanti. Anziché specificare il nome del server sottostante per un'istanza autonoma o, nel caso di un'istanza del cluster di failover di SQL Server, il valore associato alla risorsa del nome di rete, come si farebbe con un gruppo di disponibilità tradizionale, si specifica il listener configurato per il gruppo di disponibilità distribuito con il parametro ENDPOINT_URL durante la creazione. Anche se ogni gruppo di disponibilità sottostante del gruppo di disponibilità distribuito ha un listener, il gruppo di disponibilità distribuito non ha alcun listener.
La figura seguente mostra una panoramica generale di un gruppo di disponibilità distribuito che comprende due gruppi di disponibilità (AG 1 e AG 2), ognuno dei quali è configurato nel relativo cluster WSFC. Il gruppo di disponibilità distribuito ha un totale di quattro repliche, due in ogni gruppo di disponibilità. Ogni gruppo di disponibilità può supportare un numero massimo di repliche, perciò ogni gruppo di disponibilità può avere fino a 18 repliche.
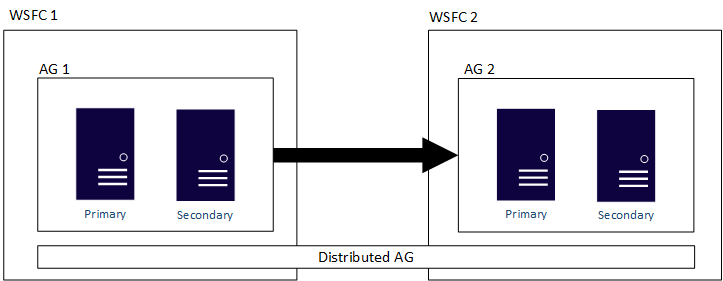
È possibile configurare lo spostamento dei dati nei gruppi di disponibilità distribuiti come sincrono o asincrono. Tuttavia, lo spostamento dei dati all'interno di gruppi di disponibilità distribuiti è leggermente diverso rispetto a quanto avviene in un gruppo di disponibilità tradizionale. Anche se ogni gruppo di disponibilità ha una replica primaria, solo una copia dei database fa parte di un gruppo di disponibilità distribuito che può accettare inserimenti, aggiornamenti ed eliminazioni. Come illustra la figura seguente, AG 1 è il gruppo di disponibilità primario. La relativa replica primaria invia transazioni sia alle repliche secondarie di AG 1 che alla replica primaria di AG 2. La replica primaria di AG 2 è anche nota come forwarder. Un server di inoltro è una replica primaria in un gruppo di disponibilità secondario in un gruppo di disponibilità distribuito. Il server di inoltro riceve le transazioni dalla replica primaria nel gruppo di disponibilità primario e le inoltra alle repliche secondarie nel proprio gruppo di disponibilità. Il server di inoltro mantiene quindi aggiornate le repliche secondarie di AG 2.
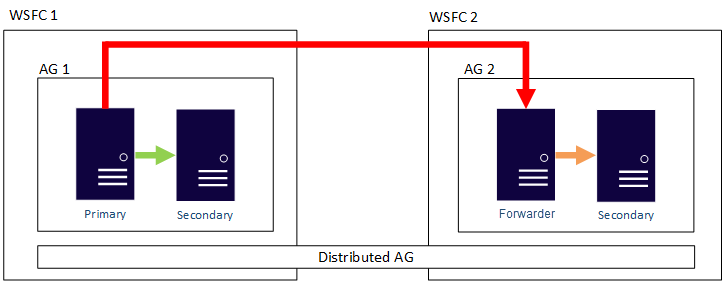
L'unico modo per far sì che la replica primaria di AG 2 accetti inserimenti, aggiornamenti ed eliminazioni è effettuare manualmente il failover del gruppo di disponibilità distribuito da AG 1. Dato che AG 1, nella figura precedente, contiene la copia scrivibile del database, con un failover AG 2 diventa il gruppo di disponibilità che accetta inserimenti, aggiornamenti ed eliminazioni. Per informazioni su come effettuare il failover di un gruppo di disponibilità distribuito in un altro, vedere Failover in un gruppo di disponibilità secondario.
Nota
- I gruppi di disponibilità distribuiti in SQL Server 2016 supportano il failover solo da un gruppo di disponibilità a un altro usando l'opzione
FORCE_FAILOVER_ALLOW_DATA_LOSS. - Quando la replica transazionale viene usata con gruppi di disponibilità distribuiti, la replica del server d'inoltro non può essere configurata come server di pubblicazione.
Modifiche di SQL Server 2025
SQL Server 2025 (17.x) introduce le modifiche seguenti:
Miglioramento della sincronizzazione dell'AG distribuito
SQL Server 2025 (17.x) introduce una modifica al meccanismo di sincronizzazione interno per i gruppi di disponibilità distribuiti per migliorare le prestazioni di sincronizzazione riducendo la saturazione di rete quando la replica del server d'inoltro è in modalità commit asincrono. Questa modifica è abilitata per impostazione predefinita e non richiede alcuna configurazione.
Nota
La configurazione del gruppo di disponibilità distribuito con una mancata corrispondenza tra le modalità di disponibilità dei due gruppi di disponibilità sottostanti non è consigliata e può introdurre latenza di sincronizzazione. Entrambi i gruppi di disponibilità devono essere configurati con la stessa modalità di disponibilità (sincrona o asincrona) per garantire prestazioni e sincronizzazioni ottimali.
Supporto del gruppo di disponibilità contenuto
SQL Server 2025 (17.x) introduce il supporto per un gruppo di disponibilità indipendente distribuito. Se si intende usare un gruppo di disponibilità indipendente come server d'inoltro in un gruppo di disponibilità distribuito, è necessario creare il gruppo di disponibilità indipendente usando la AUTOSEEDING_SYSTEM_DATABASES clausola per l'opzione WITH | CONTAINED del comando CREATE AVAILABILITY GROUP .
Requisiti della versione e dell'edizione
I gruppi di disponibilità distribuiti in SQL Server 2017 o versioni successive possono includere combinazioni di diverse versioni principali di SQL Server. Il gruppo di disponibilità (AG) contenente il database primario di lettura/scrittura può essere della stessa versione o di una versione precedente rispetto agli altri gruppi di disponibilità (AG) partecipanti al gruppo di disponibilità distribuito. Gli altri gruppi di disponibilità possono essere della stessa versione o di versioni successive. Questi scenari sono destinati agli scenari di aggiornamento e migrazione. Ad esempio, se il gruppo di disponibilità che contiene la replica primaria di lettura/scrittura è SQL Server 2016, ma si vuole eseguire l'aggiornamento o la migrazione a SQL Server 2017 o versioni successive, l'altro gruppo di disponibilità facente parte del gruppo di disponibilità distribuito può essere configurato con SQL Server 2017.
Poiché la funzionalità gruppi di disponibilità distribuiti non esiste in SQL Server 2012 o SQL Server 2014, i gruppi di disponibilità creati con tali versioni non possono far parte di gruppi di disponibilità distribuiti.
Nota
A seconda della versione di SQL Server, quando ci si connette ai servizi di Azure (ad esempio il collegamento Istanza gestita), è possibile configurare un gruppo di disponibilità distribuito con l'edizione Standard o una combinazione di edizioni Standard ed Enterprise. Per altre informazioni, vedere KB5016729.
Vista la presenza di due gruppi di disponibilità separati, il processo di installazione di un Service Pack o di un aggiornamento cumulativo in una replica che fa parte di un gruppo di disponibilità distribuito è leggermente diverso da quanto avviene in un gruppo di disponibilità tradizionale:
Per iniziare, aggiornare le repliche del secondo gruppo di disponibilità nel gruppo di disponibilità distribuito.
Applicare patch alle repliche del gruppo di disponibilità primario nel gruppo di disponibilità distribuito.
Come per un gruppo di disponibilità standard, effettuare il failover del gruppo di disponibilità primario in una delle relative repliche, non nella replica primaria del secondo gruppo di disponibilità, e applicare le patch. Se l'unica replica presente è quella primaria, sarà necessario effettuare un failover manuale verso il secondo gruppo di disponibilità.
Versioni e gruppi di disponibilità distribuiti di Windows Server
Un gruppo di disponibilità distribuito comprende più gruppi di disponibilità, ognuno nel proprio WSFC sottostante, ed è un costrutto valido solo in SQL Server. Ciò significa che i cluster WSFC che ospitano i singoli gruppi di disponibilità possono avere versioni principali di Windows Server diverse. Le versioni principali di SQL Server devono essere uguali, come illustrato nella sezione precedente. Come la figura iniziale, la figura seguente mostra i gruppi AG 1 e AG 2 come parte di un gruppo di disponibilità distribuito, ma ogni cluster WSFC ha una versione di Windows Server diversa.
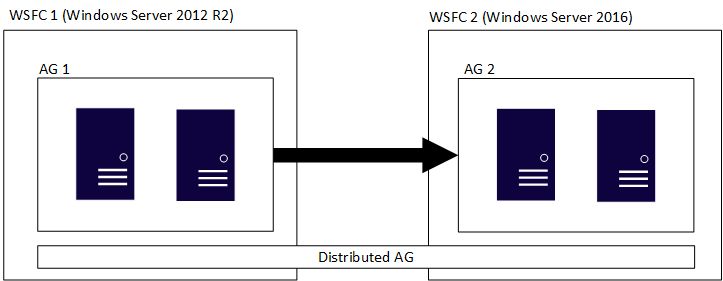
I singoli cluster WSFC e i gruppi di disponibilità corrispondenti seguono regole tradizionali. Ciò significa che possono essere aggiunti a un dominio o non aggiunti a un dominio (Windows Server 2016 o versione successiva). Quando due gruppi di disponibilità diversi vengono combinati in un unico gruppo di disponibilità distribuito, gli scenari possibili sono quattro:
- Entrambi i cluster WSFC sono aggiunti allo stesso dominio.
- Ogni cluster WSFC è aggiunto a un dominio diverso.
- Un cluster WSFC è aggiunto a un dominio e l'altro cluster WSFC non è aggiunto ad alcun dominio.
- Nessuno dei due cluster WSFC è unito a un dominio.
Se entrambi i cluster WSFC sono aggiunti allo stesso dominio (non domini attendibili), non è necessario eseguire operazioni particolari quando si crea il gruppo di disponibilità distribuito. Per gruppi di disponibilità e cluster WSFC non aggiunti allo stesso dominio, usare i certificati per consentire il funzionamento del gruppo di disponibilità distribuito, in modo molto simile a come si può creare un gruppo di disponibilità per un gruppo indipendente dal dominio. Per informazioni su come configurare i certificati per un gruppo di disponibilità distribuito, seguire i passaggi da 3 a 13 della procedura illustrata in Create a domain-independent availability group (Creare un gruppo di disponibilità indipendente dal dominio).
Con un gruppo di disponibilità distribuito, le repliche primarie di ogni gruppo di disponibilità sottostante devono avere reciprocamente i certificati. Se sono già disponibili endpoint che non usano certificati, è possibile usare ALTER ENDPOINT per riconfigurare gli endpoint in modo da riflettere l'uso dei certificati.
Scenari di utilizzo
Di seguito sono riportati i tre scenari di utilizzo principali per un gruppo di disponibilità distribuito:
- Ripristino di emergenza e semplificazione delle configurazioni multisito
- Migrazione a nuovo hardware oppure a nuove configurazioni, come ad esempio l'uso di nuovo hardware o la modifica di sistemi operativi sottostanti
- Aumento del numero di repliche leggibili oltre otto all'interno di un singolo gruppo di disponibilità spaziando su più gruppi di disponibilità
Scenari multisito e di ripristino di emergenza
In un gruppo di disponibilità tradizionale tutti i server devono appartenere allo stesso cluster WSFC. Ciò può rendere difficoltosa l'estensione in più data center. La figura seguente mostra l'aspetto dell'architettura di un gruppo di disponibilità multisito tradizionale, incluso il flusso di dati. Una replica primaria invia transazioni a tutte le repliche secondarie. Per alcuni aspetti, questa configurazione è meno flessibile di un gruppo di disponibilità distribuito. È necessario, ad esempio, implementare Active Directory (se applicabile) e il controllo del quorum nel cluster WSFC. Potrebbe anche essere necessario prendere in considerazione altri aspetti di un cluster WSFC, ad esempio la modifica dei voti dei nodi.

I gruppi di disponibilità distribuiti offrono uno scenario di distribuzione più flessibile per i gruppi di disponibilità che comprendono più data center. È anche possibile usare i gruppi di disponibilità distribuiti dove in passato venivano usate funzionalità come il log shipping per scenari come il ripristino di emergenza. A differenza del log shipping, tuttavia, i gruppi di disponibilità distribuiti non possono avere un'applicazione ritardata delle transazioni. Ciò significa che i gruppi di disponibilità o i gruppi di disponibilità distribuiti non potranno essere utili in caso di errore umano in cui i dati vengano aggiornati o eliminati involontariamente.
I gruppi di disponibilità distribuiti sono debolmente accoppiati, cioè in questo caso non richiedono un WSFC singolo e vengono gestiti da SQL Server. Dato che i cluster WSFC vengono gestiti singolarmente e la sincronizzazione tra i due gruppi di disponibilità è principalmente asincrona, è più semplice configurare il ripristino di emergenza in un altro sito. Le repliche primarie in ogni gruppo di disponibilità sincronizzano le relative repliche secondarie.
- Un gruppo di disponibilità distribuito supporta unicamente il failover manuale. In una situazione di ripristino di emergenza in cui si vogliono cambiare i data center non è consigliabile configurare il failover automatico, tranne in rare eccezioni.
- Probabilmente non sarà necessario impostare alcuni degli elementi o parametri tradizionali per i cluster o le subnet WSFC multisito, ad esempio CrossSubnetThreshold, ma sarà comunque necessario occuparsi della latenza di rete a un livello diverso per il trasporto dei dati. La differenza sta nel fatto che ogni cluster WSFC mantiene la relativa disponibilità. Il cluster non è un'unica grande entità composta da quattro nodi. Sono presenti due cluster WSFC separati di due nodi, come illustrato nella figura precedente.
- È consigliabile adottare l'approccio con spostamento dei dati asincrono, perché è il più adatto ai fini del ripristino di emergenza.
- Se si configura lo spostamento dei dati sincrono tra la replica primaria e almeno una replica secondaria del secondo gruppo di disponibilità e si configura lo spostamento sincrono nel gruppo di disponibilità distribuito, un gruppo di disponibilità distribuito dovrà attendere la conferma della ricezione dei dati da tutte le copie sincrone. Se più gruppi di disponibilità distribuiti sono concatenati (AG1 -> AG2 -> AG3) e impostati sulla modalità sincrona, un gruppo di disponibilità distribuito attende fino all'ultima replica dell'ultimo gruppo di disponibilità aggiornato.
Migrazione
I gruppi di disponibilità distribuiti supportano due configurazioni dei gruppi di disponibilità completamente diverse e semplificano non soltanto gli scenari di ripristino di emergenza e multisito, ma anche gli scenari di migrazione. Se si esegue la migrazione in un nuovo hardware o in macchine virtuali, locali o IaaS nel cloud pubblico, la configurazione di un gruppo di disponibilità distribuito consente di usare la migrazione in situazioni in cui, in passato, era necessario usare il backup, la copia, il ripristino o il log shipping.
La possibilità di eseguire la migrazione è particolarmente utile negli scenari in cui si modifica o si aggiorna il sistema operativo sottostante, mantenendo però la stessa versione di SQL Server. Anche se Windows Server 2016 consente l'aggiornamento in sequenza da Windows Server 2012 R2 nello stesso hardware, la maggior parte degli utenti sceglie di eseguire la distribuzione di nuovo hardware o macchine virtuali.
Per completare la migrazione alla nuova configurazione, alla fine del processo, arrestare tutto il traffico dei dati verso il gruppo di disponibilità originale e configurare il gruppo di disponibilità distribuito per lo spostamento dei dati sincrono. Questa operazione fa in modo che la replica primaria del secondo gruppo di disponibilità sia completamente sincronizzata ed elimina il rischio di perdita di dati. Dopo aver verificato la sincronizzazione, effettua il failover del gruppo di disponibilità distribuito al gruppo di disponibilità secondario. Per ulteriori informazioni, vedere Failover verso un gruppo di disponibilità secondario.
Dopo la migrazione, il secondo gruppo di disponibilità è ora il nuovo gruppo di disponibilità primario e potrebbe essere necessario eseguire uno dei seguenti passaggi:
- Rinominare il listener nel gruppo di disponibilità secondario e, possibilmente, eliminare o rinominare quello precedente nel gruppo di disponibilità primario originale oppure ricrearlo usando il listener del gruppo di disponibilità primario originale, in modo che le applicazioni e gli utenti possano accedere alla nuova configurazione.
- Se non è possibile rinominarlo o ricrearlo, indirizzare applicazioni e utenti al listener nel secondo gruppo di disponibilità.
Eseguire la migrazione a versioni di SQL Server più recenti
In uno scenario di migrazione, è possibile configurare un gruppo di disponibilità distribuito per eseguire la migrazione dei database a una destinazione SQL Server con versione superiore rispetto all'origine, ma esistono alcune limitazioni.
Quando si configura il gruppo di disponibilità distribuito con una destinazione di migrazione SQL Server con versione superiore rispetto all'origine, il seeding automatico non è supportato, quindi la modalità di seeding deve essere impostata su MANUAL. Se non si disabilita AUTO-SEEDING, la migrazione avrà esito negativo e verrà visualizzato l'errore 946 "Impossibile aprire il database 'DistributionAG' versione xxx. Aggiornare il database alla versione più recente" nel log degli errori. È necessario impostare la modalità di seeding su MANUAL ed eseguire manualmente un backup completo e del log delle transazioni del database sorgente dal gruppo di disponibilità primario (AG). Quindi ripristinarlo manualmente, insieme al log delle transazioni, al gruppo di disponibilità secondario. Per ulteriori informazioni, esaminare i passaggi del seeding manuale per configurare il gruppo di disponibilità distribuito e gli script per eseguire il backup e il ripristino del database dal gruppo di disponibilità primario a quello secondario.
Se si suppone che il gruppo di disponibilità secondario (AG2) sia la destinazione di migrazione con una versione superiore rispetto al gruppo di disponibilità primario (AG1), considerare le limitazioni seguenti:
- Non si avrà accesso in lettura ad alcun database di replica nel gruppo di disponibilità secondario, purché il gruppo di disponibilità primario si trovi in una versione inferiore.
- Durante questo periodo, gli aggiornamenti continueranno a fluire dal gruppo di disponibilità primario (AG1) al gruppo di disponibilità secondario (AG2), ma lo stato del gruppo di disponibilità secondario risulterà Parzialmente Integro e i database nelle repliche secondarie del gruppo di disponibilità secondario (AG2) si mostreranno in stato di sincronizzazione/ripristino (anche se il gruppo di disponibilità è impostato su commit in sincronizzazione).
- Dopo il failover del gruppo di disponibilità distribuito alla versione superiore (AG2), AG2 deve risultare integro.
- Durante questo periodo, non sarà possibile effettuare il failback su AG1, poiché si trova in una versione inferiore.
- Poiché AG1 si trova in una versione inferiore, gli aggiornamenti da AG2 dopo il failover su AG2 non verranno replicati su AG1.
- A questo punto, scegliere se si vuole decomissionare il gruppo di disponibilità originale (primario) o se si vuole aggiornare AG1 e mantenere il gruppo di disponibilità distribuito.
- Se si sceglie di disattivare AG1, rimuovere l'AG primario originale dall'AG distribuito per completare il processo.
- Se si sceglie di mantenere il gruppo di disponibilità distribuito, aggiornare la versione SQL Server per il gruppo AG1 in modo che corrisponda al gruppo AG2. Dopo l'aggiornamento di AG1, AG1 diventa integro, il gruppo di disponibilità distribuito diventa integro, le repliche vengono aggiornate per sincronizzarsi, e il failback diventa possibile.
Scalare le repliche leggibili
Un singolo gruppo di disponibilità distribuito può avere fino a 16 repliche secondarie, in base alle esigenze. Può quindi avere fino a 18 copie per la lettura, comprese le due repliche principali dei diversi gruppi di disponibilità. Ciò significa che più di un sito può avere accesso in tempo quasi reale per l'invio di segnalazioni a varie applicazioni.
I gruppi di disponibilità distribuiti consentono una maggiore scalabilità di un cluster di sola lettura rispetto a un singolo gruppo di disponibilità. Con un gruppo di disponibilità distribuito, è possibile scalare le repliche leggibili in due modi:
- È possibile usare la replica primaria del secondo gruppo di disponibilità in un gruppo di disponibilità distribuito per creare un altro gruppo di disponibilità distribuito, anche se il database non è in RECOVERY.
- È anche possibile usare la replica primaria del primo gruppo di disponibilità per creare un altro gruppo di disponibilità distribuito.
In altre parole, una replica primaria può far parte di gruppi di disponibilità distribuiti diversi. La figura seguente mostra che AG 1 e AG 2 fanno parte di Distributed AG 1, mentre AG 2 e AG 3 fanno parte di Distributed AG 2. La replica primaria (o server di inoltro) di AG 2 è una replica secondaria per Distributed AG 1, ma è anche una replica primaria per Distributed AG 2.
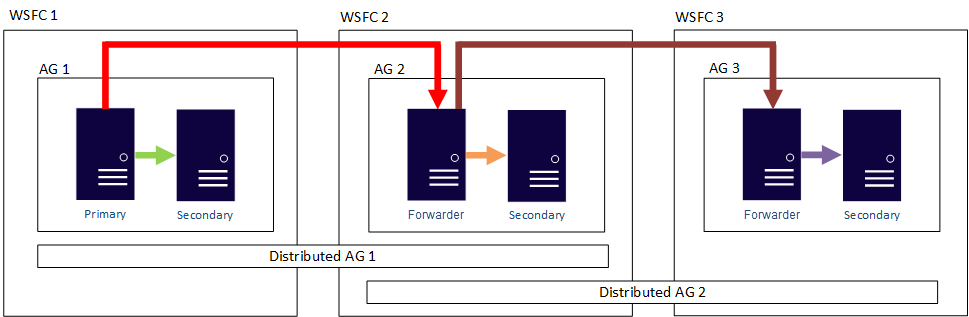
La figura seguente mostra AG 1 come replica primaria per due gruppi di disponibilità distribuiti diversi: Distributed AG 1, composto da AG 1 e AG 2, e Distributed AG 2, composto da AG 1 e AG 3.
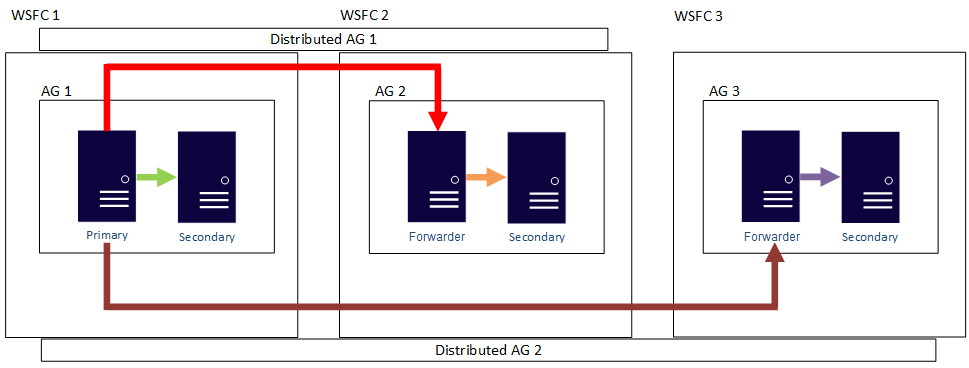
In entrambi gli esempi precedenti si possono avere fino a 27 repliche totali tra i tre gruppi di disponibilità, ognuno dei quali può essere usato per query di sola lettura.
Il instradamento di sola lettura non funziona completamente con i gruppi di disponibilità distribuiti. Più in particolare,
- Il routing di sola lettura può essere configurato e funziona per il gruppo di disponibilità primario del gruppo di disponibilità distribuito.
- Il percorso di sola lettura può essere configurato ma non funziona per il gruppo di disponibilità secondario del gruppo di disponibilità distribuito. Tutte le query che usano il listener per connettersi al gruppo di disponibilità secondario vengono inoltrate alla replica primaria del gruppo di disponibilità secondario. In caso contrario, è necessario configurare ogni replica in modo da consentire tutte le connessioni come replica secondaria e accedervi direttamente. Tuttavia il routing di sola lettura funziona correttamente se il gruppo di disponibilità secondario diventa primario dopo un failover. Questo comportamento potrà essere modificato in un aggiornamento di SQL Server 2016 o in una versione futura di SQL Server.
Inizializzare i gruppi di disponibilità secondari
I gruppi di disponibilità distribuiti sono stati progettati con il seeding automatico come metodo principale per inizializzare la replica primaria nel secondo gruppo di disponibilità. Perché sia possibile un ripristino completo del database nella replica primaria del secondo gruppo di disponibilità, seguire questa procedura:
- Ripristinare il backup del database WITH NORECOVERY.
- Se necessario, ripristinare i backup appropriati del log delle transazioni con NORECOVERY.
- Creare il secondo gruppo di disponibilità senza specificare un nome di database e con SEEDING_MODE impostato su AUTOMATIC.
- Creare il gruppo di disponibilità distribuito usando il seeding automatico.
Quando si aggiunge la replica primaria del secondo gruppo di disponibilità al gruppo di disponibilità distribuito, la replica viene confrontata con i database primari del primo gruppo di disponibilità e il seeding automatico rileva il database fino all'origine. Tenere presente alcune considerazioni:
L'output visualizzato in
sys.dm_hadr_automatic_seedingsulla replica primaria del secondo gruppo di disponibilità mostrerà uncurrent_statedi FAILED con il motivo "Timeout del messaggio di controllo del seeding."Il log degli errori di SQL Server corrente nella replica primaria del secondo gruppo di disponibilità mostrerà che il seeding automatico ha avuto esito positivo e che gli LSN sono stati sincronizzati.
L'output visualizzato in
sys.dm_hadr_automatic_seeding, nella replica primaria del primo gruppo di disponibilità, avrà il current_state impostato su COMPLETED.Il seeding automatico ha anche un comportamento diverso con i gruppi di disponibilità distribuiti. Perché il seeding automatico possa iniziare nella seconda replica, è necessario eseguire il comando
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEnella replica. Anche se questa condizione è vera per tutte le repliche secondarie che fanno parte del gruppo di disponibilità sottostante, la replica primaria del secondo gruppo di disponibilità ha già le autorizzazioni appropriate per consentire l'avvio del seeding automatico dopo l'aggiunta al gruppo di disponibilità distribuito.
Nota
- Il gruppo di disponibilità secondario deve usare lo stesso endpoint del mirroring del database. In caso contrario, la replica viene arrestata dopo un failover locale.
- I gruppi di disponibilità sottostanti devono trovarsi nella stessa modalità di disponibilità. Entrambi i gruppi di disponibilità devono trovarsi in modalità commit sincrono oppure entrambi devono essere in modalità commit asincrono. Se non si è certi di quale usare, impostare entrambi sulla modalità di commit asincrona fino a quando non si è pronti a eseguire il failover.
Monitorare la salute
Un gruppo di disponibilità distribuito è un costrutto solo SQL Server e non viene visualizzato nel WSFC sottostante. Il seguente esempio di codice mostra due diversi cluster WSFC (CLUSTER_A e CLUSTER_B), ognuno con i relativi gruppi di disponibilità. Qui vengono illustrati solo AG1 in CLUSTER_A e AG2 in CLUSTER_B.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
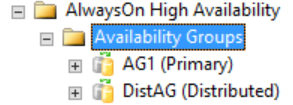
Tutte le informazioni dettagliate su un gruppo di disponibilità distribuito sono disponibili in SQL Server, in particolare nelle viste a gestione dinamica del gruppo di disponibilità. Le uniche informazioni attualmente visualizzate in SQL Server Management Studio per un gruppo di disponibilità distribuito sono disponibili nella replica primaria per i gruppi di disponibilità. Come mostrato nella figura seguente, nella cartella Gruppi di disponibilità di SQL Server Management Studio è disponibile un gruppo di disponibilità distribuito. La figura mostra AG1 come replica primaria di un gruppo di disponibilità individuale che è locale per tale istanza, non di un gruppo di disponibilità distribuito.
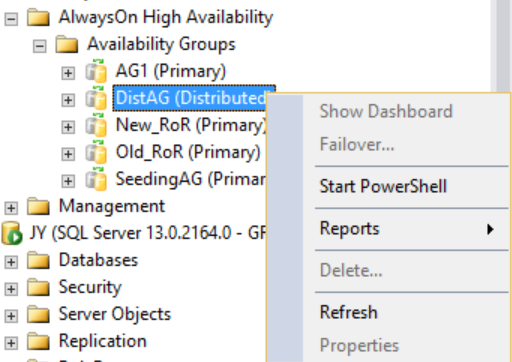
Se però si fa clic con il pulsante destro sul gruppo di disponibilità distribuito, non sono disponibili opzioni, come mostrato nella figura seguente, e le cartelle espanse Database di disponibilità, Listener del gruppo di disponibilità e Repliche di disponibilità sono tutte vuote. SQL Server Management Studio 16 mostra questo risultato, ma è possibile che tale comportamento venga modificato in una versione futura di SQL Server Management Studio.
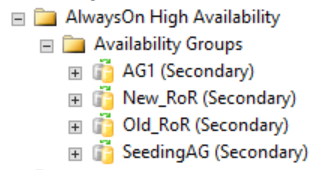
Come mostrato nella figura seguente, le repliche secondarie non mostrano nulla in SQL Server Management Studio correlato al gruppo di disponibilità distribuito. I nomi di questi gruppi di disponibilità corrispondono ai ruoli mostrati nell'immagine precedente CLUSTER_A WSFC.
DMV per visualizzare tutti i nomi delle repliche di disponibilità
Gli stessi concetti sono validi quando si usano le viste a gestione dinamica. Usando la query seguente è possibile visualizzare tutti i gruppi di disponibilità (normali e distribuiti) e i rispettivi nodi. Questo risultato viene visualizzato solo se si esegue una query sulla replica primaria in uno dei cluster WSFC inclusi nel gruppo di disponibilità distribuito. Nella vista a gestione dinamica sys.availability_groups è disponibile una nuova colonna denominata is_distributed, che corrisponde a 1 quando il gruppo di disponibilità è un gruppo di disponibilità distribuito. Per visualizzare questa colonna:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
Un esempio di output del secondo cluster WSFC che partecipa a un gruppo di disponibilità distribuito viene mostrato nella figura seguente. SPAG1 è costituito da due repliche: DENNIS e JY. Il gruppo di disponibilità distribuito denominato SPDistAG include tuttavia i nomi dei due gruppi di disponibilità inclusi (SPAG1 e SPAG2), invece dei nomi delle istanze, usati in un gruppo di disponibilità tradizionale.
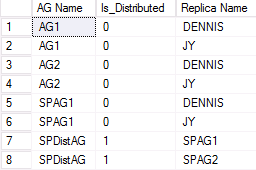
DMV per elencare lo stato di salute del gruppo di disponibilità distribuito
In SQL Server Management Studio qualsiasi stato mostrato nel Dashboard e in altre aree è relativo solo alla sincronizzazione locale entro tale gruppo di disponibilità. Per visualizzare l'integrità di un gruppo di disponibilità distribuito, eseguire query nelle viste a gestione dinamica. La query di esempio seguente estende e perfeziona la query precedente:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV per visualizzare le prestazioni di base
Per estendere ulteriormente la query precedente, è anche possibile visualizzare le prestazioni sottostanti tramite le viste a gestione dinamica aggiungendo sys.dm_hadr_database_replicas_states. La vista a gestione dinamica archivia attualmente informazioni solo sul secondo gruppo di disponibilità. La query di esempio seguente, eseguita sul gruppo di disponibilità primario, produce l'output di esempio mostrato di seguito:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV per visualizzare i contatori delle prestazioni per un Availability Group distribuito
La query seguente consente di visualizzare i contatori delle prestazioni associati allo specifico gruppo di disponibilità distribuito.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'
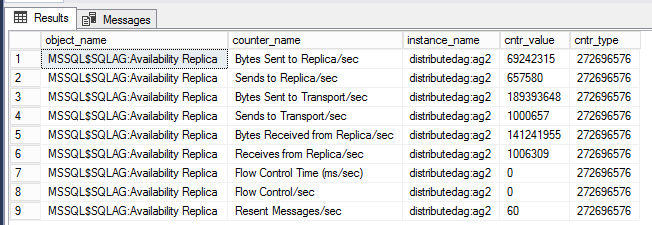
Nota
Il filtro LIKE deve avere il nome del gruppo di disponibilità distribuito. In questo esempio, il nome del gruppo di disponibilità distribuito è 'distributedag'. Modificare il modificatore LIKE in modo che rispecchi il nome del gruppo di disponibilità distribuito.
DMV per visualizzare lo stato di salute sia del gruppo di disponibilità che del gruppo di disponibilità distribuito
La query seguente consente di visualizzare un'ampia gamma di informazioni sull'integrità sia del gruppo di disponibilità che del gruppo di disponibilità distribuito. (Riprodotto con l'autorizzazione di Tracy Boggiano).
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMV per visualizzare i metadati del gruppo di disponibilità distribuito
Le query seguenti visualizzeranno informazioni sugli URL dell'endpoint usati dai gruppi di disponibilità, incluso il gruppo di disponibilità distribuito. (Riprodotto con l'autorizzazione di David Barbarin).
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV per visualizzare lo stato corrente del seeding
La query seguente visualizza informazioni sullo stato corrente del seeding. Ciò è utile per la risoluzione degli errori di sincronizzazione tra le repliche. (Riprodotto con l'autorizzazione di David Barbarin).
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO
